分布式一致性算法Raft
Raft算法
在了解Raft之前,我们先了解一致性(Consensus)这个概念,它是指多个服务器在状态达成一致,但是在一个分布式系统中,因为各种意外可能,有的服务器可能会崩溃或变得不可靠,它就不能和其他服务器达成一致状态。这样就需要一种Consensus协议,一致性协议是为了确保容错性,也就是即使系统中有一两个服务器当机,也不会影响其处理过程。
为了以容错方式达成一致,我们不可能要求所有服务器100%都达成一致状态,只要超过半数的大多数服务器达成一致就可以了,假设有N台服务器,N/2 +1 就超过半数,代表大多数了。
角色
在一个由 Raft 协议组织的集群中有三类角色:
- follower
- candidate
- leader
三类角色的变迁图如下,结合后面的选举过程来看很容易理解:

就像一个民主社会,领袖由民众投票选出。刚开始没有领袖,集群中的所有参与者都是群众,那么首先开启一轮大选,在大选期间所有群众都能参与竞选,这时所有群众的角色就变成了候选人,民主投票选出领袖后就开始了这届领袖的任期(用术语 Term 表达),然后选举结束,所有除领袖的候选人又变回群众角色服从领袖领导。
选主(Leader Election)
- 系统在初始状态下,所有node都是follower;
- follower在没有监听到leader的时候,会变为candidate;
- cadidate会向其它node发送投票请求,如果得票数过半就变为leader(candidate可以给自己投票);
- 选出 Leader 后,Leader 通过定期向所有 Follower 发送心跳信息(Heart Beat)维持其统治;
- 若 Follower 一段时间未收到 Leader 的心跳则认为 Leader 可能已经挂了再次发起选主过程。

考虑极简的例子,一个最小的 Raft 民主集群需要三个参与者(如下图:A、B、C),这样才可能投出多数票。初始状态 ABC 都是 Follower,然后发起选举这时有三种可能情形发生。下图中前二种都能选出 Leader,第三种则表明本轮投票无效(Split Votes),每方都投给了自己,结果没有任何一方获得多数票。