跳表
跳表
跳表(skip list)是一种随机化数据结构,基于并联的链表,其效率可比拟于二叉查找树(对于大多数操作需要O(lgN)平均时间);
跳表的构造过程:
- 给定一个有序链表;
- 选择链表中最大和最小的元素,然后从其它元素中按照一定算法随机选出一些元素,将这些元素组成有序链表;这个新的链表称为一层,原链表称为其下一层;
- 为刚选出的每个元素添加一个指针域,这个指针指向下一层中值同自己相等的元素,Top指针指向该层首元素;
- 重复2、3步,直到不再能选择出除最大最小元素以外的元素;
跳表的特征:
1、一个跳表由几个level组成,并且每个level都是一个有序链表,且每个level都包含INT_MIN和INT_MAX两个元素;
2、level 1(第一层)包含所有元素;
3、较高层的元素能在较低的层里找到;
4、第i层元素通过一个down指针指向下一层拥有相同值的元素;
5、Top指针指向最高层的第一个元素;
查找
如下图,构建了一个包含3层的跳表:

假如我们要从这个跳表中找到值为85的元素,首先在Level3 查找到第一个大于该值的节点(如果不存在就用最后一个节点),并往下一层继续查找。
在这个例子中,查找的路径是21--37--71--85。
插入
要在跳表中插入一个节点,先要确定该元素要占据的层数 K(通过随机算法产生),然后在 Level 1 ... Level K 各个层的链表都插入元素。
例子:插入 119, K = 2

如果 K 大于链表的层数,则要添加新的层。
例子:插入 119, K = 4

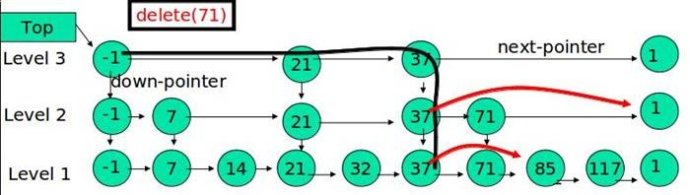
删除
在各个层中找到包含 x 的节点,使用标准的 delete from list 方法删除该节点。
例子:删除 71
跳表和红黑树
一些开源NOSQL数据库,如Redis就使用了skiplist,而非红黑树,这样做
1、skiplist的复杂度和红黑树一样,但实现起来更简单;
2、红黑树在插入和删除的时候可能需要做再平衡,这样的操作可能会涉及到整个树的其他部分,而skiplist的操作显然更加局部性一些,锁需要盯住的节点更少,因此在这样的情况下性能好一些。
======专注高性能web服务器架构和开发=====

 浙公网安备 33010602011771号
浙公网安备 33010602011771号