
搞定短视频!批量下载快手视频(附源码)

大家好,我是辰哥~
相信大家都接触了短视频平台,比如某音、某手等平台,竟然大家都熟悉了,那么今天辰哥分享的技术是:在某手上搜索视频,并实现下载!
01 获取搜索链接
编写过接口或者开发过网站的小伙伴都知道,对一个服务器上的资源进行请求时,是通过访问链接(接口),服务器进行响应返回数据。
1.搜索请求链接
因此,我们第一步先获取到搜索的请求链接,这里辰哥通过抓取数据包的方式进行获取。
这里通过mitmproxy抓取某手小程序,如果不清楚这个技术操作的小伙伴,可以参考我之前的一篇文章(以【某程旅行】为例,讲述小程序爬虫技术),该文章从0到1讲解了如何使用mitmproxy采集小程序。
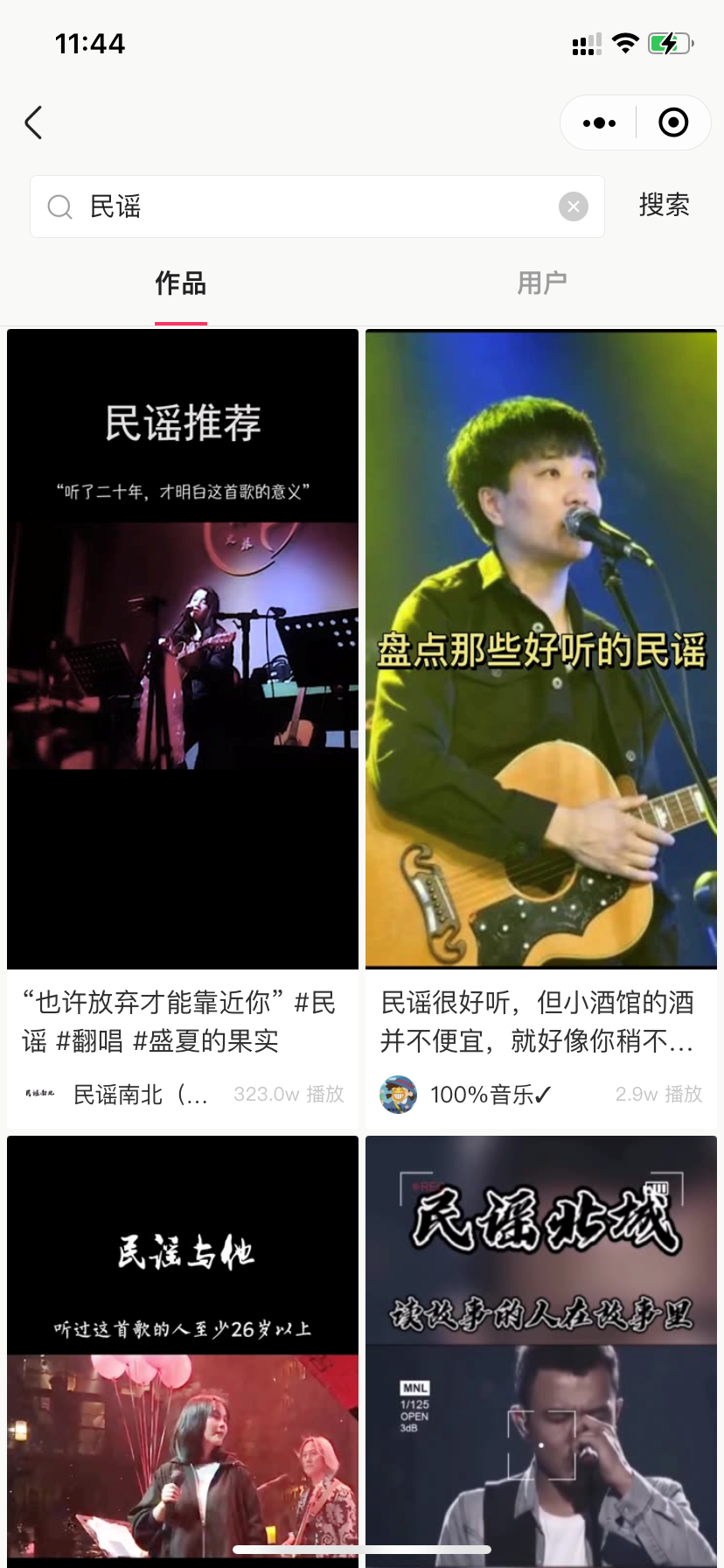
比如搜索:民谣,在抓包页面查看数据包,找到下面这个数据包
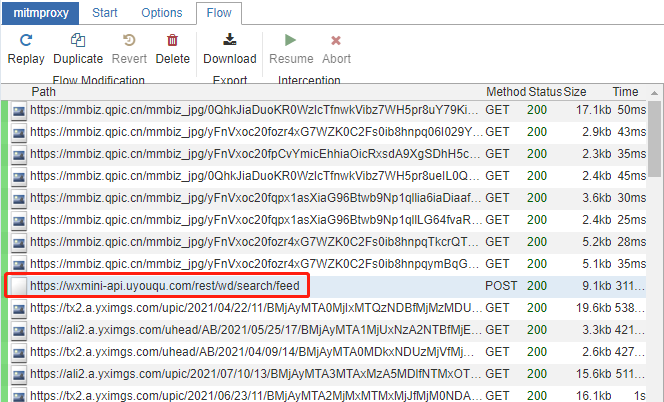
点击数据包


