手把手教你实现『B站直播』弹幕实时分析
大家好,我是阿辰,今天来教大家如何实现『B站直播』弹幕实时分析
思路:采集直播弹幕,然后通过情感分析,不同时间点的评论数,高频词统计
一、采集直播弹幕
首先在B站随意打开一个直播房间
https://live.bilibili.com/22080761?hotRank=0&session_id=acbf4a0396f4c22_E68865D5-1DD6-4677-859D-4A81FC5B86C6&visit_id=64j0r30ef8c0
房间号:22080761
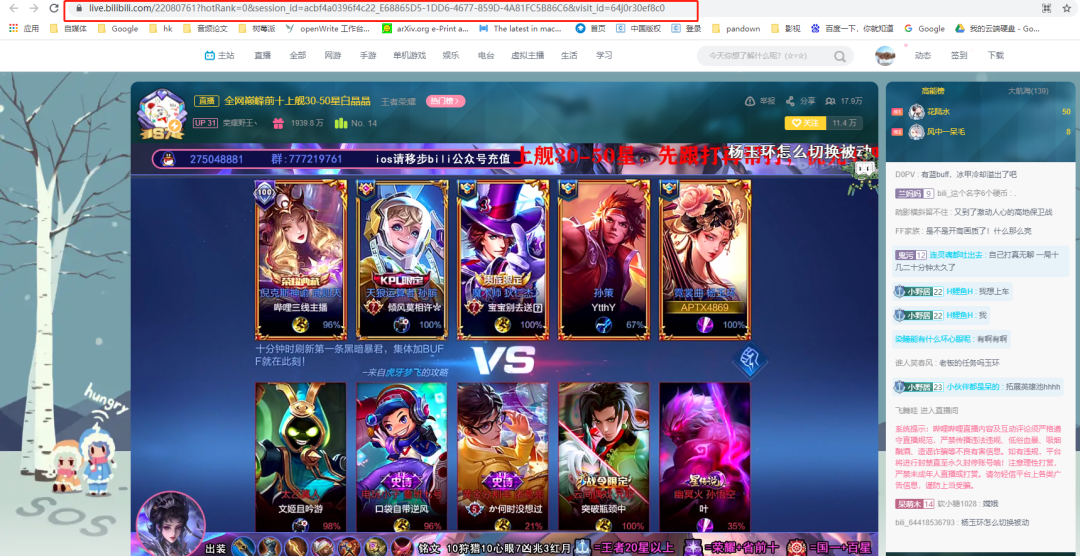
1.查找弹幕链接
通过F12查看network,找到下面这个链接
https://api.live.bilibili.com/xlive/web-room/v1/index/roomEntryAction

可以看到是post请求,经过验证只需要房间号就可以获取弹幕!
2.构造post请求
roomid = "22080761"
url = 'https://api.live.bilibili.com/xlive/web-room/v1/dM/gethistory'
headers = {
'Host': 'api.live.bilibili.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.90 Safari/537.36',
}
data = {
'roomid': roomid,
}
html = requests.post(url=url, headers=headers, data=data).json()
直接返回json数据

