Java 线程池
线程
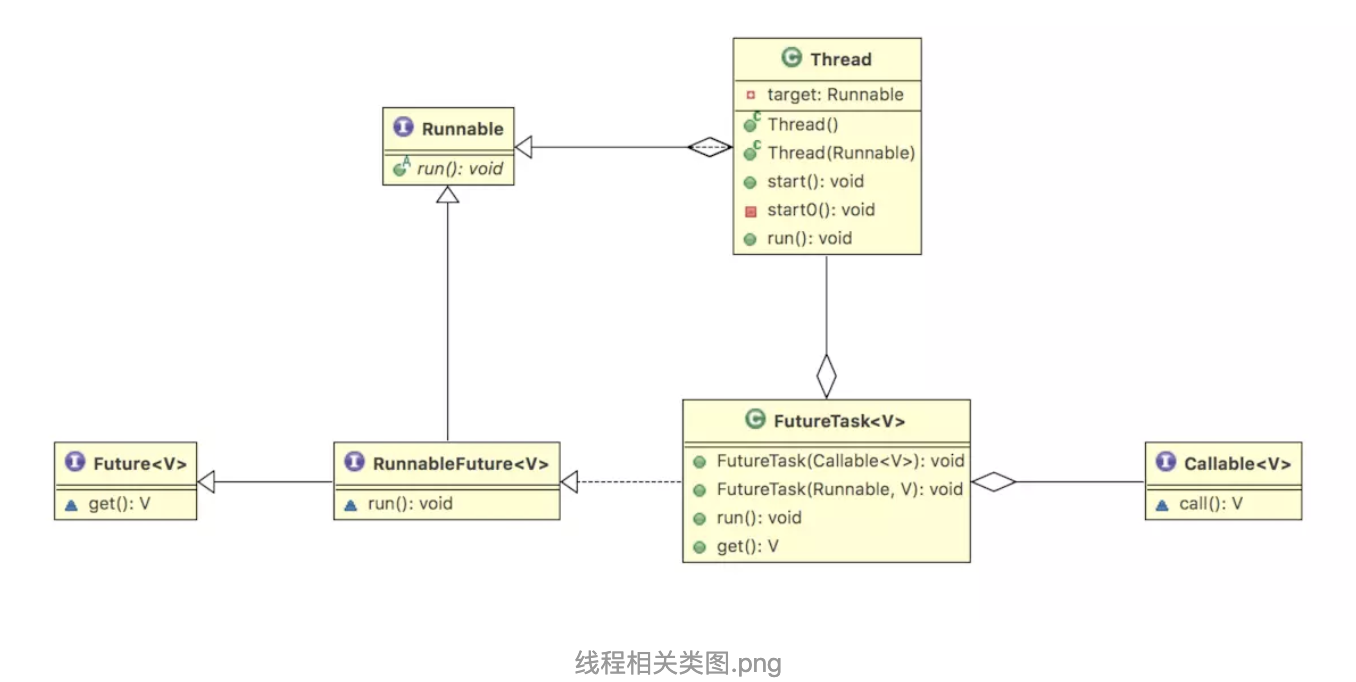
Java多线程,皆始于Thread。Thread是多线程的根,每一个线程的开启都始于Thread的start()方法。
Runnable
看一个例子:
Thread thread = new Thread(new Runnable() { @Override public void run() { System.out.println("thread begin..."); try { Thread.sleep(1000 * 30); } catch (Exception e) { } System.out.println("thread end"); } }); thread.start(); try { thread.join(); } catch (Exception e) { } System.out.println("main done");
new 一个 Thread,然后调用其 start() 方法,会启动一个线程并使线程进入了就绪状态,当分配到时间片后就可以开始运行了。 start() 会执行线程的相应准备工作,然后自动执行 run() 方法的内容。 如果直接执行Thread的 run() 方法,会把 run 方法当成一个 main 线程下的普通方法去执行,并不会在某个线程中执行它。
调用 start 方法方可启动线程并使线程进入就绪状态,而 run 方法只是 thread 的一个普通方法调用,还是在主线程里执行,此外:
- start方法用synchronized修饰,为同步方法;
- 虽然为同步方法,但不能避免多次调用问题,用threadStatus来记录线程状态,如果线程被多次start会抛出异常;threadStatus的状态由JVM控制。
- 使用Runnable时,主线程无法捕获子线程中的异常状态。线程的异常,应在线程内部解决。
Callable
FutureTask<String> futureTask = new FutureTask<>(new Callable<String>() { @Override public String call() throws Exception { return "hello world!"; } }); Thread thread = new Thread(futureTask); thread.start(); try { String result = futureTask.get(); System.out.println(result); } catch (Exception e) { } System.out.println("main done");
中止线程
如果用Thread.stop()方法中止一个正在运行的线程:
public class MyThread { public static void main(String[] args) throws InterruptedException { StopThread thread = new StopThread(); thread.start(); // 休眠1秒,确保线程进入运行 Thread.sleep(1000); // 暂停线程 thread.stop(); //thread.interrupt(); // 确保线程已经销毁 while (thread.isAlive()) { } thread.print(); } private static class StopThread extends Thread { private int x = 0; private int y = 0; @Override public void run() { // 这是一个同步原子操作 synchronized (this) { ++x; try { // 休眠3秒,模拟耗时操作 Thread.sleep(3000); } catch (InterruptedException e) { e.printStackTrace(); } ++y; } } public void print() { System.out.println("x=" + x + " y=" + y); } } }
