CUDA入门笔记
硬件概念:
一个SM(Streaming Multiprocessor)中的所有SP(Streaming Processor)是分成Warp的,共享同一个Memory和Instruction Unit(指令单元)。
从硬件角度讲,一个GPU由多个SM组成(当然还有其他部分),一个SM包含有多个SP(以及还有寄存器资源,Shared Memory资源,L1cache,Scheduler,SPU,LD/ST单元等等)
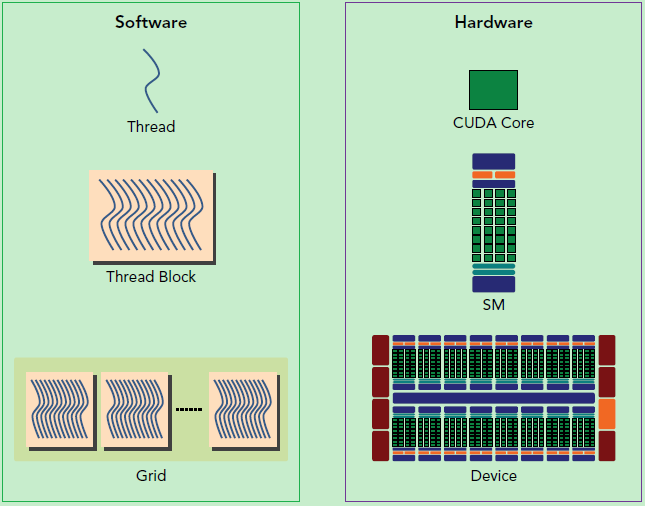
SM采用的是SIMT (Single-Instruction, Multiple-Thread,单指令多线程)架构,基本的执行单元是线程束(warps),线程束包含32个线程.
线程数尽量为32的倍数,因为线程束(Warp)共享一个内存和指令。假如线程数是1,则Warp会生成一个掩码,当一个指令控制器对一个Warp单位的线程发送指令时,32个线程中只有一个线程在真正执行,其他31个进程会进入静默状态。
了解硬件的代码:
cu文件:
#include <iostream>
#include "cuda_runtime.h"
int main() {
int dev = 0;
cudaDeviceProp devProp;
cudaGetDeviceProperties(&devProp, dev);
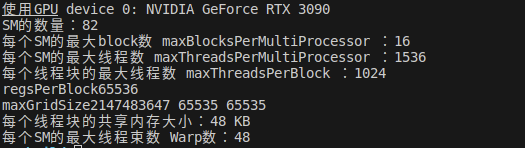
std::cout << "使用GPU device " << dev << ": " << devProp.name << std::endl;
std::cout << "SM的数量:" << devProp.multiProcessorCount << std::endl;
std::cout << "每个SM的最大block数 maxBlocksPerMultiProcessor :" << devProp.maxBlocksPerMultiProcessor << std::endl;
std::cout << "每个SM的最大线程数 maxThreadsPerMultiProcessor :" << devProp.maxThreadsPerMultiProcessor << std::endl;
std::cout << "每个线程块的最大线程数 maxThreadsPerBlock :" << devProp.maxThreadsPerBlock << std::endl;
std::cout << "regsPerBlock" << devProp.regsPerBlock << std::endl;
std::cout << "maxGridSize" << devProp.maxGridSize[0] << " " << devProp.maxGridSize[1] << " " << devProp.maxGridSize[2]<< std::endl;
std::cout << "每个线程块的共享内存大小:" << devProp.sharedMemPerBlock / 1024.0 << " KB" << std::endl;
std::cout << "每个SM的最大线程束数 Warp数:" << devProp.maxThreadsPerMultiProcessor / 32 << std::endl;
return 0;
}
CMakeLists:
cmake_minimum_required(VERSION 3.8)
