用python爬虫简单网站却有 “多重思路”--猫眼电影
目录
-
-
分析页面:
-
构造页面参数:
-
请求网址:
-
解析网址:
-
-
保存数据:
-
-
全部代码:
-
使用xpath解析网址:
-
使用正则去匹配信息:
-
保存为excel:
-
保存为csv:
-
爬虫思路:
-
-
爬虫思路:
-
本次爬取网站为:https://maoyan.com/board/4?offset=0
-
本次爬虫函数库:
import reimport requestsfrom lxml import etreefrom openpyxl import Workbook # pip install openpyxl 操作excel 表格的优秀库import csv # 操作csv表格
这些函数库没有的话 就自己下载一下, 下载慢出现timeout的话,需要搭配一下国内镜像网站。百度一下 清华镜像
-
本次爬虫代码思路:面向过程的简单操作
-
本次爬虫主要侧重于解析页面和保存数据二大模块,有需求可以直接跳转阅读。
分析页面:
拿到这个网站的第一步,就是分析页面, 切不可着急,直接套用代码而上!
-
查看网页源代码之后, 你可以找到页面中对应的数据, 如图:
![]()
这说明这个网站就是很中规中矩的静态网站了, 你想怎么耍就可以怎么耍。 -
因为是要爬取T100或者更多, 观察每一页的网址特点,我们发现:

https://maoyan.com/board/4?offset=0 1
https://maoyan.com/board/4?offset=10 2
https://maoyan.com/board/4?offset=20 3
每一页都是offset的不同变化,那我们字符串的构造就可以完成这个任务,得到任意页的网址。
-
当我们拿到每一页的网址,只需要向服务器发送请求,得到返回后的html页面,然后就可以进行不同的解析工作了, 在解析中,我们可以提取我们要的数据,将这些数据进行二次加工, 在返回, 那么就可以进入到我们保存数据的过程了, 在保存数据的时候,我们可以采用不同的方式进行保存,在这边文章中,我使用了excel和 csv 二种方式去保存,这样可以增加自己的代码练手率, 方便自己熟悉各种方式的保存。
构造页面参数:
for i in range(10):url = 'https://maoyan.com/board/4?offset={}'.format(i * 10)html = spider(page_url=url)
就直接这样用字符串构造一下就行了,很简单。
请求网址:
def spider(page_url):headers = {'user-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) ''AppleWebKit/537.36 (KHTML, like Gecko) ''Chrome/83.0.4103.106 Safari/537.36'}r = requests.get(page_url, headers=headers)if r.status_code == 200:return r.textelse:print(r.status_code)
带上一些必要的信息, 就可以伪装一下,发送请求,返回页面源代码。
解析网址:
使用xpath解析网址:
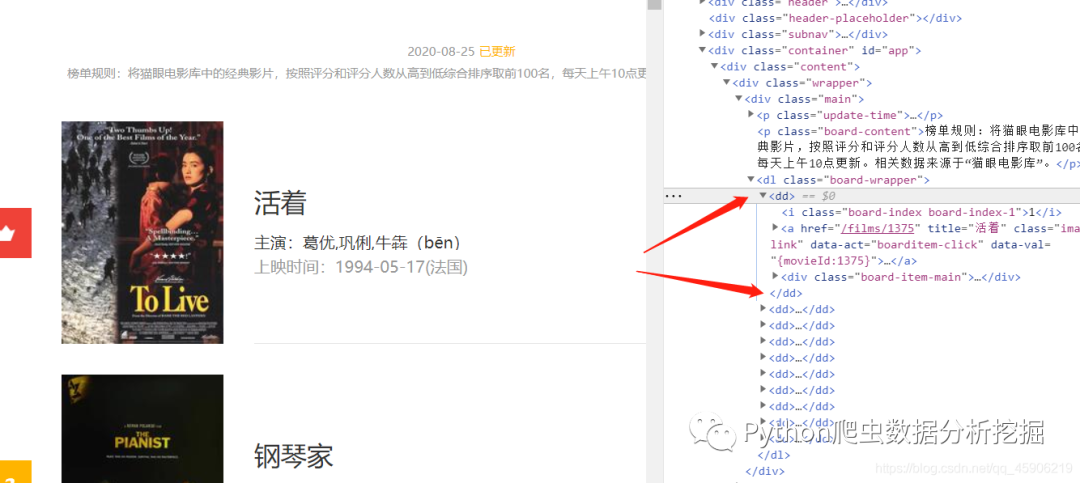
我们可以通过浏览器发现, 每个电影都在在标签dd中, 但是我们还是要根据dl标签来遍历下面的dd标签,方便得到如下数据!最后使用枚举 enumerate() 去返回一个参数字典。
代码如下:
def parse_xpath_page(page_html):html = etree.HTML(page_html)title = html.xpath('//dl/dd/div/div/div[1]/p/a/text()') # 10actress = html.xpath('//dl/dd/div/div/div[1]/p[2]/text()')time = html.xpath('//dl/dd/div/div/div[1]/p[3]/text()')score1 = html.xpath('//dl/dd/div/div/div[2]/p/i[1]/text()')score2 = html.xpath('//dl/dd/div/div/div[2]/p/i[2]/text()')for index, value in enumerate(title):yield {'title': value.strip(),'actress': str(actress[index]).strip(),'time': time[index],'score': score1[index] + score2[index]}
使用正则去匹配信息:
正则这个东西,在爬虫中真不到万不得已的时候才使用, 个人感觉,在这个网址,我们练练手, 打开网页源代码。如下: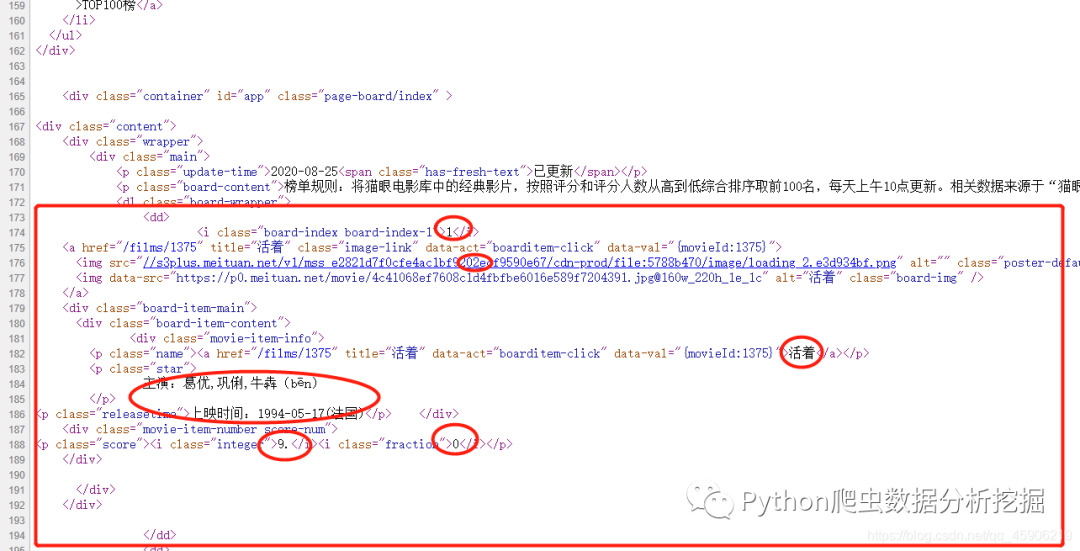
我们要的数据都在每一个dd标签中, 所以我们需要编写正则表达式, 这里我编写了二种表达式,都可以实现。关于不会正则的朋友,希望自己去学一下。
