
采集+图谱可视化|手把手教你采集明星人物关系并进行图谱展示
大家好,我是阿辰~
今天教大家获取采集(某度百科)的明星人物关系数据,并进行图谱可视化展示。
亮点(难点):
1.动态查询(输入任意明星名字就可以查询该明星关系人物)。
2.图谱展示(以及key-value形式)
具体介绍就不多讲了,先上效果:
可以在链接里面输入对应的明星名称就可以获取对应的人物关系图谱(还支持拖拽),比如:李易峰

1. 采集数据
在百度里面搜索:李易峰
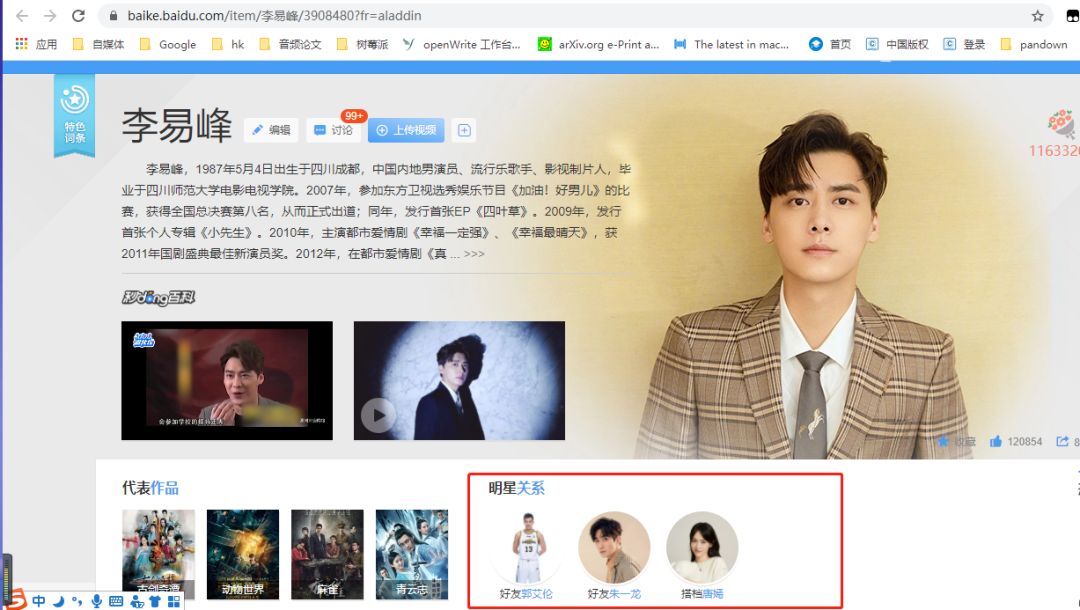
可以在明星这栏里面看到明星关系
下面开始定位网页标签
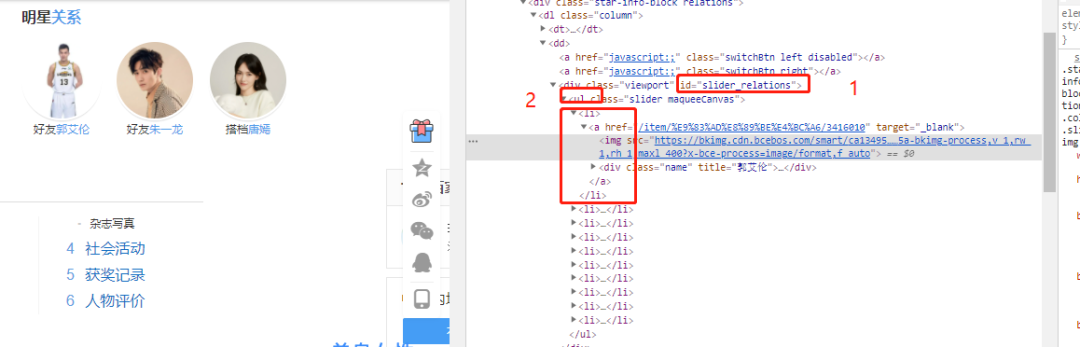
可以看到数据是在id为slider_relations下,对应的ul下的li标签
relations = selector.xpath('//*[@id="slider_relations"]/ul/li')
获取到li标签之后,需要解析key-value,key对应关系(搭档、好友等),value对应明星名字
for i in relations:
re = i.xpath('.//div[@class="name"]/text()')[0]
name = i.xpath('.//div[@class="name"]/em/text()')[0]

