day05_MySQL学习笔记_02
五、数据的完整性
1、实体完整性(行级约束)
1.1 主键约束(primary key)
1.2 唯一约束(unique)
1.3 自动增长列约束(auto_increment)
2、域完整性(列级约束)
2.1 数据类型约束(数值类型、日期类型、字符串类型)
2.2 非空约束(not null)
2.3 默认值约束(default)
3、引用完整性(参照完整性)

在表外修改:alter table xxx add constraint PK_字段 primary key(字段);
在表中修改:constraint PK_字段 primary key(字段),
在表中修改:字段 字段类型 primary key,
在表外修改:alter table xxx add constraint UK_字段 unique key(字段);
在表中修改:constraint UK_字段 unique key(字段),
在表中修改:字段 字段类型 unique,
在表外修改:alter table xxx add constraint DF_字段 default('默认值') for 字段;
在表中修改:constraint DF_字段 default('默认值') for 字段,
在表中修改:字段 字段类型 default('默认值'),
在表外修改:alter table xxx add constraint CK_字段 check(约束。如:len(字段)>1);
在表中修改:constraint CK_字段 check(约束。如:len(字段)>1),
在表中修改:字段 字段类型 check(约束。如:len(字段)>1),
在表外修改:alter table xxx add constraint FK_主表_子表_主表主键字段 foreignkey(子表外键字段) references 主表(主表主键字段);
在表中修改:constraint FK_主表_子表_主表主键字段 foreign key(子表外键字段) references 主表(主表主键字段),
在表中修改:字段 字段类型 foreign key(子表外键字段) references 主表(主表主键字段),
4、表与表之间的关系
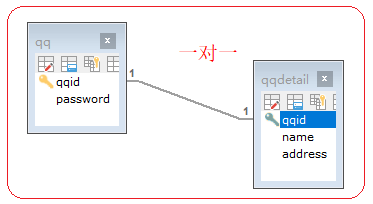
一对一:
例如t_person表和t_card表,即人和身份证。这种情况需要找出主从关系,即谁是主表,谁是从表。
人可以没有身份证,但身份证必须要有人才行,所以人是主表,而身份证是从表。
设计从表可以有两种方案:
方式1:在t_card表中添加外键列(相对t_user表),并且给外键添加唯一约束;即:字段 字段类型 unique,
方式2:给t_card表的主键添加外键约束(相对t_user表),即t_card表的主键也是外键。
示例:用方式2
create table QQ(
qqid int primary key,
password varchar(50)
);
create table QQDetail(
qqid int primary key,
name varchar(50),
address varchar(200)
);
alter table QQDetail add constraint fk_QQ_QQDetail foreign key(qqid) references QQ(qqid); 或者
alter table QQ add constraint fk_QQ_QQDetail foreign key(qqid) references QQDetail(qqid);
注意:虽然是一对一,但是维护关系不一样,那么主从表关系也不一样。(也就是说仍然有主从表的关系)
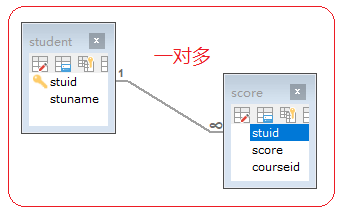
