Scribe日志收集工具
Scribe日志收集工具
概述
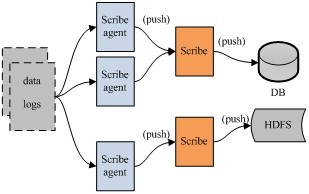
Scribe是facebook开源的日志收集系统,在facebook内部已经得到大量的应用。它能够从各种日志源上收集日志,存储到一个中央存储系统(可以是NFS,分布式文件系统等)上,以便于进行集中统计分析处理。它为日志的“分布式收集,统一处理”提供了一个可扩展的,高容错的方案。当中央存储系统的网络或者机器出现故障时,scribe会将日志转存到本地或者另一个位置,当中央存储系统恢复后,scribe会将转存的日志重新传输给中央存储系统。
scribe的相关资料比较少,主要限于它的主页(见参考资料1)。此外,它的安装比较复杂,可参见《scribe日志收集系统安装方法介绍》。
架构
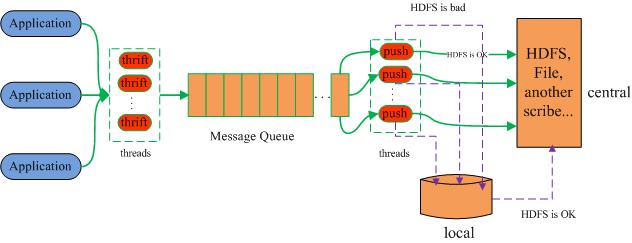
如上图所示,Scribe从各种数据源上收集数据,放到一个共享队列上,然后push到后端的中央存储系统上。当中央存储系统出现故障时,scribe可以暂时把日志写到本地文件中,待中央存储系统恢复性能后,scribe把本地日志续传到中央存储系统上。
需要注意的是,各个数据源须通过thrift向scribe传输数据(每条数据记录包含一个category和一个message)。可以在scribe配置用于监听端口的thrift线程数(默认为3)。在后端,scribe可以将不同category的数据存放到不同目录中,以便于进行分别处理。后端的日志存储方式可以是各种各样的store,包括file(文件),buffer(双层存储,一个主储存,一个副存储),network(另一个scribe服务器),bucket(包含多个store,通过hash的将数据存到不同store中),null(忽略数据),thriftfile(写到一个Thrift TFileTransport文件中)和multi(把数据同时存放到不同store中)。
scribe的全局配置
| global配置 | 默认值 | 说明 |
| port | 0 | 监听端口 |
| max_msg_per_second | 10000 | 每秒处理的最大消息数 |
| max_quque_size | 5000000 | 消息队列的大小 |
| check_interval | 5s | store的检查频率 |
| new_thread_per_category | yes | yes的话,会为每个category建立一个线程来处理 |
| num_thrift_server_threads | 3 | 线程数 |
例如:
port=1463 max_msg_per_second=2000000 max_queue_size=10000000 check_interval=3
store有3种类型:
- 默认store,处理没有匹配到任何store的category; 配置项:category=default
- 带前缀的store,处理所有以指定前缀开头的category;配置项:category=web*
- 复合categories,在一个store里面包含多个category;配置项:categories=rock paper* scissors
store配置
| store 配置 | 默认值 | 说明 |
| category | default | 哪些消息被这个store处理,取值范围:default、、 |
| type | 存储类型,取值范围:file、buffer、network、bucket、thriftfile、null、multi | |
| max_write_interval | 1s | 处理消息队列的时间最小间隔 |
| target_write_size | 16K | 当消息队列超过该值时,才进行处理 |
| max_batch_size | 1MB | 一次处理的数据量 |
| must_succeed | yes | 如果一个处理消息失败,是否重新进入消息队列排队,为no时丢弃该消息 |
例如:
<store> category=statistics type=file target_write_size=20480 max_write_interval=2 </store>
下面介绍不同的store类型:
file
将日志写到文件或者NFS中。目前支持两种文件格式,即std和hdfs,分别表示普通文本文件和HDFS。可配置的选项有:
例如:
<store> category=sprockets type=file file_path=/tmp/sprockets base_filename=sprockets_log max_size=1000000 add_newlines=1 rotate_period=daily rotate_hour=0 rotate_minute=10 max_write_size=4096 </store>
配置解释:
| file store 配置 | 默认值 | 说明 |
| file_path | /tmp | 文件保存路径 |
| base_filename | category name | |
| use_hostname_sub_directory | no | 为yes的话,使用hostname来创建子目录 |
| sub_directory | 使用指定的名字来创建子目录 | |
| rotate_period | 创建新文件的频率 | 可以使用"s"、"m"、"h"、"d"、"w"后缀(秒、分、时、天、周) |
| rotate_hour | 1 | 如果totate_period为d,则取值范围:0-23 |
| rotate_minute | 15 | 如果totate_period为m,则取值范围:0-59 |
| max_size | 1GB | 当文件超过指定大小时进行回滚 |
| write_meta | FALSE | 文件回滚时,最后一行包含下一个文件的名字 |
| fs_type | std | 取值范围:"std"和"hdfs" |
| chunk_size | 0 | 数据块大小,如果消息不超过数据块容量,就不应该跨chunk存储 |
| add_newlines | 0 | 为1时,为每个消息增加一个换行 |
| create_symlink | yes | 创建一个链接,指向最新的一个写入文件 |
| write_stats | yes | 创建一个状态文件,记录每个store的写入情况 |
| max_write_size | 1MB | 缓冲区大小,超过这个值进行flush。该值不能超过max_size配置项的值 |
network
network store转发消息到其他scribe服务器上,scribe以长连接的方式批量转发消息。