之后每个参与方随机休息一阵(Election Timeout,150~300ms之间的随机数)重新发起投票直到一方获得多数票。这里的关键就是随机 timeout,最先从 timeout 中恢复发起投票的一方向还在 timeout 中的另外两方请求投票,这时它们就只能投给对方了,很快达成一致。

任期(term)
在 Raft 算法中,所有的节点在发送 RPC 消息时(请求或响应),都会带上 term 字段,
- 如果收到的消息的 term 号小于自身的任期号,则该消息会被视为过期信息并被忽略;
- 如果一个节点收到了一个包含较新 term 的消息,它会立即更新自己的当前任期到这个新的任期,并将自己的状态切换为 follower;
日志复制(Log Replication)
- 预写日志(Write-Ahead-Log, WAL),WAL 目标是在系统发生故障时保证数据的一致性和可靠性。当进行状态改变的操作时,系统首先将这些操作记录到日志中,然后再实际执行这些操作。
- 只有当一个日志(即写入请求)得到了集群超过半数节点的认同后,它才会被提交并将修改应用到状态机中;
- 如果过程中发生了故障,例如系统崩溃或者电源中断,可以通过重新执行日志中的操作来恢复之前的状态(redo);
- 状态机,节点用来实际存储数据的仓库。每个写入请求的最终步骤都是把结果保存到状态机里面,同时,读取请求也需要从这个状态机中提取数据以便响应;
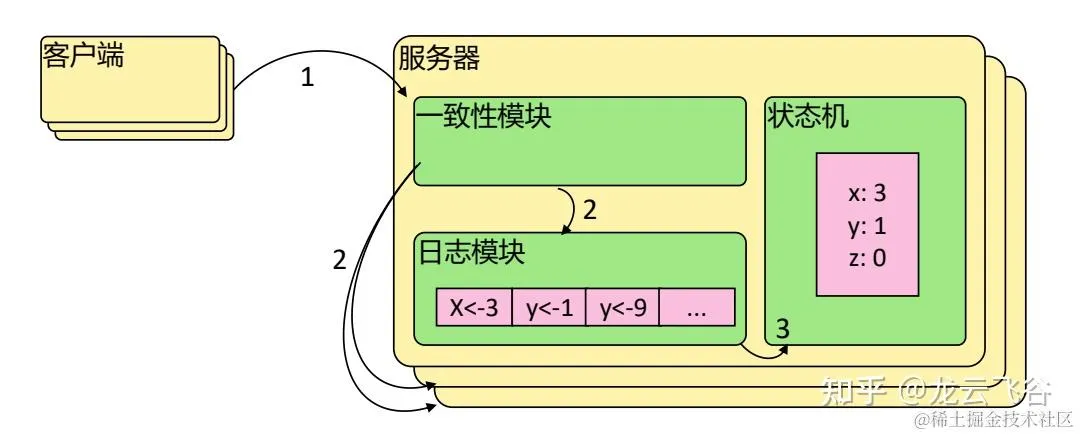
Raft 协议强依赖 Leader 节点的可用性来确保集群数据的一致性。数据的流向只能从 Leader 节点向 Follower 节点转移。当 Client 向集群 Leader 节点提交数据后,Leader 节点接收到的数据处于未提交状态(Uncommitted),接着 Leader 节点会并发向所有 Follower 节点复制数据并等待接收响应,确保至少集群中超过半数节点已接收到数据后再向 Client 确认数据已接收。一旦向 Client 发出数据接收 Ack 响应后,表明此时数据状态进入已提交(Committed),Leader 节点再向 Follower 节点发通知告知该数据状态已提交。