一对多(多对一):
最为常见的就是一对多!一对多和多对一,这是从哪个角度去看或者说以谁为参照物。
-- 学生表(主表)
CREATE TABLE student(
stuid VARCHAR(10) primary key,
stuname VARCHAR(50) not null
);
第一种添加外键约束的方式:在创建表格的时候同时添加外键约束。
-- 分数表(次表/子表)
CREATE TABLE score(
stuid VARCHAR(10), -- 外键列的数据类型一定要与主键列的数据类型一致
score INT,
courseid INT,
CONSTRAINT fk_stuid FOREIGN KEY(stuid) REFERENCES student(stuid)
);
CONSTRAINT(constraint:约束) FOREIGN KEY(foreign key:外键) REFERENCES(references:引用/参照/关联)
第二种添加外键约束的方式:在表格创建时没有添加外键约束,之后通过修改表格添加外键约束。
-- 分数表(次表/子表)
CREATE TABLE score(
stuid VARCHAR(10), -- 外键列的数据类型一定要与主键列的数据类型一致
score INT,
courseid INT,
);
ALTER TABLE score ADD CONSTRAINT fk_student_score_stuid FOREIGN KEY(stuid) REFERENCES stu(stuid);

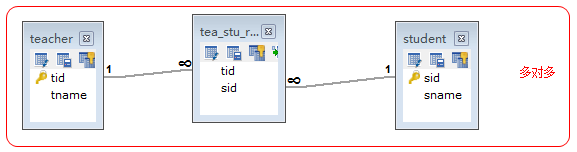
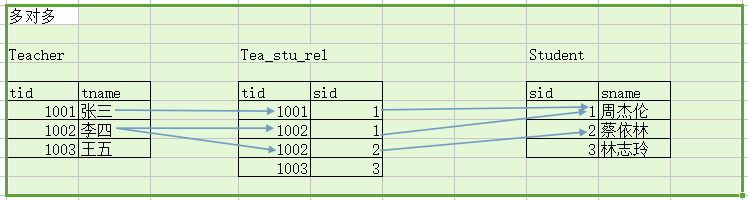
多对多:
例如t_stu和t_teacher表,即一个学生可以有多个老师,而一个老师也可以有多个学生。这种情况通常需要创建中间表来处理多对多关系。
例如再创建一张表t_stu_tea表,给出两个外键,一个相对t_stu表的外键,另一个相对t_teacher表的外键。
create table teacher(
tid int primary key,
tname varchar(20)
);
create table stu(
sid int primary key,
sname varchar(50)
);
--中间表
create table tea_stu_rel(
tid int,
sid int
);
alter table tea_stu_rel add constraint fk_teacher_rel foreign key(tid) references teacher(tid);
alter table tea_stu_rel add constraint fk_stu_rel foreign key(sid) references stu(sid);
六、多表查询(重要)
- 合并结果集查询(UNION、UNION ALL)
- 连接查询
内连接查询 [INNER] JOIN ON
外连接查询 OUTER JOIN ON
左外连接查询 LEFT [OUTER] JOIN
右外连接查询 RIGHT [OUTER] JOIN
全外连接查询(MySQL不支持) FULL JOIN
自然连接查询 NATURAL JOIN - 子查询
- 自连接查询
1、合并结果集查询(UNION、UNION ALL)
作用:合并结果集就是把两个select语句的查询结果合并到一起。
合并结果集有两种方式:
-
-
- UNION:去除重复记录, 例如:SELECT * FROM t1 UNION SELECT * FROM t2;
- UNION ALL:不去除重复记录,例如:SELECT * FROM t1 UNION ALL SELECT * FROM t2;
