可视化分析中国500强排行榜数据后,我发现了...
1
前言
今天来跟大家分析一下2020年中国500强企业排行榜数据,从不同角度去对数据进行统计分析,可视化展示。
本文从开始到最后发文,花费了一天时间(精心制作),保证以高质量文章给大家阅读,麻烦给个赞和在看,谢谢
文中只是给出部分代码,文末有完整代码获取方式(包括数据和全部代码)
主要分析内容:
中国500强企业-省份分布。
中国500强企业-营业收入年增率。中国500强企业-营业收入年减率。中国500强企业-利润年增率。中国500强企业-利润年减率。中国500强企业-排名上升最快。中国500强企业-排名下降最快。中国500强企业-资产区间分布。中国500强企业-市值区间分布。中国500强企业-营业收入区间分布。中国500强企业-利润区间分布。中国500强企业-排名前10营业收入、利润、资产、市值、股东权益等情况。
下面开始从数据采集到数据统计分析,最后进行可视化!!!
2
数据采集
1.数据源
http://www.fortunechina.com/fortune500/c/2020-07/27/content_369925.htm

2.开始爬取
获取企业列表
url="http://www.fortunechina.com/fortune500/c/2020-07/27/content_369925.htm"
res = requests.get(url,headers=headers)
res.encoding = 'utf-8'
text = res.text
获取企业对应url
for i in range(0,len(table_tr)):
try:
#name = i.xpath('.//td/a/text()')[0]
href = table_tr[i].xpath('.//td/a/@href')[0].replace("../../../../","http://www.fortunechina.com/")
column_list = get_detail(href)
for k in range(0,len(column_list)):
outws.cell(row=count, column=k+1, value=column_list[k])
print(count)
count = count+1
except:
pass
获取每一个企业相关数据
name = selector.xpath('//*[@class="comp-name"]/text()')[0]
r1 = selector.xpath('//*[@class="con"]/em[@class="r1"]/text()')[0]
r2 = selector.xpath('//*[@class="con"]/span/em/font[@class="ft-red"]/text()')[0]
address = selector.xpath('//*[@class="info"]/p')[0].xpath('.//text()')[0].replace(" ", "")
table_tbody_tr = selector.xpath('//*[@class="table"]/table/tr')
3.保存到Excel
outwb = openpyxl.Workbook()
outws = outwb.create_sheet(index=0)
outws.cell(row=1, column=1, value="企业名称")
outws.cell(row=1, column=2, value="2020年排名")
outws.cell(row=1, column=3, value="2019年排名")
outws.cell(row=1, column=4, value="总部地址")
outws.cell(row=1, column=5, value="营业收入")
outws.cell(row=1, column=6, value="营业收入年增减")
outws.cell(row=1, column=7, value="利润")
outws.cell(row=1, column=8, value="利润年增减")
outws.cell(row=1, column=9, value="资产")
outws.cell(row=1, column=10, value="市值")
outws.cell(row=1, column=11, value="股东权益")
outwb.save("中国500强排行榜数据.xlsx") # 保存
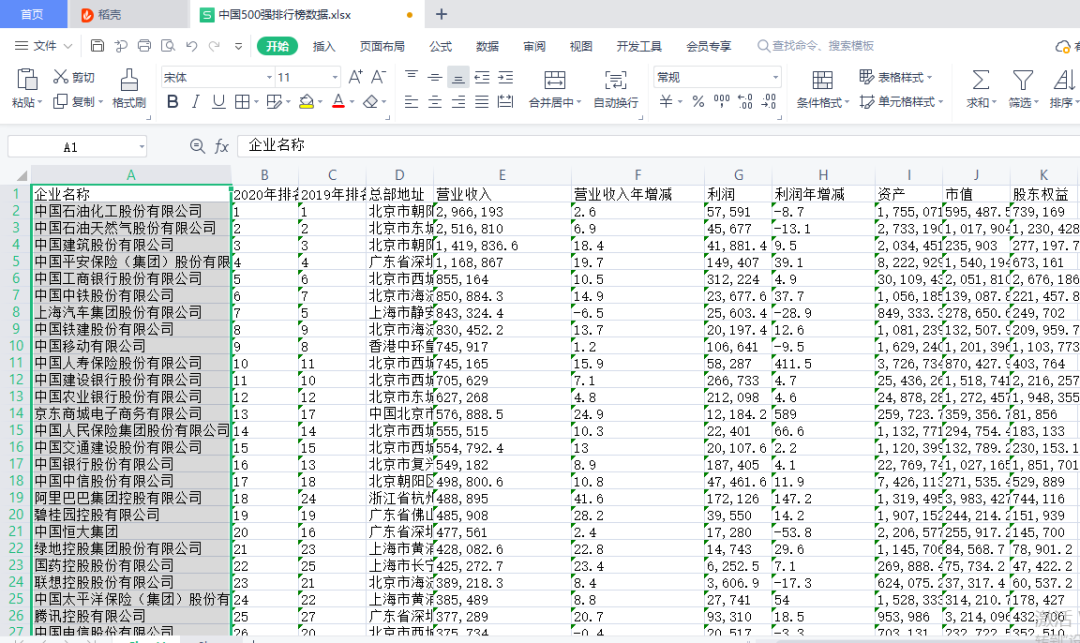
数据就已经保存到Excel中,下面开始进行统计分析,可视化!
