mysql 索引及其原理
mysql 索引
KEY与INDEX的区别:
KEY is something on the logical level, describes your table and database design.
INDEX is something on the physical level, helps improve access time for table operations.
KEY是关系模型理论中的一部份,比如有主键(Primary Key),外键(Foreign Key)等,用于数据完整性检查与唯一性约束等。
而Index则处于实现层面,比如可以对表个的任意列建立索引,那么当建立索引的列处于Select语句中的Where条件中时,就可以得到快速的数据定位,从而快速检索。至于Unique Index,则只是属于Index中的一种而已,建立了Unique Index表示此列数据不可重复。
注意:对于MySQL而言,术语"Index"和"Key"经常是混用的。
索引原理
磁盘与IO预读
先简单介绍一下磁盘IO和预读,磁盘读取数据靠的是机械运动,每次读取数据花费的时间可以分为寻道时间、旋转延迟、传输时间三个部分。
- 寻道时间指的是磁臂移动到指定磁道所需要的时间,主流磁盘一般在5ms以下;
- 旋转延迟就是我们经常听说的磁盘转速,比如一个磁盘7200转,表示每分钟能转7200次,也就是说1秒钟能转120次,旋转延迟就是1/120/2 = 4.17ms;
- 传输时间指的是从磁盘读出或将数据写入磁盘的时间,一般在零点几毫秒,相对于前两个时间可以忽略不计。
那么访问一次磁盘的时间,即一次磁盘IO的时间约等于5+4.17 = 9ms左右,听起来还挺不错的,但要知道一台500 -MIPS的机器每秒可以执行5亿条指令,因为指令依靠的是电的性质,换句话说执行一次IO的时间可以执行40万条指令,数据库动辄十万百万乃至千万级数据,每次9毫秒的时间,显然是个灾难。
考虑到磁盘IO是非常高昂的操作,计算机操作系统做了一些优化,当一次IO时,不光把当前磁盘地址的数据,而是把相邻的数据也都读取到内存缓冲区内,因为局部预读性原理告诉我们,当计算机访问一个地址的数据的时候,与其相邻的数据也会很快被访问到。每一次IO读取的数据我们称之为一页(page)。具体一页有多大数据跟操作系统有关,一般为4k,也就是我们读取一页内的数据时候,实际上才发生了一次IO,这个理论对于索引的数据结构设计非常有帮助。
b+树
索引需要什么样的数据结构呢,其实很简单,那就是:每次查找数据时把磁盘IO次数控制在一个很小的数量级,最好是常数数量级。那么我们就想到如果一个高度可控的多路搜索树是否能满足需求呢?就这样,b+树应运而生。
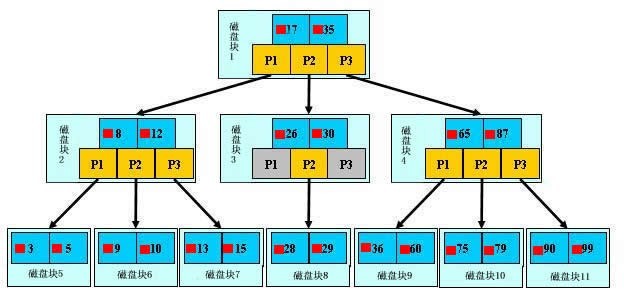
如上图,是一棵B+树。
浅蓝色的块我们称之为一个磁盘块,可以看到每个磁盘块包含几个数据项(深蓝色所示)和指针(黄色所示),如磁盘块1包含数据项17和35,包含指针P1、P2、P3,P1表示小于17的磁盘块,P2表示在17和35之间的磁盘块,P3表示大于35的磁盘块。真实的数据存在于叶子节点即3、5、9、10、13、15、28、29、36、60、75、79、90、99。非叶子节点只不存储真实的数据,只存储指引搜索方向的数据项,如17、35并不真实存在于数据表中。
