2024数据采集与融合技术实践第一次作业
| 这个作业属于哪个课程 | <首页 - 2024数据采集与融合技术实践 - 福州大学 - 班级博客 - 博客园 (cnblogs.com)> |
|---|---|
| 这个作业要求在哪里 | <作业1 - 作业 - 2024数据采集与融合技术实践 - 班级博客 - 博客园 (cnblogs.com)> |
| 学号 | <102202126> |
一、作业内容
作业①
-
要求:用requests和BeautifulSoup库方法定向爬取给定网址(http://www.shanghairanking.cn/rankings/bcur/2020)的数据,屏幕打印爬取的大学排名信息。
-
代码如下
import requests from bs4 import BeautifulSoup from prettytable import PrettyTable # 目标网址 url = 'http://www.shanghairanking.cn/rankings/bcur/2020' # 发送HTTP请求 response = requests.get(url) response.encoding = 'utf-8' # 设置编码 # 解析HTML内容 soup = BeautifulSoup(response.text, 'html.parser') # 查找排名表格 table = soup.find('table', {'class': 'rk-table'}) # 提取表格行 rows = table.find_all('tr') # 创建PrettyTable对象 pt = PrettyTable() pt.field_names = ["排名", "学校名称", "省市", "学校类型", "总分"] # 遍历每一行,提取并添加信息到表格 for row in rows[1:]: # 跳过表头 cols = row.find_all('td') rank = cols[0].text.strip() name = cols[1].text.strip() province = cols[2].text.strip() type_ = cols[3].text.strip() score = cols[4].text.strip() pt.add_row([rank, name, province, type_, score]) print(pt) -
输出信息:
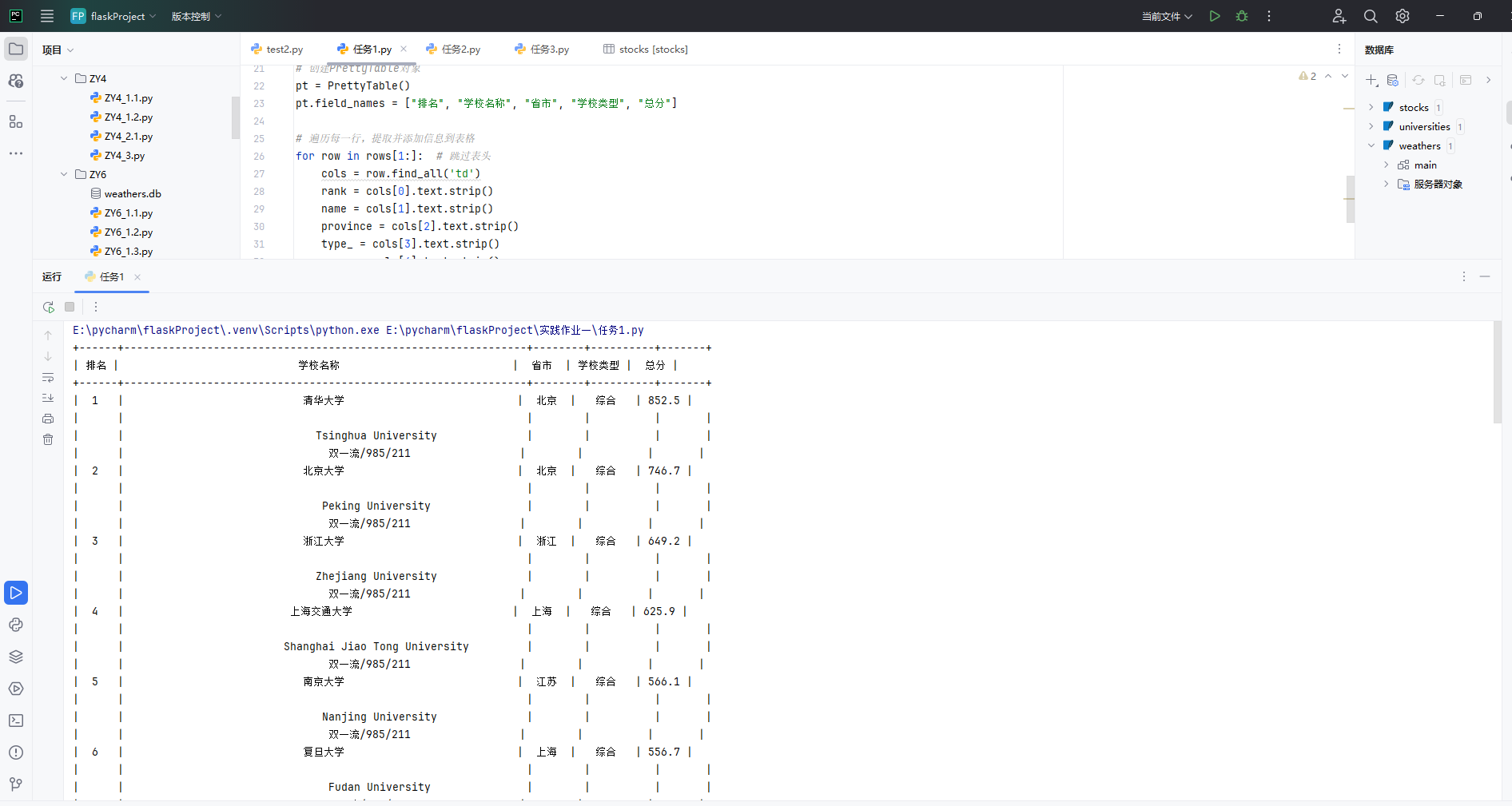
-
Gitee文件夹链接:陈家凯第一次实践作业
-
心得体会:学会了使用requests库发送HTTP请求并处理响和使用BeautifulSoup库解析HTML内容并提取所需数据。
作业②
-
要求:用requests和BeautifulSoup库方法定向爬取股票相关信息,并存储在数据库中。
-
代码如下
