报错kernel:NMI watchdog: BUG: soft lockup - CPU#0 stuck for 22s
客户三台云主机报错如下:
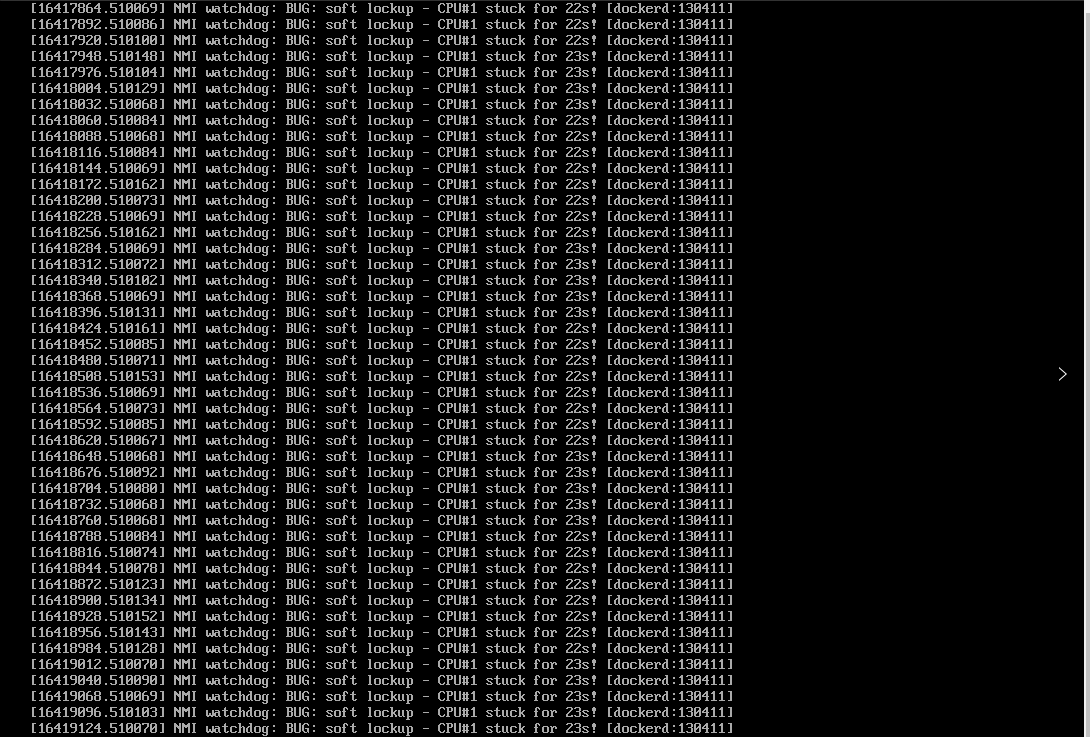
内核软死锁(soft lockup)bug原因分析
Soft lockup名称解释:所谓,soft lockup就是说,这个bug没有让系统彻底死机,但是若干个进程(或者kernel thread)被锁死在了某个状态(一般在内核区域),很多情况下这个是由于内核锁的使用的问题。
Linux内核对于每一个cpu都有一个监控进程,在技术界这个叫做watchdog(看门狗)。通过ps –ef | grep watchdog能够看见,进程名称大概是watchdog/X(数字:cpu逻辑编号1/2/3/4之类的)。
这个进程或者线程每一秒钟运行一次,否则会睡眠和待机。这个进程运行会收集每一个cpu运行时使用数据的时间并且存放到属于每个cpu自己的内核数据结构。在内核中有很多特定的中断函数。
这些中断函数会调用soft lockup计数,他会使用当前的时间戳与特定(对应的)cpu的内核数据结构中保存的时间对比,如果发现当前的时间戳比对应cpu保存的时间大于设定的阀值,他就假设监测进程或看门狗线程在一个相当可观的时间还没有执。
Cpu软锁为什么会产生,是怎么产生的?如果linux内核是经过精心设计安排的CPU调度访问,那么怎么会产生cpu软死锁?那么只能说由于用户开发的或者第三方软件引入,看我们服务器内核panic的原因就是qmgr进程引起。
因为每一个无限的循环都会一直有一个cpu的执行流程(qmgr进程示一个后台邮件的消息队列服务进程),并且拥有一定的优先级。
Cpu调度器调度一个驱动程序来运行,如果这个驱动程序有问题并且没有被检测到,那么这个驱动程序将会暂用cpu的很长时间。
根据前面的描述,看门狗进程会抓住(catch)这一点并且抛出一个软死锁(soft lockup)错误。软死锁会挂起cpu使你的系统不可用。
内核参数kernel.watchdog_thresh(/proc/sys/kernel/watchdog_thresh)系统默认值为10。如果超过2*10秒会打印信息,注意:调整值时参数不能大于60。
虽然调整该值可以延长喂狗等待时间,但是不能彻底解决问题,只能导致信息延迟打印。因此问题的解决,还是需要找到根本原因。
可以打开panic,将/proc/sys/kernel/panic的默认值0改为1,便于定位。
网上查找资料,发现引发CPU死锁的原因有很多种:
* 服务器电源供电不足,导致CPU电压不稳导致CPU死锁
https://ubuntuforums.org/showthread.php?t=2205211
I bought a small (500W) new power supply made by what I feel is a reputable company and made the swap.