如图所示,如果要查找数据项29,那么首先会把磁盘块1由磁盘加载到内存,此时发生一次IO,在内存中用二分查找确定29在17和35之间,锁定磁盘块1的P2指针,内存时间因为非常短(相比磁盘的IO)可以忽略不计,通过磁盘块1的P2指针的磁盘地址把磁盘块3由磁盘加载到内存,发生第二次IO,29在26和30之间,锁定磁盘块3的P2指针,通过指针加载磁盘块8到内存,发生第三次IO,同时内存中做二分查找找到29,结束查询,总计三次IO。真实的情况是,3层的b+树可以表示上百万的数据,如果上百万的数据查找只需要三次IO,性能提高将是巨大的,如果没有索引,每个数据项都要发生一次IO,那么总共需要百万次的IO,显然成本非常非常高。
通过上面的分析,我们知道IO次数取决于b+数的高度h,假设当前数据表的数据为N,每个磁盘块的数据项的数量是m,则有h=㏒(m+1)N,当数据量N一定的情况下,m越大,h越小;而m = 磁盘块的大小 / 数据项的大小,磁盘块的大小也就是一个数据页的大小,是固定的,如果数据项占的空间越小,数据项的数量越多,树的高度越低。这就是为什么每个数据项,即索引字段要尽量的小,比如int占4字节,要比bigint8字节少一半。这也是为什么b+树要求把真实的数据放到叶子节点而不是内层节点,一旦放到内层节点,磁盘块的数据项会大幅度下降,导致树增高。当数据项等于1时将会退化成线性表。
当b+树的数据项是复合的数据结构,比如(name,age,sex)的时候,b+数是按照从左到右的顺序来建立搜索树的,比如当(张三,20,F)这样的数据来检索的时候,b+树会优先比较name来确定下一步的所搜方向,如果name相同再依次比较age和sex,最后得到检索的数据;但当(20,F)这样的没有name的数据来的时候,b+树就不知道下一步该查哪个节点,因为建立搜索树的时候name就是第一个比较因子,必须要先根据name来搜索才能知道下一步去哪里查询。比如当(张三,F)这样的数据来检索时,b+树可以用name来指定搜索方向,但下一个字段age的缺失,所以只能把名字等于张三的数据都找到,然后再匹配性别是F的数据了, 这个是非常重要的性质,即索引的最左匹配特性。
如何使用索引
简而言之,INDEX是为实现基于数据列的快速检索(fast retrieval)而设计的。虽然索引可以加快数据检索操作,但会使数据修改操作变慢。每当修改数据记录,索引就必须刷新一次。为了在某种程度上弥补这一缺陷,许 多SQL命令都有一个DELAY_KEY_WRITE项,这个选项的作用是暂时制止MySQL在每插入一条新行和每修改一条现有行之后立刻对索引进行刷新,对索引的刷新将等到全部记录插入/修改完毕之后再进行。另外,索引还会在硬盘上占用相当大的空间。因此应该只为最经常查询和最经常排序的数据列建立索引。
Mysql使用索引的方式有以下几种:
1、在SELECT操作中,把与WHERE子句中所给出的条件相匹配的数据行尽快找出来;
2、使用MIN()或MAX()函数的查询,如果数据列带索引,那么它的最小值和最大值能被迅速找到而不用逐行检查;
3、使用索引也可以迅速完成ORDER BY子句和GROUP BY子句的分类和分组操作;
4、对那些仅需要使用带索引的数据列的场合,可以直接从索引文件读取到数据,甚至不用去读数据文件;
5、在运行联接多个数据表的查询时,索引也可以发挥很大作用;
综上,最适合有索引的数据列是那些出现在WHERE子句/ORDER BY子句/GROUP BY子句的字段,以及在联接子句中出现的字段,例如:
SELECT col_a --> not a candidate FROM tbl1 INNER JOIN tbl2 ON tbl1.col_b = tbl2.col_c -->candidates WHERE col_d = expr; ---> a candidate
挑选索引的思路:
