避坑之Hadoop安装伪分布式(Hadoop3.2.0/Ubuntu14.04 64位)
一.安装JDK环境(这个可以网上随意搜一篇教程了照着弄,这里不赘述)
安装成功之后
输入
输入:java -version
显示如下说明jdk安装成功(我这里是安装JDK8)

二.安装Hadoop3.2.0
1、官网下载http://mirror.bit.edu.cn/apache/hadoop/common/
2、安装
A.解压
sudo tar xzf hadoop-3.2.0.tar.gz
B.假如我们要把hadoop安装到/usr/local下
C.拷贝到/usr/local/下,文件夹为hadoop
sudo mv hadoop-3.2.0 /usr/local/hadoop
D.赋予用户对该文件夹的读写权限
sudo chmod 774 /usr/local/hadoop
三.配置Hadoop(JDK和Hadoop的路径)
1.配置~/.bashrc
输入:sudo gedit ~/.bashrc
添加如下代码:

之后保存退出
2.执行下面命名,使添加的环境变量生效:(如果报错,请看下面避坑一)
source ~/.bashrc
3.判断Hadoop是否安装成功
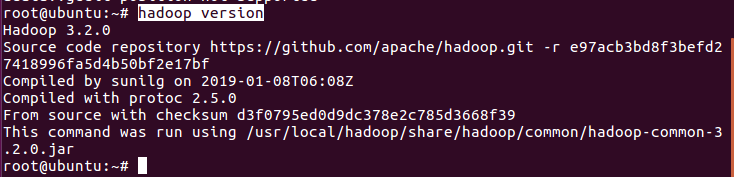
出现版本信息,说明成功
四,,接下来进行配置伪分布式(上面的Hadoop只是单机模式)
4.1修改hadoop配置文件
4.1.1修改配置文件core-site.xml(使用gedit etc/hadoop/core-site.xml).将configuration节点添加子节点,修改为下面内容:
<configuration>
<!--指定fs的缺省名称-->
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
<!--指定HDFS的(NameNode)的缺省路径地址,localhost:是计算机名,也可以是ip地址-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
<!-- 指定hadoop运行时产生文件的存储目录(以个人为准) -->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
</property>
</configuration>
ps:如果没有该目录:/usr/local/hadoop/tmp,需要自己新建
4.1.2修改配置文件hdfs-site.xml(使用gedit etc/hadoop/hdfs-site.xml).将configuration节点添加子节点,修改为下面内容:
<configuration>
<!-- 指定HDFS副本的数量 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>/usr/local/hadoop/hdfs/name</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/usr/local/hadoop/hdfs/data</value>
</property>
</configuration>
ps:如果没有该目录:/usr/local/hadoop/hdfs/name,需要自己新建
ps:如果没有该目录:/usr/local/hadoop/hdfs/data,需要自己新建
4.1.3 etc/hadoop目录下查看是否有配置文件mapred-site.xml。目录下默认情况下没有该文件,可通过执行如下命令:cp mapred-site.xml.template mapred-site.xml修改一个文件的命名,然后执行编辑文件命令:gedit mapred-site.xml并修改该文件内容:
<configuration>
<!-- 指定mr运行在yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
4.1.4在etc/hadoop目录下执行gedit yarn-site.xml修改为:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
4.2同样使用source ~/.bashrc命令使配置文件生效。(如果报错,请看下面避坑一)
五:Hadoop的运行
5.1格式化namenode
第一次运行格式化namennode。执行hdfs namenode -format命令。
5.2启动hadoop hdfs (如果报错,请看避坑二)
执行start-dfs.sh命令。
5.3启动yarn ( 如果报错,请看避坑二)
执行start-yarn.sh命令。
5.4查看运行进程
使用jps命令,查看运行中java进程