3
可视化分析
1.省份分布
导入相关可视化库
from pyecharts import options as opts
from pyecharts.charts import Line
from pyecharts.charts import Map
import pandas as pd
from pyecharts import options as opts
from pyecharts.globals import ThemeType
from pyecharts.charts import Bar
统计数据

从excel中中取出:总部地址,然后取出前两位(省份),统计每一个省份的500强分布情况
address = pd_data['总部地址']
address = address.tolist()
address_03 = []
for i in address:
###取省份(前两位)
address_03.append(i[0:2])
data =[]
address_03_set = set(address_03) #address_03_set是另外一个列表,里面的内容是address_03里面的无重复 项
for item in address_03_set:
data.append((item,address_03.count(item)))
地图可视化
def map_china() -> Map:
c = (
Map()
.add(series_name="企业数量", data_pair=data, maptype="china",zoom = 1,center=[105,38])
.set_global_opts(
title_opts=opts.TitleOpts(title="中国500强企业省份分布"),
visualmap_opts=opts.VisualMapOpts(max_=9999,is_piecewise=True,
pieces=[{"max": 9, "min": 0, "label": "0-9","color":"#FFE4E1"},
{"max": 99, "min": 10, "label": "10-99","color":"#FF7F50"},
{"max": 499, "min": 100, "label": "100-499","color":"#F08080"},
{"max": 999, "min": 500, "label": "500-999","color":"#CD5C5C"},
{"max": 9999, "min": 1000, "label": ">=1000", "color":"#8B0000"}]
)
)
)
return c
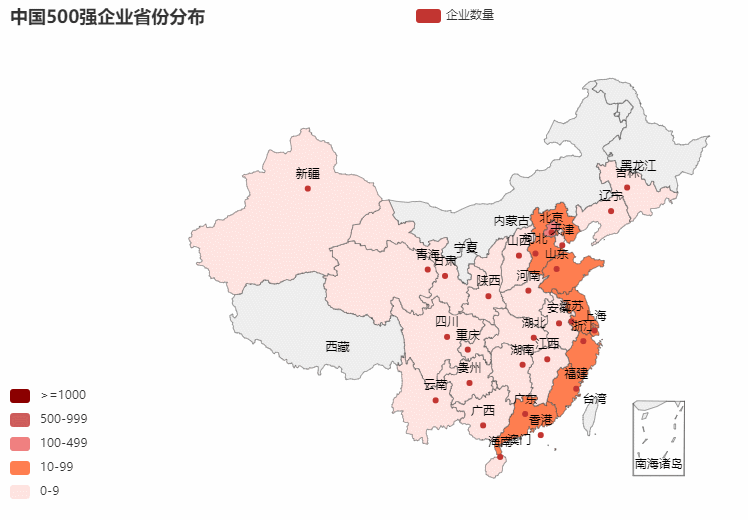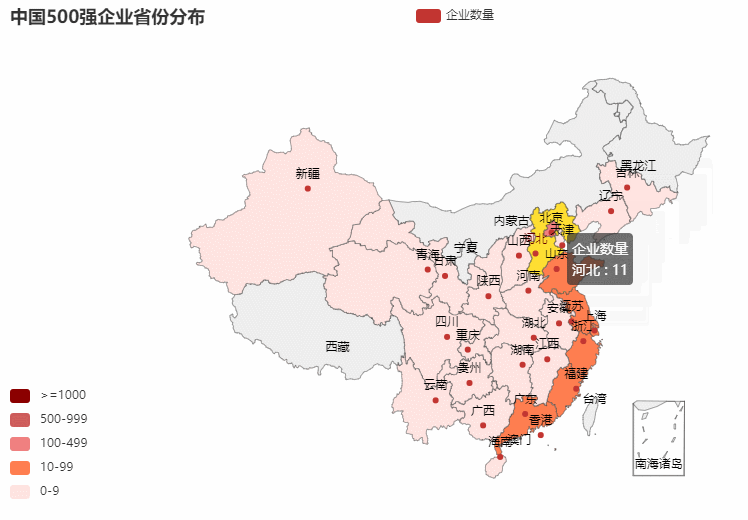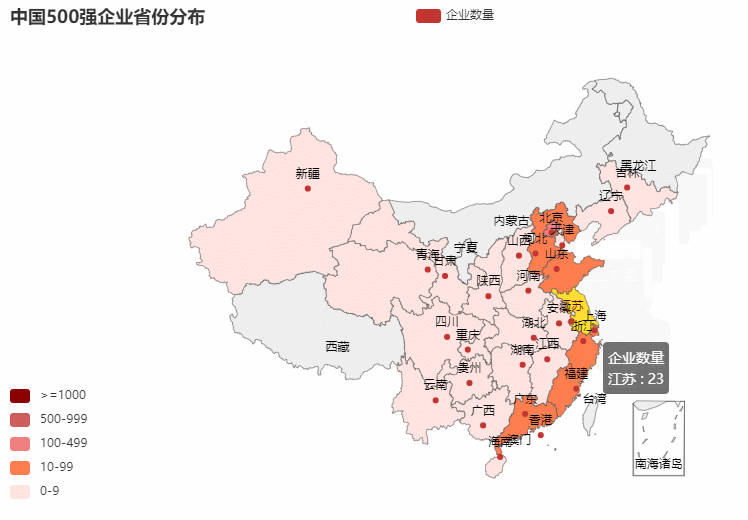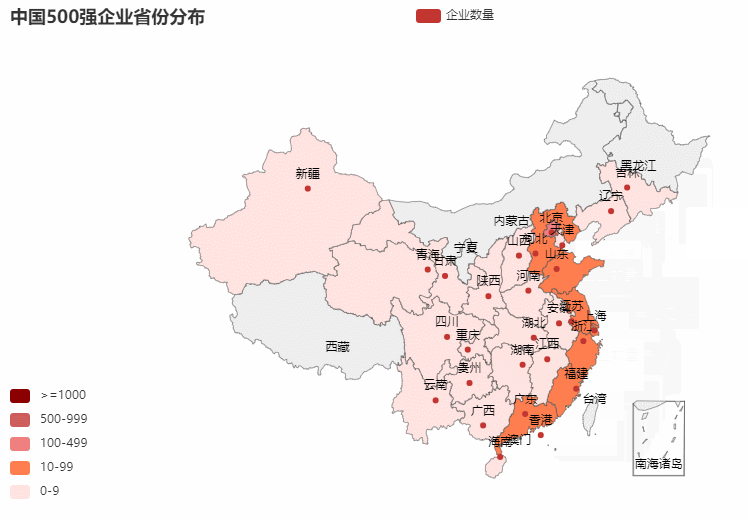
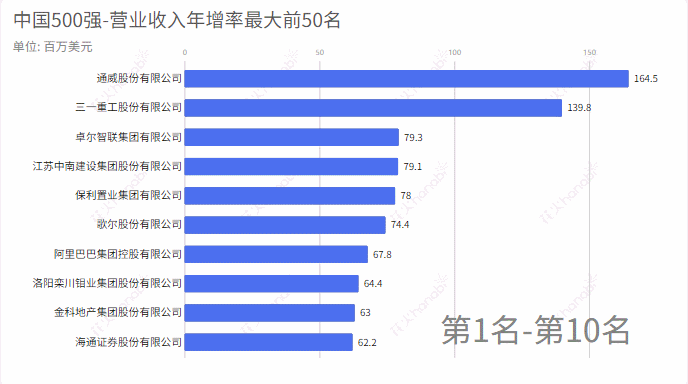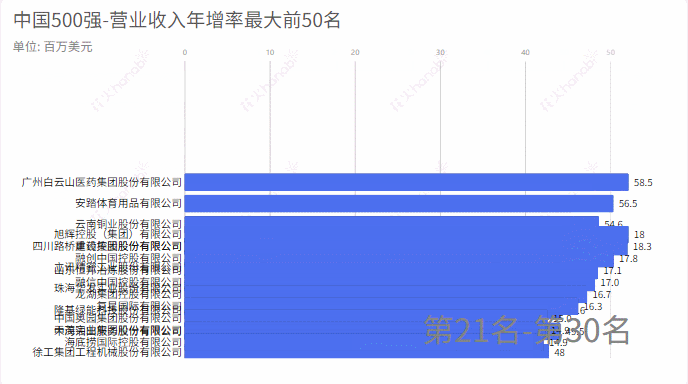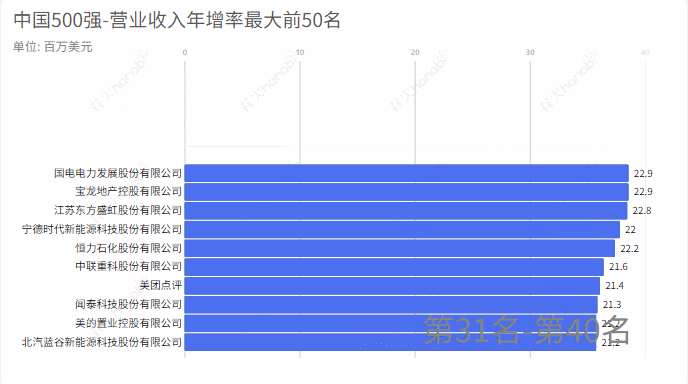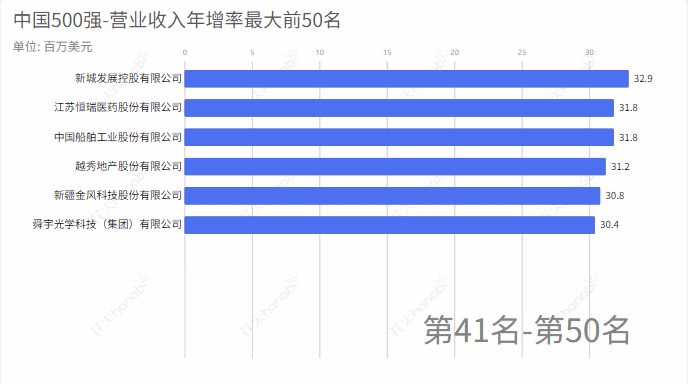
2.营业收入年增率

从excel中中取出:营业收入年增减,统计增加率最大的前50名和减少率(负数)最大的前50名
income_rate = pd_data['营业收入年增减']
compare_name = pd_data['企业名称']
income_rate = income_rate.tolist()
compare_name = compare_name.tolist()
m = income_rate
# 求一个list中最大的50个数,并排序
max_number = heapq.nlargest(50, m)
# 最大的2个数对应的,如果用nsmallest则是求最小的数及其索引
max_index = map(m.index, heapq.nlargest(50, m))
# max_index 直接输出来不是数,使用list()或者set()均可输出
#print(set(max_index)) ###{235, 140, 273, 148, 86}
