
5. 配置项:rule_files
- 一、配置规则
- 二、语法检查规则
- 三、记录规则
- 3.1 <rule_group>
- 3.2 <rule>
- 四、警报规则
- 4.1 定义报警规则
- 4.2 模板
- 4.3 在运行时检查警报
- 4.4 发送提醒通知
prometheus配置文件内容:


1 global: 2 # 默认情况下抓取目标的频率. 3 [ scrape_interval: <duration> | default = 1m ] 4 5 # 抓取超时时间. 6 [ scrape_timeout: <duration> | default = 10s ] 7 8 # 评估规则的频率. 9 [ evaluation_interval: <duration> | default = 1m ] 10 11 # 与外部系统通信时添加到任何时间序列或警报的标签 12 #(联合,远程存储,Alertma# nager). 13 external_labels: 14 [ <labelname>: <labelvalue> ... ] 15 16 # 规则文件指定了一个globs列表. 17 # 从所有匹配的文件中读取规则和警报. 18 rule_files: 19 [ - <filepath_glob> ... ] 20 21 # 抓取配置列表. 22 scrape_configs: 23 [ - <scrape_config> ... ] 24 25 # 警报指定与Alertmanager相关的设置. 26 alerting: 27 alert_relabel_configs: 28 [ - <relabel_config> ... ] 29 alertmanagers: 30 [ - <alertmanager_config> ... ] 31 32 # 与远程写入功能相关的设置. 33 remote_write: 34 [ - <remote_write> ... ] 35 36 # 与远程读取功能相关的设置. 37 remote_read: 38 [ - <remote_read> ... ]
配置文件通用占位符:PS:本部分主要介绍rule_files的详细内容。
1 通用占位符定义如下: 2 <boolean>:一个可以取值为true或false的布尔值 3 <duration>:与正则表达式匹配的持续时间[0-9] +(ms | [smhdwy]) 4 <labelname>:与正则表达式匹配的字符串[a-zA-Z _] [a-zA-Z0-9 _] * 5 <labelvalue>:一串unicode字符 6 <filename>:当前工作目录中的有效路径 7 <host>:由主机名或IP后跟可选端口号组成的有效字符串 8 <path>:有效的URL路径 9 <scheme>:一个可以取值http或https的字符串 10 <string>:常规字符串 11 <secret>:一个秘密的常规字符串,例如密码 12 <tmpl_string>:在使用前进行模板扩展的字符串
一、配置规则
Prometheus支持两种类型的规则,这些规则可以定期配置,然后定期评估:记录规则和警报规则。 要在Prometheus中包含规则,请创建包含必要规则语句的文件,并让Prometheus通过Prometheus配置中的rule_files字段加载文件。 规则文件使用YAML。
通过将SIGHUP发送到Prometheus进程,可以在运行时重新加载规则文件。 仅当所有规则文件格式正确时才会应用更改。
二、语法检查规则
要在不启动Prometheus服务器的情况下快速检查规则文件在语法上是否正确,请安装并运行Prometheus的promtool命令行实用工具:
go get github.com/prometheus/prometheus/cmd/promtool promtool check rules /path/to/example.rules.yml |
当文件在语法上有效时,检查器将已解析规则的文本表示打印到标准输出,然后以0返回状态退出。
如果存在任何语法错误或无效的输入参数,则会向标准错误输出错误消息,并以1返回状态退出。
三、记录规则
记录规则允许您预先计算经常需要或计算上昂贵的表达式,并将其结果保存为一组新的时间序列。 因此,查询预先计算的结果通常比每次需要时执行原始表达式快得多。 这对于仪表板尤其有用,仪表板需要在每次刷新时重复查询相同的表达式。
记录和警报规则存在于规则组中。 组内的规则以固定间隔顺序运行。
规则文件的语法是:
groups: [ - <rule_group> ] |
3.1 <rule_group>
1 # 组的名称。 在文件中必须是唯一的。 2 name: <string> 3 4 # 评估组中的规则的频率。 5 [ interval: <duration> | default = global.evaluation_interval ] 6 7 rules: 8 [ - <rule> ... ]
3.2 <rule>
记录规则的语法是:
1 # 要输出的时间序列的名称。 必须是有效的度量标准名称。 2 record: <string> 3 4 # 要评估的PromQL表达式。 每个评估周期都会在当前时间进行评估,并将结果记录为一组新的时间序列,其中度量标准名称由“记录”给出。 5 expr: <string> 6 7 # 在存储结果之前添加或覆盖的标签。 8 labels: 9 [ <labelname>: <labelvalue> ]
一个简单的示例规则文件将是:
groups: - name: sum rules: - record: job:up:sum expr: sum(up) by (job) lables: rulesName: record
验证:
创建配置,并使其动态生效,通过prometheus可编辑浏览器查看,如下所示:

四、警报规则
警报规则允许您基于Prometheus表达式语言表达式定义警报条件,并将有关触发警报的通知发送到外部服务。 每当警报表达式在给定时间点生成一个或多个向量元素时,警报将计为这些元素的标签集的活动状态。
4.1 定义报警规则
警报规则在Prometheus中与记录规则相同的方式配置。
带警报的示例规则文件将是:
1 # 警报的名称。 必须是有效的度量标准名称。 2 alert: <string> 3 4 # 要评估的PromQL表达式。 每个评估周期都会在当前时间进行评估,并且所有结果时间序列都会成为待处理/触发警报。 5 expr: <string> 6 7 # 警报一旦被退回这段时间就会被视为开启。 8 # 尚未解雇的警报被认为是未决的。 9 [ for: <duration> | default = 0s ] 10 11 # 为每个警报添加或覆盖的标签。 12 labels: 13 [ <labelname>: <tmpl_string> ] 14 15 # 要添加到每个警报的注释。 16 annotations: 17 [ <labelname>: <tmpl_string> ]
labels子句允许指定要附加到警报的一组附加标签。 任何现有的冲突标签都将被覆盖。 标签值可以是模板化的。