import re import urllib.request import os def getHTMLText(url): headers = { 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/129.0.0.0 Safari/537.36 Edg/129.0.0.0' } try: req = urllib.request.Request(url, headers=headers) data = urllib.request.urlopen(req).read().decode() return data except Exception as err: print(f"Error fetching data from {url}: {err}") return "" def parsePage(uinfo, data): plt = re.findall(r'"sku_price":"([\d.]+)"', data) # 商品价格 tlt = re.findall(r'"ad_title_text":"(.*?)"', data) # 商品名称 base_url = "https://img1.360buyimg.com/n6/" # 替换为实际的基础 URL min_length = min(len(plt), len(tlt)) for i in range(min_length): price = plt[i].replace('"', '') # 去掉引号 name = tlt[i].strip('"') # 去掉引号 uinfo.append([len(uinfo) + 1, price, name]) # 添加信息到uinfo列表 return uinfo def downloadImage(img_url, save_path): try: if img_url != '无图片': urllib.request.urlretrieve(img_url, save_path) except Exception as e: print(f"Error downloading {img_url}: {e}") def printGoodslist(uinfo): tplt = "{0:^5}\t{1:^10}\t{2:^20}" print(tplt.format("序号", "价格", "商品名称")) for i in uinfo: print(tplt.format(i[0], i[1], i[2])) def main(): base_url = 'https://re.jd.com/search?keyword=%E4%B9%A6%E5%8C%85&enc=utf-8&page=' uinfo = [] # 循环爬取3-4页 for page in range(3, 5): url = f"{base_url}{page}" data = getHTMLText(url) if data: parsePage(uinfo, data) printGoodslist(uinfo) if __name__ == '__main__': os.makedirs(r"D:\Users\20733\Desktop\数据采集与融合技术\书包", exist_ok=True) main() -
输出信息:

-
Gitee文件夹链接:陈家凯第一次实践作业
