
Fzu软工第二次作业-词频分析
(0)前言:
(1)PSP表格:
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 40 |
| • Estimate | • 估计这个任务需要多少时间 | 30 | 40 |
| Development | 开发 | 1070 | 1300 |
| • Analysis | • 需求分析 (包括学习新技术) | 150 | 200 |
| • Design Spec | • 生成设计文档 | 50 | 60 |
| • Design Review | • 设计复审 | 30 | 20 |
| • Coding Standard | • 代码规范 (为目前的开发制定合适的规范) | 40 | 20 |
| • Design | • 具体设计 | 200 | 50 |
| • Coding | • 具体编码 | 360 | 330 |
| • Code Review | • 代码复审 | 40 | 360 |
| • Test | • 测试(自我测试,修改代码,提交修改) | 200 | 260 |
| Reporting | 报告 | 110 | 120 |
| • Test Repor | • 测试报告 | 50 | 60 |
| • Size Measurement | • 计算工作量 | 30 | 25 |
| • Postmortem & Process Improvement Plan | • 事后总结, 并提出过程改进计划 | 30 | 35 |
| 合计 | 1210 | 1460 |
(2)解题思路描述:
- 刚拿到题目后,我发现本题只是要求我们实现一个控制台程序,通过命令行参数传入一个文本后,将文本进行解析,分析出文本里的字符数,单词数,有效行数等内容。总体而已,这个程序的基本功能并不是很难。
-由于我对于java的学习比较浅显,现在已经忘的差不多了,所以我用了c++,思路有很多。编程其实并不难,同一个问题有多种实现方法,并且大问题很容易可以拆成小问题,分块解决。 - 例如这题我想了两个思路,一个是先把文件预处理,可以利用fread把文件读取成字符串,之后按照特定的分割符可以利用类似split函数,判断合法的单词,统计字符数。另一个思路是利用ifstream文件流读出txt文件的内容,之后用getline按行读出文件,并且vector存储单词,并且用map按字典序存储单词。
