ElasticSearch之二——集群
ElasticSearch 集群
首先看下ElasticSearch(ES)的架构:

术语解释:
- cluster:代表一个集群,集群中有多个节点,其中有一个master节点,master通过选举自动产生;
- shards:代表索引分片,ES可以把一个完整的索引分成多个分片,并将它们分布到不同的节点上,从而构成分布式索引;
- replicas:代表索引副本,副本可以保证系统的高可用性,当某个节点的某个分片损坏时可以从副本中恢复,此外,多个分片副本还可以起到负载均衡的作用;
- recovery:代表数据恢复,ES在有节点加入或退出时会根据机器的负载对索引分片进行重新分配;
- river:代表ES的一个数据源,它是以插件方式存在的一个ES服务,通过读取river中的数据并把它索引到ES中,官方的river有couchDB、RabbitMQ、Kafka、 Wikipedia等;
- geteway:代表ES索引快照的存储方式,ES默认是把索引存放到内存中,当内存满了再持久化到磁盘。geteway对索引快照进行存储,当这个集群关闭再重新启动时就会从geteway中读取索引备份数据。ES支持多种类型的gateway,如本地文件系统(默认),分布式文件系统(HDFS);
-
discovery.zen,ES自动发现节点的机制,ES是一个基于P2P协议的系统,它先通过广播寻找存在的节点,再通过多播协议来进行节点之间的通信,同时也支持点对点的交互;
- transport,代表ES内部节点之间或集群与客户端的交互方式,默认使用TCP协议,同时支持HTTP协议(json格式)、thrift、servlet、zeroMQ、memcached等传输协议(通过插件方式集成);
ES的分布式操作大多是自动完成的:
1、跨节点平衡集群中各节点的索引与搜索负载;
2、自动复制索引数据以提供冗余副本,防止硬件错误导致数据丢失;
3、自动在节点之间路由,以帮助找到检索的数据;
4、无缝扩展或者恢复集群;
node(节点)是ES运行中的实例,一个或多个具有相同cluster.name的节点构成一个cluster(集群),它们协同工作,共享数据,并共同分担工作负载。
集群中的一个节点会被选为master,它将负责管理集群范畴的变更,例如创建或删除索引,在集群中添加或删除节点,但master无需参与文档层面的变更和搜索,这意味着仅有一个master并不会因流量增长而成为瓶颈。
作为用户,我们可以访问包括master在内的集群中的任一节点,每个节点都知道各个文档的位置,并能够将我们的请求直接转发到拥有我们想要的数据的节点,无论我们访问的是哪个节点它都会控制从拥有数据的节点收集响应的过程,并返回给客户端最终的结果,这一切都是由ES透明管理的。
1、添加索引
在ES中,分片用来分配集群中的数据。把分片想象成一个数据的容器。数据被存储在分片中,然后分片又被分配在集群的节点上。当你的集群扩展或者缩小时,elasticsearch会自动的在节点之间迁移分配分片,以便集群保持均衡。
分片分为 主分片(primary shard) 以及 从分片(replica shard) 两种:
- 主分片,在你的索引中,每一个文档都属于一个主分片。理论上主分片对存储多少数据是没有限制的,但分片的最大数量完全取决于你的实际状况:硬件的配置、文档的大小和复杂度、如何索引和查询你的文档,以及你期望的响应时间。
- 从分片,从分片只是主分片的一个副本,它用于提供数据的冗余副本,在硬件故障时提供数据保护,同时服务于搜索和检索这种只读请求。
索引中的主分片的数量在索引创建后就固定下来了,但是从分片的数量可以随时改变。
接下来,我们在空的单节点集群中上创建一个叫做blogs的索引。一个索引默认设置了5个主分片,但是为了演示,我们这里只设置3个主分片和一组从分片(每个主分片有一个从分片对应):
PUT /blogs { "settings" : { "number_of_shards" : 3, "number_of_replicas" : 1 } }
现在,我们的集群看起来就像下图所示了有索引的单节点集群,这三个主分片都被分配在Node 1。

