高性能网络编程
高性能网络编程
1、建立连接 accept
int accept(int sockfd, struct sockaddr *addr, socklen_t *addrlen);
TCP通过三次握手建立连接,如下图,
当服务器绑定、监听了某个端口后,这个端口的SYN队列和ACCEPT队列就建立好了(在内核中实现)。注意,SYN队列存放的是未建立的连接,数值由内核 /proc/sys/net/ipv4/tcp_max_syn_backlog 参数决定,应用程序无法修改;而ACCEPT队列即listen函数的backlog参数决定,它是ESTABLISHED 状态的连接,这个数值不能超过 /proc/sys/net/core/somaxconn。
客户端使用connect向服务器发起TCP连接,当客户端的SYN包到达了服务器后,内核会把这一信息放到SYN队列(即未完成握手队列)中,同时回一个SYN+ACK包给客户端。一段时间后,客户端再次发来了针对服务器SYN包的ACK网络分组时,内核会把连接从SYN队列中取出,再把这个连接放到ACCEPT队列(即已完成握手队列)中。之后服务器在调用accept()时,其实就是直接从ACCEPT队列中取出已经建立成功的连接套接字而已。

如果上图中第1步执行的速度大于第2步执行的速度,SYN队列就会不断增大直到队列满;如果第2步执行的速度远大于第3步执行的速度,ACCEPT队列同样会达到上限。第1、2步不是应用程序可控的,但第3步却是应用程序的行为,假设进程中调用accept获取新连接的代码段长期得不到执行,例如获取不到锁、IO阻塞等。
另外,应用程序可以把listen时设置的套接字设为非阻塞模式(默认为阻塞模式),这两种模式会导致accept方法有不同的行为。
对阻塞套接字,accept行为如下图:

对非阻塞套接字,accept会有两种返回,如下图:

非阻塞套接字上的accept,不存在等待ACCEPT队列不为空的阶段,它要么返回成功并拿到建立好的连接,要么返回失败。
如果 accept 队列满,client 发来 ack,连接从 syn 队列移到 accept 队列的时候会发生什么呢?
1). 如果 /proc/sys/net/ipv4/tcp_abort_on_overflow 为1,会发送 RST;如果为0,则「什么都不做」,也就是「忽略」。
2). 但是,即使被忽略,对于 SYN RECEIVED 状态, 会有重试,重试次数定义在 /proc/sys/net/ipv4/tcp_synack_retries(重试时间有个算法)。
3). client 在收到 server 发来的重试 synack 之后,它认为之前发给 server 的 ack 丢失,会重发,此时如果 server 的 accept 队列有「空位」,会把连接移到 accpet 队列,并把 SYN RECEIVED 改成 ESTABLISHED。
4). 从另一个角度看, 即使 client 发的 ack 被忽略,因为 client 已经收到了 synack,client 认为连接已经建立,它可能会直接发送数据(ack 和 数据一起发送),这部分数据也会被忽略,会重传,幸好有「慢」启动机制保证重传的数据不会太多。
5). 如果 client 先等待 server 发来的数据,在 client 端连接是 ESTABLISHED,server 认为连接是 CLOSED,这会造成「半连接」。
6). 事实上,如果 accept 队列满了,内核会限制 syn 包的进入速度,如果太快,有些包会被丢弃。
2、消息发送 send
ssize_t send(int sockfd, const void *buf, size_t len, int flags);