1、尽量选择区分度高的列作为索引
区分度的公式是count(distinct col)/count(*),表示字段不重复的比例,比例越大我们扫描的记录数越少,唯一键的区分度是1。
比如说,假设有一张包含1000万数据的银行客户信息表,年龄这个字段的取值在1-100平均分布,那么对年龄字段建立索引可以很很快捷的找到30岁的客户群(大概包含10万行数据);但如果对性别建立索引,并查询所有男性客户群,这大概有500万行数据,索引的意义就不大了,还不如直接全表扫描;
2、索引列不能参与计算,保持列“干净”
比如from_unixtime(create_time) = ’2014-05-29’就不能使用到索引,原因很简单,b+树中存的都是数据表中的字段值,但进行检索时,需要把所有元素都应用函数才能比较,显然成本太大。所以语句应该写成create_time = unix_timestamp(’2014-05-29’)。
3、最左前缀匹配(对复合索引要特别注意字段顺序)
mysql会一直向右匹配直到遇到范围查询(>、<、between、like)就停止匹配,比如a = 1 and b = 2 and c > 3 and d = 4 如果建立(a,b,c,d)顺序的索引,d是用不到索引的,如果建立(a,b,d,c)的索引则都可以用到,a,b,d的顺序可以任意调整。
例如一个数据表的复合索引是province+city+zip,即省份+城市+邮编的组合,该索引能够用来查询下面的数据列的组合:
province=a and city=b and zip=c
province=a and city=b
province=a
如果搜索的是一个给定的city+zip,索引就不能使用了。
4、尽量的扩展索引,不要新建索引
每一个多出的索引都要占据额外的磁盘空间,而且都会影响写入操作的性能。
例如:如果想对已经存在了一个复合索引的数据表的某个数据列新建索引时,需要先看下该字段是否是复合索引最左边的数据列,如果是这样的话,就没有必要了。
5、选择合适的索引类型
InnoDB/MyISAM存储引擎通常使用“B树”索引结构,MEMORY存储引擎默认使用散列索引。
散列索引在使用<>、!= 操作符进行的精确匹配比较操作速度极快,但不擅长范围比较操作。
B树索引在使用<、<=、=、>、>=、<>、!= 和 BETWEEN 操作符进行的精确比较操作或范围比较操作里都很有效率。
6、利用“慢查询”日志。
如果在“慢查询”日志里面经常看到某个查询命令,应该尝试改写它以加快其运行速度。
MySQL索引操作的语法
MySQL 可以创建好几种索引,如下所示:
1、唯一索引,这种索引不允许索引项(包括单列索引和复合索引)本身出现重复的值。
2、普通索引,允许索引值出现重复;
3、FULLTEXT索引,只适用于MyISAM数据表,用来进行全文检索。
4、SPATIAL索引,只适用于MyISAM数据表和空间(spatial)数据类型;
5、HASH索引,MEMORY数据表的默认索引类型,利用散列索引进行精确值查询的速度非常快。不过如果打算用一个MEMORY数据表进行范围比较(如id<100),散列索引的性能就比较差了,这种情况下可以改用BTREE索引,例如:
CREATE TABLE namelist { id INT NOT NULL, name CHAR(100), INDEX USING BTREE(id) }ENGINE=MEMORY;
可以在使用CREATE TABLE 语句创建新数据表时创建索引,例如:
CREATE TABLE tbl_name{
... column definitions ...