运行结果:
x=1 y=0
线程没有抛出异常,如果把stop改成interrupt,那么运行结果变为
x=1 y=1
java.lang.InterruptedException: sleep interrupted
at java.lang.Thread.sleep(Native Method)
at com.meitu.helloworld.MyThread$StopThread.run(MyThread.java:34)
stop() 方法事实上已被废弃,它对线程的强制中断是不可预期的。
interrupt() 方法是一个比较温柔的做法,它更类似一个标志位。它不能中断线程,而是「通知线程应该中断了」,具体到底中断还是继续运行,应该由被通知的线程自己处理:
具体来说,当对一个线程,调用 interrupt() 时,
- 如果线程处于被阻塞状态(例如处于sleep, wait, join 等状态),那么线程将立即退出被阻塞状态,并抛出一个InterruptedException异常,仅此而已。
- 如果线程处于正常活动状态,那么会将该线程的中断标志设置为 true,仅此而已。被设置中断标志的线程将继续正常运行,不受影响。
- 在正常运行任务时,经常检查本线程的中断标志位,如果被设置了中断标志就自行停止线程;
- 在调用阻塞方法时正确处理InterruptedException异常;
最后,总结下创建Thread的三种方法:
- 继承Thread类,重写run方法;
- 实现Runnable的run方法;
- 实现Callable的call方法;
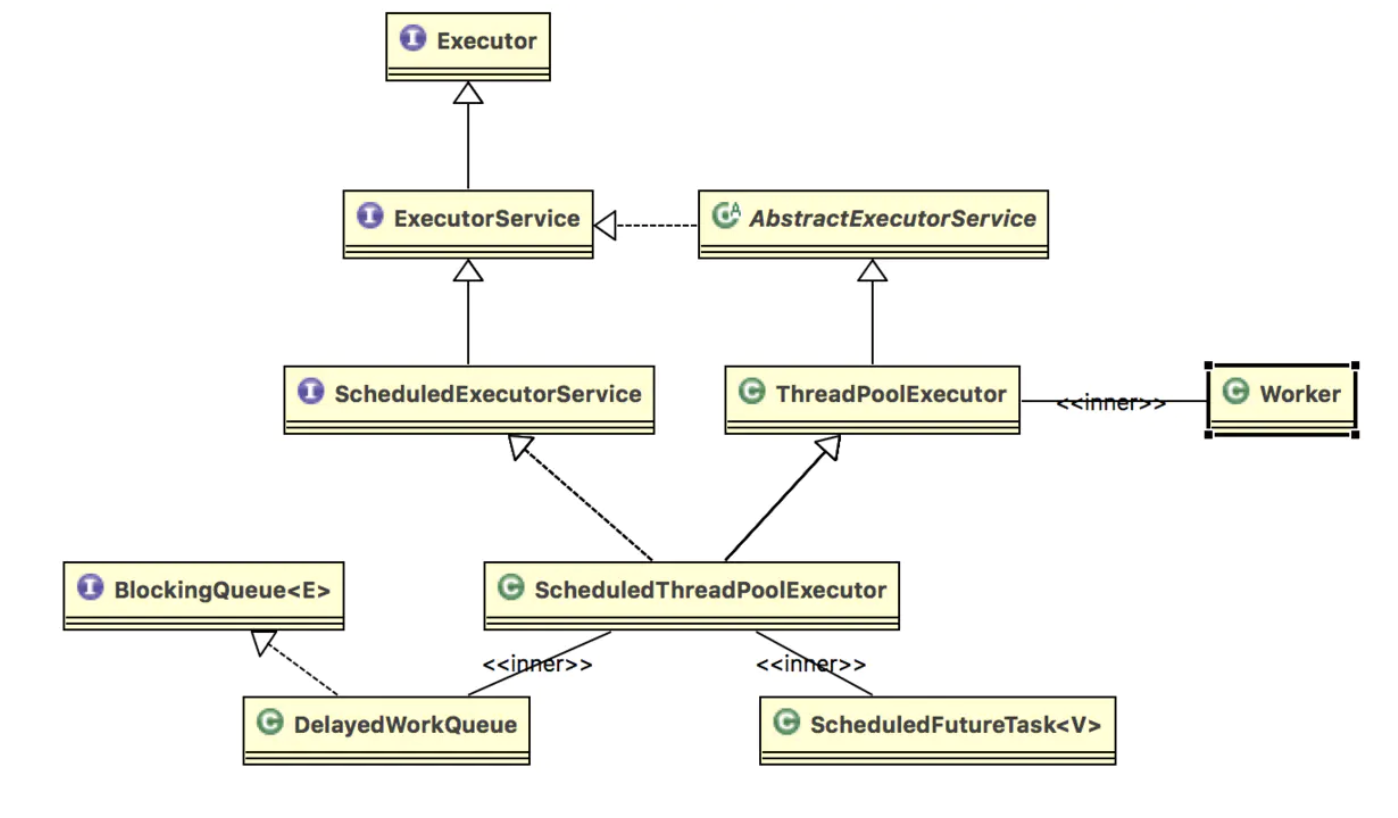
线程池
public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory, RejectedExecutionHandler handler);
参数:
- corePoolSize : 核心线程数,一旦创建将不会再释放;
- maximumPoolSize : 最大线程数,如果最大线程数等于核心线程数,则无法创建非核心线程;如果非核心线程处于空闲时,超过设置的空闲时间,则将被回收,释放占用的资源。
- keepAliveTime : 也就是当线程空闲时,所允许保存的最大时间,超过这个时间,线程将被释放销毁,但只针对于非核心线程。
- unit : 时间单位,TimeUnit.SECONDS等。
- workQueue : 任务队列,用于保存等待执行的任务的阻塞队列,可以选择以下几个阻塞队列。
- ArrayBlockingQueue:是一个基于数组结构的有界阻塞队列,必须设置容量。此队列按 FIFO(先进先出)原则对元素进行排序。
- LinkedBlockingQueue:一个基于链表结构的阻塞队列,可以设置容量,此队列按FIFO (先进先出) 排序元素,吞吐量通常要高于ArrayBlockingQueue。
- SynchronousQueue:一个不存储元素的阻塞队列。每个插入offer操作必须等到另一个线程调用移除poll操作,否则插入操作一直处于阻塞状态,吞吐量通常要高于LinkedBlockingQueue。
- PriorityBlockingQueue:一个具有优先级的无限阻塞队列。