max_index = list(set(max_index))
#ss = [m.index(j) for j in max_number]
name =[compare_name[k] for k in set(max_index)]
outwb = openpyxl.Workbook()
outws = outwb.create_sheet(index=0)
3.营业收入年减率
income_rate = income_rate.tolist()
compare_name = compare_name.tolist()
m = income_rate
# 求一个list中最小的50个数,并排序
min_number = heapq.nsmallest(60, m)
min_index = [m.index(j) for j in min_number]
name =[compare_name[k] for k in set(min_index)]
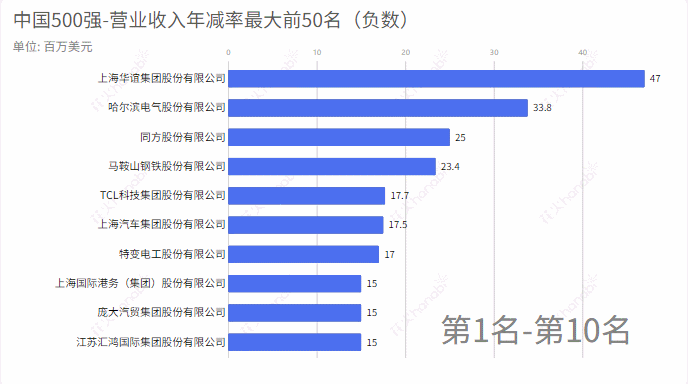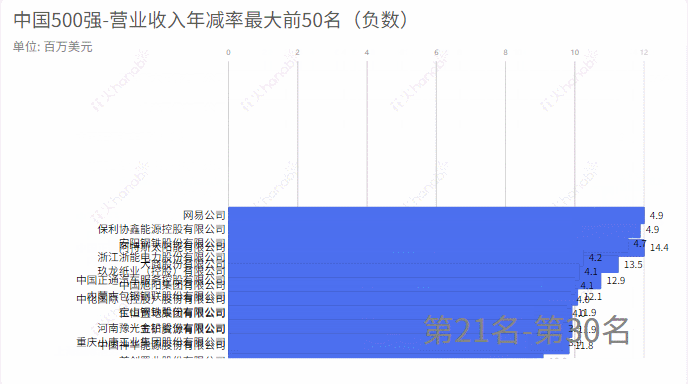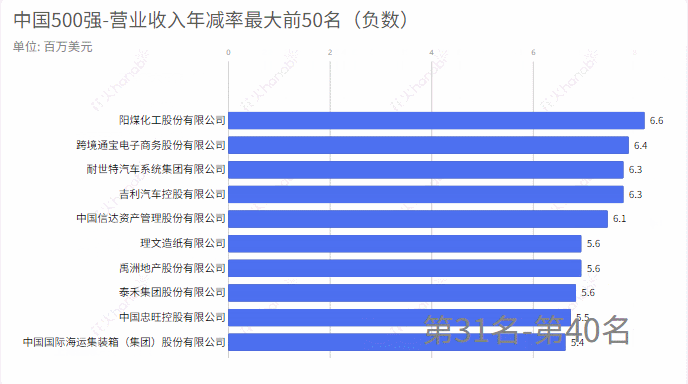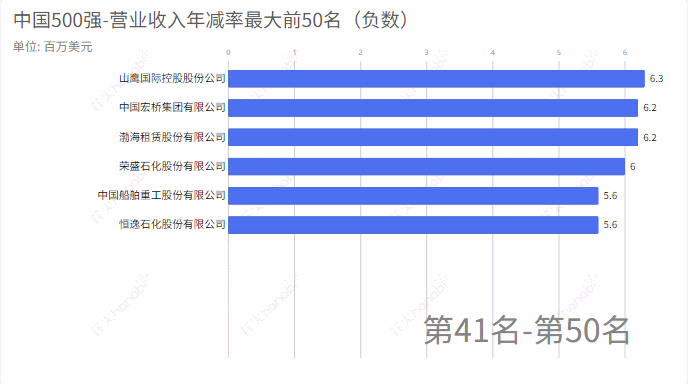
4.利润年增率

从excel中中取出:利润年增减,统计增加率最大的前50名和减少率(负数)最大的前50名

5.利润年减率
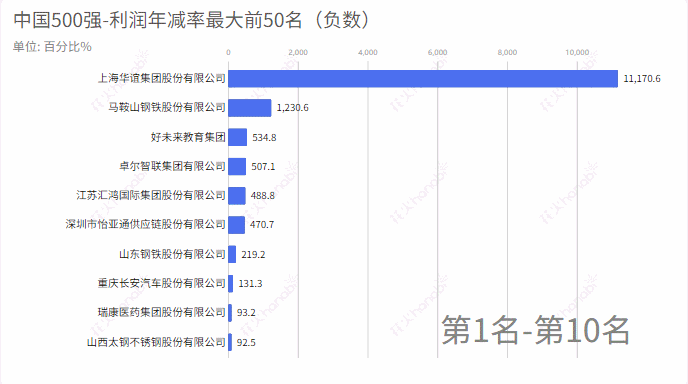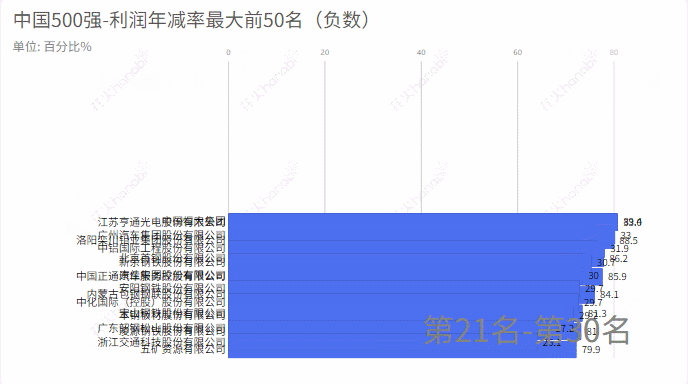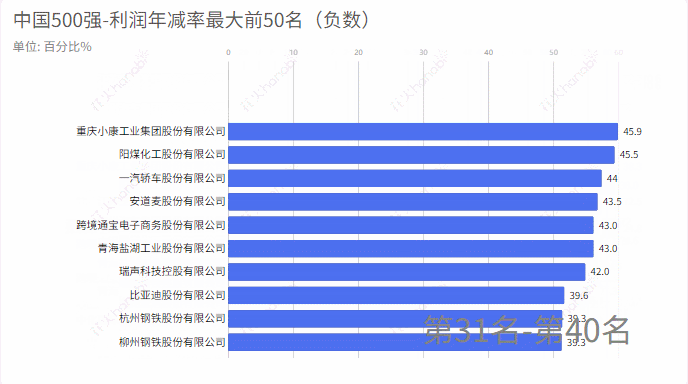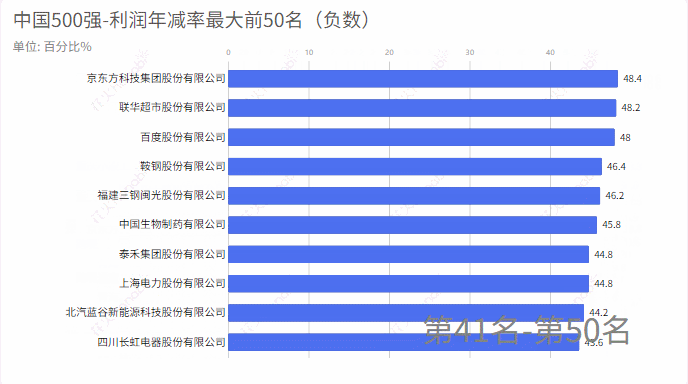
6.排名上升最快20家企业

从excel中中取出:2020年排名和2019年排名,进行对比,统计排名上升最大的前20家企业,和排名下降最大的前20家企业。
###折线图
def LinePic(x_data,y_data,name):
(