INDEX index_name(index_columns),
UNIQUE index_name(index_columns),
PRIMARY KEY(index_columns),
FULLTEXT index_name(index_columns),
SPATIAL index_name(index_columns),
}
也可以用ALTER TABLE或CREATE INDEX语句给现有数据表添加索引,例如:
CREATE INDEX index_name ON tbl_name (index_columns);
CREATE UNIQUE INDEX index_name ON tbl_name (index_columns);
CREATE FULLTEXT INDEX index_name ON tbl_name (index_columns);
CREATE SPATIAL INDEX index_name ON tbl_name (index_columns);
ALTER TABLE tbl_name ADD INDEX index_name(index_columns);
ALTER TABLE tbl_name ADD UNIQUE index_name(index_columns);
ALTER TABLE tbl_name ADD PRIMARY KEY (index_columns);
ALTER TABLE tbl_name ADD FULLTEXT index_name(index_columns);
ALTER TABLE tbl_name ADD SPATIAL index_name(index_columns);
在ALTER语句中,索引本身的名字"index_name"是可选的,如果没有给出,MySQL将根据第一个带索引的数据列给它挑选一个名字。
删除索引:
DROP INDEX `index_name` ON tbl_name;
ALTER TABLE tbl_name DROP INDEX index_name;
ALTER TABLE tbl_name DROP PRIMARY KEY;
如果想限制某个索引只包含独一无二的值,可以使用PRIMARY KEY或UNIQUE索引,这两种索引的区别是:
1、每个数据表只能有一个PRIMARY KEY,而UNIQUE索引可以有多个;
2、PRIMARY KEY不允许包含NULL值,而UNIQUE索引可以;
可以只对某个字符串类型字段的一个前缀进行索引,例如:
CREATE TABLE address_list {
name CHAR(30) NOT NULL,
address BINARY(60) NOT NULL,
INDEX(name(10)),
INDEX(address(15))
}
它对CHAR字段的前10个字符和BINARY字段的前15个字节编制了索引。
注意:
1、BLOB或TEXT字段只能创建前缀型索引;
2、索引项本身的长度等于构成索引的各个字段的长度总和,如果这个长度超过了索引项本身所能容纳的最大字节数,可以通过前缀索引来缩短长度;
聚集索引和非聚集索引
聚集索引(clustered index)中键值的逻辑顺序决定了表中相应行的物理顺序。
非聚集索引(nonclustered index)中索引的逻辑顺序与磁盘上行的物理存储顺序不同。
聚集索引确定表中数据的物理顺序。聚集索引类似于电话簿,后者按姓氏排列数据。由于聚集索引规定数据在表中的物理存储顺序,因此一个表只能包含一个聚集索引。但该索引可以包含多个列(组合索引),就像电话簿按姓氏和名字进行组织一样。
对MyISAM引擎而言,索引文件和数据文件时分离的(聚集索引和表文件也是分离的),聚集索引和非聚集索引的叶节点都存的是指向数据文件的指针;可见,MyIsAM可以没有主键;
对InnoDB引擎而言,聚集索引的叶节点就是数据节点(聚集索引文件即表文件);而非聚簇索引的叶节点是主键,取出来之后需要再走一遍聚集索引。
对InnoDB引擎而言,决定聚集索引的顺序如下:
- primary key;
- 第一个不为空的unique索引;
- 生成一个隐藏的主键(DB_ROW_ID);
聚集索引对于那些经常要搜索范围值的列特别有效。使用聚集索引找到包含第一个值的行后,便可以确保包含后续索引值的行在物理相邻。例如,如果应用程序执行 的一个查询经常检索某一日期范围内的记录,则使用聚集索引可以迅速找到包含开始日期的行,然后检索表中所有相邻的行,直到到达结束日期。这样有助于提高此 类查询的性能。同样,如果对从表中检索的数据进行排序时经常要用到某一列,则可以将该表在该列上聚集(物理排序),避免每次查询该列时都进行排序,从而节 省成本。
当索引值唯一时,使用聚集索引查找特定的行也很有效率。例如,使用唯一雇员 ID 列 emp_id 查找特定雇员的最快速的方法,是在 emp_id 列上创建聚集索引或 PRIMARY KEY 约束。
| 动作描述 | 使用聚集索引 | 使用非聚集索引 |
| 列经常被分组排序 | 应 | 应 |
| 返回某范围内的数据 | 应 | 不应 |
| 一个或极少不同值 | 不应 | 不应 |
| 小数目的不同值 | 应 | 不应 |
| 大数目的不同值 | 不应 | 应 |
| 频繁更新的列 | 不应 | 应 |
| 外键列 | 应 | 应 |
| 主键列 | 应 | 应 |
| 频繁修改索引列 | 不应 | 应 |
表有两种组织方式,B树(Balance Tree)或者堆(Heap)。当在表上创建了一个聚集索引的时候,整个表数据就以B树的结构排列。否则就是按照堆的结构排列。无论表是怎么组织的,都可以在表上面创建多个非聚集索引。非聚集索引都是以B树的结构排列。
参考文档:
https://tech.meituan.com/2014/06/30/mysql-index.html
http://www.tuicool.com/articles/ZRN3qu

 浙公网安备 33010602011771号
浙公网安备 33010602011771号