- threadFactory : 线程工厂,用于创建线程。
- handler : 拒绝策略,当线程边界和队列容量已经达到最大时,用于处理阻塞时的程序:
- AbortPolicy:默认策略,抛出异常RejectedExecutionException拒绝提交任务;
- CallerRunsPolicy:由调用execute方法提交任务的线程来执行这个任务;
- DiscardPolicy:直接抛弃任务,不做任何处理;
- DiscardOldestPolicy:去除任务队列中的第一个任务,重新提交;
处理任务
- execute(Runnable),无返回值;
- submit(Callable<T>),有返回值;
public class ThreadTest { public static void main(String[] args) throws InterruptedException, IOException { final AtomicInteger mThreadNum = new AtomicInteger(1); ThreadPoolExecutor executor = new ThreadPoolExecutor(2, 4, 10, TimeUnit.SECONDS, new ArrayBlockingQueue<>(2), new ThreadFactory() { @Override public Thread newThread(@NotNull Runnable r) { Thread t = new Thread(r, "my-thread-" + mThreadNum.getAndIncrement()); System.out.println(t.getName() + " has been created"); return t; } }, new RejectedExecutionHandler() { @Override public void rejectedExecution(Runnable r, ThreadPoolExecutor e) { System.err.println(r.toString() + " rejected"); } }); executor.prestartAllCoreThreads(); // 预启动所有核心线程 for (int i = 1; i <= 10; i++) { MyTask task = new MyTask(String.valueOf(i)); executor.execute(task); } executor.shutdown(); } static class MyTask implements Runnable { private String name; public MyTask(String name) { this.name = name; } @Override public void run() { try { System.out.println(this.toString() + " is running!"); Thread.sleep(3000); //让任务执行慢点 } catch (InterruptedException e) { e.printStackTrace(); } } @Override public String toString() { return "MyTask [name=" + name + "]"; } } }
运行结果:
my-thread-1 has been created
my-thread-2 has been created
my-thread-3 has been created
MyTask [name=1] is running!