在ES集群中可以监控统计很多信息,其中最重要的就是:集群健康(cluster health)。它的 status 有 green、yellow、red 三种;
GET /_cluster/health
返回:
{
"cluster_name": "elasticsearch",
"status": "yellow",
"timed_out": false,
"number_of_nodes": 1,
"number_of_data_nodes": 1,
"active_primary_shards": 3,
"active_shards": 3,
"relocating_shards": 0,
"initializing_shards": 0,
"unassigned_shards": 3
}
其中status可以告诉我们当前集群是否处于一个可用的状态。三种颜色分别代表:
| 状态 | 意义 |
|---|---|
green |
所有主分片和从分片都可用 |
yellow |
所有主分片可用,但存在不可用的从分片 |
red |
存在不可用的主要分片 |
集群的健康状况yellow意味着所有的 主分片(primary shards) 启动并且运行了,这时集群已经可以成功的处理任意请求,但是 从分片(replica shards) 没有完全被激活。事实上,当前这3个从分片都处于unassigned(未分配)的状态,它们还未被分配到节点上。在同一个节点上保存相同的数据副本是没有必要的,如果这个节点故障了,就等同于所有的数据副本也丢失了。
2、容错转移
为了提高系统的可用性,生产环境几乎不会使用单节点ES集群。
下面介绍如何使用双节点集群(cluster-two-nodes),只要第二个节点与第一个节点的cluster.name相同(参见./config/elasticsearch.yml文件中的配置),它就能自动发现并加入到第一个节点的集群中。如果没有,请结合日志找出问题所在。这可能是多播(multicast)被禁用,或者防火墙阻止了节点间的通信。
如下图,双节点集群——所有的主分片和从分片都被分配:
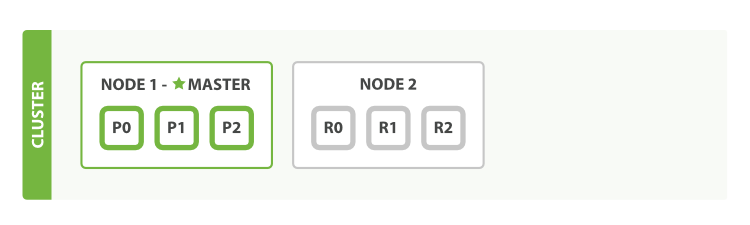
当第二个节点加入后,就产生了三个 从分片(replica shards) ,它们分别于三个主分片一一对应。也就意味着即使有一个节点发生了损坏,我们可以保证数据的完整性。
所有被索引的新文档都会先被存储在主分片中,之后才会被平行复制到关联的从分片上。这样可以确保我们的文档在主节点和从节点上都能被检索。
3、横向扩展
随着应用需求的增长,我们该如何扩展?如果我们启动第三个节点,集群内会自动重组,这时便成为了三节点集群(cluster-three-nodes)。
分片已经被重新分配以平衡负载:
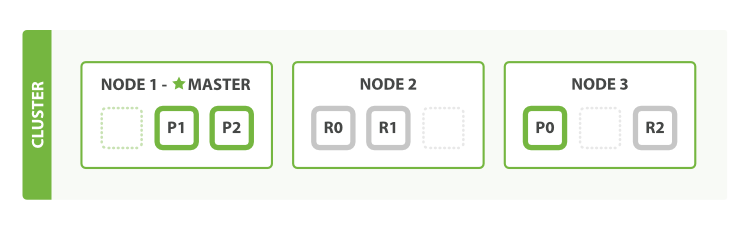
在Node 1和Node 2中分别会有一个分片被移动到Node 3上,这样一来,每个节点上就都只有两个分片了。这意味着每个节点的硬件资源(CPU、RAM、I/O)被更少的分片共享,所以每个分片就会有更好的性能表现。
分片本身就是一个非常成熟的搜索引擎,它可以使用单个节点的所有资源。我们一共有6个节点(3个主分片和3个从分片),因此最多可以扩展到6个节点,每个节点上有一个分片,这样每个分片都可以使用到所在节点100%的资源了。
前面提到,主分片的数量在索引创建时就确定了,而从分片的数量可以随时调整:
PUT /blogs/_settings { "number_of_replicas" : 2 }
将从分片的数量增加到2份:

从图中可以看出,现在blogs的索引总共有9个分片:3个主分片和6个从分片。也就是说,现在我们就可以将总节点数扩展到9个,就又会变成一个节点一个分片的状态了。最终我们得到了三倍搜索性能的三节点集群。
4、故障恢复
如果上面的三节点集群中有一个节点发生故障,例如:

被杀掉的节点是主节点。而为了集群的正常工作必须需要一个主节点,所以首先进行的进程就是从各节点中选择了一个新的主节点:Node 2。
主分片1和2在我们杀掉Node 1后就丢失了,我们的索引在丢失主节点的时候是不能正常工作的。如果我们在这个时候检查集群健康状态,将会显示red:存在不可用的主节点!
幸运的是,丢失的两个主分片的完整拷贝在存在于其他的节点上,所以新的主节点所完成的第一件事情就是将这些在Node 2和Node 3上的从分片提升为主分片,然后集群的健康状态就变回至yellow。这个提升的进程是瞬间完成了,就好像按了一下开关。
那么为什么集群健康状态依然是是yellow而不是green呢?是因为现在我们有3个主分片,但是我们之前设定了1个主分片有2个从分片,但是现在却只有1份从分片,所以状态无法变为green,不过我们可以不用太担心这里:当我们再次杀掉Node 2的时候,我们的程序依旧可以在没有丢失任何数据的情况下运行,因为Node 3中依旧拥有每个分片的备份。
如果我们重启Node 1,集群就能够重新分配丢失的从分片,这样结果就会与三节点两从集群一致。如果Node 1依旧还有旧节点的内容,系统会尝试重新利用他们,并只会复制在故障期间的变更数据。
5、分布式存储
当需要新增一个文档到索引中时,需要为这个文档找到一个主分片进行存储,它按照下面的公式选择主分片:
shard = HASH(文档ID) % 主分片数量
其中,文档ID也可以被替换成其它能唯一表示一个文档的字符串。另外,主分片数量在索引创建时就已经确定了,运行过程中不允许修改,因此,同一个文档总是会被路由到同一个主分片上。
ES集群如果包含多个节点,每个节点都可以服务所有请求,节点可以根据上面的方法计算出当前请求的文档在哪个分片,然后转发请求到该节点上。
参考文档:
http://www.learnes.net/distributed_cluster/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号