-
要求:被合并的两个结果:列数、列类型必须相同。

-- 联合查询
CREATE TABLE A(
NAME VARCHAR(10),
score INT
);
CREATE TABLE B(
NAME VARCHAR(10),
score INT
);
-- 批量插入
INSERT INTO A VALUES('a',10),('b',20),('c',30);
INSERT INTO B VALUES('a',10),('b',20),('d',40);
--合并结果集查询
SELECT * FROM A
UNION
SELECT * FROM B;
SELECT * FROM A
UNION ALL
SELECT * FROM B;
2、连接查询(非常重要)
连接查询就是求出多个表的乘积,
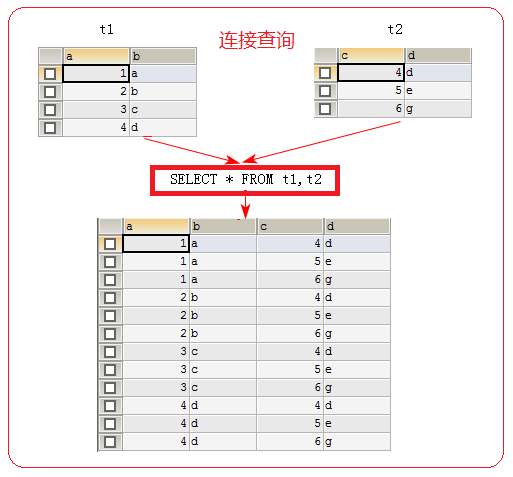
2.1 内连接查询 [INNER] JOIN ON

2.2 外连接查询(左外连接查询、右外连接查询) [OUTER] JOIN ON
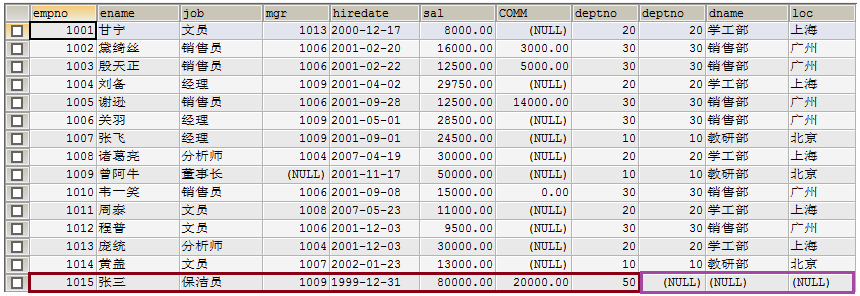
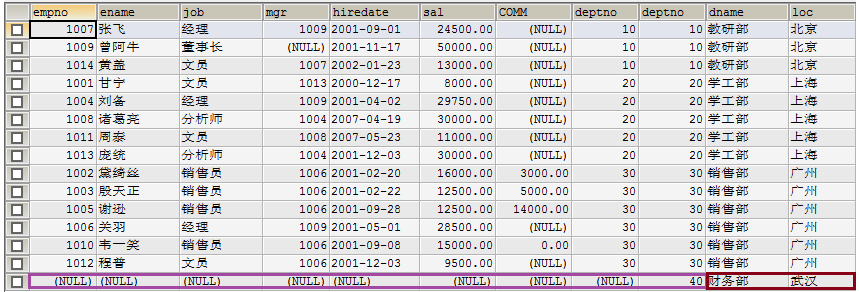
2.3、自然连接查询(NATURAL JOIN)
3、子查询(非常重要)
子查询出现的位置:
-
-
- where后,作为主句的条件来用。
- from后,作表。
-
当子查询出现在where后作为条件时,还可以使用如下关键字:
-
-
- any
- all
-
子查询结果集的形式:
-
-
- 单行单列(用于条件)
- 单行多列(用于条件)
- 多行单列(用于条件)
- 多行多列(用于表)
-
练习1:查询工资高于JONES的员工。
分析:
查询条件:工资>JONES工资,其中JONES工资需要一条子查询。
第一步:查询JONES的工资
SELECT sal FROM emp WHERE ename='JONES';
第二步:查询高于甘宁工资的员工
SELECT * FROM emp WHERE sal>(第一步);
结果:
SELECT * FROM emp WHERE sal>(
SELECT sal FROM emp WHERE ename='JONES');
练习2:查询与SCOTT在同一个部门的员工。
SELECT *FROMemp WHERE depton=(
SELECT depton FROM emp WHERE ename ='SCOTT');
SELECT * FROM emp WHERE depton=(20); -- 两句等价
-
-
-
- 子查询结果集作为条件
- 子查询结果集形式为单行单列
-
-
练习3:查询工资高于30号部门所有人的员工信息。
分析:
法一:
SELECT * FROM emp WHERE sal>(
SELECT MAX(sal) FROM emp WHERE deptno=30);
法二:查询条件:查询工资高于30号部门所有人的工资,其中查询30号部门所有人工资是子查询。高于所有需要使用all关键字。
第一步:查询30号部门所有人的工资(多行单列)
SELECT sal FROM emp WHERE deptno=30;
第二步:查询高于部门编号为30号的部门所有人的工资的员工信息
SELECT * FROM emp WHERE sal > ALL(第一步);
结果:
SELECT * FROM emp WHERE sal > ALL(
SELECT sal FROM emp WHERE deptno=30)
-
-
-
- 子查询结果集作为条件
- 子查询结果集形式为多行单列(当子查询结果集形式为多行单列时可以使用ALL或ANY关键字)
-
-
练习4:查询工作和工资与MARTIN(马丁)完全相同的员工信息。
分析:
查询条件:工作和工资与MARTIN完全相同,这是子查询。
第一步:查询出MARTIN的工作和工资(单行多列)
SELECT job,sal FROM emp WHERE ename='MARTIN';
第二步:查询出与MARTIN工作和工资相同的人
SELECT * FROM emp WHERE (job,sal) IN(第一步);
结果:
SELECT * FROM emp WHERE (job,sal) IN(
SELECT job,sal FROM emp WHERE ename='MARTIN');
练习5:查询有2个以上直接下属的员工信息。(即如果mgr中的数据有出现两次以上一样的,说明该编号对应的人有两个以上的直接下属)
SELECT * FROM emp WHERE empno IN(
SELECT mgr FROM emp GROUP BY mgr HAVING COUNT(mgr)>=2);
-
-
-
- 子查询结果集作为条件
- 子查询结果集形式为单行多列
-
-
练习6:查询员工编号为7788的员工名称、员工工资、部门名称、部门地址
分析:(多表查询,无需子查询)
查询列:员工名称、员工工资、部门名称、部门地址
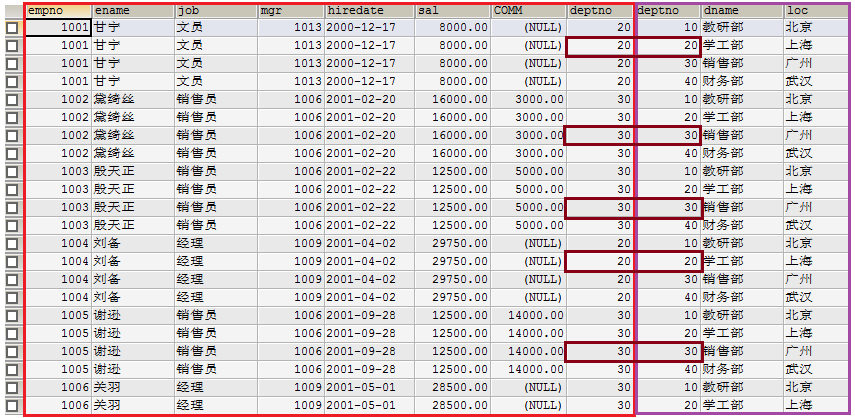
查询表:emp和dept,分析得出,不需要外连接(外连接的特性:某一行(或某些行)记录上会出现一半有值,一半为NULL值)
条件:员工编号为7788
第一步:去除多表,只查一张表,这里去除部门表,只查员工表
SELECT ename, sal FROM emp e WHERE empno=7788;
第二步:让第一步与dept做内连接查询,添加主外键条件去除无用笛卡尔积
SELECT e.ename, e.sal, d.dname, d.loc FROM emp e, dept d WHERE e.deptno = d.deptno AND empno =7788; -- 不用子查询
-- 用子查询(很鸡肋,意义不大)
第二步中的dept表表示所有行所有列的一张完整的表,这里可以把dept替换成所有行,但只有dname和loc列的表,这需要子查询。
第三步:查询dept表中dname和loc两列,因为deptno会被作为条件,用来去除无用笛卡尔积,所以需要查询它。
SELECT dname,loc,deptno FROM dept;
第四步:替换第二步中的dept
SELECT e.ename, e.sal, d.dname, d.loc FROM emp e, (SELECT dname, loc, deptno FROM dept) d WHERE e.deptno=d.deptno AND e.empno=7788;
SELECT e.ename, e.sal, d.dname, d.loc FROM emp e, (SELECT * FROM dept) d WHERE e.deptno=d.deptno AND e.empno=7788;
-
-
-
- 子查询作为表
- 子查询形式为多行多列
-
-
小结:表dept是一张表的表名,表示一张表,
dept AS d(dept d),给表dept起了个新名字d,则d也表示一张表,
dept 等价于 select * from dept。
4、自连接查询
SELECT ename,empno FROM emp WHERE empno = (
SELECT mgr FROMemp WHERE empno =7369);
求7369员工编号和姓名以及该员工的经理编号和姓名
SELECT e1.empno, e1.ename, e2.empno, e2.ename FROM emp e1, emp e2 WHERE e1.mgr = e2.empno AND e1.empno =7369;
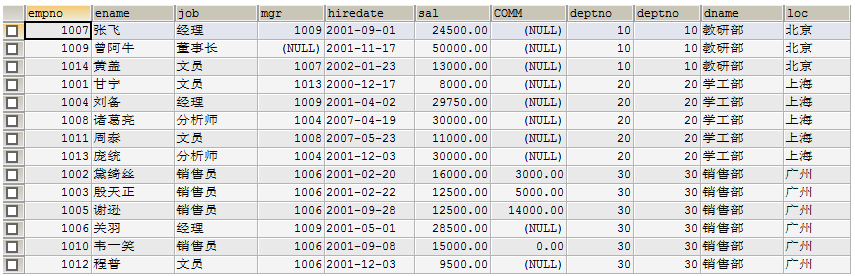
