Python预测糖尿病

今天给大家讲解一个实战案例:如何根据现有数据预测糖尿病。在这个案例开始之前,希望大家回忆一下大学里讲过的线性回归的知识,这是数据挖掘里非常重要的一部分知识。当然,鉴于大家都学过,本篇就不再赘述。
一. 数据集介绍
diabetes dataset数据集
这是一个糖尿病的数据集,主要包括442行数据,10个属性值,分别是:Age(年龄)、性别(Sex)、Body mass index(体质指数)、Average Blood Pressure(平均血压)、S1~S6一年后疾病级数指标。Target为一年后患疾病的定量指标。
输出如下所示:
二、LinearRegression使用方法
LinearRegression模型在Sklearn.linear_model下,它主要是通过fit(x,y)的方法来训练模型,其中x为数据的属性,y为所属类型。
sklearn中引用回归模型的代码如下:
输出的函数原型如下所示:
fit(x, y): 训练。分析模型参数,填充数据集。其中x为特征,y位标记或类属性。
predict(): 预测。它通过fit()算出的模型参数构成的模型,对解释变量进行预测其类属性。预测方法将返回预测值y_pred。
引用搬砖小工053"大神的例子:
运行结果如下所示,首先输出数据集,同时调用sklearn包中的LinearRegression()回归函数,fit(X, Y)载入数据集进行训练,然后通过predict()预测数据12尺寸的匹萨价格,最后定义X2数组,预测它的价格。
输出的图形如下所示: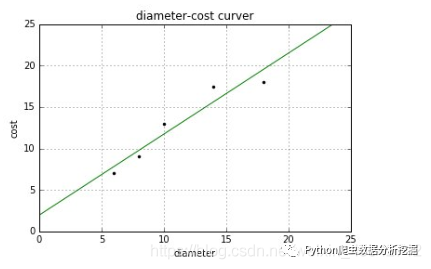
线性模型的回归系数W会保存在他的coef_方法中,截距保存在intercept_中。score(X,y,sample_weight=None) 评分函数,返回一个小于1的得分,可能会小于0。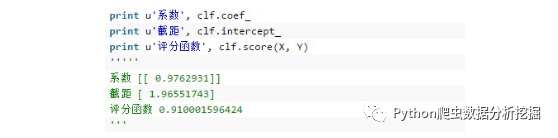
