Python网络爬虫(理论篇)
欢迎关注公众号:Python爬虫数据分析挖掘,回复【开源源码】免费获取更多开源项目源码

网络爬虫的组成
网络爬虫由控制节点,爬虫节点,资源库构成。
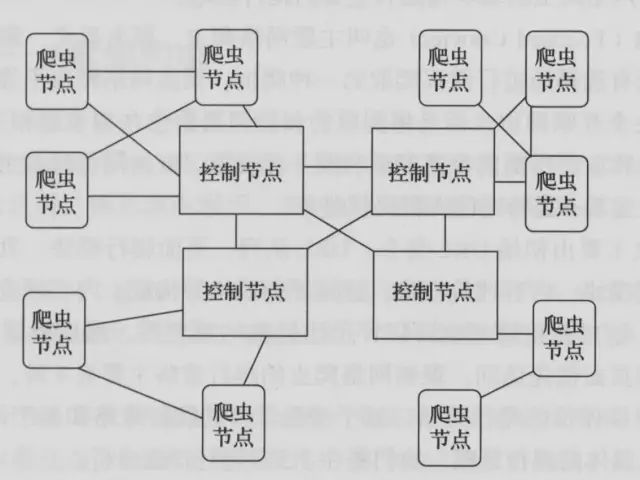
网络爬虫的控制节点和爬虫节点的结构关系
-
控制节点(爬虫的中央控制器):主要负责根据URL地址分配线程,并调用爬虫节点进行具体的爬行。
-
爬虫节点会按照相关的算法,对网页进行具体的爬行,主要包括下载网页以及对网页的文本进行处理,爬行后,会将对应的爬行结果存储到对应的资源库中。
网络爬虫的类型
网络爬虫可分为通用网络爬虫,聚焦网络爬虫,增量式网络爬虫,深层网络爬虫等类型。
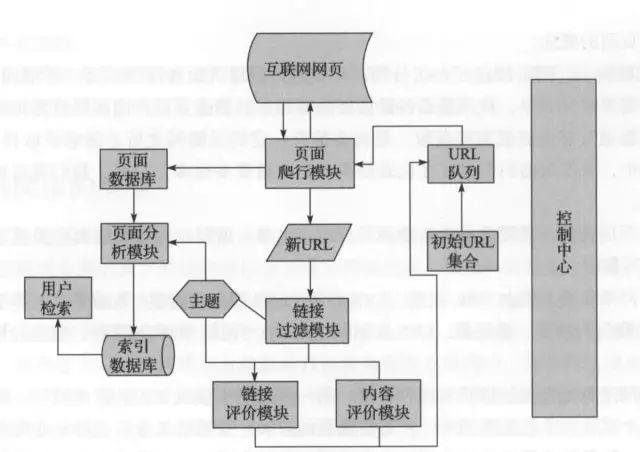
聚焦爬虫运行的流程
搜索引擎核心
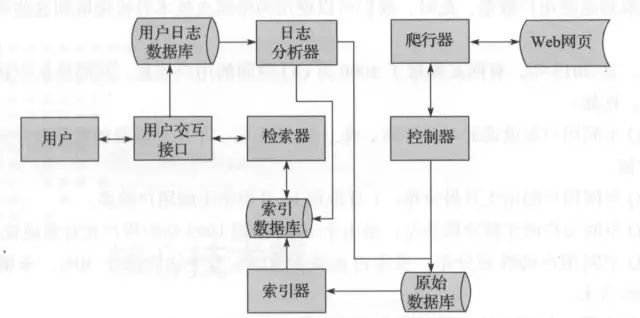
搜索引擎的核心工作流程
网络爬虫实现原理详解
通用网络爬虫
通用网络爬虫的实现原理及过程可以简要概括如下:
1)获取初始的URL。
2)根据初始的URL爬取页面,并获得新的URL。
3)将新的URL放到URL队列中。
4)从URL队列中读取新的URL,并依据新的URL爬取网页,同时从新网页中获取URL,并重复上述的爬取过程。
5)满足爬虫系统设置的停止,停止爬取。
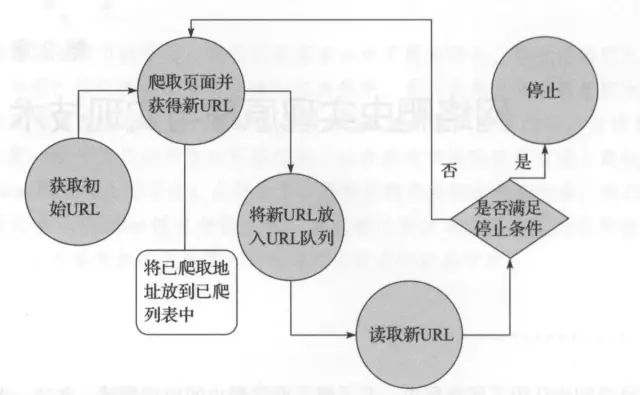
通用网络爬虫的实现原理及过程
聚焦网络爬虫
1)对爬取目标的定义和描述。
2)获取初始的URL。
3)根据初始的URL爬取页面,并获得新的URL。
4)从新的URL中过滤掉与爬取目标无关的链接。
5)将过滤后的链接放到URL队列中。
6)从URL队列中,根据搜索算法,确定URL的优先级,并确定下一步要爬取的URL地址。
7)从下一步要爬取的URL地址中,读取新的URL,然后依据新的URL地址爬取网页,并重复上述爬取过程。
8)满足系统中设置的停止条件时,或无法获取新的URL地址时,停止爬行。
聚焦网络爬虫的实现原理及过程
爬行策略
爬行策略主要有深度优先爬行策略,广度优先爬行策略,大战优先策略,反链策略,其他爬行策略等。
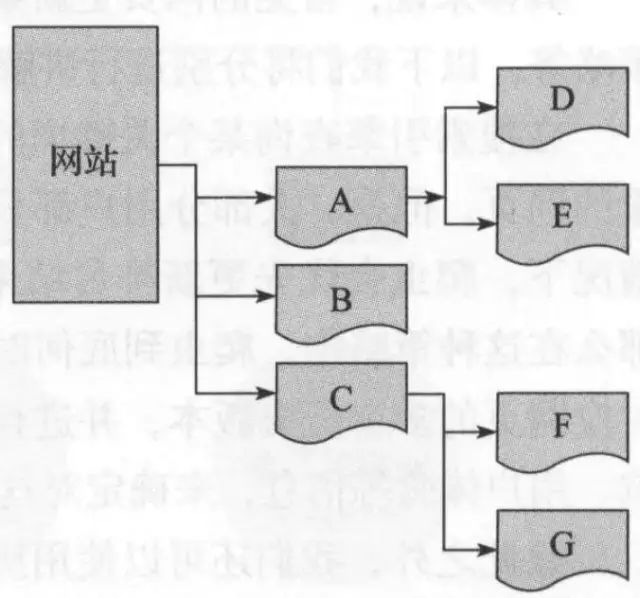
某网站的网页层次结构示意图
1)深度优先爬行策略:会先爬取一个网页,然后将这个网页的下层链接依次深入爬取完再返回上一层进行爬取。
爬行顺序:A->D->E->B->C->F_>G
2)广度优先爬行策略:会爬取同一层次的网页,将同一层次的网页全部爬取完后,再选择下一个层次的网页取爬行。