练习:求各个部门薪水最高的员工所有信息
普通版本(会有问题)
SELECT * FROM emp WHERE sal IN(
SELECTMAX(sal) FROM emp GROUP BY deptno);
改进版本
SELECT e1.* FROM emp e1,
(SELECT MAX(sal) maxsal, deptno d FROM emp GROUP BY deptno) e2 --部门最高工资和部分号一起组成的表
WHERE e1.deptno = e2.d AND e1.sal = e2.maxsal;
七、MySQL中的函数
-- 时间、日期相关函数
SELECT ADDTIME('19:52:00','01:01:01'); -- 20:53:01
SELECT CURRENT_DATE(); -- 2017-03-09
SELECT CURRENT_TIME(); -- 20:05:44
SELECT CURRENT_TIMESTAMP(); -- 2017-03-09 20:05:44
SELECT TIME(NOW()); -- 20:07:16
SELECT YEAR(NOW()); -- 2017
SELECT NOW(); -- 2017-03-09 20:08:10
SELECT DATE_ADD(NOW(),INTERVAL 1 DAY); -- 2017-04-10 20:09:45
SELECT DATE_ADD(NOW(),INTERVAL 1 MONTH); -- 2017-04-09 20:09:45
SELECT DATE_ADD(NOW(),INTERVAL -1 YEAR); -- 2016-04-09 20:09:45
-- 字符串相关函数
SELECT CHARSET('tom'); -- utf8 查看字符集
SELECT CONCAT('aaa','bbb'); -- aaabbb 字符串拼接
SELECT CONCAT(ename,job) FORM emp;
SELECT INSTR('admin','d'); -- 2 相当于indexof
SELECT INSTR('admin','f'); -- 0
SELECT LEFT('admin',2); -- ad 从字符串左边起截取2个字符
SELECT RIGHT('admin',2); -- in 从字符串右边起截取2个字符
SELECT REPLACE('black','ack','ue'); -- blue 替换
SELECT STRCMP('a','b'); -- -1 (a-b=-1) strcmp逐字符比较,返回ASCII的差值,但是值只有+1、-1、0
SELECT STRCMP('ab','ab'); -- -1
SELECT CONCAT('#',TRIM(' abc '),'#'),CONCAT('#',LTRIM(' abc '),'#'),CONCAT('#',RTRIM(' abc '),'#'); -- #abc# #abc # # abc#
-- 数学相关函数
SELECT ABS(-5); -- 5
SELECT BIN(10); -- 1010
SELECT FLOOR(12.34); -- 12 向下取整
SELECT FORMAT(100.999,2); -- 101.00 格式化,保留小数位数
八、MySQL数据库的备份与恢复
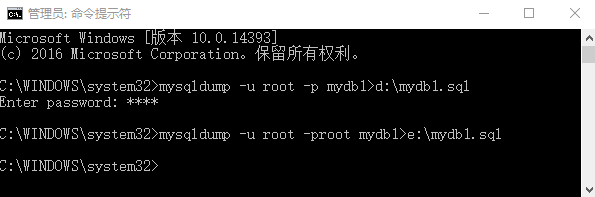
1、生成SQL脚本 导出数据
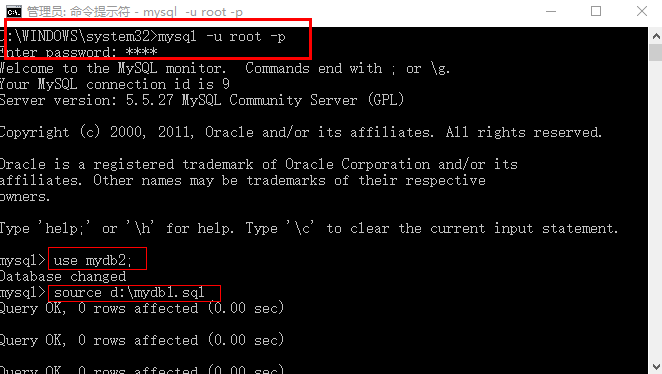
2、执行SQL脚本 恢复数据

【转载文章务必保留出处和署名,谢谢!】

 浙公网安备 33010602011771号
浙公网安备 33010602011771号