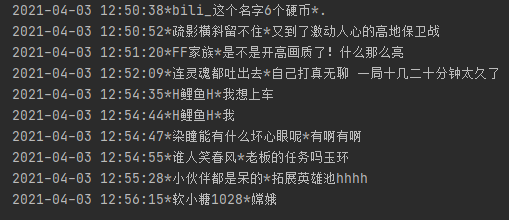
二、实时采集
为了达到实时采集的目的,需要将采集弹幕的代码封装成函数,然后每个几秒调用一次这个函数(比如这里定为5秒)
1.定时代码
def sleeptime(hour, min, sec):
return hour * 3600 + min * 60 + sec
second = sleeptime(0, 0, 5)
while 1 == 1:
time.sleep(second)
print('do action')
###5秒采集一次
get_msg()
这里的get_msg是采集弹幕函数
2.写入TxT
with open(filename,"a+", encoding='gb18030') as f:
for content in html['data']['room']:
# 获取昵称
nickname = content['nickname']
# 获取发言
text = content['text']
# 获取发言时间
timeline = content['timeline']
# 记录发言
msg = timeline + '*' + nickname + '*' + text
###不存在则添加
if msg not in msg_data:
f.write(str(msg)+"\n")
文本以房间号命名
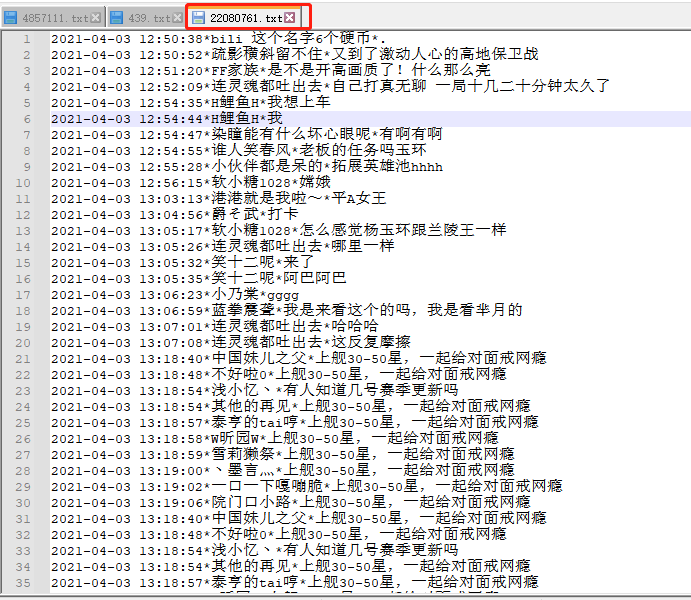
三、情感分析
情绪判断,返回值为正面情绪的概率,越接近1表示正面情绪,越接近0表示负面情绪先简单来看一个例子
text1 = '这部电影真心棒,全程无尿点'
s1 = SnowNLP(text1)
print(text1, s1.sentiments) # 这部电影真心棒,全程无尿点 0.9842572323704297
通过SnowNLP库实现文本的情感分析
roomid = "22080761"
filename = roomid + ".txt"
##读取当前txt
with open(filename, "r", encoding='gb18030') as f:
msg_data = f.readlines()
Sentiment_list = []
###正面
count1 = 0
###负面
count2 = 0
for i in msg_data:
text = i.split("*")[2]
t = SnowNLP(text)
if t.sentiments > 0.5:
count1 = count1 +1
else:
count2 = count2 + 1
Sentiment_list.append(count1)
Sentiment_list.append(count2)
print(Sentiment_list)
从弹幕文本文件中读取出每一条弹幕,然后进行情感分析,最后统计正面评论数和负面评论数
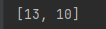
正面弹幕13条、负面弹幕10条。
四、不同时间点评论数分析
同样还是读取弹幕文本文件,之后就以分钟为间隔进行统计
获取当前小时
h = time.strftime("%Y-%m-%d %H", time.localtime())
开始统计
for i in msg_data:
time_list.append(i.split("*")[0].split(":")[1])
data_time = list(set(time_list))
data_time.sort()
###只取三个
if len(data_time)>7:
data_time = data_time[-7:]
name = [h+":"+i for i in data_time]
value =[time_list.count(i) for i in data_time]
print(name)
print(value)

五、高频词统计
思路:通过SnowNLP库对文本(弹幕)进行分词然后会分好的词进行统计排序
先将弹幕合并成文本
for i in msg_data:
#if ymdhm in i:
text_list.append(i.split("*")[2])
# 需要操作的句子
text = "".join(text_list)
text = text.replace("\n","")
print(text)
s = SnowNLP(text)
开始进行统计,然后取出前5
list_all = s.words
dict_x = {}
for item in list_all:
dict_x[item] = list_all.count(item)
sorted_x = sorted(dict_x.items(), key=operator.itemgetter(1), reverse=True)
re_word_list = []
re_word_list_name = []
re_word_list_data = []
count = 0
for k, v in sorted_x:
if count==5:
break
if len(k)>1:
re_word_list_name.append(k)
re_word_list_data.append(v)
count = count+1
re_word_list.append(re_word_list_name)
re_word_list.append(re_word_list_data)
print(re_word_list)
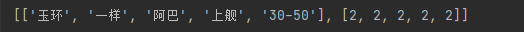
六、总结
本文主要是讲解了任何实时采集直播弹幕,然后通过SnowNLP库等对弹幕数据进行统计。
如果大家对本文代码源码感兴趣,扫码关注『Python爬虫数据分析挖掘』后台回复:直播弹幕 ,获取完整代码!
最后说一声:原创不易,求给个赞 、在看
、在看 、评论
、评论
------------- 推荐阅读 -------------
高质量推荐

专注:python、爬虫、数据分享、数据可视化
耐得住寂寞,才能登得顶
Gitee码云:https://gitee.com/lyc96/projects

 浙公网安备 33010602011771号
浙公网安备 33010602011771号