三、线性回归判断糖尿病
1.Diabetes数据集(糖尿病数据集)
糖尿病数据集包含442个患者的10个生理特征(年龄,性别、体重、血压)和一年以后疾病级数指标。
然后载入数据,同时将diabetes糖尿病数据集分为测试数据和训练数据,其中测试数据为最后20行,训练数据从0到-20行(不包含最后20行),即diabetes.data[:-20]。
输出结果如下所示,可以看到442个数据划分为422行进行训练回归模型,20行数据用于预测。输出的diabetes_x_test共20行数据,每行仅一个特征。
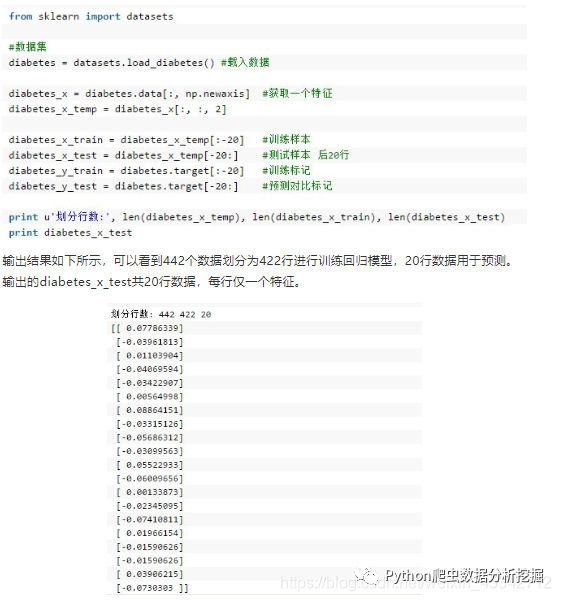
2.完整代码
改代码的任务是从生理特征预测疾病级数,但仅获取了一维特征,即一元线性回归。【线性回归】的最简单形式给数据集拟合一个线性模型,主要是通过调整一系列的参以使得模型的残差平方和尽量小。
线性模型:y = βX+b
X:数据 y:目标变量 β:回归系数 b:观测噪声(bias,偏差)
运行结果如下所示,包括系数、残差平方和、方差分数。
绘制图形如下所示,每个点表示真实的值,而直线表示预测的结果,比较接近吧。
同时绘制图形时,想去掉坐标具体的值,可增加如下代码:
四、优化代码
下面是优化后的代码,增加了斜率、 截距的计算,同时增加了点图到线性方程的距离,保存图片设置像素。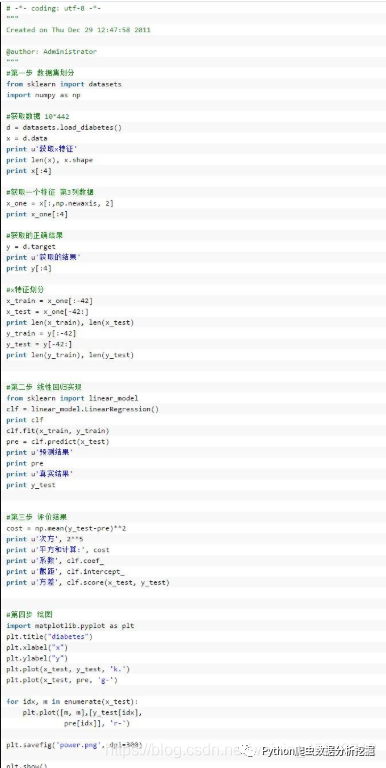
运行结果如下所示: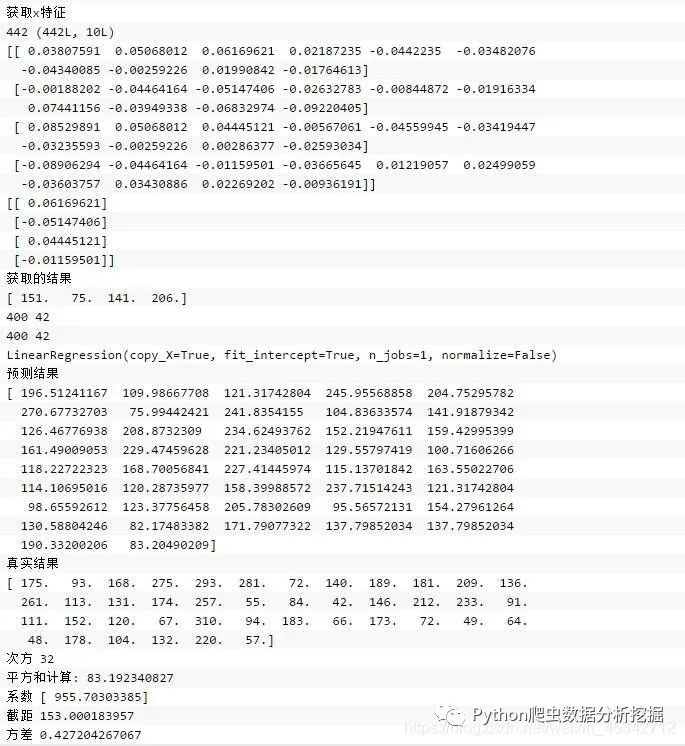
绘制图形如下所示: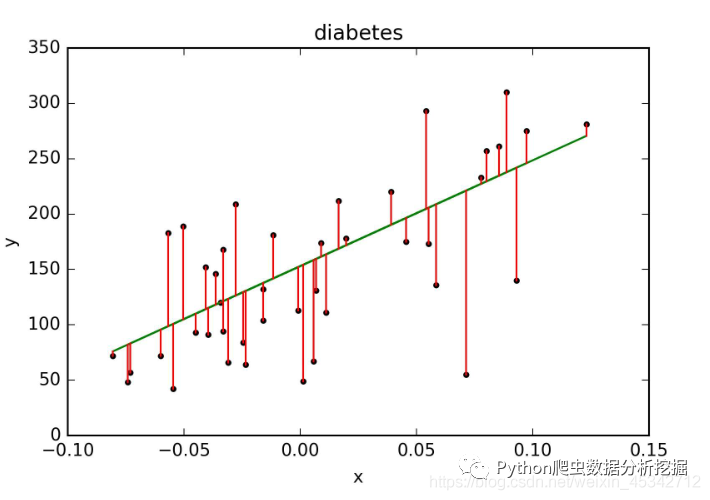
欢迎关注公众号:Python爬虫数据分析挖掘,回复【开源源码】免费获取更多开源项目源码
公众号每日更新python知识和【免费】工具


 浙公网安备 33010602011771号
浙公网安备 33010602011771号