Line()
# 进行全局设置
.set_global_opts(
tooltip_opts=opts.TooltipOpts(is_show=True), # 显示提示信息,默认为显示,可以不写
xaxis_opts=opts.AxisOpts(type_="category"),
yaxis_opts=opts.AxisOpts(
type_="value",
axistick_opts=opts.AxisTickOpts(is_show=True),
splitline_opts=opts.SplitLineOpts(is_show=True),
),
)
# 添加x轴的点
.add_xaxis(xaxis_data=x_data)
# 添加y轴的点
.add_yaxis(
series_name=name,
y_axis=y_data,
symbol="emptyCircle",
is_symbol_show=True,
label_opts=opts.LabelOpts(is_show=True),
)
# 保存为一个html文件
.render(name+".html")
)

7.排名下降最快20家企业
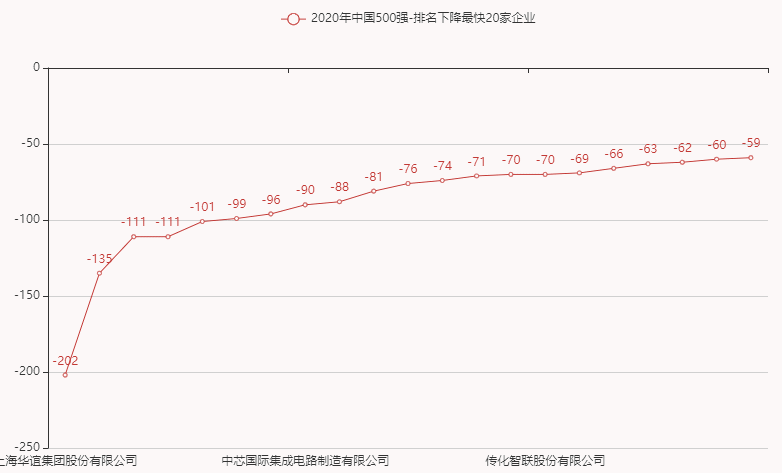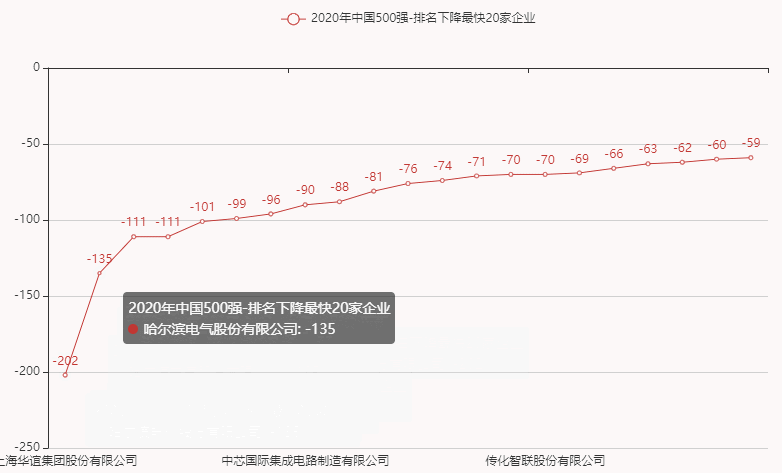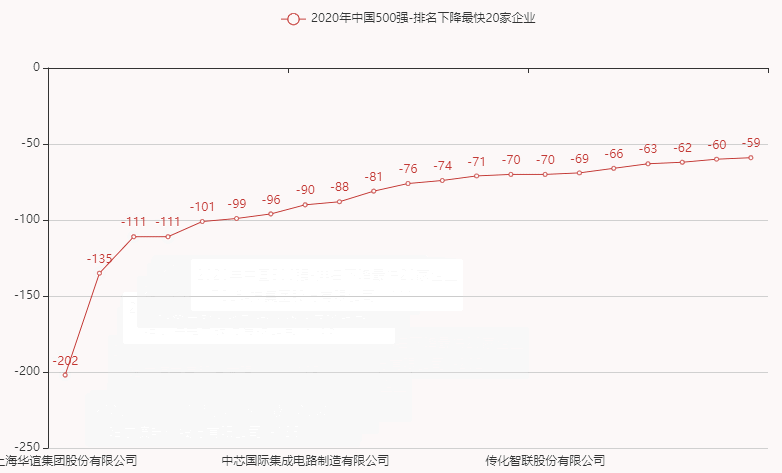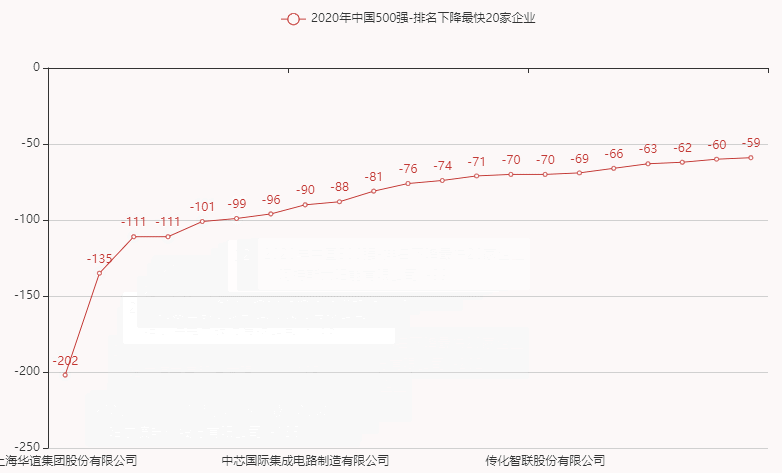
8.资产区间分布

从excel中中取出:资产,为9000 间隔进行区间划分,并统计每一个区间的个数。
for k, g in groupby(sorted(assets_list), key=lambda x: x // 90000):
name.append(str(k * 90000) + "~" + str((k + 1) * 90000 - 1))
dict_value.append(int(len(list(g))))

9.市值区间分布

从excel中中取出:市值,为7000 间隔进行区间划分,并统计每一个区间的个数。