不过存在两个问题:
- 1.用map储存有一个问题,就是map只能按特定的key值存储单词,并不能在此基础上按单词出现的频率排序,因此我用multimap多重映射对单词再次排序,如此一来就可以按单词频率按字典序排序。
- 2.我以前没有用过通过命令行参数传入一个文件名,因此我学习了一下ifstream怎么读取输出文件。
(3)设计实现过程:
- 本项目我采用类进行接口封装,关于类的说明与接口的函数在stdafx.h文件里,关于接口的详细代码内容在stdafx.cpp文件里。
-对于本作业,主要我设计了两个类,一个类是Word类用于进行词频分析以及存储词频分析的结果.另一个类File是用于进行文件的异常测试。
Word类包含了5个函数:
Word();//用于初始化
int Countcharacters(char *argv);//用于统计字符数
int Countlines(char *argv);//用于统计空白行
int Countwords(char *argv);//用于统计单词数
vector<pair<string,int>> Counttop10(char *argv);//统计词频前十的单词
File类包含了2个函数:
File();//用于初始化
int FileTest(char *argv[]);//用于文件异常测试
模块分析:
- Countcharacters函数是用于统计字符数的,主要是根据题意,遍历一次文件里的字符串,判断字符是否是在0到127,属于Ascill码的范围。
- Countlines函数是用于统计空白行,在分析这个功能的时候,需要先理解什么是空白字符串,主要包括tab,空格跟回车三种,只要按行读取,判断该行内是否存在除这三者以外的字符,就可以判断是否是空白行。
- Countwords函数用于统计单词数,我主要是先通过大小写转化,把合法单词所可能用的字符大小写转化,之后用ans作为标记,判断是否存在开头为4个连续的字母的单词,若存在合法单词,则用map进行存储。
- Counttop10用于统计词频前十的单词,属于这次词频分析作业里的核心函数,同样是找出合法单词用map按字典序存储,多重映射的multimap,将key设为单词的词频,按词频进行字典序排序,由于map要求key值唯一,而multimap可以多重映射,因此我使用multimap进行排序,最后用vector和pair存储词频前十的单词。核心代码见(5)