可选的for子句使Prometheus在第一次遇到新的表达式输出向量元素和将此警告作为此元素的触发计数之间等待一段时间。 在这种情况下,Prometheus将在每次评估期间检查警报是否继续处于活动状态10分钟,然后再触发警报。 处于活动状态但尚未触发的元素处于暂挂状态。
annotations子句指定一组信息标签,可用于存储更长的附加信息,例如警报描述或Runbook链接。 注释值可以是模板化的。
4.2 模板
可以使用控制台模板模板化标签和注释值。 $labels变量保存警报实例的标签键/值对,$value保存警报实例的评估值。
1 # 要插入触发元素的标签值: 2 {{ $labels.<labelname> }} 3 # 要插入触发元素的数值表达式值: 4 {{ $value }}
例子:
1 groups: 2 - name: example 3 rules: 4 5 # 对于任何无法访问> 5分钟的实例的警报。 6 - alert: InstanceDown 7 expr: up == 0 8 for: 5m 9 labels: 10 severity: page 11 annotations: 12 summary: "Instance {{ $labels.instance }} down" 13 description: "{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 5 minutes." 14 15 # 对中值请求延迟> 1s的任何实例发出警报。 16 - alert: APIHighRequestLatency 17 expr: api_http_request_latencies_second{quantile="0.5"} > 1 18 for: 10m 19 annotations: 20 summary: "High request latency on {{ $labels.instance }}" 21 description: "{{ $labels.instance }} has a median request latency above 1s (current value: {{ $value }}s)"
4.3 在运行时检查警报
要手动检查哪些警报处于活动状态(待处理或触发),请导航至Prometheus实例的"警报"选项卡。 这将显示每个定义的警报当前处于活动状态的确切标签集,如下所示:
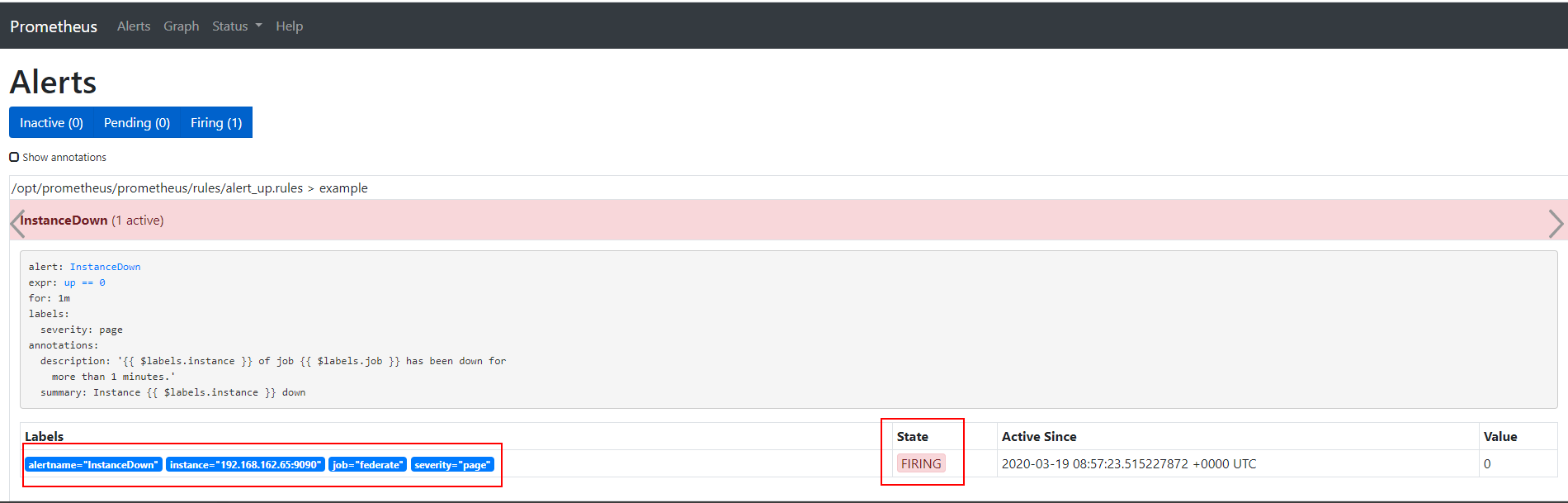
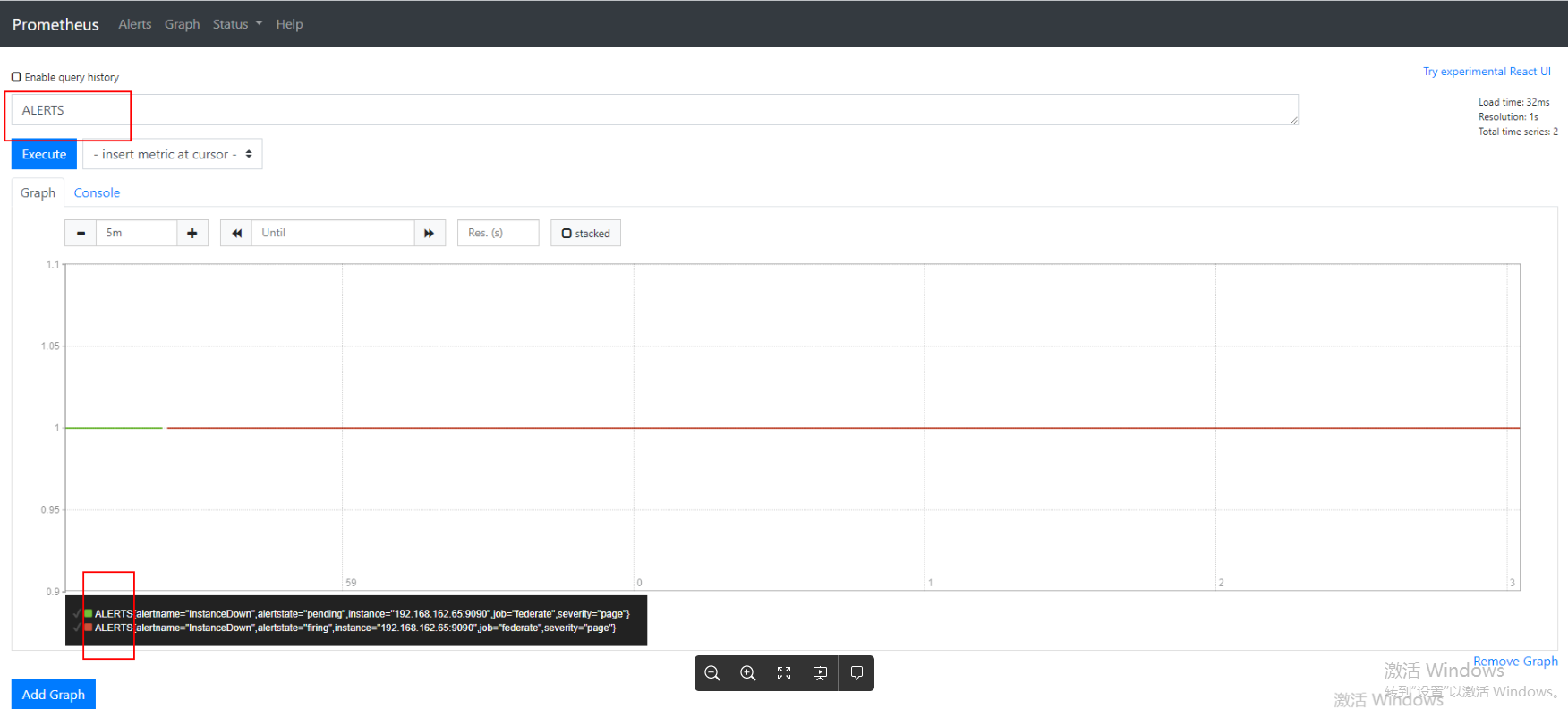
对于待处理和触发警报,Prometheus还存储ALERTS{alertname="<alert name>",alertstate ="pending|firing",<additional alert labels>}形式的合成时间序列。 只要警报处于指示的活动(pending or firing(挂起或触发))状态,样本值就会设置为1,并且当不再是这种情况时,系列会标记为过时。
4.4 发送提醒通知
普罗米修斯的警报规则很好地判断当前发生的故障,但它们并不是一个完全成熟的通知解决方案。在简单的警报定义之上,还需要另一层来添加摘要,通知速率限制,静默和警报依赖性。 在Prometheus的生态系统中,Alertmanager担当了这个角色。 因此,Prometheus可以配置为定期将有关警报状态的信息发送到Alertmanager实例,该实例随后负责调度正确的通知。
Prometheus可以配置为通过其服务发现集成自动发现可用的Alertmanager实例。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号