C语言博客作业05——指针
0.展示PTA总分

1.本章学习总结
1.1 学习内容总结
•指针做循环变量做法
1.使指针移动,指向下一个地址单元,改变了指针原本指向的位置。
2.下标法,寻找离指针指向位置i个单位的位置,不会改变了指针原本指向的位置。
•字符指针如何表示字符串
用字符指针指向一个字符串的首地址。
•动态内存分配
void *malloc(size_t size);
函数 malloc()分配连续的内存区域,其大小不小于 size,需要强制类型转换。malloc()获得内存区域时,内存中的内容没有初值。
2. ```
void*calloc(size_t n,size_t size);
calloc()函数功能是动态分配n个大小为size的内存空间,需要强制类型转换。calloc()函数会将所申请的内存空间中的每个字节都初始化为0。
3. ```
void * realloc(void * ptr,size_t size);
realloc() 函数可以做到对动态开辟内存大小的调整(既可以往大调整, 也可以往小调整)。ptr为需要调整的内存地址,size为调整后需要的大小(字节数)。
4. ```
void free(void* ptr);
申请的动态内存不再使用时,要及时释放。free()不能重复释放一块内存。在free()函数之后需要将ptr再置空 ,即ptr = NULL;
如果不将ptr置空的话,后面程序如果再通过ptr会访问到已经释放过无效的或者已经被回收再利用的内存, 为保证程序的健壮性, 一般我们都要写ptr = NULL; 。
•指针数组及其应用
指针数组就是存放指针的数组,其本质为数组且每个数组元素是指针。
应用:6-7 输出月份英文名
char* getmonth(int n)
{
char* p[12] = { "January","February","March","April","May","June","July","August","September","October","November","December" };
if (n > 12 || n < 1) return NULL;
return p[n - 1];
}
•二级指针、行指针
二级指针 :int * * ptr:数据类型是int * * ,即指向指针的指针,是个二级地址。
行指针:指向某一行,不指向具体的元素。
•函数返回值为指针
指针函数的定义,顾名思义,指针函数即返回指针的函数。
用指针作为函数返回值时需要注意的一点是,函数运行结束后会销毁在它内部定义的所有局部数据,包括局部变量、局部数组和形式参数等,函数返回的指针请尽量不要指向这些临时数据,
谁都不能保证这些临时的数据一直有效,它们在后续使用过程中可能会引发运行时错误。
1.2 本章学习体会
学会了指针,能够对地址直接进行操作。对于二级指针、行指针、指针数组、指针函数不太理解,也不太会用。
代码量:480行
2.PTA实验作业
2.1 6-4 求出数组中最大数和次最大数
2.1.1 伪代码
int fun(int* a, int n)
{
int t;//交换中间值
int* p;//循环变量
p = a+1;
for (p; p < a + n; p++)
{
寻找最大值
}
for (p = a + 2; p < a + n; p++)