my-thread-4 has been created
MyTask [name=3] is running!
MyTask [name=2] is running!
MyTask [name=5] is running!
MyTask [name=7] rejected
MyTask [name=8] rejected
MyTask [name=9] rejected
MyTask [name=10] rejected
MyTask [name=4] is running!
MyTask [name=6] is running!
其中线程线程1-4先占满了核心线程和最大线程数量,然后4、5线程进入等待队列,7-10线程被直接忽略拒绝执行,等1-4线程中有线程执行完后通知4、5线程继续执行。
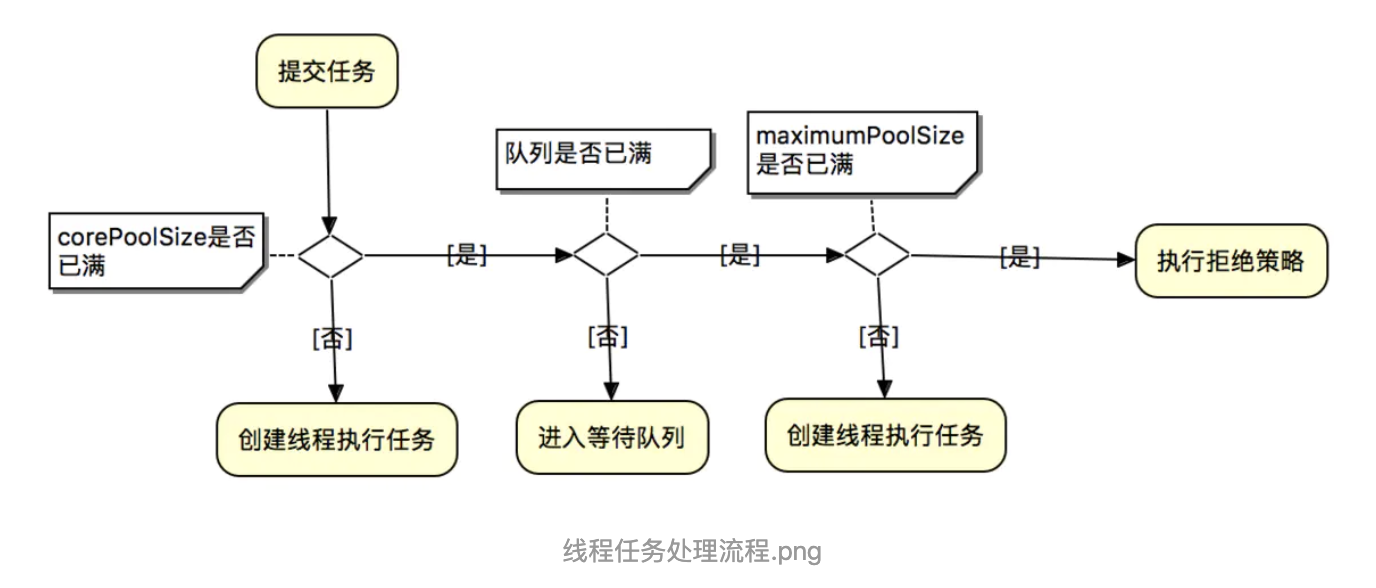
- 如果运行的线程少于 corePoolSize,则 Executor 始终首选添加新的线程,而不进行排队。(即如果当前运行的线程小于corePoolSize,则任务根本不会添加到workQueue中)
- 如果运行的线程等于或多于 corePoolSize,则 Executor 始终首选将请求加入工作队列,而不添加新的线程。
- 如果无法将请求加入workQueue(但是队列已满),则创建新的线程,除非创建此线程超出 maximumPoolSize,如果超过,在这种情况下,新的任务将被拒绝。
预定义线程池
FixedThreadPool
public static ExecutorService newFixedThreadPool(int nThreads) { return new ThreadPoolExecutor(nThreads, nThreads, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>()); }
corePoolSize与maximumPoolSize相等,即其线程全为核心线程,是一个固定大小的线程池。
SingleThreadExecutor
public static ExecutorService newSingleThreadExecutor() { return new FinalizableDelegatedExecutorService (new ThreadPoolExecutor(1, 1, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>())); }
看起来很像 newFixedThreadPool(1),但多了一层 FinalizableDelegatedExecutorService 包装,看下它的作用:
