2024数据采集与融合技术实践第二次作业
| 这个作业属于哪个课程 | <首页 - 2024数据采集与融合技术实践 - 福州大学 - 班级博客 - 博客园 (cnblogs.com)> |
|---|---|
| 这个作业要求在哪里 | <作业2 - 作业 - 2024数据采集与融合技术实践 - 班级博客 - 博客园 (cnblogs.com)> |
| 学号 | <102202126> |
一、作业内容
作业①
-
要求:在中国气象网(http://www.weather.com.cn)给定城市集的7日天气预报,并保存在数据库。
-
代码如下
from bs4 import BeautifulSoup from bs4 import UnicodeDammit import urllib.request import sqlite3 class WeatherDB: def openDB(self): self.con = sqlite3.connect("weathers.db") self.cursor = self.con.cursor() try: self.cursor.execute("CREATE TABLE weathers (wCity VARCHAR(16), wDate VARCHAR(16), wWeather VARCHAR(64), wTemp VARCHAR(32), CONSTRAINT pk_weather PRIMARY KEY (wCity, wDate))") except sqlite3.OperationalError: # If the table already exists, we ignore the error. pass def closeDB(self): self.con.commit() self.con.close() def insert(self, city, date, weather, temp): try: self.cursor.execute("INSERT INTO weathers (wCity, wDate, wWeather, wTemp) VALUES (?, ?, ?, ?)", (city, date, weather, temp)) except Exception as err: print(err) def show(self): self.cursor.execute("SELECT * FROM weathers") rows = self.cursor.fetchall() print("%-16s%-16s%-32s%-16s" % ("City", "Date", "Weather", "Temp")) for row in rows: print("%-16s%-16s%-32s%-16s" % (row[0], row[1], row[2], row[3])) class WeatherForecast: def __init__(self): self.headers = { "User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre" } self.cityCode = {"北京": "101010100", "上海": "101020100", "广州": "101280101", "深圳": "101280601"} self.db = WeatherDB() # Initialize WeatherDB instance def forecastCity(self, city): if city