数据更新的流程(两阶段提交,proposal - commit ):
- 所有的修改会写入 leader 节点的 WAL 日志中,写入 WAL 的每条记录都有一个自增的 索引号;
- 客户端如何知道 leader 节点的位置呢?可以让客户端先随机访问一个节点,如果访问到的不是 leader 节点,拒绝访问,并提供 leader 的地址给客户端。
- leader 将此次修改通过心跳请求发给所有的 follower,这个过程称为 proposal;
- follower 节点收到请求后,会在写入 WLA 日志后再返回;
- leader 收到超半数的 follower 节点同意的响应后,leader 节点会再次请求所有 follower 节点提交修改(写入状态机),这个过程称为 commit;
- 如果要求立即一致性的话,leader 需要先修改状态机,然后响应客户端;
- 如果只要求最终一致性的话,leader 可以先响应客户端,再异步写入状态机;
脑裂(Brain Split)
假如一个集群有 5 个节点,节点 1 是 leader,
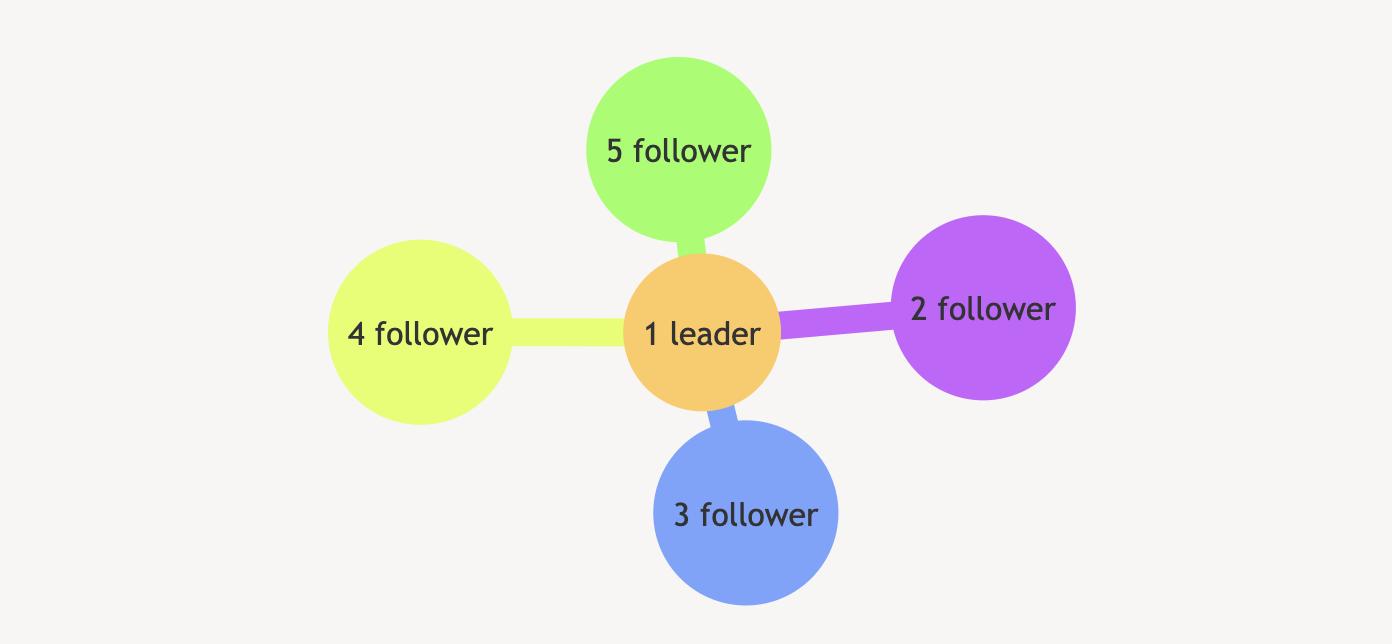
case1、发生脑裂后,原 leader 在多数节点的分区上,
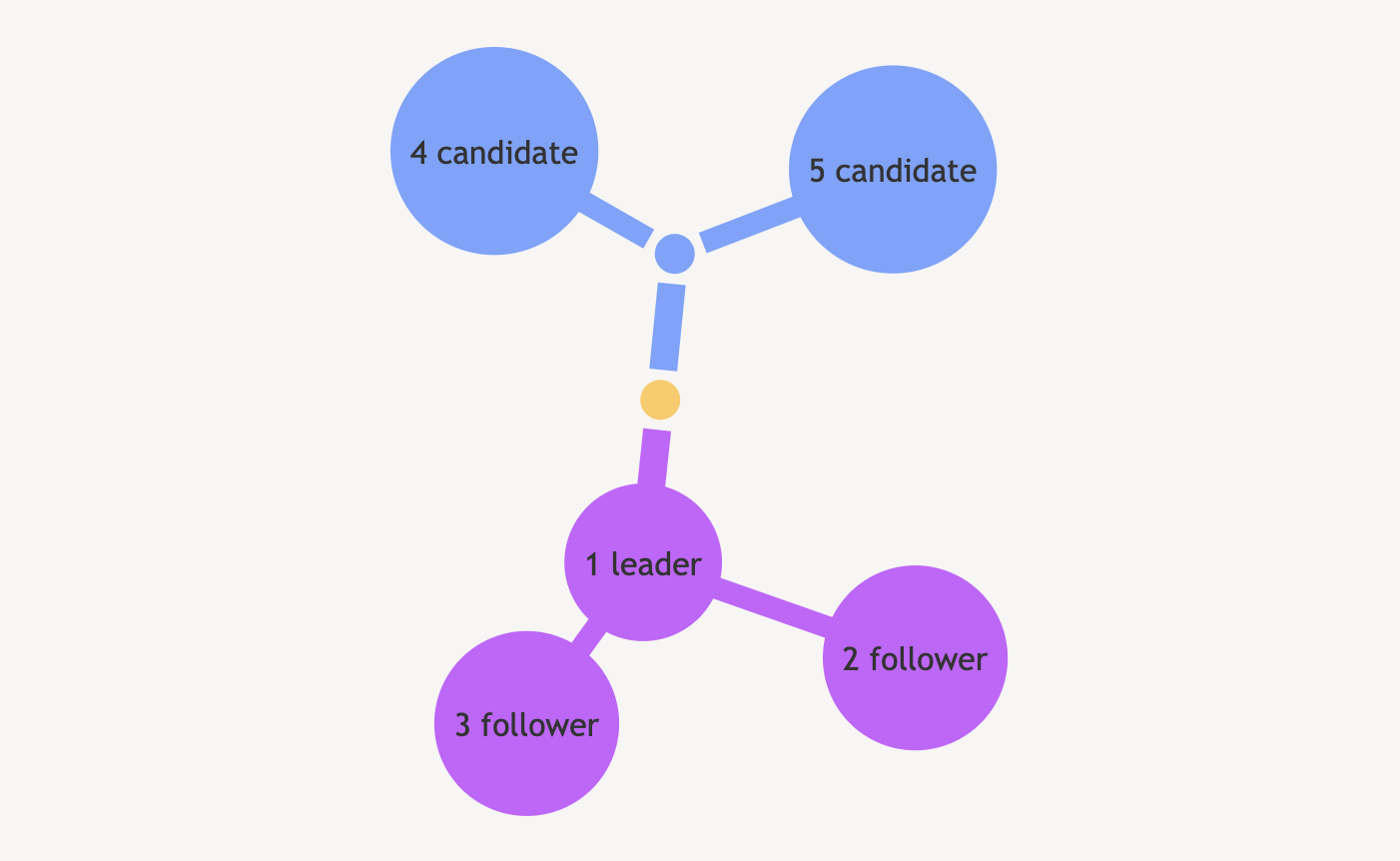
分区后,节点 4、5 在一个分区,1、2、3 在一个分区 。此时 4、5 收不到 leader 的心跳,成为candidate 后由于得不到多数票所以选举失败,都不会成为leader;
case2、发生脑裂后,原 leader 在少数节点的分区上,
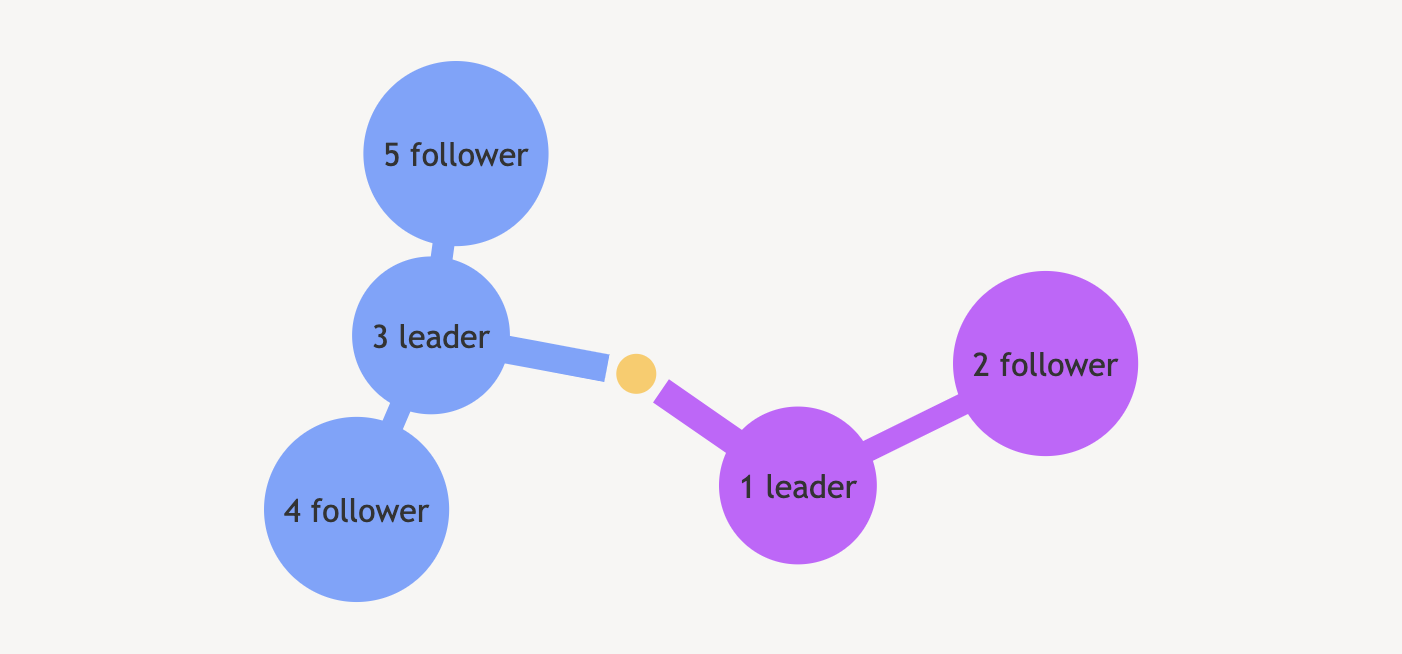
分区后,节点 1、2 在一个分区,3、4、5 在一个分区,1 还是 leader,3、4、5 也会选出一个新的 leader 出来(假设是节点 3),且 term 值更新;此时,
- 如果写请求到节点1,由于 1 只能与 2通信,得不到多数节点的确认,请求会处于无法 commit 的状态;