for k, g in groupby(sorted(assets_list), key=lambda x: x // 7000):
name.append(str(k * 7000) + "~" + str((k + 1) * 7000 - 1))
dict_value.append(int(len(list(g))))
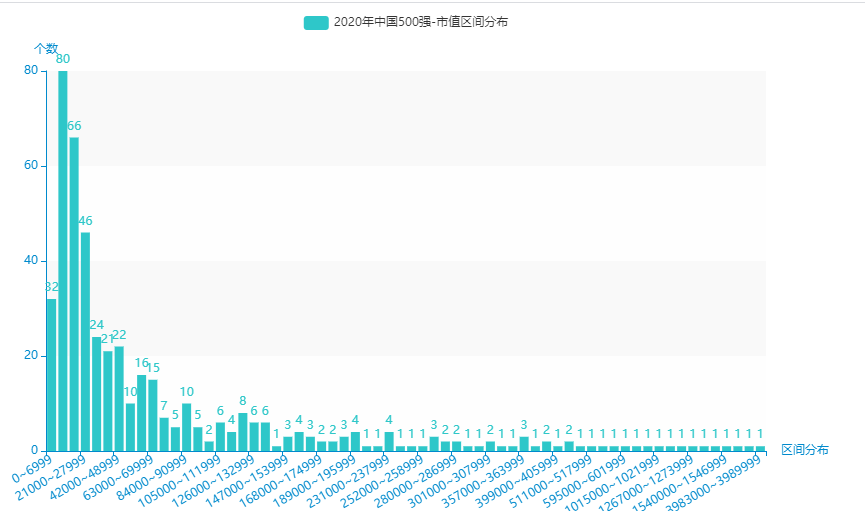
10.营业收入区间分布

从excel中中取出:营业收入,为50000 间隔进行区间划分,并统计每一个区间的个数。
for k, g in groupby(sorted(assets_list), key=lambda x: x // 50000):
name.append(str(k * 50000) + "~" + str((k + 1) * 50000 - 1))
dict_value.append(int(len(list(g))))
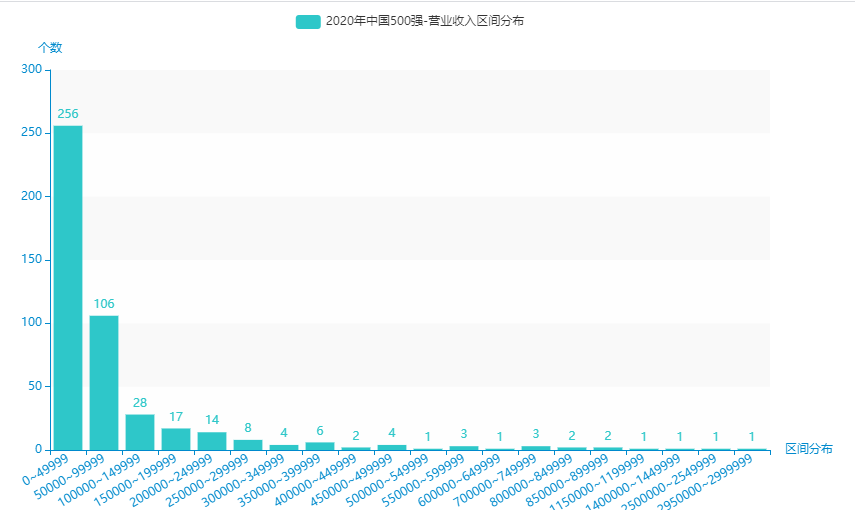
11.利润区间分布

从excel中中取出: 利润,为5000 间隔进行区间划分,并统计每一个区间的个数。
for k, g in groupby(sorted(assets_list), key=lambda x: x//5000):
name.append(str(k*5000)+"~"+str((k+1)*5000-1))
dict_value.append(int(len(list(g))))

12.中国500强企业-排名前10营业收入、利润、资产、市值、股东权益
从excel中中取出排名前10: 营业收入、利润、资产、市值、股东权益、
name = pd_data['企业名称'][0:11].tolist()
data_1 = pd_data['营业收入'][0:11].tolist()
data_2 = pd_data['利润'][0:11].tolist()
data_3 = pd_data['资产'][0:11].tolist()
data_4 = pd_data['市值'][0:11].tolist()
data_5 = pd_data['股东权益'][0:11].tolist()