ExecutorService fixedThreadPool = Executors.newFixedThreadPool(1); ((ThreadPoolExecutor) fixedThreadPool).setMaximumPoolSize(3); System.out.println(((ThreadPoolExecutor) fixedThreadPool).getMaximumPoolSize()); // 3 ExecutorService singleThreadExecutor = Executors.newSingleThreadExecutor(); ((ThreadPoolExecutor) singleThreadExecutor).setMaximumPoolSize(3); // 运行时异常 java.lang.ClassCastException //System.out.println(((ThreadPoolExecutor) singleThreadExecutor).getMaximumPoolSize());
可见,SingleThreadExecutor被包装后,无法成功向下转型。因此,SingleThreadExecutor被定以后,无法修改,做到了真正的Single。
newCachedThreadPool
public static ExecutorService newCachedThreadPool() { return new ThreadPoolExecutor(0, Integer.MAX_VALUE, 60L, TimeUnit.SECONDS, new SynchronousQueue<Runnable>()); }
corePoolSize = 0,maximumPoolSize = Integer.MAX_VALUE,即其线程全为非核心线程,空闲超时会被释放。
ScheduledThreadPool
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) { return new ScheduledThreadPoolExecutor(corePoolSize); }
public ScheduledThreadPoolExecutor(int corePoolSize) { super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS, new DelayedWorkQueue()); }
关闭线程池
线程池自动关闭的两个条件:1、线程池的引用不可达;2、线程池中没有线程;
如果核心线程不为0,由于没有超时策略,所以并不会自动关闭。
当shutdown一个线程池后,继续提交任务,会执行拒绝策略;
public static void main(String[] args) { ThreadPoolExecutor executor = new ThreadPoolExecutor(4, 4, 10, TimeUnit.SECONDS, new LinkedBlockingQueue<>()); executor.execute(() -> System.out.println("before shutdown")); executor.shutdown(); executor.execute(() -> System.out.println("after shutdown")); }
shutdown一个线程池后,等待队列的任务仍会被继续执行,但如果用shutdownNow()方法,则不执行队列中的任务;
shutdown和shutdownNow对正在执行的任务的影响是怎样的呢?