(4)性能分析及改进:
测试文件input.txt内容:
vasdvs
bsbsdb.vasdvs
;casv[vdav/vv
vas.vsv+v
casvsa2000
casvsa1998
as*casvsa2001
123acasv;;;;;
12sav
vasdvs
vdv++
12sav;;fas
b
测试文件结果:
characters: 130
words: 9
lines: 13
<vasdvs>: 3
<bsbsdb>: 1
<casv>: 1
<casvsa1998>: 1
<casvsa2000>: 1
<casvsa2001>: 1
<vdav>: 1
-
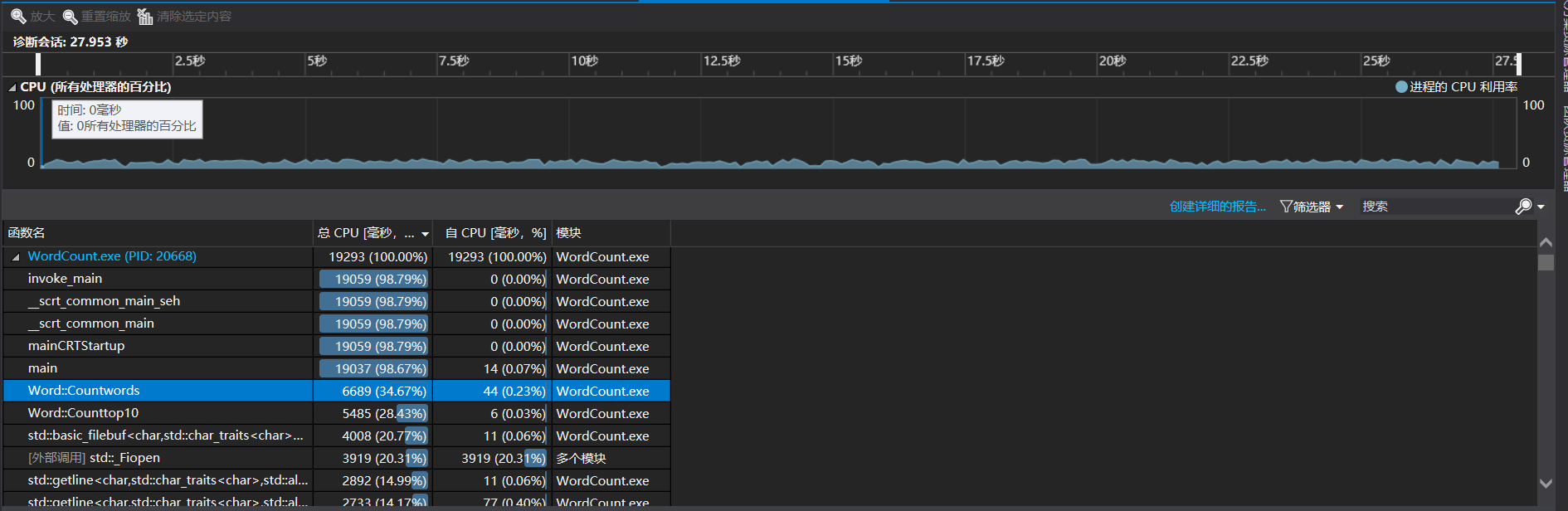
我将这个文件循环测试了10000次,性能分析结果如图:
![]()
-
从图可以看出Countwords函数占了接近35%的时间,Counttop10占了快20%的时间,总耗时28s,由于我一开始是在执行Countwords过程中,顺便用map存储合法单词,由于题目要求是要三个独立的接口,因此我在调用Counttop10函数时是先执行了一次Countwords函数。因此我把两个进行拆分,做出改进。
-
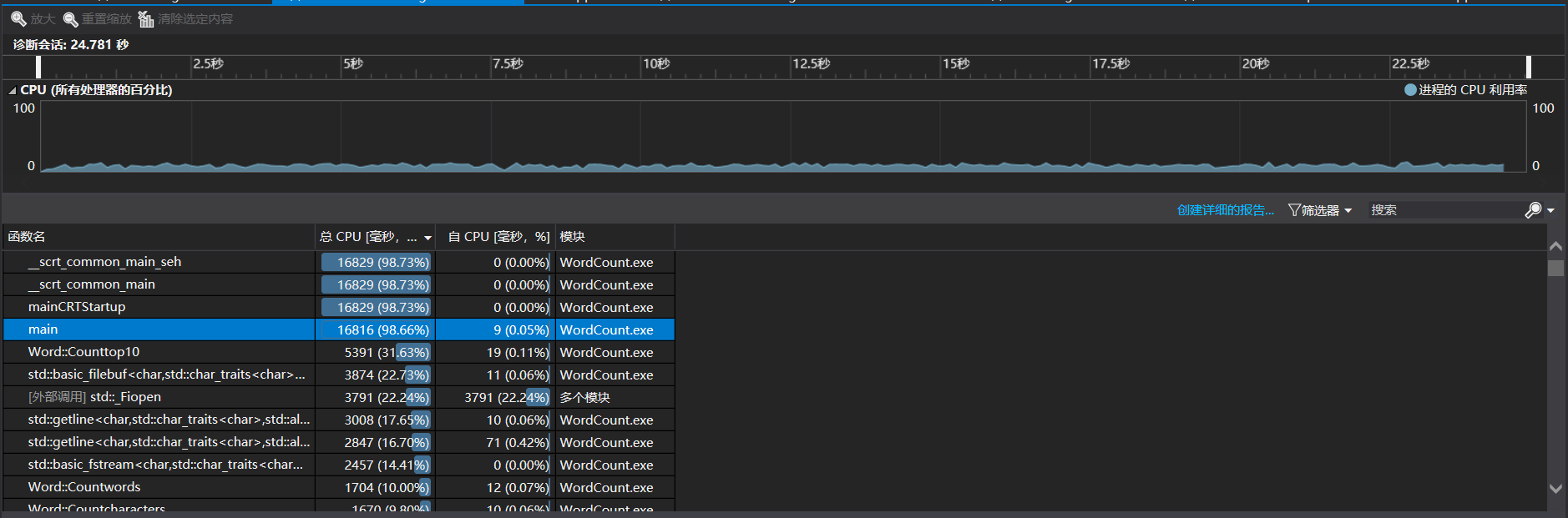
改进后Countwords函数只用于统计单词个数,Counttop10则是先自行遍历一次文件,查找合法单词后,进行后续操作,改进后性能分析结果如图:
![]()
-
改进结果,时间减少了3s,Countwords占用时间大幅度减少。
(5)项目关键代码:
Counttop10函数:
vector<pair<string, int>> Word::Counttop10(char *argv)
{
//利用多重映射的multimap,将单词按词频字典序排序,之后用vector存储前十的单词
mapword.clear(); //先对原本的map初始化
map<string, int>::iterator iter; //迭代器
multimap<int, string> mapint;
multimap<int, string>::iterator iter2;