# 链式调用
c = (
Bar(
init_opts=opts.InitOpts( # 初始配置项
theme=ThemeType.MACARONS,
animation_opts=opts.AnimationOpts(
animation_delay=1000, animation_easing="cubicOut" # 初始动画延迟和缓动效果
))
)
.add_xaxis(xaxis_data=name) # x轴
.add_yaxis(series_name="营业收入", yaxis_data=cleardata(data_1)) # y轴
.add_yaxis(series_name="利润", yaxis_data=cleardata(data_2)) # y轴
.add_yaxis(series_name="资产", yaxis_data=cleardata(data_3)) # y轴
.add_yaxis(series_name="市值", yaxis_data=cleardata(data_4)) # y轴
.add_yaxis(series_name="股东权益", yaxis_data=cleardata(data_5)) # y轴
.set_global_opts(
title_opts=opts.TitleOpts(title='', subtitle='排名前10经济情况', # 标题配置和调整位置
title_textstyle_opts=opts.TextStyleOpts(
font_family='SimHei', font_size=25, font_weight='bold', color='red',
), pos_left="90%", pos_top="10",
),
xaxis_opts=opts.AxisOpts(name='企业名称', axislabel_opts=opts.LabelOpts(rotate=20)),
# 设置x名称和Label rotate解决标签名字过长使用
yaxis_opts=opts.AxisOpts(name='单位:百万美元'),
)
.render("2020年中国500强-排名前10名经济情况.html")