六.web管理界面
6.1MapReduce管理界面:http://localhost:8088/
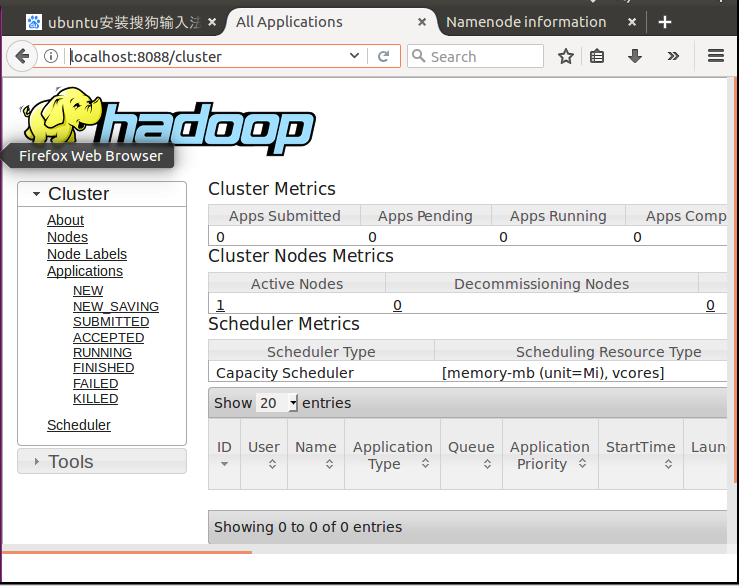
6.2HDFS管理界面:http://localhost:50070/
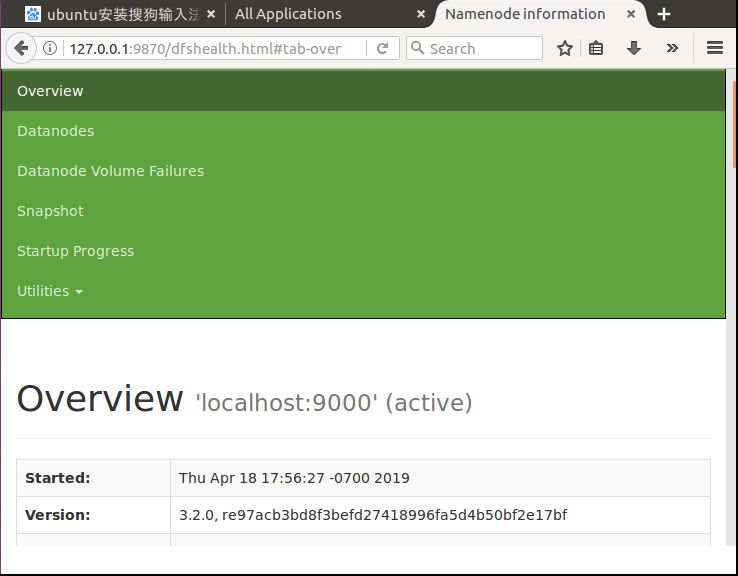
如果显示如下页面,请看避坑三

七.退出
可执行stop-all.sh 命令,一次性关闭所有hadoop进程,也可以通过stop-dfs.sh stop-yarn.sh分别关闭进程
避坑一:bashrc命令报错
两种方法解决此问题:
1.在当前用户下添加环境变量:将环境变量添加到文件:~/.bashrc下,
然后source ~/.bashrc即可。
2.首先进入root用户:sudo su -或者sudo -s,
然后将环境变量添加到/etc/profile或者/root/.bashrc或者/etc/bash.bashrc文件,然后source该文件即可。
避坑二:start-dfs.sh或者start-yarn.sh报错
报错如下

在/hadoop/sbin路径下:
将start-dfs.sh,stop-dfs.sh两个文件顶部添加以下参数
1 #!/usr/bin/env bash 2 HDFS_DATANODE_USER=root 3 HADOOP_SECURE_DN_USER=hdfs 4 HDFS_NAMENODE_USER=root 5 HDFS_SECONDARYNAMENODE_USER=root
还有,start-yarn.sh,stop-yarn.sh顶部也需添加以下
#!/usr/bin/env bash YARN_RESOURCEMANAGER_USER=root HADOOP_SECURE_DN_USER=yarn YARN_NODEMANAGER_USER=root
修改后重启 ./start-dfs.sh,成功!

修改后重启 ./start-yarn.sh

避坑三:localhost:50070报错
hadoop3.X的webUI已经改到端口 localhost:9870

 浙公网安备 33010602011771号
浙公网安备 33010602011771号