爬行顺序:A->B->C->D->E->F_>G
3)大站爬行策略:安照对应网页所属的站点进行归类,如果某个网站的网页数量多,那么我们则将其称为大站,优先爬取大战中的网页URL地址。
4)反链策略:指的是该网页被其他网页指向的次数,这个次数在一定程度上代表着该网页被其他网页的推荐次数,优先爬取反链数量多的网页。
除此之外,还有OPIC策略,PartialPageRank策略等。
网页更新策略
网页更新策略主要有用户体验策略,历史数据策略,聚类分析策略等。
1)用户体验策略:大部分用户都只会关注排名靠前的网页,所以在爬虫服务器资源有限的情况下,优先爬取更新排名结果靠前的网页。
2)历史数据策略:使用历史数据策略来确定对网页更新爬取的周期。
3)聚类分析策略:
-
网页可能具有不同的内容,但是一般来说,具有类似熟悉的网页,其更新频率类似。
-
首先对海量的网页进行聚类分析,在聚类后,会形成多个类,每个类中的网页具有类似的属性,即一般具有类似的更新频率。
-
聚类完成后,对同一个聚类中的网页进行抽样,然后求该抽样结果的平均更新值,从而确定对每个聚类的爬行频率。
网页分析算法
在搜索引擎中,爬虫爬取了对应的网页之后,会将网页存储到服务器的原始数据库中,之后搜索引擎会对这些网页进行分析并确定各网页的重要性,即会影响用户搜索的排名结果。
网页分析算法:基于用户行为的网页分析算法,基于网络拓扑的网页分析算法,基于网页内容的网页分析算法。
基于用户行为的网页分析算法
依据用户对这些网页的访问行为,对这些网页进行平价。
基于网络拓扑的网页分析算法
依靠网页的链接关系,结构关系,已知网页或数据等对网页进行分析的一种算法。
基于网页内容的网页分析算法
依据网页的数据,文本等网页内容特征,对网页进行相应的评价。
主要细分3种类型:基于网页粒度的分析算法,基于网页块粒度的分析算法,基于网站粒度的分析算法。
1)基于网页粒度的分析算法
根据网页之间的链接关系对网页的权重进行计算,并可以依靠这些计算出来的权重,对网页进行排名。
2)基于网页块粒度的分析算法
也是依靠网页间链接关系进行计算,但是计算规则有所不同,需要对一个网页中的外部链接划分层次,不同外部链接对于该网页来说,其重要程度不同。
3)基于网站粒度的分析算法
依据网页的数据,文本等网页内容特征,对网页进行相应的评价。
身份识别
在爬虫对网页爬取的过程中,爬虫必然需要访问对应的网页,正规的爬虫一般会告诉对应网页的网站站长其爬虫身份。网站的管理员则可以通过爬虫告知的身份信息对爬虫的身份进行识别,我们称这个过程为爬虫的身份识别过程。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号