在建立的TCP连接上发送消息,可以使用send或者write函数,先看下发送消息时内核在做什么:

当我们调用发送方法时,会把我们代码中构造好的消息流作为参数传递。这个消息流可大可小,例如几个字节,或者几兆字节。当消息流较大时,将有可能出现分片。
我们先来讨论分片问题,数据链路层有一个MTU(最大传输单元)的限制,例如以太网限制为1500字节,802.3限制为1492字节,如果IP层报文长度大于MTU限制,就会被分成若干个小于MTU的报文,每个报文都会有独立的IP头部,如下图:

可以看出,IP头部中指定长度的字段有16位,这意味着一个IP包最大可以是65535字节。
为了避免IP层的分片,TCP协议定义了一个新的概念:MSS(最大报文段长度),它定义了一个TCP连接上,一个主机期望对端主机发送单个报文的最大长度。TCP3次握手建立连接时,连接双方都要互相告知自己期望接收到的MSS大小。
如下图,是TCP三次握手的过程,SYN包携带了期望的MSS大小:

例子中两台主机都在以太网内,MTU=1500,减去IP和TCP头部,MSS就是1460。
send方法的流程可以分为10步:
1、应用程序调用send方法来发送一段较长的数据;
2、内核通过tcp_sendmsg方法来完成;
3-4、内核真正执行报文的发送,与send方法的调用并不是同步的。即,send方法返回成功了,也不一定把IP报文都发送到网络中了。因此,得把需要发送的用户态内存中的数据,拷贝到内核态内存中,也使得进程可以快速释放发送数据占用的用户态内存。但这个拷贝操作并不是简单的复制,而是把待发送数据划分成多个尽量达到MSS大小的分片报文段,复制到内核中的sk_buff 结构来存放,同时把这些分片组成队列,放到这个TCP连接对应的tcp_write_queue发送队列中。
5、内核中为这个TCP连接分配的内核缓存是有限的(/proc/sys/net/core/wmem_default)。当没有多余的内核态缓存来复制用户态的待发送数据时,需要调用sk_stream_wait_memory方法来等待滑动窗口移动,释放出一些缓存出来(收到ACK后,不需要再缓存原来已经发送出的报文,因为既然已经确认对方收到,就不需要定时重发,自然就释放缓存了)。例如:
static inline long sock_sndtimeo(const struct sock *sk, int noblock) { return noblock ? 0 : sk->sk_sndtimeo; } // 等待超时时间,对非阻塞套接字是0,对阻塞套接字由SO_SNDTIMEO选项指定 timeo = sock_sndtimeo(sk, flags & MSG_DONTWAIT); wait_for_memory: if (copied) tcp_push(sk, tp, flags & ~MSG_MORE, mss_now, TCP_NAGLE_PUSH); if ((err = sk_stream_wait_memory(sk, &timeo)) != 0) goto do_error;
tcp_push方法的流程:
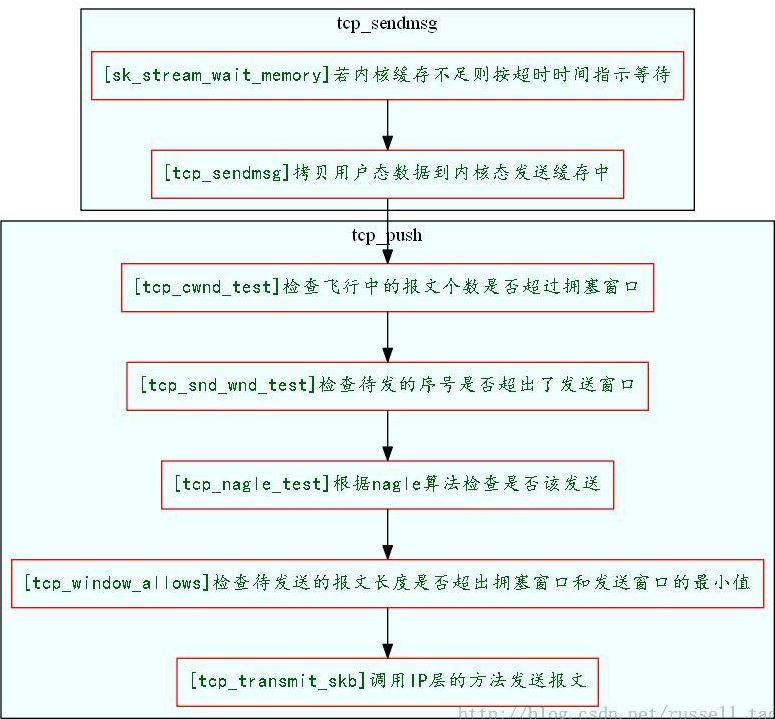
这里有几个概念:
滑动窗口:
TCP连接上的双方都会通知对方自己的接收窗口大小。而对方的接收窗口大小就是自己的发送窗口大小。tcp_push在发送数据时当然需要与发送窗口打交道。发送窗口是一个时刻变化的值,随着ACK的到达会变大,随着发出新的数据包会变小。当然,最大也只能到三次握手时对方通告的窗口大小。tcp_push在发送数据时,最终会使用tcp_snd_wnd_test方法来判断当前待发送的数据,其序号是否超出了发送滑动窗口的大小,例如:
//检查这一次要发送的报文最大序号是否超出了发送滑动窗口大小 static inline int tcp_snd_wnd_test(struct tcp_sock *tp, struct sk_buff *skb, unsigned int cur_mss) { //end_seq待发送的最大序号 u32 end_seq = TCP_SKB_CB(skb)->end_seq; if (skb->len > cur_mss) end_seq = TCP_SKB_CB(skb)->seq + cur_mss; //snd_una是已经发送过的数据中,最小的没被确认的序号;而snd_wnd就是发送窗口的大小 return !after(end_seq, tp->snd_una + tp->snd_wnd); }
慢启动和拥塞窗口:
Nagle算法:
Nagle算法的初衷是这样的:应用进程调用发送方法时,可能每次只发送小块数据,造成这台机器发送了许多小的TCP报文。对于整个网络的执行效率来说,小的TCP报文会增加网络拥塞的可能,因此,如果有可能,应该将相临的TCP报文合并成一个较大的TCP报文(当然还是小于MSS的)发送。Nagle算法要求一个TCP连接上最多只能有一个发送出去还没被确认的小分组,在该分组的确认到达之前不能发送其他的小分组。
内核中是通过 tcp_nagle_test方法实现该算法的。我们简单的看下:
static inline int tcp_nagle_test(struct tcp_sock *tp, struct sk_buff *skb, unsigned int cur_mss, int nonagle) { // nonagle标志位设置了,返回1表示允许这个分组发送出去 if (nonagle & TCP_NAGLE_PUSH) return 1; // 如果这个分组包含了四次握手关闭连接的FIN包,也可以发送出去 if (tp->urg_mode || (TCP_SKB_CB(skb)->flags & TCPCB_FLAG_FIN)) return 1; // 检查Nagle算法, 返回0表示可以发送,返回非0则不可以 if (!tcp_nagle_check(tp, skb, cur_mss, nonagle)) return 1; return 0; } static inline int tcp_nagle_check(const struct tcp_sock *tp, const struct sk_buff *skb, unsigned mss_now, int nonagle) { //先检查是否为小分组,即报文长度是否小于MSS return (skb->len < mss_now && ( (nonagle&TCP_NAGLE_CORK) || (!nonagle // 如果开启了Nagle算法 && tp->packets_out // 若已经有小分组发出(packets_out表示“飞行”中的分组)还没有确认 && tcp_minshall_check(tp)) ) ); } static inline int tcp_minshall_check(const struct tcp_sock *tp) { //最后一次发送的小分组还没有被确认 return after(tp->snd_sml,tp->snd_una) && //将要发送的序号是要大于等于上次发送分组对应的序号 !after(tp->snd_sml, tp->snd_nxt); }
设置TCP_NODELAY选项可以关闭Nagle算法,看看setsockopt是怎么工作的:
static int do_tcp_setsockopt(struct sock *sk, int level, int optname, char __user *optval, int optlen) { switch (optname) { case TCP_NODELAY: if (val) { //如果设置了TCP_NODELAY,则更新nonagle标志 tp->nonagle |= TCP_NAGLE_OFF|TCP_NAGLE_PUSH; tcp_push_pending_frames(sk, tp); } else { tp->nonagle &= ~TCP_NAGLE_OFF; } break; } }
3、消息接收 recv
ssize_t recv(int sockfd, void *buf, size_t len, int flags);
接收TCP消息的过程可以一分为二:
- 网卡接收到的报文,通过软中断,内核拿到并且解析其为TCP报文,然后TCP模块决定如何处理这个TCP报文;
- 用户进程调用read、recv等方法获取TCP消息,则是将内核已经从网卡上收到的消息流拷贝到用户进程里的内存中。
内核在处理接收到的TCP报文时使用了4个队列:
- receive队列,receive队列是允许用户进程直接读取的,它是将已经接收到的TCP报文,去除了TCP头部、排好序放入的、用户进程可以直接按序读取的队列;
- out_of_order队列,存放乱序的报文;
- backlog 队列,临时队列,当socker被锁住时(该socket有进程上下文),网卡收到的报文会放入backlog队列;
- prequeue队列,如果sysctl_tcp_low_latency=1表示系统关闭prequeue队列,这是一个优化队列,可有可无。 并且如果有应用程序正在recvmsg,则才会把数据包放入prequeue中。
第一个场景:
如下图,应用进程使用了阻塞套接字,调用recv等方法时flag标志位为0,用户进程读取套接字时没有发生进程睡眠。
TCP连接上将要收到的消息序号是S1(TCP上的每个报文都有序号),此时操作系统内核依次收到了序号S1-S2的报文、S3-S4、S2-S3的报文,注意后两个包乱序了。之后,用户进程分配了一段len大小的内存用于接收TCP消息,此时,len是大于S4-S1的。另外,用户进程始终没有对这个socket设置过SO_RCVLOWAT参数,因此,接收阀值SO_RCVLOWAT使用默认值1。另外,系统参数tcp_low_latency设置为0,即从操作系统的总体效率出发,使用prequeue队列提升吞吐量。当然,由于用户进程收消息时,并没有新包来临,所以此图中prequeue队列始终为空,先不细表。
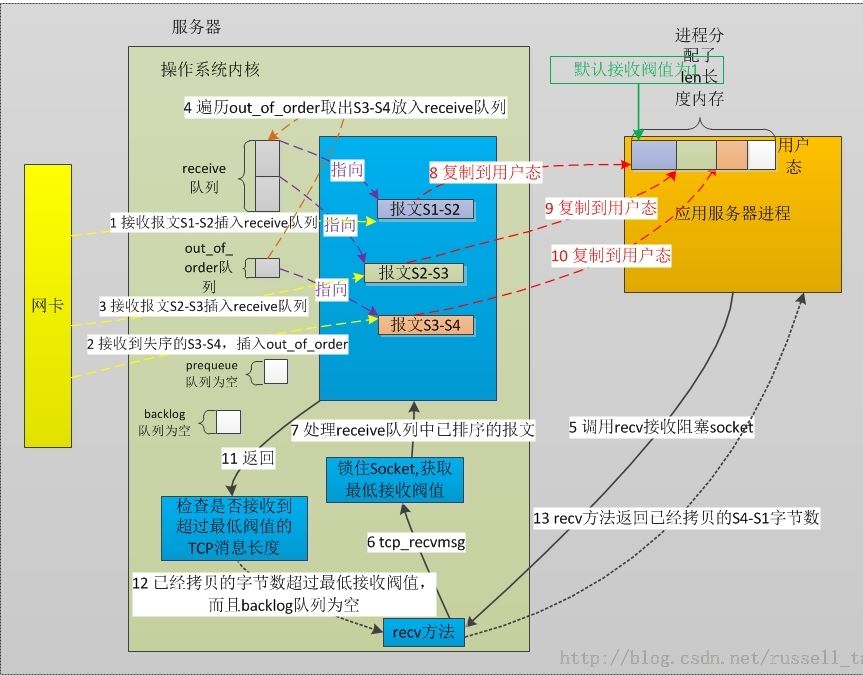
上图的流程可以分为13个步骤:
- 当网卡接收到报文并判断为TCP协议后,将会调用到内核的tcp_v4_rcv方法。此时,这个TCP连接上需要接收的下一个报文序号恰好就是S1,而这一步里,网卡上收到了S1-S2的报文,所以,tcp_v4_rcv方法会把这个报文直接插入到receive队列中;
- 接着收到了S3-S4报文。在第1步结束后,这时我们需要收到的是S2序号,但到来的报文却是S3打头的,怎么办呢?进入out_of_order队列!从这个队列名称就可以看出来,所有乱序的报文都会暂时放在这儿;
- 用户进程仍然没有调用recv来读取socket,但又过来了我们期望的S2-S3报文,它会像第1步一样,直接进入receive队列。不同的时,由于此时out_of_order队列不像第1步是空的,所以,引发了接来的第4步。