public class InteruptTest { public static void main(String[] args) throws InterruptedException { ThreadPoolExecutor executor = new ThreadPoolExecutor(1, 1, 10, TimeUnit.SECONDS, new LinkedBlockingQueue<>()); executor.execute(new Task("0")); Thread.sleep(1); executor.shutdownNow(); System.out.println("executor has been shutdown"); } static class Task implements Runnable { String name; public Task(String name) { this.name = name; } @Override public void run() { for (int i = 1; i <= 100 && !Thread.interrupted(); i++) { Thread.yield(); System.out.println("task " + name + " is running, round " + i); } } } }
运行结果:
task 0 is running, round 1
task 0 is running, round 2
task 0 is running, round 3
task 0 is running, round 4
task 0 is running, round 5
task 0 is running, round 6
task 0 is running, round 7
task 0 is running, round 8
task 0 is running, round 9
task 0 is running, round 10
task 0 is running, round 11
task 0 is running, round 12
task 0 is running, round 13
task 0 is running, round 14
task 0 is running, round 15
task 0 is running, round 16
task 0 is running, round 17
task 0 is running, round 18
task 0 is running, round 19
executor has been shutdown
task 0 is running, round 20
shutdownNow 会将正在执行任务的Thread.interrupted 置为true,如果线程检测了该状态,可以决定要不要停止运行。
总结一下:
shutdown
l 停止接收外部submit的任务
l 内部正在跑的任务和队列里等待的任务,会执行完
l 等到第二步完成后,才真正停止
shutdownNow
l 停止接收外部submit的任务
l 队列里等待的任务走拒绝策略;
l interrupt正在执行的任务;
| 等到第三步完成后,才真正停止
调整线程池大小
对于CPU密集型任务,线程池大小可以设置为CPU核数,这可以通过下面的方式获取
Runtime.getRuntime().availableProcessors();
对于IO密集型任务,线程池大小可以参考公式:
NThreads = NCPU * UCPU * (1 + W/C)
其中:
- NCPU,CPU核个数;
- UCPU,期望的CPU利用率(0-1之间);
- W/C,等待时间/计算时间 比率;
ForkJoinPool
ForkJoinPool是ExecutorSerice的一个补充,而不是替代品,特别适合用于“分而治之”,递归计算的算法。
JAVA8 中CompeleteFuture、并发流等都是基于ForkJoinPool实现;
ForkJoinPool的线程池默认大小为CPU核数:
/** * Creates a {@code ForkJoinPool} with parallelism equal to {@link * java.lang.Runtime#availableProcessors}, using the {@linkplain * #defaultForkJoinWorkerThreadFactory default thread factory}, * no UncaughtExceptionHandler, and non-async LIFO processing mode. * * @throws SecurityException if a security manager exists and * the caller is not permitted to modify threads * because it does not hold {@link * java.lang.RuntimePermission}{@code ("modifyThread")} */ public ForkJoinPool() { this(Math.min(MAX_CAP, Runtime.getRuntime().availableProcessors()), defaultForkJoinWorkerThreadFactory, null, false); }