result = re.findall(r'<dd>.*?board-index.*?>(\d+)</i>.*?data-src="(.*?)".*?name"><a'r'.*?>(.*?)</a>.*?star">(.*?)</p>.*?releasetime">(.*?)</p>'r'.*?integer">(.*?)</i>.*?fraction">(.*?)</i>.*?</dd>', page_html, re.S)result = re.findall(r'<dd>.*?board-index.*?>(\d+)</i>'r'.*?data-src="(.*?)".*?</a>'r'.*?name.*?<a.*?>(.*?)</a></p>'r'.*?<p.*?star.*?>(.*?)</p>'r'.*?<p.*?releasetime.*?>(.*?)</p>'r'.*?<p.*?score.*?integer.*?>(.*?)</i>'r'.*?fraction.*?>(.*?)</i></p>.*?</dd>', page_html, re.S)
二种都差不多, 有点细微差别。
代码如下:
def parse_re_page(page_html):# result = re.findall(r'<dd>.*?board-index.*?>(\d+)</i>.*?data-src="(.*?)".*?name"><a'# r'.*?>(.*?)</a>.*?star">(.*?)</p>.*?releasetime">(.*?)</p>'# r'.*?integer">(.*?)</i>.*?fraction">(.*?)</i>.*?</dd>', page_html, re.S)result = re.findall(r'<dd>.*?board-index.*?>(\d+)</i>'r'.*?data-src="(.*?)".*?</a>'r'.*?name.*?<a.*?>(.*?)</a></p>'r'.*?<p.*?star.*?>(.*?)</p>'r'.*?<p.*?releasetime.*?>(.*?)</p>'r'.*?<p.*?score.*?integer.*?>(.*?)</i>'r'.*?fraction.*?>(.*?)</i></p>.*?</dd>', page_html, re.S)if result:for content in result:yield {"id": content[0],'img_path': ''.join(content[1].split('@')[0]).strip(),'title': content[2].strip(),'actress': content[3].strip(),'time': content[4].strip(),'score': content[5] + "" + content[6]}
保存数据:
数据的保存,至关重要。
保存为excel:
能直接操作excel 表格的库确实有很多,但是我喜欢用openpyxl, 我觉得这个最好耍, 简单的一些配置,就能直接上手。
代码如下:
workbook = Workbook()sheet = workbook.active # 获取激活的表格sheet.title = '猫眼TOP100'sheet['A1'] = 'title'sheet['B1'] = 'actress'sheet['C1'] = 'time'sheet['D1'] = 'score'
因为之前我传过来的数据是字典类型的, 但考虑到openpyxl能直接操作的是列表类型,所以有如下修改:
def save_excel(item):a = [] # 列表暂存for key, value in item.items():a.append(value)sheet.append(a) # 保存
保存为csv:
直接操作csv的函数库 我觉得只有csv库最香了。
因为字典类型, 我们需要设置表头, 但是设置表头需要注意不要多次设置, 可能表中存在多个表头,应该这样:
# 先设置表头 关闭文件with open('猫眼top.csv', 'a+', newline='', encoding='utf-8') as fw:header = ['id', 'img_path', 'title', 'actress', 'time', 'score']fw_csv = csv.DictWriter(fw, header)fw_csv.writeheader()# 再写入数据def save_csv(item):header = ['id', 'img_path', 'title', 'actress', 'time', 'score']with open('猫眼top.csv', 'a+', encoding='utf-8', newline='') as fw:fw_csv = csv.DictWriter(fw, header)fw_csv.writerow(item)
全部代码:
import reimport requestsfrom lxml import etreefrom openpyxl import Workbookimport csvdef spider(page_url):headers = {'user-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) ''AppleWebKit/537.36 (KHTML, like Gecko) ''Chrome/83.0.4103.106 Safari/537.36'}r = requests.get(page_url, headers=headers)if r.status_code == 200:return r.textelse:print(r.status_code)def parse_xpath_page(page_html):html = etree.HTML(page_html)title = html.xpath('//dl/dd/div/div/div[1]/p/a/text()') # 10actress = html.xpath('//dl/dd/div/div/div[1]/p[2]/text()')time = html.xpath('//dl/dd/div/div/div[1]/p[3]/text()')score1 = html.xpath('//dl/dd/div/div/div[2]/p/i[1]/text()')score2 = html.xpath('//dl/dd/div/div/div[2]/p/i[2]/text()')for index, value in enumerate(title):yield {'title': value.strip(),'actress': str(actress[index]).strip(),'time': time[index],'score': score1[index] + score2[index]}def parse_re_page(page_html):# result = re.findall(r'<dd>.*?board-index.*?>(\d+)</i>.*?data-src="(.*?)".*?name"><a'# r'.*?>(.*?)</a>.*?star">(.*?)</p>.*?releasetime">(.*?)</p>'# r'.*?integer">(.*?)</i>.*?fraction">(.*?)</i>.*?</dd>', page_html, re.S)result = re.findall(r'<dd>.*?board-index.*?>(\d+)</i>'r'.*?data-src="(.*?)".*?</a>'r'.*?name.*?<a.*?>(.*?)</a></p>'r'.*?<p.*?star.*?>(.*?)</p>'r'.*?<p.*?releasetime.*?>(.*?)</p>'r'.*?<p.*?score.*?integer.*?>(.*?)</i>'r'.*?fraction.*?>(.*?)</i></p>.*?</dd>', page_html, re.S)if result:for content in result:yield {"id": content[0],'img_path': ''.join(content[1].split('@')[0]).strip(),'title': content[2].strip(),'actress': content[3].strip(),'time': content[4].strip(),'score': content[5] + "" + content[6]}def save_excel(item):a = []for key, value in item.items():a.append(value)sheet.append(a)def save_csv(item):header = ['id', 'img_path', 'title', 'actress', 'time', 'score']with open('猫眼top.csv', 'a+', encoding='utf-8', newline='') as fw:fw_csv = csv.DictWriter(fw, header)fw_csv.writerow(item)if __name__ == '__main__':flag = int(input('1:to_excel\n2:to_csv\nplease enter you chooser:'))if flag == 1:workbook = Workbook()sheet = workbook.activesheet.title = '猫眼TOP100'sheet['A1'] = 'title'sheet['B1'] = 'actress'sheet['C1'] = 'time'sheet['D1'] = 'score'for i in range(10):url = 'https://maoyan.com/board/4?offset={}'.format(i * 10)html = spider(page_url=url)for item in parse_xpath_page(html):save_excel(item=item)print('数据保存成功!')workbook.save(filename='猫眼top.xlsx')workbook.close()elif flag == 2:with open('猫眼top.csv', 'a+', newline='', encoding='utf-8') as fw:header = ['id', 'img_path', 'title', 'actress', 'time', 'score']fw_csv = csv.DictWriter(fw, header)fw_csv.writeheader()for i in range(10):url = 'https://maoyan.com/board/4?offset={}'.format(i * 10)html = spider(page_url=url)for item in parse_re_page(html):save_csv(item=item)print('数据保存成功!')
欢迎关注公众号:Python爬虫数据分析挖掘,回复【开源源码】免费获取更多开源项目源码
公众号每日更新python知识和【免费】工具


 浙公网安备 33010602011771号
浙公网安备 33010602011771号