string name, word;
long ans, num, i, j, wordpos;
vector<pair<string, int>> top10;
ifstream Fileread; //读出文件
Fileread.open(argv, std::ios::in);
if (Fileread.fail()) //异常检测
{
printf("file isn't exist\n");
return top10;
}
while (!Fileread.eof())
{
getline(Fileread, name); //按行读取文件
ans = 0; wordpos = 0;
num = name.size();
for (i = 0; i<num; i++)
{
if (65 <= name[i] && name[i] <= 90)name[i] += 32;//大小写转化
//判断是否为合法单词
if (97 <= name[i] && name[i] <= 122)
{
ans++;
continue;
}
if ('0' <= name[i] && name[i] <= '9')
{
if (ans >= 4)
{
continue;
}
else
{
for (j = i; j<num; j++)
{
if ('0' <= name[j] && name[j] <= '9')
continue;
else if (('a' <= name[j] && name[j] <= 'z') || ('A' <= name[j] && name[j] <= 'Z'))
continue;
else
{
//寻找下一个合法单词的开头
while (j<num)
{
if (('a' <= name[j + 1] && name[j + 1] <= 'z') || ('A' <= name[j + 1] && name[j + 1] <= 'Z'))
{
wordpos = j + 1;
break;
}
else
j++;
} //寻找下一个单词的开头
i = j;
break;
}
} //寻找下一个分隔符
if (j == num)
{
break;
} //寻找不到下一个分隔符
ans = 0;
}
}
else
{
if (ans >= 4)
{
//添加单词
