
es match、match_phrase、query_string和term的区别
(一)text字段和keyword字段的区别
以下给出一个例子:
首先建立一个索引和类型,引入一个keywork的字段:
PUT my_index { "mappings": { "products": { "properties": { "name": { "type": "keyword" } } } } }
然后查询是否有索引:
GET _cluster/state
可以看到已经创建成功:

添加一条数据:
POST my_index/products { "name":"washing machin" }
然后查询:
GET my_index/products/_search { "query": { "term": { "name": "washing" } } }
可以看到没有匹配到任何数据: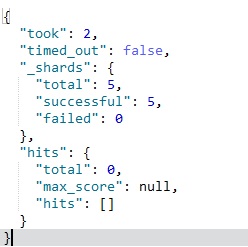
然后查询:
GET my_index/products/_search { "query": { "term": { "name": "washing machine" } } }
可以看到成功匹配到了数据:
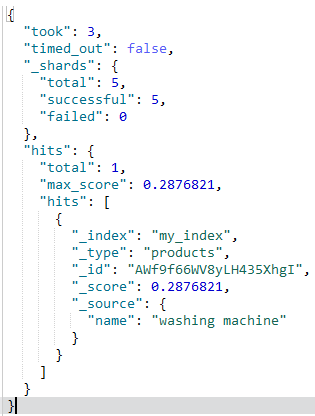
所以将字段设置成keyword的时候查询的时候已有的值不会被分词。
现在添加一个text类型的字段:
PUT my_index/_mapping/products?update_all_types { "properties": { "tag": { "type": "text" } } }
可以看到添加成功:

往之前已经创建的doc之中添加tag的数据:
POST my_index/products/AWf9f66WV8yLH435XhgI { "name":"washing machine", "tag":"electric household" }
查询一下,可以看到:

然后对tag字段进行查询:
POST /my_index/products/_search { "query": { "term": { "tag": "household" } } }
可以看到虽然没有全部输入,但是已经查询到了:
现在输入全部的查询:
POST /my_index/products/_search { "query": { "term": { "tag": "electric household" } } }
发现现在已经查询不到了:
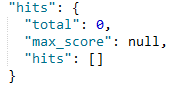
说明text类型的字段会被分词,查询的时候如果用拆开查可以查询的到,但是要是直接全部查,就是查询不到。
注意“1, 2”会被拆分成[1, 2],但是"1,2"是不拆分的,少了个空格。
(二)match和term的区别
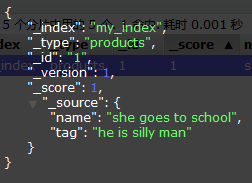
1.term
1)term查询keyword字段。
term不会分词。而keyword字段也不分词。需要完全匹配才可。
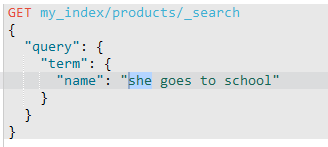

成功。
但是如果:
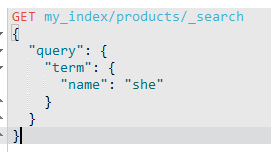

则查询失败。
2)term查询text字段。
因为text字段会分词,而term不分词,所以term查询的条件必须是text字段分词后的某一个。


查询成功。
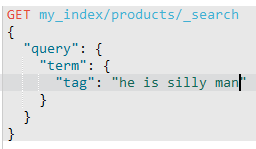
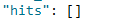
查询失败,因为现在tag已经被分词了,存储的是[he, is, silly, man]。
这样查询:
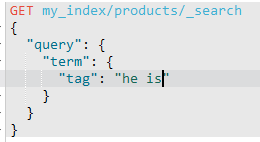
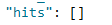
也是失败了,道理跟上面的是一样的。
2.
1)match查询keyword字段
match会被分词,而keyword不会被分词,match的需要跟keyword的完全匹配可以。


其他的不完全匹配的都是失败的。
2)match查询text字段
match分词,text也分词,只要match的分词结果和text的分词结果有相同的就匹配。
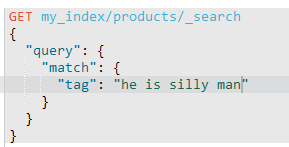

成功。如果都不相同就失败了。
3.
1)match_phrase匹配keyword字段。
这个同上必须跟keywork一致才可以。
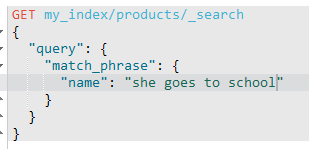
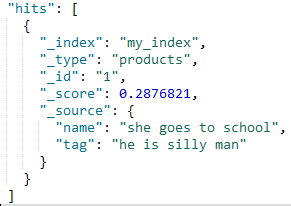
只有这种情况才是成功的。
2)match_phrase匹配text字段。
match_phrase是分词的,text也是分词的。match_phrase的分词结果必须在text字段分词中都包含,而且顺序必须相同,而且必须都是连续的。
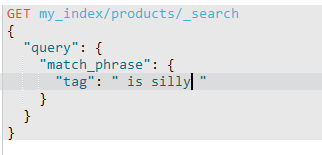

这是成功的。
如果不是连续的,就会失败。
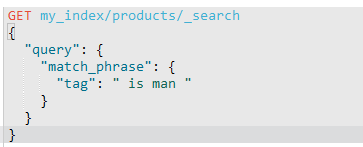
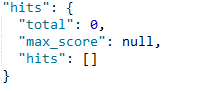
4.
1)query_string查询key类型的字段,试过了,无法查询。


失败的,无法查询。
2)query_string查询text类型的字段。
和match_phrase区别的是,不需要连续,顺序还可以调换。


成功。


这样也是可以的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号