GREAT NEWS: After replacing the power supply, the crashes completely stopped!
I wanted to wait a while just to be sure, but it is now a few weeks since the new powersupply went in, and I haven't had a single crash since.
The power supply is not something that I would normally worry about, but in this case it totally fixed my problem.
Thanks to those who read my post, and especially to those who responded.
* vcpus超过物理cpu cores
https://unix.stackexchange.com/questions/70377/bug-soft-lockup-cpu-stuck-for-x-seconds
* 虚机所在的宿主机的CPU太忙或磁盘IO太高
* 虚机的的CPU太忙或磁盘IO太高
https://www.centos.org/forums/viewtopic.php?t=60087
* BIOS KVM开启以后的相关bug,关闭KVM可解决,但关闭以后物理机不支持虚拟化
https://unix.stackexchange.com/questions/70377/bug-soft-lockup-cpu-stuck-for-x-seconds
* VM网卡驱动存在bug,处理高水位流量时存在bug导致CPU死锁
* BIOS开启了超频,导致超频时电压不稳,容易出现CPU死锁
https://ubuntuforums.org/showthread.php?t=2205211
* Linux kernel存在bug
https://unix.stackexchange.com/questions/70377/bug-soft-lockup-cpu-stuck-for-x-seconds
* KVM存在bug
https://unix.stackexchange.com/questions/70377/bug-soft-lockup-cpu-stuck-for-x-seconds
* clocksource tsc unstable on CentOS and cloud Linux with Hyper-V Virtualisation
https://unix.stackexchange.com/questions/70377/bug-soft-lockup-cpu-stuck-for-x-seconds
通过设置clocksource=jiffies可解决
* BIOS Intel C-State开启导致,关闭可解决
https://unix.stackexchange.com/questions/70377/bug-soft-lockup-cpu-stuck-for-x-seconds
https://support.citrix.com/article/CTX127395
http://blog.sina.com.cn/s/blog_906d892d0102vn26.html
* BIOS spread spectrum开启导致
当主板上的时钟震荡发生器工作时,脉冲的尖峰会产生emi(电磁干扰)。spread spectrum(频展)设定功能可以降低脉冲发生器所产生的电磁干扰,脉冲波的尖峰会衰减为较为平滑的曲线。
如果我们没有遇到电磁干扰问题,建议将此项设定为disabled,这栏可以优化系统的性能表现和稳定性;
否则应该将此项设定为enabled。 如果对cpu进行超频,必须将此项禁用。因为即使是微小的脉冲值漂移也会导致超频运行的cpu锁死。
再次强调:CPU超频时,SPREAD SPECTRUM必须关闭,否则容易出现锁死cpu的情况。
说白了就是cpu锁死了,系统不能用,重启即可。(经分析,可能客户在服务器上跑大量高负载程序,导致cpu占用过高)
如果确认不是软件或者程序问题的问题。
解决办法:
追加到配置文件中
#]echo 30 > /proc/sys/kernel/watchdog_thresh
#] tail -1 /proc/sys/kernel/watchdog_thresh
30
临时生效
#]sysctl -w kernel.watchdog_thresh=30
永久生效
#]vim /etc/sysctl.conf
kernel.watchdog_thresh=30

 浙公网安备 33010602011771号
浙公网安备 33010602011771号