not in self.cityCode.keys(): print(city + " code cannot be found") return url = "http://www.weather.com.cn/weather/" + self.cityCode[city] + ".shtml" try: req = urllib.request.Request(url, headers=self.headers) data = urllib.request.urlopen(req) data = data.read() dammit = UnicodeDammit(data, ["utf-8", "gbk"]) data = dammit.unicode_markup soup = BeautifulSoup(data, "lxml") lis = soup.select("ul[class='t clearfix'] li") for li in lis: try: date = li.select('h1')[0].text weather = li.select('p[class="wea"]')[0].text temp = li.select("p[class='tem']")[0].text.strip() self.db.insert(city, date, weather, temp) except Exception as err: print(f"Error processing weather data: {err}") except Exception as err: print(f"Error fetching weather data: {err}") def process(self, cities): self.db.openDB() # Open database for city in cities: self.forecastCity(city) # Scrape and store weather data for each city self.db.show() # Print data from the database self.db.closeDB() # Close database # Create weather forecast instance and process specified cities ws = WeatherForecast() ws.process(["北京", "上海", "广州", "深圳"]) print("Completed") -
输出信息:
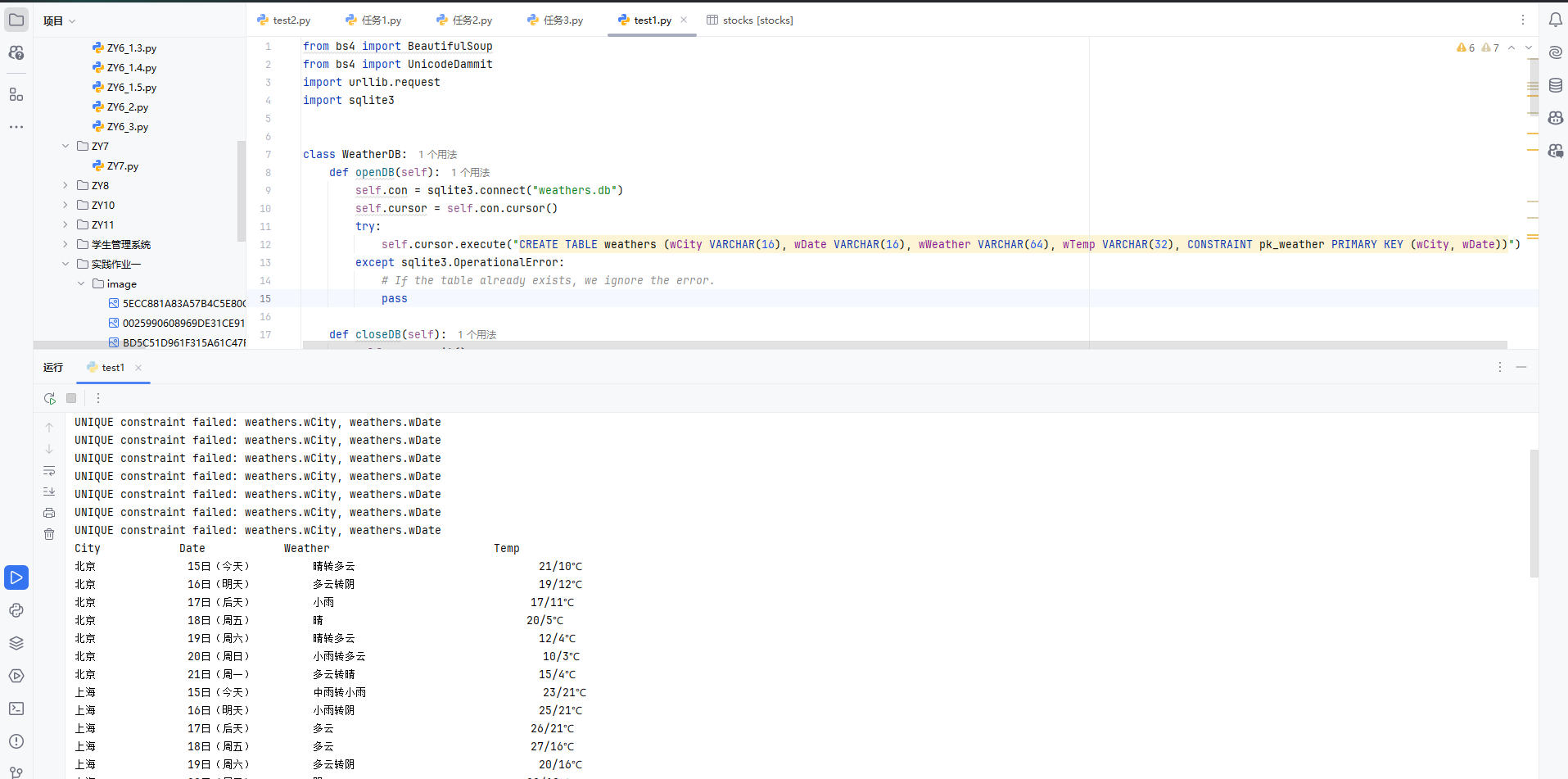

-
Gitee文件夹链接:陈家凯第二次实践作业
-
心得体会:
- 定义类 WeatherDB 和 WeatherForecast,将数据库操作和天气数据处理逻辑封装在类中。
- 使用类的方法进行数据库的打开、关闭、插入和显示操作。
- 使用类的方法进行天气数据的抓取和处理
作业②
-
要求:用requests和BeautifulSoup库方法定向爬取股票相关信息,并存储在数据库中。
-
代码如下
