TF-IDF 加权及其应用
TF-IDF 加权及其应用
TF-IDF(term frequency–inverse document frequency)是一种用于资讯检索的常用加权技术。TF-IDF是一种统计方法,用以评估某个单词对于一个文档集合(或一个语料库)中的其中一份文件的重要程度。单词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。TF-IDF加权的各种形式常被搜寻引擎应用,作为文件与用户查询之间相关程度的度量或评级。
一、原理
在一份给定的文件里,词频 (term frequency, TF) 指的是某一个给定的单词在该文件中出现的次数。这个数字通常会被归一化,以防止它偏向长的文件(同一个单词在长文件里可能会比短文件有更高的词频,而不管该词语重要与否)。
逆向文件频率 (inverse document frequency, IDF) 是一个单词普遍重要性的度量。某一特定单词的IDF,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取对数得到。IDF是一个全局因子,其考虑的不是文档本身的特征,而是特征单词之间的相对重要性。特征词出现在其中的文档数目越多,IDF值越低,这个词区分不同文档的能力就越差。
IDF(w)=log(n/docs(w, D))
TF-IDF的主要思想是:如果某个单词在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。
二、应用
1、搜索引擎
2、自动提取关键词
比如我们要想提取一篇新闻的关键词,先要对该新闻进行分词,然后根据TF-IDF计算每个单词的权重,并将权重最大的N个单词作为此新闻的关键词。
3、找出相似文章
计算大概过程如下(更详细内容可参考这里):
- 使用TF-IDF算法,找出两篇文章的关键词;
- 每篇文章各取出若干个关键词(比如20个),合并成一个集合,计算每篇文章对于这个集合中的词的词频(为了避免文章长度的差异,可以使用相对词频);
- 生成两篇文章各自的词频向量;
- 计算两个向量的余弦相似度(如下图),值越大就表示越相似。
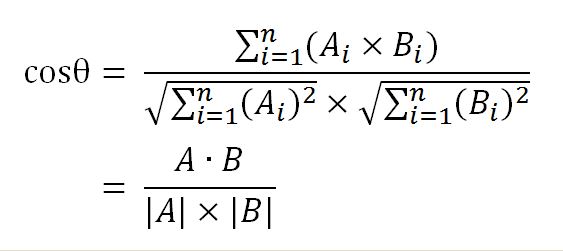
4、自动摘要
2007年,美国学者的论文《A Survey on Automatic Text Summarization》(Dipanjan Das, Andre F.T. Martins, 2007)总结了目前的自动摘要算法。其中很重要的一种就是词频统计,这种方法最早出自1958年的IBM公司科学家H.P. Luhn的论文《The Automatic Creation of Literature Abstracts》。
Luhn博士认为,文章的信息都包含在句子中,有些句子包含的信息多,有些句子包含的信息少。"自动摘要"就是要找出那些包含信息最多的句子。句子的信息量用"关键词"来衡量。如果包含的关键词越多,就说明这个句子越重要。Luhn提出用"簇"(cluster)表示关键词的聚集。所谓"簇"就是包含多个关键词的句子片段。

上图就是Luhn原始论文的插图,被框起来的部分就是一个"簇"。只要关键词之间的距离小于"门槛值",它们就被认为处于同一个簇之中。Luhn建议的门槛值是4或5。也就是说,如果两个关键词之间有5个以上的其他词,就可以把这两个关键词分在两个簇。
下一步,对于每个簇,都计算它的重要性分值。

以前图为例,其中的簇一共有7个词,其中4个是关键词。因此,它的重要性分值等于 ( 4 x 4 ) / 7 = 2.3。
然后,找出包含分值最高的簇的句子(比如5句),把它们合在一起,就构成了这篇文章的自动摘要。
PS:Luhn的这种算法后来被简化,不再区分"簇",只考虑句子包含的关键词。
参考文档:
http://www.cnblogs.com/biyeymyhjob/archive/2012/07/17/2595249.html
http://www.ruanyifeng.com/blog/2013/03/tf-idf.html
http://www.ruanyifeng.com/blog/2013/03/cosine_similarity.html
http://www.ruanyifeng.com/blog/2013/03/automatic_summarization.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号