- 如果从节点 1 读取数据,由于它们所在分区的数据无法更新,会出现脏读。如何解决脏读呢?可以要求 leader 节点在响应只读请求之前,必须通过心跳先获取多数节点的确认。
- 如果写请求到节点3,能得到多数节点的返回,可以正常提交;
如果出现脑裂,可能会有多个 leader 节点,此时两个 partition 的数据会分叉。如果后面网络又好了,会再合并成一个集群,并以新 leader 的数据为准。
预选举(prevote)
假设有A,B,C,D,E五个节点。假设A和E网络不通,但是他们和 B,C,D 都是通的如下图:
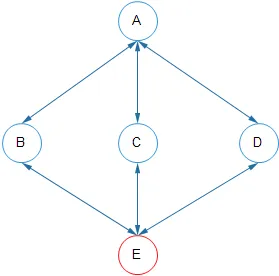
假设某一时刻 leader 是 A 节点,E 在超时没有收到心跳后,把 term+1,发起选举,由于 E 的 term 更大,就会被选为 leader,A 在后面的 RPC 中因为自己的 term 较小也会被降为 follower。但是由于A 成为 follower 之后和 E 之间网络不通也会按照上面 E 的方式发起选举成为 leader。A 和 E 反复成为leader。
Raft 给出的解决方法是使用 preVote。想要成为 Candidate 要先进行 preVote 投票。prevote 要求节点在开始选举前,必须先和所有其他节点进行一次通讯,如果超过了半数以上响应才能开始选举。
收到投票请求的节点也需要检查下面2个条件都满足,才会同意发起选举流程:
- 没有收到有效 leader 的心跳,至少有一次选举超时;
- Candidate的日志足够新(Term更大,或者 Term 相同但 WAL的 index 更大);
参考文档:
http://www.jdon.com/artichect/raft.html
http://thesecretlivesofdata.com/raft/
http://www.cnblogs.com/mindwind/p/5231986.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号