- 每次向receive队列插入报文时都会检查out_of_order队列。由于收到S2-S3报文后,期待的序号成为了S3,这样,out_of_order队列里的唯一报文S3-S4报文将会移出本队列而插入到receive队列中(这件事由tcp_ofo_queue方法完成)。
- 用户进程开始读取socket了。做过应用端编程的同学都知道,先要在进程里分配一块内存,接着调用read或者recv等方法,把内存的首地址和内存长度传入,再把建立好连接的socket也传入。当然,对这个socket还可以配置其属性。这里,假定没有设置任何属性,都使用默认值,因此,此时socket是阻塞式,它的SO_RCVLOWAT是默认的1。当然,recv这样的方法还会接收一个flag参数,它可以设置为MSG_WAITALL、MSG_PEEK、MSG_TRUNK等等,这里我们假定为最常用的0。
- C库和内核经过层层封装,接收TCP消息最终一定会走到tcp_recvmsg方法。下面介绍代码细节时,它会是重点。
- 在tcp_recvmsg方法里,会首先锁住socket。为什么呢?因此socket是可以被多进程同时使用的,同时,内核中断也会操作它,而下面的代码都是核心的、操作数据的、有状态的代码,不可以被重入的,锁住后,再有用户进程进来时拿不到锁就要休眠在这了。内核中断看到被锁住后也会做不同的处理。
- 此时,第1-4步已经为receive队列里准备好了3个报文。最上面的报文是S1-S2,将它拷贝到用户态内存中。由于第5步flag参数并没有携带MSG_PEEK这样的标志位,因此,再将S1-S2报文从receive队列的头部移除,从内核态释放掉。反之,MSG_PEEK标志位会导致receive队列不会删除报文。所以,MSG_PEEK主要用于多进程读取同一套接字的情形。
- 如第8步,拷贝S2-S3报文到用户态内存中。当然,执行拷贝前都会检查用户态内存的剩余空间是否足以放下当前这个报文,不足以时会直接返回已经拷贝的字节数。
- 同上。
- receive队列为空了,此时会先来检查SO_RCVLOWAT这个阀值。如果已经拷贝的字节数到现在还小于它,那么可能导致进程会休眠,等待拷贝更多的数据。第5步已经说明过了,socket套接字使用的默认的SO_RCVLOWAT,也就是1,这表明,只要读取到报文了,就认为可以返回了。做完这个检查了,再检查backlog队列。backlog队列是进程正在拷贝数据时,网卡收到的报文会进这个队列。此时若backlog队列有数据,就顺带处理下。
- 在本图对应的场景中,backlog队列是没有数据的,已经拷贝的字节数为S4-S1,它是大于1的,因此,释放第7步里加的锁,准备返回用户态了。
- 用户进程代码开始执行,此时recv等方法返回的就是S4-S1,即从内核拷贝的字节数。
第二个场景:
用户进程调用recv方法时,连接上没有任何接收并缓存到内核的报文,而socket是阻塞的,所以进程睡眠了。然后网卡收到了TCP连接上的报文,此时prequeue队列开始产生作用。
下图中tcp_low_latency为默认的0,套接字socket的SO_RCVLOWAT是默认的1,仍然是阻塞socket,如下图:

- 用户进程分配了一块len大小的内存,将其传入recv这样的函数,同时socket参数皆为默认,即阻塞的、SO_RCVLOWAT为1。调用接收方法,其中flags参数为0;
- C库和内核最终调用到tcp_recvmsg方法来处理;
- 锁住socket;
- 由于此时receive、prequeue、backlog队列都是空的,即没有拷贝1个字节的消息到用户内存中,而我们的最低要求是拷贝至少SO_RCVLOWAT为1长度的消息。此时,开始进入阻塞式套接字的等待流程。最长等待时间为SO_RCVTIMEO指定的时间;