)
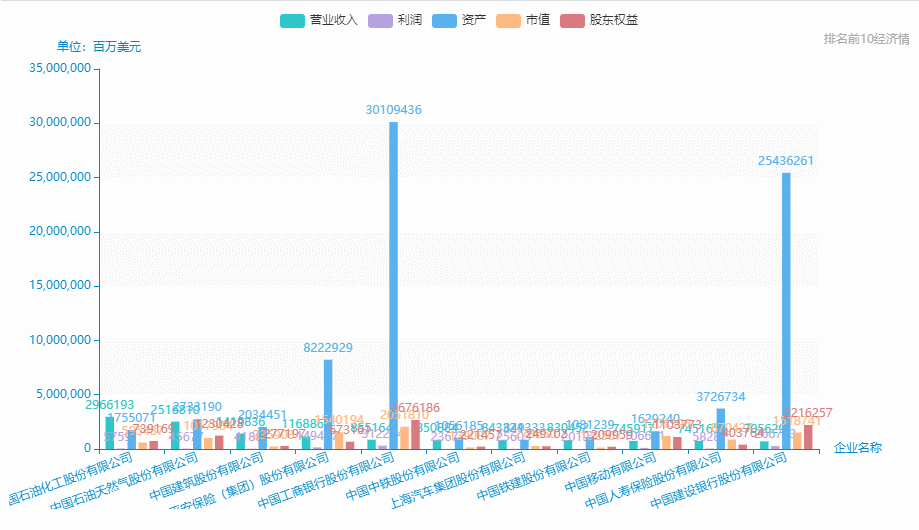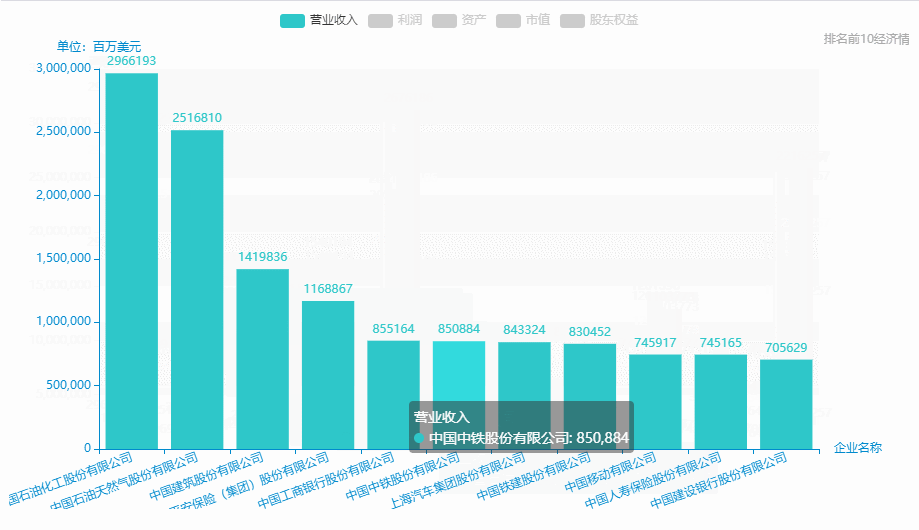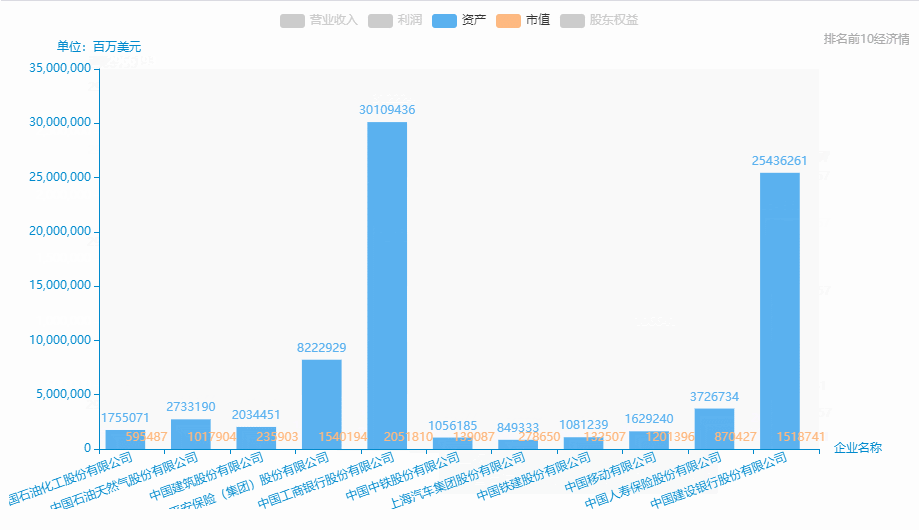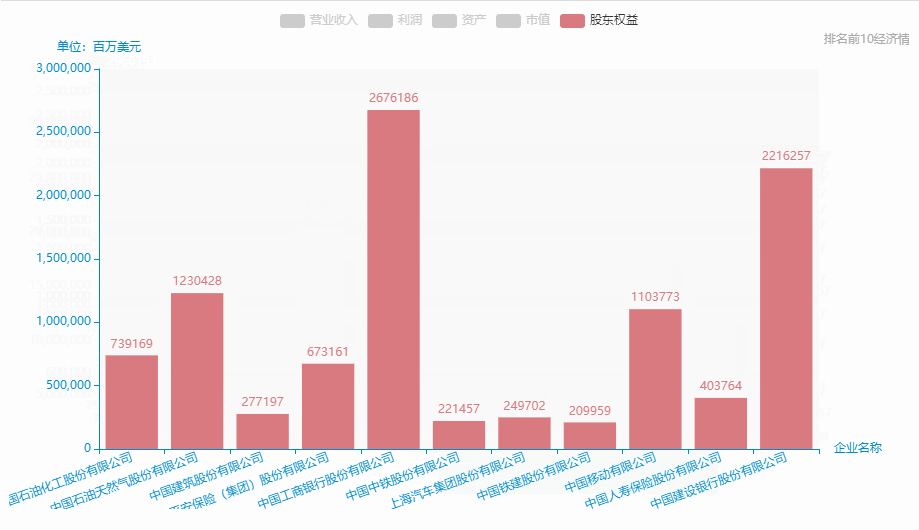
4
总结
本文主要对以下12个方面进行统计分析,最后绘制可视化图
中国500强企业-省份分布。
中国500强企业-营业收入年增率。中国500强企业-营业收入年减率。中国500强企业-利润年增率。中国500强企业-利润年减率。中国500强企业-排名上升最快。中国500强企业-排名下降最快。中国500强企业-资产区间分布。中国500强企业-市值区间分布。中国500强企业-营业收入区间分布。中国500强企业-利润区间分布。中国500强企业-排名前10营业收入、利润、资产、市值、股东权益等情况。
如果大家对本文代码源码感兴趣,扫码关注『Python爬虫数据分析挖掘』后台回复:中国500强 ,获取完整代码!
本文从开始到最后发文,花费了一天时间(精心制作),保证以高质量文章给大家阅读,麻烦给个赞和在看,谢谢
最后说一声:原创不易,求给个赞 、在看
、在看 、评论
、评论
------------- 推荐阅读 -------------
高质量推荐
1.教你解决禁止F12、调试Debugger、丑化JS等反爬
可视化篇
1.爬取3w条『各种品牌』笔记本电脑数据,统计分析并进行可视化展示!真好看~
2.python爬取7w+『赘婿』弹幕,发现弹幕比剧还精彩!
3.爬取1907条『课程学习』数据,分析哪类学习资源最受大学生青睐
4.python爬取各类基金数据,以『动图可视化』方式展示基金的涨跌情况
5.python爬取『大年初一』热映电影,以『可视化及词云秀』方式带你了解热映电影
6.python爬取淘宝全部『螺蛳粉』数据,看看你真的了解螺蛳粉吗?
8.王者荣耀白晶晶皮肤1小时销量突破千万!分析网友评论我发现了原因
9.分析各类基金近一年『日涨幅』流水线动态图!哭了,真是跌妈不认!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号