例如:
<store> category=default type=network remote_host=hal remote_port=1465 </store>
配置解释:
| scribe store 配置 | 默认值 | 说明 |
| remote_host | 远程主机地址 | |
| remote_port | 远程主机端口 | |
| timeout | 5000ms | socket超时时间 |
| use_conn_pool | FALSE | 是否使用连接池 |
buffer
buffer stores有两个子stores,分别为"primary"和"secondary",当primary store不可用时,才将日志写入secondary store(只能是File Stores或Null Stores)。当primary store恢复工作时,会从secondary store恢复数据(除非replay_buffer=no)。
例如:
<store> category=default type=buffer buffer_send_rate=1 retry_interval=30 retry_interval_range=10 <primary> type=network remote_host=wopr remote_port=1456 </primary> <secondary> type=file file_path=/tmp base_filename=thisisoverwritten max_size=10000000 </secondary> </store>
配置解释:
| buffer store 配置 | 默认值 | 说明 |
| buffer_send_rate | 1 | 在一次check_interval中,从secondary读取多少次消息并发到primary |
| retry_interval | 300s | 在写primary失败后,指定重试的时间间隔 |
| retry_interval_range | 60s | 在写primary失败后,重试的时间间隔在一个时间范围内随机选择一个 |
| replay_buffer | yes | 是否将secondary的消息恢复到primary |
null
丢弃指定category的消息;
例如:
<store> category=tps_report* type=null </store>
bucket
bucket stores将每个消息的前缀作为key,并hash到多个文件中。
例如:
<store>
category=bucket_me
type=bucket
num_buckets=2
bucket_type=key_hash
<bucket0>
type=file
fs_type=std
file_path=/tmp/scribetest/bucket0
base_filename=bucket0
</bucket0>
<bucket1>
...
</bucket1>
<bucket2>
...
</bucket2>
</store>
配置解释:
| bucket store 配置 | 默认值 | 说明 |
| num_buckets | 1 | hash表的bucket个数 |
| bucket_type | 取值范围:key_hash、key_modulo、random | |
| delimiter | : | 识别key的前缀分隔符 |
| remove_key | no | 是否删除每个消息的前缀 |
| bucket_subdir | 每个子目录的名字 |
multi
multi store将消息同时转发给多个子sotres(如store0, store1, store2, ...)。
例如:
<store> category=default type=multi target_write_size=20480 max_write_interval=1 <store0> type=file file_path=/tmp/store0 </store0> <store1> type=file file_path=/tmp/store1 </store1> </store>
Thriftfile
Thriftfile store与File store类似,只是前者将消息发送给Thrift TFileTransport 文件;
例如:
<store> category=sprockets type=thriftfile file_path=/tmp/sprockets base_filename=sprockets_log max_size=1000000 flush_frequency_ms=2000 </store>
配置解释:
| thriftfile store 配置 | 默认值 | 说明 |
| file_path | /tmp | 文件保存路径 |
| base_filename | category name | |
| rotate_period | 创建新文件的频率 | 可以使用"s"、"m"、"h"、"d"、"w"后缀(秒、分、时、天、周) |
| rotate_hour | 1 | 如果totate_period为d,则取值范围:0-23 |
| rotate_minute | 15 | 如果totate_period为m,则取值范围:0-59 |
| max_size | 1GB | 当文件超过指定大小时进行回滚 |
| fs_type | std | 取值范围:"std"和"hdfs" |
| chunk_size | 0 | 数据块大小,如果消息不超过数据块容量,就不应该跨chunk存储 |
| create_symlink | yes | 创建一个链接,指向最新的一个写入文件 |
| flush_frequency_ms | 3000ms | 同步Thrift file 到磁盘的频率 |
| msg_buffer_size | 0 | 非0时,拒绝所有大于该值的写入 |
参考文档:
http://dongxicheng.org/search-engine/scribe-installation/
http://dongxicheng.org/search-engine/scribe-intro/
http://blog.octo.com/en/scribe-a-way-to-aggregate-data-and-why-not-to-directly-fill-the-hdfs/
https://github.com/facebookarchive/scribe/wiki/Scribe-Configuration

 浙公网安备 33010602011771号
浙公网安备 33010602011771号