例子:使用RecursiveTask实现一个累加的功能,使用分而治之的思想,实现分段求和后汇总
import java.util.concurrent.RecursiveTask; public class SumTask extends RecursiveTask<Integer> { private Integer start = 0; private Integer end = 0; public SumTask(int start, int end) { this.start = start; this.end = end; } @Override protected Integer compute() { if (end - start < 100) { int sumResult = 0; for (int i = start; i <= end; i++) { sumResult += i; } return sumResult; } else { int middle = (end + start) / 2; SumTask leftSum = new SumTask(this.start, middle); SumTask rightSum = new SumTask(middle + 1, this.end); leftSum.fork(); rightSum.fork(); return leftSum.join() + rightSum.join(); } } public static void main(String[] args) { SumTask sumTask = new SumTask(1, 999999); sumTask.fork(); System.out.println("result:" + sumTask.join()); } }
看下fork()方法做了什么:
public final ForkJoinTask<V> fork() { Thread t; if ((t = Thread.currentThread()) instanceof ForkJoinWorkerThread) ((ForkJoinWorkerThread)t).workQueue.push(this); else ForkJoinPool.common.externalPush(this); return this; }
ForkJoinWorkerThread的时候,则加入到ForkJoinPool线程池(基于ExecutorService实现);当前线程已经是
ForkJoinWorkerThread了,则把这个任务加入到当前线程的workQueue。workQueue。- 若队列非空,则代表自己线程的Task还没执行完毕,取出Task并执行。
- 若队列为空,则随机选取一个其他的工作线程的Task并执行(work-stealing)。
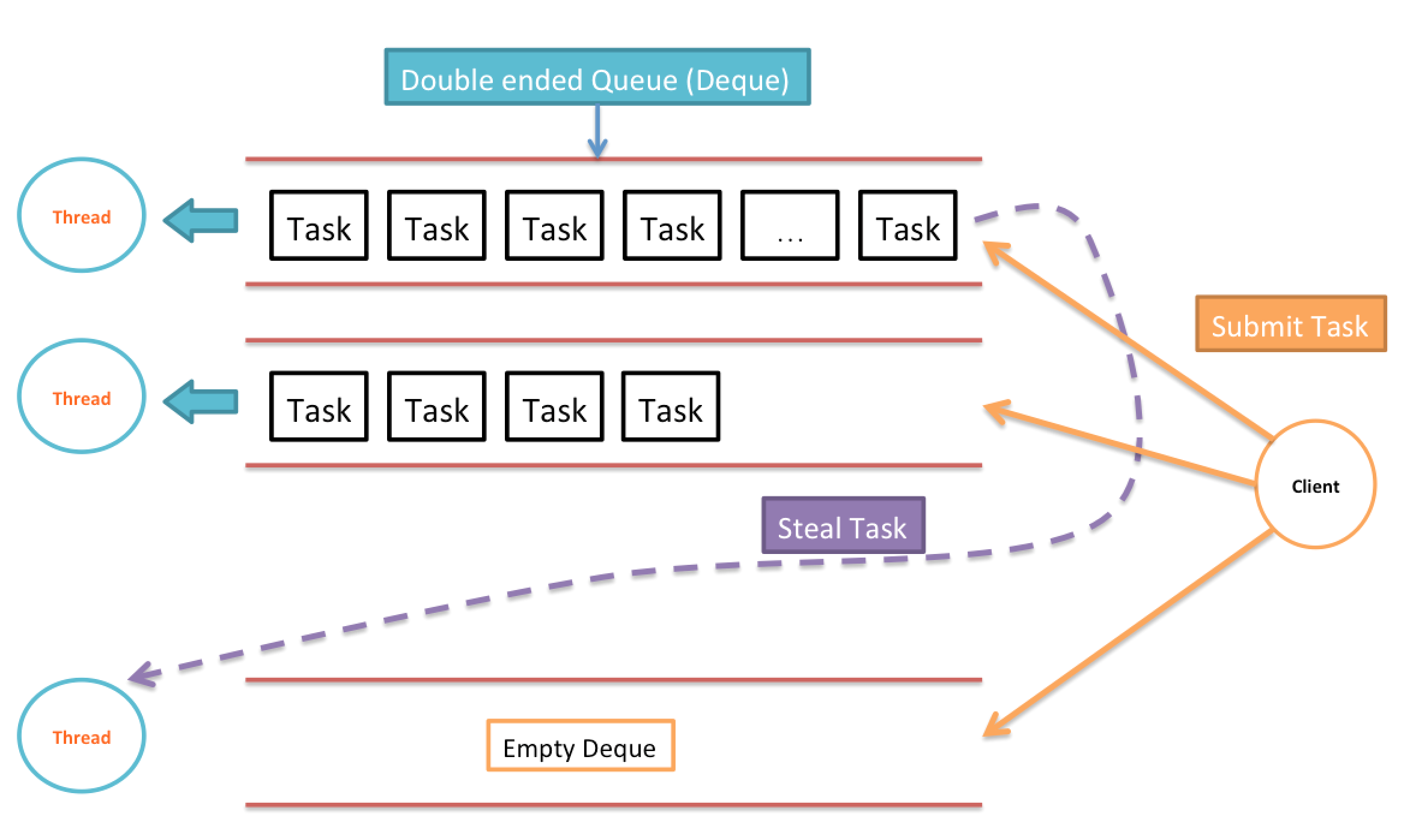
那么为了减少在对Task双端队列进行操作时的Race Condition,这里的双端队列通过维护一个top变量和一个base变量来解决这个问题。top变量类似于栈帧,当ForkJoinTask fork出新的Task或者Client从外部提交一个新的Task的ForkJoinPool时,工作线程将Task以LIFO的方式push到双端队列的队头,top维护队头的位置,可以简单理解为双端队列push的部分为一个栈。而base维护队列的队尾,当别的线程需要从本工作线程密取任务时,是从双端队列的队尾出取出任务。工作队列基于以下几个保证对队列进行操作:
- push和pop操作只会被owner线程调用。
- 只有非owner线程会调用take操作。
- pop和take操作只有在队列将要变成空(当前只有一个元素)时才会需要处理同步问题。
也就是说这个实现的双端队列将整体的同步问题转换为了一个two-party的同步问题,对于take而言我们只要提供一个简单的entry lock来保证所以其他线程的take的一致性,而对于自己owner线程的pop和push几乎不需要同步。
由于ForkJoinPool的这些特性,因此它除了适合用来实现分而治之的计算框架以外,还非常适合用来作为基于event的异步消息处理执行框架,而Akka正是将ForkJoinPool作为默认的底层ExcutorService。事实证明,ForkJoinPool在Akka这种基于消息传递的异步执行环境下能够展现出非常高的性能优势,前提是尽量减少在处理过程中的线程阻塞(如IO等待等等)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号