word = name.substr(wordpos, i - wordpos);
iter = mapword.find(string(word));
if (iter != mapword.end())
iter->second += 1;
else
mapword.insert(pair<string, int>(word, 1));
// cout<<"word:"<<word<<endl;
}//获取单词
while (i<num)
{
if (('a' <= name[i + 1] && name[i + 1] <= 'z') || ('A' <= name[i + 1] && name[i + 1] <= 'Z'))
{
wordpos = i + 1;
break;
}
else
i++;
} //寻找下一个合法单词的开头
ans = 0;
}
}
//防止该行以合法单词结尾
if (ans >= 4)
{
word = name.substr(wordpos, i - wordpos);
iter = mapword.find(string(word));
if (iter != mapword.end())
iter->second += 1;
else
{
mapword.insert(pair<string, int>(word, 1));
}
}
}
num = 0;
iter = mapword.begin();
for (; iter != mapword.end(); iter++)
{
mapint.insert(pair<int, string>(-iter->second, iter->first));
}
for (iter2 = mapint.begin(); iter2 != mapint.end(); iter2++)
{
num++;
top10.push_back(make_pair(iter2->second.c_str(), -(iter2->first)));
if (num == 10)
break;
}
Fileread.close();
return top10; //返回一个vector
}
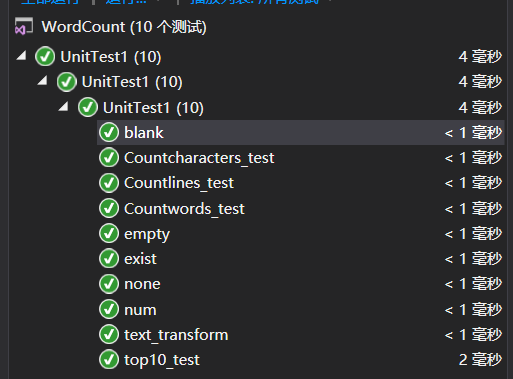
(6)单元测试:
本次作业共设置了10个单元测试点,分别用于测试:
- 测试空白文件
- 测验没有命令行参数
- 测试文件不存在
- 测试单词数字开头的情况
- 测试大小写单词是否能识别
- 测试空白行是否识别
- 测试Countlines函数
- 测试Countwords函数
- 测试Countcharacters函数
- 测试Counttop10函数
单元测试结果:
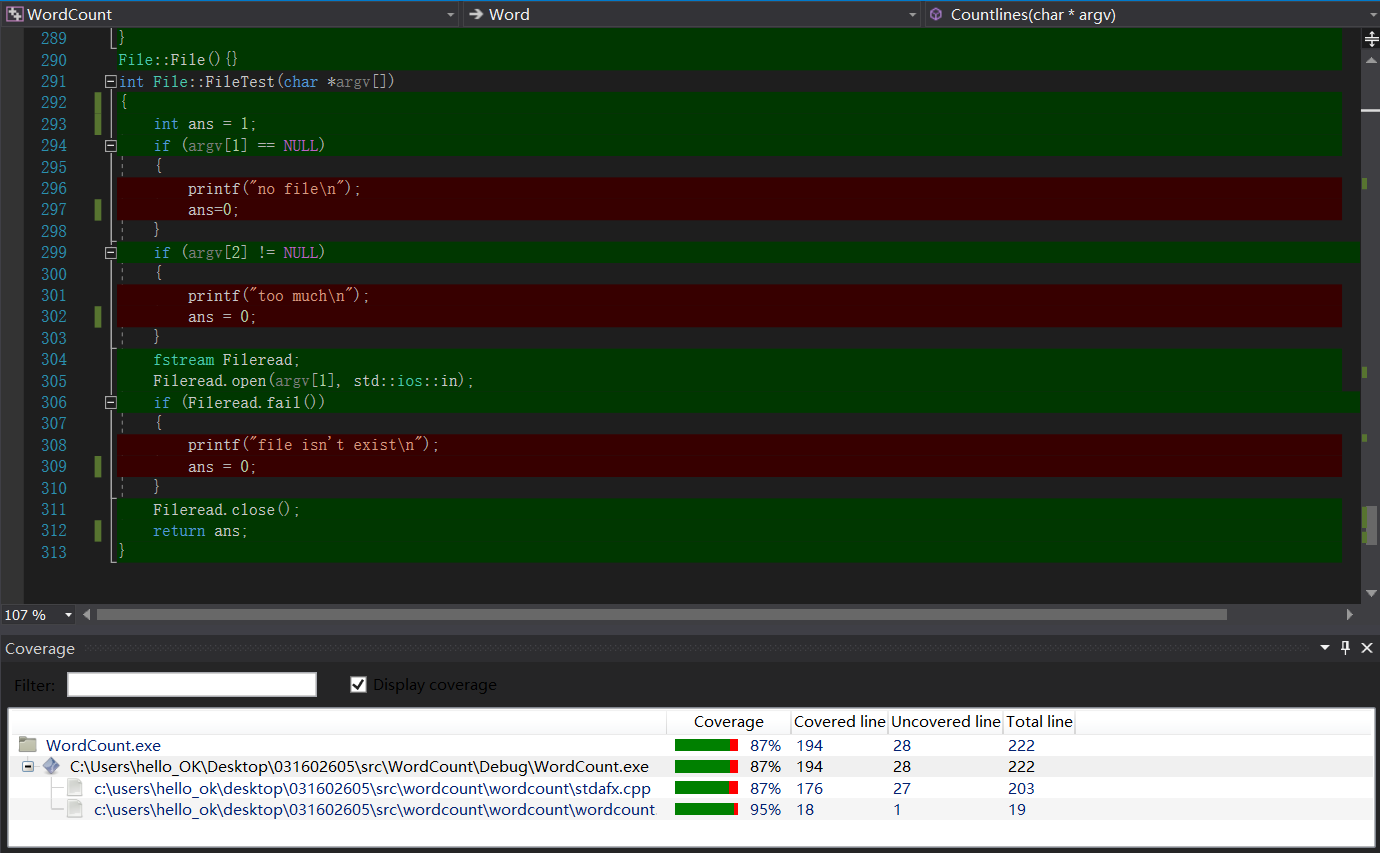
代码测试覆盖率:
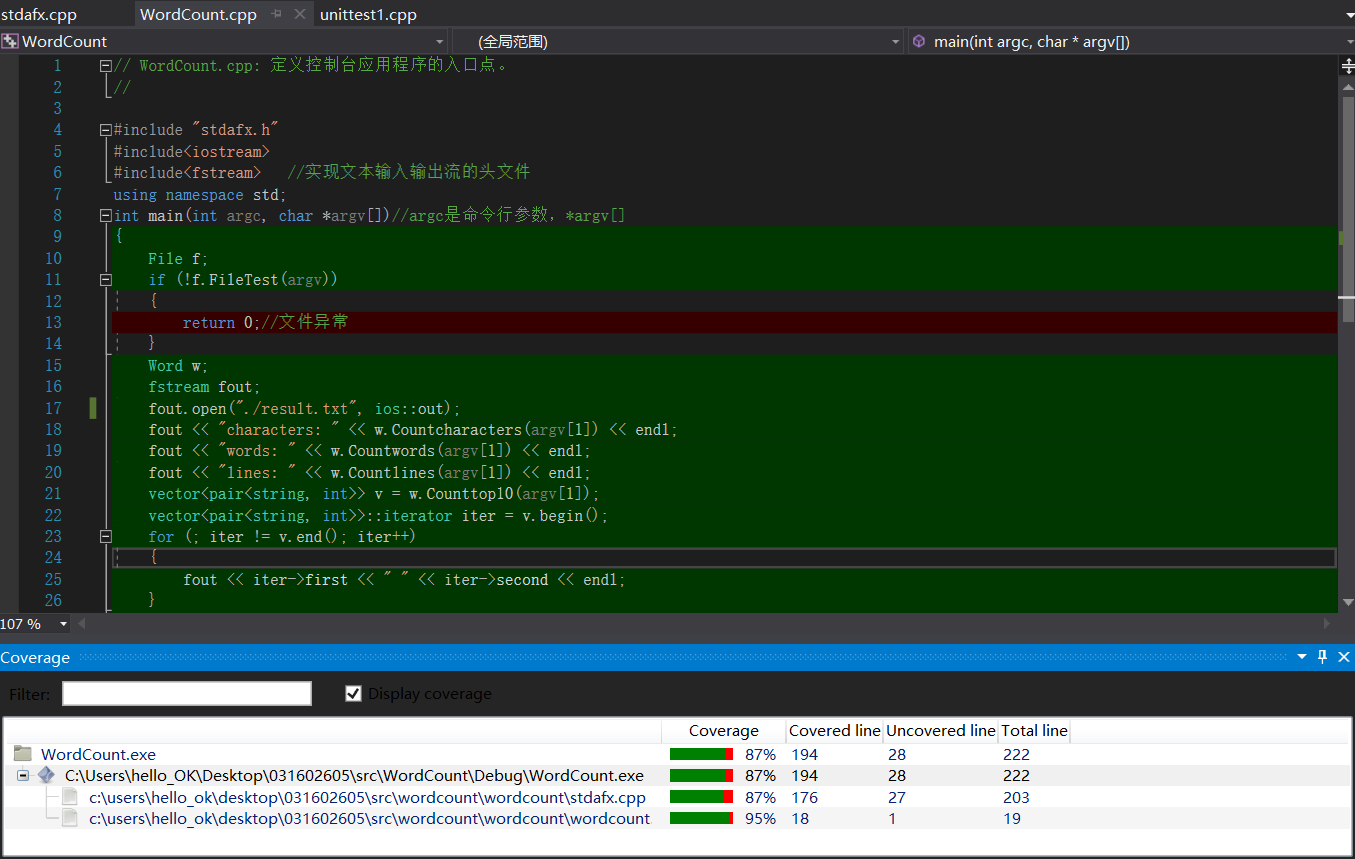
其中stdafx.cpp覆盖率较低的原因是写了一些文件异常处理的代码,如下图:
(7)异常处理:
- 针对异常处理我主要设置了三种情况,一种是命令行无参数,一种是命令行有多个参数,一种是命令行参数地址错误
- FileTest(char *argv[]);//用于文件异常测试
int File::FileTest(char *argv[])
{
if (argv[1] == NULL)
{
printf("no file\n");
return 0;
}
if (argv[2] != NULL)
{
printf("too much\n");
return 0;
}
fstream Fileread;
Fileread.open(argv[1], std::ios::in);
if (Fileread.fail())
{
printf("file isn't exist\n");
return 0;
}
Fileread.close();
return 1;
}
(8)项目小节及个人感想:
- 本实验我是用c++写的,可能由于参加过acm,学习过一些算法的知识,实现代码的基本功能对我并不是很困难,主要难点在于我以前没用使用过vs,对于vs的功能基本上是属于一知半解的,因此我大部分的时候是学习vs的功能。原本接口的封装我是想采用dll封装,后面因为时间原因,临时换回了class封装,感觉这次在代码改进上做的不够,原本想文件预处理,Word再预处理后直接存储ifstream 的指针,这样再后面调用其他函数时,就可以节省一些开销,不过尝试没用成功,准备等之后有时间再查查fstream文件流的详细原理,看看这个方法是否可行再进行尝试。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号