{
寻找次大值
}
return 0;
}
2.1.2 代码截图
int fun(int* a, int n)
{
int t;
int* p;
p = a+1;
for (p; p < a + n; p++)
{
if (*p > * a)
{
t = *p;
*p = *a;
*a = t;
}
}
for (p = a + 2; p < a + n; p++)
{
if (*p > * (a + 1))
{
t = *p;
*p = *(a + 1);
*(a + 1) = t;
}
}
return 0;
}
2.1.3 总结本题的知识点
- 原本的指针不能改变,所以定义一个新指针来做循环变量。
- *的优先级比+来得高,所以a+1需要加括号提高优先级。
2.1.4 PTA提交列表及说明
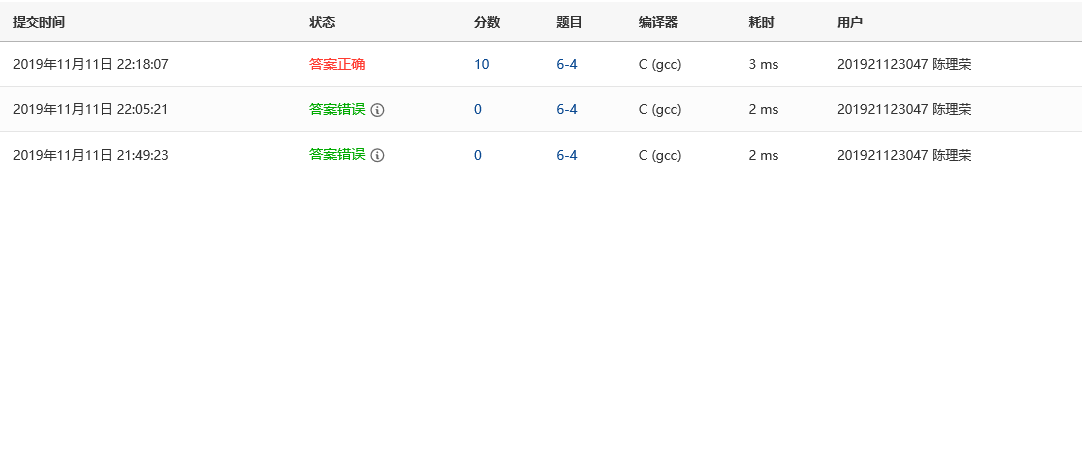
答案错误:没有使用新指针来做循环变量。
答案错误:没有考虑优先级。
2.2 6-9 合并两个有序数组(2)
2.2.1 伪代码
void merge(int* a, int m, int* b, int n)/* 合并a和b到a */
{
int i;
int j=0;
int k=0;
int t;
static int h[100001];
for (i = 0; i < m; i++)
{
h[a[i]]++;//将a中出现过的数值用h储存起来
}
for (i = 0; i < n; i++)
{
h[b[i]]++;//将b中出现过的数值用h储存起来
}
for (i = 0; i < 100001; i++)
{
if (j > m + n - 1) break;
if (h[i] > 0)
{
for (; h[i] > 0;)
{
利用h重构指针所指内容
}
}
}
}
2.2.2 代码截图
void merge(int* a, int m, int* b, int n)/* 合并a和b到a */
{
int i;
int j=0;
int k=0;
int t;
static int h[100001];
for (i = 0; i < m; i++)
{
h[a[i]]++;
}
for (i = 0; i < n; i++)
{
h[b[i]]++;
}
for (i = 0; i < 100001; i++)
{
if (j > m + n - 1) break;
if (h[i] > 0)
{
for (; h[i] > 0;)
{
a[j] = i;
j++;
h[i]--;
}
}
}
}
2.2.3 总结本题的知识点
题目并不难,但数据量较大,因此需要较为简洁高效的代码来降低时间和空间复杂度。因此使用了h数组来存放数值。
2.2.4 PTA提交列表及说明
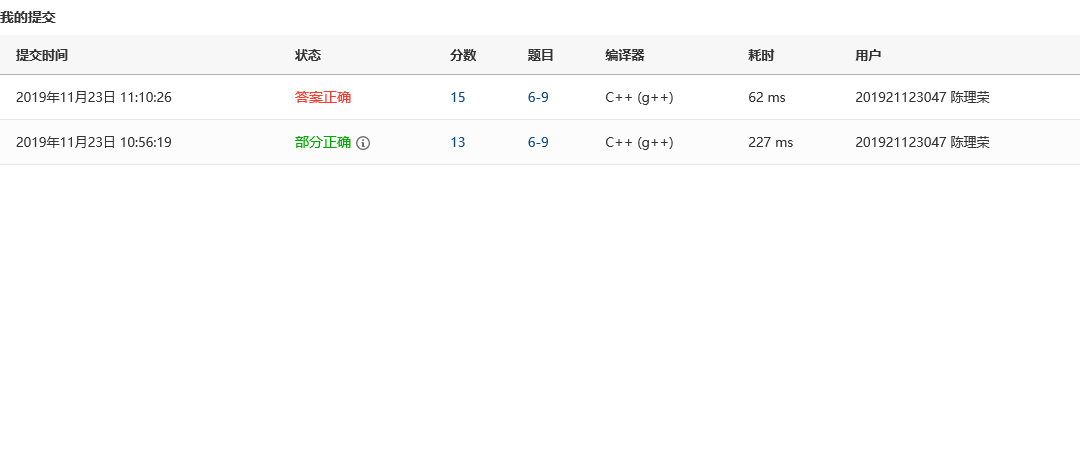
部分正确:运行超时,因为是先将b接到a后面,再用冒泡排序法进行排序,时间复杂度太高。
2.3 7-5 删除字符串中的子串
2.3.1 伪代码
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <ctype.h>
int main()
{
char s1[100];