2. 网页制作
为了将图谱结合以及可以动态查询任意明星人物关系,这里写成网站(网页)形式
通过Flask框架去编写后台,html作为前端,由于前端代码较多这里就不展示了(后面会提供源码)。
首先将采集明星人物关系的代码封装成函数。
###获取信息
def getlist(name_i):
url_name = "https://baike.baidu.com/search/word?word="+str(name_i)
s = requests.Session()
response = s.get(url_name, headers=headers)
text = response.text
#此处是解析代码
links = []
for i in relations:
re = i.xpath('.//div[@class="name"]/text()')[0]
name = i.xpath('.//div[@class="name"]/em/text()')[0]
print(re + "-" + name)
dict = {'source': str(name_i), 'target': str(name), 'rela': str(re), 'type': 'resolved'}
links.append(dict)
return links
其中的name_i就是搜索的明星名字,封装好的函数名称是getlist,函数返回的数据为links
接着是Flask的路由(浏览器里面的网站访问名getdata)
#获取数据
@app.route('/getdata')
def getdata():
name_i = request.args.get('name')
# 采集数据
links = getlist(name_i)
print(links)
#return Response(json.dumps(links), mimetype='application/json')
return render_template('index.html', linkss=json.dumps(links))
3. 启动
if __name__ == "__main__":
"""初始化"""
app.run(host=''+ip, port=80,threaded=True)
这里的端口是80,ip是默认本机ip(你们运行代码访问时候,输入自己的本机ip即可)

运行py代码后,出现上述界面说明启动成功
接着在浏览器里面访问
http://127.0.0.1/getdata?name=明星名字
这里的明星名字是任意一位明星,比如:李易峰
http://127.0.0.1/getdata?name=李易峰

http://127.0.0.1/getdata?name=成龙
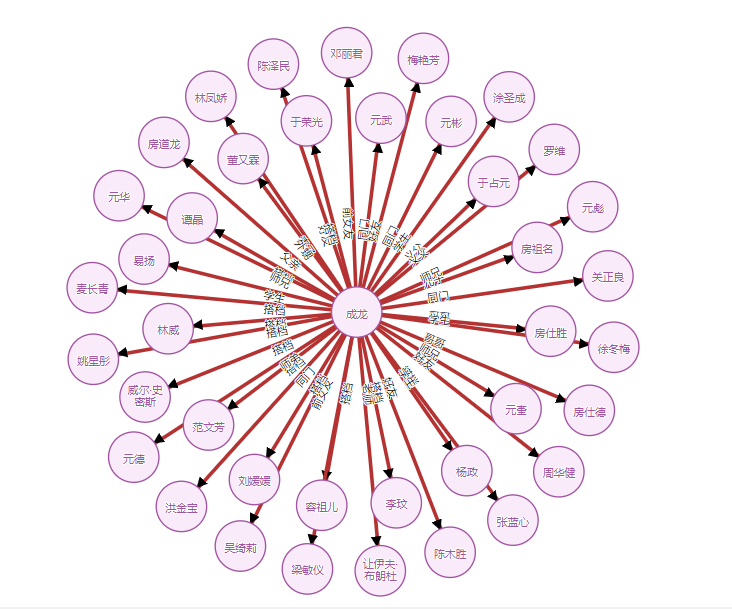
4. 小结
本文获取了明星人物关系动态数据,并进行了可视化展示, 源代码在下方获取。
本文完整源码和数据获取方式,在阿辰的朋友圈有完整源码下载地址
需要的小伙伴可以去逛一下阿辰的朋友圈(还没有添加阿辰微信的小伙伴,下方可以扫码添加 )
)
最后说一声:原创不易,求给个赞 、在看
、在看 、评论
、评论

推荐阅读

爬虫+可视化|爬取「奔跑吧」全系列嘉宾名单,并进行可视化分析


耐得住寂寞,才能登得顶
Gitee码云:https://gitee.com/lyc96/projects

 浙公网安备 33010602011771号
浙公网安备 33010602011771号