-
心得体会:学会了设置了请求头headers以伪装成浏览器请求,避免被网站屏蔽
作业③
-
要求:
-
代码如下
import requests from bs4 import BeautifulSoup import re import os def fetch_images(url, download_folder): headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3' } # 获取网页内容 response = requests.get(url, headers=headers) response.raise_for_status() # 检查请求是否成功 # 解析HTML内容 soup = BeautifulSoup(response.text, 'html.parser') # 查找所有以.jpeg或.jpg结尾的图片URL img_tags = soup.find_all('img', src=re.compile(r'\.(jpeg|jpg)$', re.IGNORECASE)) img_urls = [img['src'] for img in img_tags] # 确保下载文件夹存在 os.makedirs(download_folder, exist_ok=True) # 下载每张图片 for img_url in img_urls: # 处理相对URL if not img_url.startswith('http'): img_url = requests.compat.urljoin(url, img_url) img_name = os.path.join(download_folder, os.path.basename(img_url)) img_data = requests.get(img_url, headers=headers).content with open(img_name, 'wb') as img_file: img_file.write(img_data) print(f"Downloaded {img_name}") if __name__ == "__main__": webpage_url = 'https://news.fzu.edu.cn/yxfd.htm' download_folder = 'image' fetch_images(webpage_url, download_folder) -
输出信息:
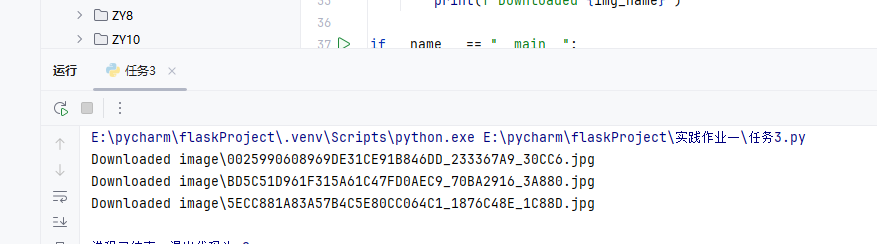
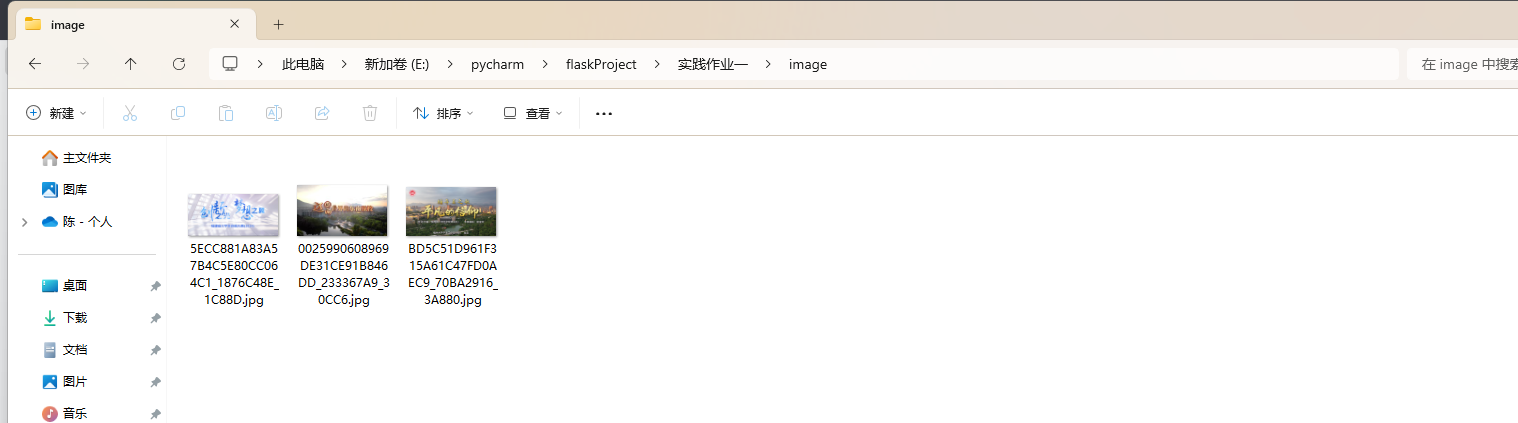
-
Gitee文件夹链接:陈家凯第一次实践作业
-
心得体会:体会到了处理文件操作,包括创建目录和保存文件,同时也体会了如何处理相对 URL
总结
- 通过本次实验,我更加深刻的体会到了数据采集和处理的几个重要库和技术,包括
requests用于发送 HTTP 请求、BeautifulSoup用于解析 HTML、re用于字符串匹配和处理。通过这些工具,可以高效地进行数据采集和分析,为后续的数据融合和决策提供支持。