import requests import pandas as pd import sqlite3 import json # 用get方法访问服务器并提取页面数据 def getHtml(page): url = f"https://78.push2.eastmoney.com/api/qt/clist/get?cb=jQuery112408723133727080641_1728978540544&pn={page}&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&dect=1&wbp2u=|0|0|0|web&fid=f3&fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23,m:0+t:81+s:2048&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1728978540545" try: r = requests.get(url) r.raise_for_status() json_data = r.text[r.text.find("{"):r.text.rfind("}")+1] # 提取 JSON 数据部分 data = json.loads(json_data) return data except requests.RequestException as e: print(f"Error fetching data: {e}") return None # 获取单个页面股票数据 def getOnePageStock(page): data = getHtml(page) if not data or 'data' not in data or 'diff' not in data['data']: return [] return data['data']['diff'] # 将股票信息存储到SQLite数据库 def saveToDatabase(stock_list): conn = sqlite3.connect('stocks.db') c = conn.cursor() try: c.execute('''CREATE TABLE IF NOT EXISTS stocks (code TEXT PRIMARY KEY, name TEXT, price REAL, change REAL, percent_change REAL, volume INTEGER, amount REAL)''') for stock in stock_list: c.execute("INSERT OR IGNORE INTO stocks VALUES (?, ?, ?, ?, ?, ?, ?)", (stock.get('f12'), stock.get('f14'), stock.get('f2'), stock.get('f3'), stock.get('f4'), stock.get('f5'), stock.get('f6'))) conn.commit() except sqlite3.Error as e: print(f"Database error: {e}") finally: c.execute("SELECT * FROM stocks") rows = c.fetchall() df = pd.DataFrame(rows, columns=['Code', 'Name', 'Price', 'Change', 'Percent Change', 'Volume', 'Amount']) print(df) conn.close() def main(): all_stocks = [] for page in range(1, 6): # 爬取前5页数据 stock_list = getOnePageStock(page) if stock_list: all_stocks.extend(stock_list) else: print(f"未能获取到第{page}页的股票数据") if all_stocks: print("爬取到的股票数据:") for stock in all_stocks: print(stock) saveToDatabase(all_stocks) print("股票信息已成功存储到数据库。") else: print("未能获取到任何股票数据") if __name__ == "__main__": main() -