-
这个套接字上期望接收的序号也是S1,此时网卡恰好收到了S1-S2的报文,在tcp_v4_rcv方法中,通过调用tcp_prequeue方法把报文插入到prequeue队列中。
-
插入prequeue队列后,此时会接着调用wake_up_interruptible方法,唤醒在socket上睡眠的进程。
-
用户进程被唤醒后,重新调用lock_sock接管了这个socket,此后再进来的报文都只能进入backlog队列了。
-
进程醒来后,先去检查receive队列,当然仍然是空的;再去检查prequeue队列,发现有一个报文S1-S2,正好是socket连接待拷贝的起始序号S1,于是,从prequeue队列中取出这个报文并把内容复制到用户内存中,再释放内核中的这个报文。
-
目前已经拷贝了S2-S1个字节到用户态,检查这个长度是否超过了最低阀值(即len和SO_RCVLOWAT的最小值)。
-
由于SO_RCVLOWAT使用了默认的1,所以准备返回用户。此时会顺带再看看backlog队列中有没有数据,若有,则检查这个无序的队列中是否有可以直接拷贝给用户的报文。当然,此时是没有的。所以准备返回,释放socket锁。
- 返回用户已经拷贝的字节数。
第三个场景:
这个场景中,我们把系统参数tcp_low_latency设为1,socket上设置了SO_RCVLOWAT属性的值。服务器先是收到了S1-S2这个报文,但S2-S1的长度是小于SO_RCVLOWAT的,用户进程调用recv方法读套接字时,虽然读到了一些,但没有达到最小阀值,所以进程睡眠了,与此同时,在睡眠前收到的乱序的S3-S4包直接进入backlog队列。此时先到达了S2-S3包,由于没有使用prequeue队列,而它起始序号正是下一个待拷贝的值,所以直接拷贝到用户内存中,总共拷贝字节数已满足SO_RCVLOWAT的要求!最后在返回用户前把backlog队列中S3-S4报文也拷贝给用户了。如下图:

上图的流程可以分为15个步骤:
- 内核收到报文S1-S2,S1正是这个socket连接上待接收的序号,因此,直接将它插入有序的receive队列中。
- 用户进程所处的linux操作系统上,将sysctl中的tcp_low_latency设置为1。这意味着,这台服务器希望TCP进程能够更及时的接收到TCP消息。用户调用了recv方法接收socket上的消息,这个socket上设置了SO_RCVLOWAT属性为某个值n,这个n是大于S2-S1,也就是第1步收到的报文大小。这里,仍然是阻塞socket,用户依然是分配了足够大的len长度内存以接收TCP消息。
- 通过tcp_recvmsg方法来完成接收工作。先锁住socket,避免并发进程读取同一socket的同时,也在告诉内核网络软中断处理到这一socket时要有不同行为,如第6步。
- 准备处理内核各个接收队列中的报文。
- receive队列中的有序报文可直接拷贝,在检查到S2-S1是小于len之后,将报文内容拷贝到用户态内存中。
- 在第5步进行的同时,socket是被锁住的,这时内核又收到了一个S3-S4报文,因此报文直接进入backlog队列。注意,这个报文不是有序的,因为此时连接上期待接收序号为S2。
- 在第5步,拷贝了S2-S1个字节到用户内存,它是小于SO_RCVLOWAT的,因此,由于socket是阻塞型套接字(超时时间在本文中忽略),进程将不得不转入睡眠。转入睡眠之前,还会干一件事,就是处理backlog队列里的报文,图2的第4步介绍过休眠方法sk_wait_data,它在睡眠前会执行release_sock方法,看看是如何实现的:
-
进程休眠,直到超时或者receive队列不为空。