可以看到搜索链接的请求是post方式,以及请求头headers和请求参数,请求参数中keyword是搜索的关键词,通过修改keyword就可以获取到不同的内容。
2.分析数据包
通过查看返回的数据,可以发现所有的视频内容都在字段feeds中

提取字段:视频地址、用户名、封面图、视频名称
mp4_url = i['mainMvUrls'][0]['url']
userName = i['userName']
pic_url = i['coverUrls'][0]['url']
caption = i['caption']
02 请求数据
清楚了数据包的请求方式和参数,以及返回的数据,接着我们开始通过Python去构造请求和处理响应数据。
请求头和请求参数
headers = {
'content-type':'application/json',
'cookie':'自己的cookie'
}
s = json.dumps({
"keyword": "民谣",
"pcursor": "",
"ussid": ""
})
请求地址:
url = 'https://wxmini-api.uyouqu.com/rest/wd/search/feed'
r = requests.post(url, data=s,headers=headers).json()
打印输出结果:

03 保存数据
我们将视频和对应的封面图下载保存到本地,这里新建两个函数,一个是下载视频,一个是下载封面图。
下载视频
#下载视频
def download_mp4(mp4_name,mp4_url):
dir = str(time.strftime('%y%m%d', time.localtime()))
dir_path = "/"+dir
# 判断文件夹是否存在
if not os.path.exists(dir_path):
os.mkdir(dir_path)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36'
}
r = requests.get(mp4_url, headers=headers, stream=True)
if r.status_code == 200:
# 截取图片文件名
with open(dir_path+"/"+mp4_name+".mp4", 'wb') as f:
f.write(r.content)
下载封面图
#下载图片
def download_img(img_name,img_url):
dir = str(time.strftime('%y%m%d', time.localtime()))
dir_path = "/"+dir
# 判断文件夹是否存在
if not os.path.exists(dir_path):
os.mkdir(dir_path)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36'
}
r = requests.get(img_url, headers=headers, stream=True)
if r.status_code == 200:
# 截取图片文件名
with open(dir_path+"/"+img_name+".jpg", 'wb') as f:
f.write(r.content)
视频和封面图都保存到当天日期命名的文件夹中,如果没有该文件夹则自动创建。
调用这两个函数
#开始下载图片
download_img(caption,pic_url)
#开始下载视频
download_mp4(caption,mp4_url)
执行结束后,保存结果:
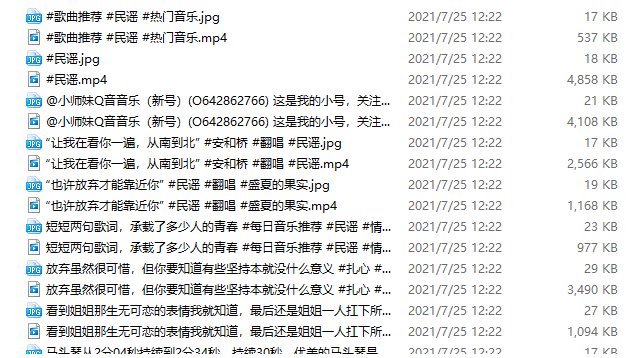
可以看到封面图和视频都保存成功!其名为是以视频名称对两者进行命名。
04 小结
本文讲解了某手搜索视频下载的技术,对于新手学习来说还是一个不错的可以练习的小爬虫,想学习的小伙伴,一定要动手尝试****!一定要动手尝试****!一定要动手尝试!
耐得住寂寞,才能登得顶
Gitee码云:https://gitee.com/lyc96/projects

 浙公网安备 33010602011771号
浙公网安备 33010602011771号