char s2[100];
char* p;
int l;
输入s1,s2;
s2长度;
s2[l - 1] = 0;
l--;
while (1)
{
寻找s2在s1的首地址;
*p = 0;
strcat(s1, p + l);
}
printf("%s", s1);
}
2.3.2 代码截图
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <ctype.h>
int main()
{
char s1[100];
char s2[100];
char* p;
int l;
fgets(s1, 100, stdin);
fgets(s2, 100, stdin);
l = strlen(s2);
s2[l - 1] = 0;
l--;
while (1)
{
p = strstr(s1, s2);
if (p == NULL) break;
*p = 0;
strcat(s1, p + l);
}
printf("%s", s1);
}
2.2.3 总结本题的知识点
- 将s2最后的'\n'改为'\0'。
- 使用strstr寻找s2在s1中的首地址
- NULL的使用。
2.3.4 PTA提交列表及说明
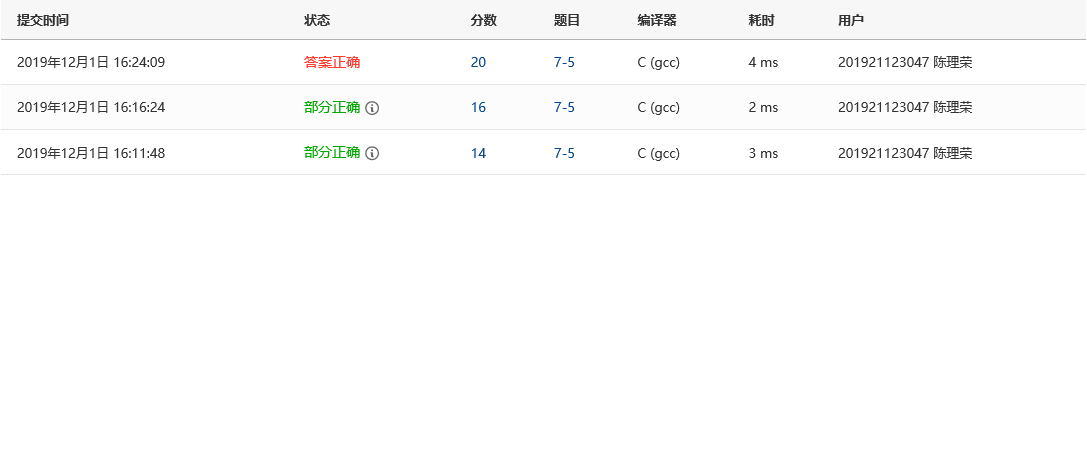
部分正确:使用fgets输入s2,最后的字符是'\n',且s2的长度不正确。
3.阅读代码
7-4 说反话-加强版
#include <stdio.h>
#include <string.h>
int main()
{
char c[500000];
char a;
int i=0,j, count = 0,flag=0;
while ((a = getchar()) != '\n')
{
if (a != ' ')
{
flag = 1;//遇到单词
c[i++] = a;
count = 0;//重置空格数量
}
else if (count > 0) continue;//已有一个空格
else if(flag)//1==空格前有单词
{
c[i++] = a;
count++;//标记一个空格
}
}
count = 0;
i--;
for (i; i >= 0; i--)
{
if (c[i] != ' ')
{
count++;//统计单词的字母数量
}
else if (c[i] == ' ' && count > 0)//遇到空格,结束统计,开始输出
{
for (j = i + 1; j <= i + count; j++)
{
printf("%c", c[j]);
}
printf(" ");
count=0;
}
}
for (j = i + 1; j <= i + count; j++) //最后一个单词
{
printf("%c", c[j]);
}
return 0;
}
这道题我一开始是想着全部输入再进行查找,但是失败了。而这份代码是边输入边做处理,这跟以往我的方法截然不同。这样子就将输入和遍历两次循环变为一次,大大地节约了时间。
而且它对于细节的处理也十分到位,例如flag的使用,最后一个单词的特殊处理。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号