输出信息:

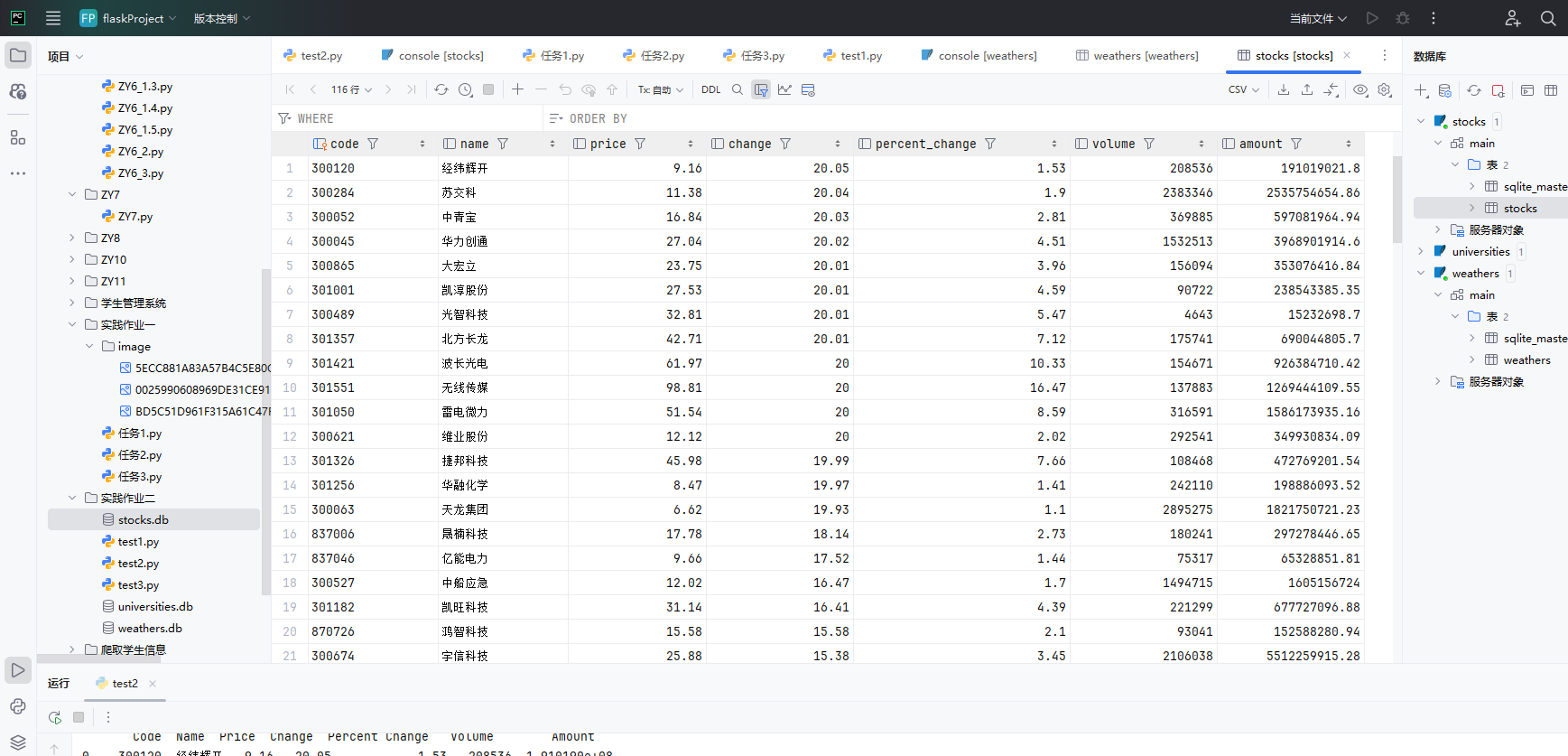
-
Gitee文件夹链接:陈家凯第二次实践作业
-
心得体会:
- 分页处理:通过循环处理多页数据,每次只爬取 20 条记录,对于 API 限制了请求量的情况是合适的。
- 灵活性:在 main 函数中,可以轻松调整爬取的页数(例如从 range(1, 6) 变更为其他范围),这使得代码具备一定的灵活性。
作业③
-
要求:爬取中国大学2021主榜(https://www.shanghairanking.cn/rankings/bcur/2021)所有院校信息,并存储在数据库中,同时将浏览器F12调试分析的过程录制Gif加入至博客中。
-
代码如下
import requests import re import sqlite3 class UniversityDB: def openDB(self): # 连接到SQLite数据库 self.con = sqlite3.connect('universities.db') self.cursor = self.con.cursor() try: # 如果表不存在,则创建universities表 self.cursor.execute('''CREATE TABLE IF NOT EXISTS universities ( id INTEGER PRIMARY KEY AUTOINCREMENT, name TEXT, score REAL )''') except sqlite3.Error as e: print(f"Error creating table: {e}") def closeDB(self): # 提交更改并关闭数据库连接 self.con.commit() self.con.close() def insert(self, university_data): try: # 插入大学数据到表中 sql = "INSERT INTO universities (name, score) VALUES (?, ?)" self.cursor.execute(sql, university_data) except sqlite3.Error as e: print(f"Error inserting data: {e}") def show(self): # 获取并显示universities表中的所有记录 self.cursor.execute("SELECT * FROM universities") rows = self.cursor.fetchall() print("{:<5}{:<20}{:<5}".format("排名", "学校", "总分")) for index, row in enumerate(rows): print("{:<5}{:<20}{:<5}".format(index + 1, row[1], row[2])) class UniversityCrawler: def __init__(self): # 请求的URL和头信息 self.url = 'https://www.shanghairanking.cn/_nuxt/static/1728872418/rankings/bcur/2020/payload.js' self.headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3947.100 Safari/537.36' } def crawl_universities(self): try: # 发送GET请求到URL response = requests.get(self.url, headers=self.headers) response.raise_for_status() response_text = response.text except requests.RequestException as e: print(f"Error fetching data: {e}") return [] # 使用正则表达式提取大学名称和分数 name_pattern = r'univNameCn:"(.*?)"' score_pattern = r'score:(.*?),' names = re.findall(name_pattern, response_text, re.S) scores = re.findall(score_pattern, response_text, re.S) universities_data = [] for name, score in zip(names, scores): try: # 将分数转换为浮点数并添加到列表中 score_value = float(score) universities_data.append((name, score_value)) except ValueError: print(f"Invalid score value: {score}") continue return universities_data def process(self): # 初始化数据库并插入爬取的数据 db = UniversityDB() db.openDB() universities_data = self.crawl_universities() for uni_data in universities_data: db.insert(uni_data) db.show() db.closeDB() if __name__ == "__main__": # 创建爬虫实例并开始处理 crawler = UniversityCrawler() crawler.process() print("completed") -
输出信息:
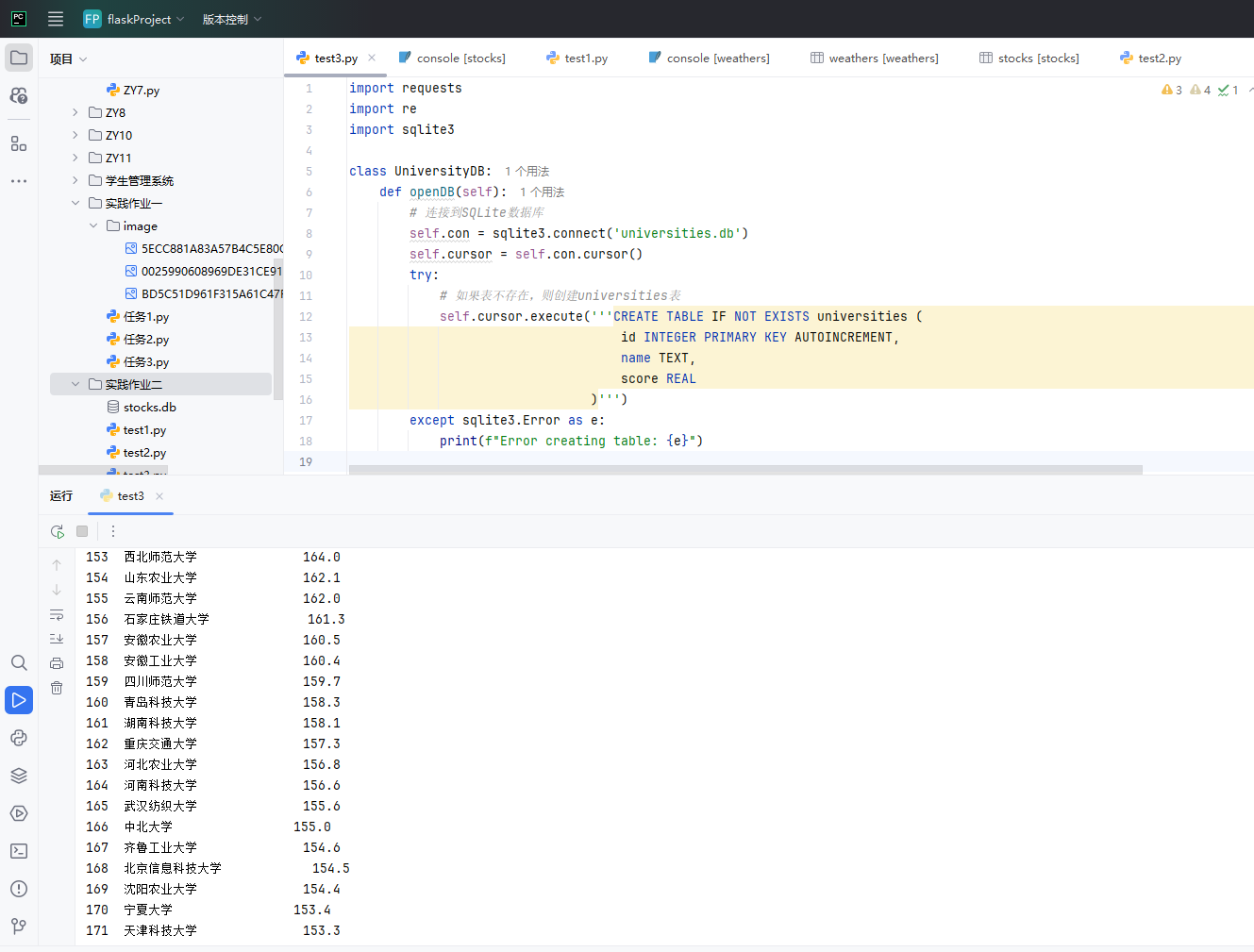

-
gif图:
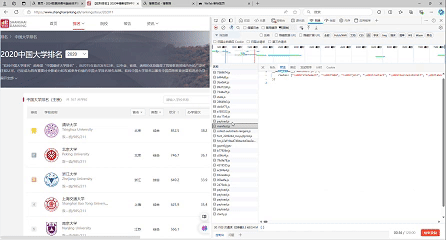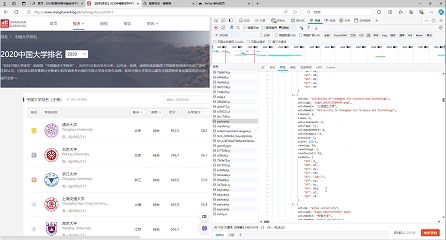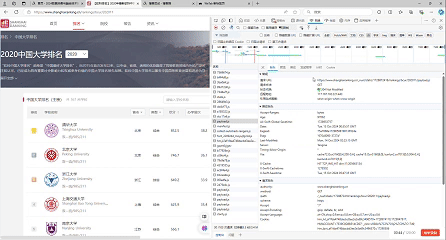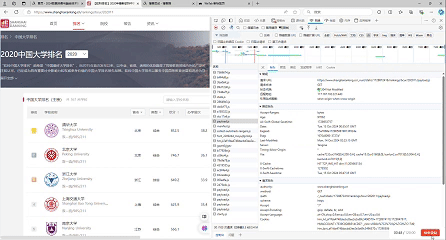
-
Gitee文件夹链接:陈家凯第二次实践作业
-
心得体会:
- 学会了使用 json 库解析 JSON 数据。
- 学会了提取 JSON 数据中的特定部分。
- 学会了使用 sqlite3 库进行 SQLite 数据库操作。
- 学会了创建数据库表并定义主键约束。
- 学会了插入数据并处理可能的异常。
- 学会了查询并显示数据库中的数据