-
内核接收到了S2-S3报文。注意,这里由于打开了tcp_low_latency标志位,这个报文是不会进入prequeue队列以待进程上下文处理的。
-
此时,由于S2是连接上正要接收的序号,同时,有一个用户进程正在休眠等待接收数据中,且它要等待的数据起始序号正是S2,于是,这种种条件下,使得这一步同时也是网络软中断执行上下文中,把S2-S3报文直接拷贝进用户内存。
-
上文介绍tcp_data_queue方法时大家可以看到,每处理完1个有序报文(无论是拷贝到receive队列还是直接复制到用户内存)后都会检查out_of_order队列,看看是否有报文可以处理。那么,S3-S4报文恰好是待处理的,于是拷贝进用户内存。然后唤醒用户进程。
-
用户进程被唤醒了,当然唤醒后会先来拿到socket锁。以下执行又在进程上下文中了。
-
此时会检查已拷贝的字节数是否大于SO_RCVLOWAT,以及backlog队列是否为空。两者皆满足,准备返回。
-
释放socket锁,退出tcp_recvmsg方法。
- 返回用户已经复制的字节数S4-S1
MSG_PEEK
MSG_WAITALL
MSG_TRUNK
SO_RCVLOWAT
4、关闭连接 close/shutdown
int close(int fd); int shutdown(int sockfd, int how);
关闭TCP连接时可以考虑下面几个问题:
#define __NR_close 3 __SYSCALL(__NR_close, sys_close) #define __NR_shutdown 48 __SYSCALL(__NR_shutdown, sys_shutdown)
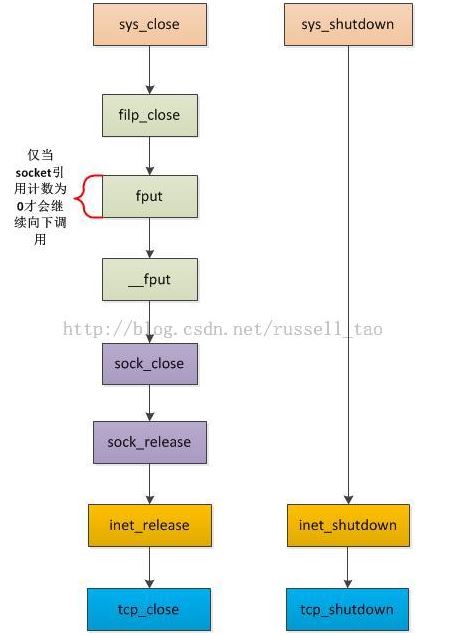
sys_shutdown与多进程无关,而sys_close则不然,上图中可以看到,层层封装调用中有一个方法叫fput,它有一个引用计数,记录这个socket被引用了多少次。在说明多进程调用close的区别前,先在代码上简单看下close是怎么调用的,对内核代码没兴趣的同学可以仅看fput方法:
void fastcall fput(struct file *file) { if (atomic_dec_and_test(&file->f_count))//检查引用计数,直到为0才会真正去关闭socket __fput(file); }
TCP连接是一种双工的连接,何谓双工?即连接双方可以并行的发送或者接收消息,而无须顾及对方此时到底在发还是收消息。这样,关闭连接时,就存在3种情形:
- 完全关闭连接;
- 关闭发送消息的功能;
- 关闭接收消息的功能。
其中,后两者就叫做半关闭,由shutdown实现(所以 shutdown多出一个参数正是控制关闭发送或者关闭接收),前者由close实现。

这个图稍复杂,这是因为它覆盖了关闭监听句柄、关闭普通连接、关闭设置了SO_LINGER的连接这三种主要场景。
1)关闭监听句柄
再看看较为简单的shutdown流程:

参考文档:
http://blog.csdn.net/russell_tao/article/details/9111769
http://blog.csdn.net/russell_tao/article/details/9370109
http://blog.csdn.net/russell_tao/article/details/9950615
http://blog.csdn.net/russell_tao/article/details/13092727

 浙公网安备 33010602011771号
浙公网安备 33010602011771号