project(CUDA_TEST)
find_package(CUDA REQUIRED)
message(STATUS "cuda version: " ${CUDA_VERSION_STRING})
include_directories(${CUDA_INCLUDE_DIRS})
cuda_add_executable(cuda_test src/test001.cu)
target_link_libraries(cuda_test ${CUDA_LIBRARIES})软件概念
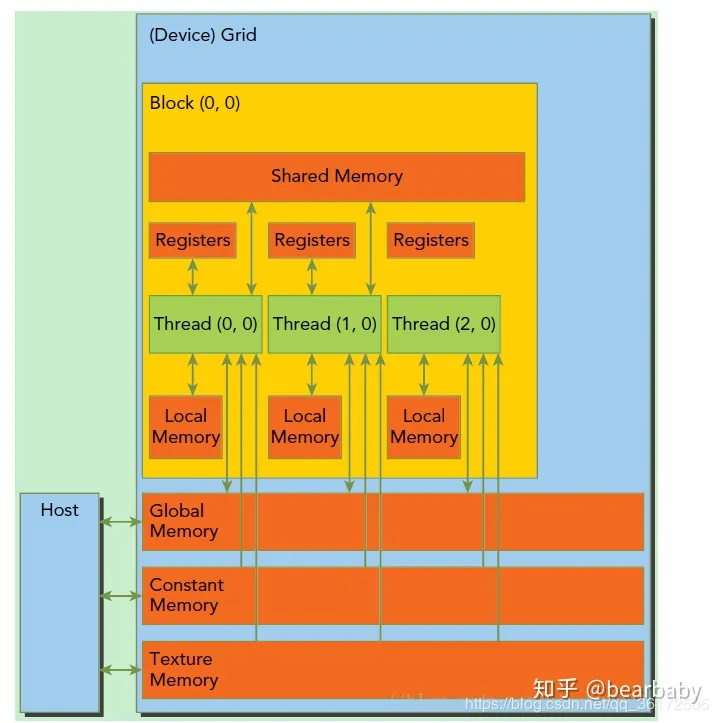
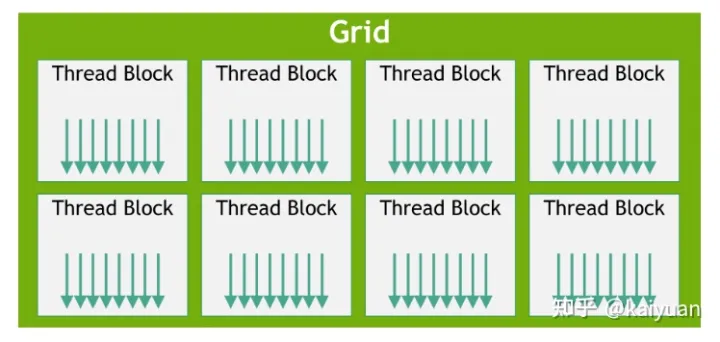
在利用cuda进行编程时,一个grid分为多个block,而一个block分为多个thread
- 每个 thread 都有自己的一份 register 和 local memory 的空间。
- 一组thread构成一个 block,这些thread 则共享有一份shared memory。
- 所有的 thread(包括不同 block 的 thread)都共享一份global memory、constant memory、和 texture memory。
- 不同的 grid 则有各自的 global memory、constant memory 和 texture memory。
- 每一个时钟周期内,warp(一个block里面一起运行的thread,其中各个线程对应的数据资源不同(指令相同但是数据不同)包含的thread数量是有限的,现在的规定是32个。一个block中含有16个warp。所以一个block中最多含有512个线程,每次Device(就是显卡)只处理一个grid。
- 一个sm只会执行一个block里的warp,当该block里warp执行完才会执行其他block里的warp。
cuda线程索引方式
cuda 通过<<<Gridsize Blocksize>>>符号来分配索引线程的方式
<<<>>>运算符完整的执行配置参数形式是<<<Dg, Db, Ns, S>>>
- 参数Dg(dim grid)用于定义整个grid的维度和尺寸,即一个grid有多少个block。为dim3类型。
Dim3 Dg(Dg.x, Dg.y, 1)表示grid中每行有Dg.x个block,每列有Dg.y个block,第三维恒为1(目前一个核函数只有一个grid)。
整个grid中共有Dg.x*Dg.y个block,其中Dg.x和Dg.y最大值为65535。
- 参数Db(dim block)用于定义一个block的维度和尺寸,即一个block有多少个thread。为dim3类型。
Dim3 Db(Db.x, Db.y, Db.z)表示整个block中每行有Db.x个thread,每列有Db.y个thread,高度为Db.z。
Db.x和Db.y最大值为512,Db.z最大值为62。 一个block中共有Db.x*Db.y*Db.z个thread。
计算能力为1.0,1.1的硬件该乘积的最大值为768,计算能力为1.2,1.3的硬件支持的最大值为1024。
- 参数Ns是一个可选参数,用于设置每个block除了静态分配的shared Memory以外,最多能动态分配的shared memory大小,单位为byte。
不需要动态分配时该值为0或省略不写。
- 参数S是一个cudaStream_t类型的可选参数,初始值为零,表示该核函数处在哪个流之中。
根据block和thread的维度不同 共有15种索引方式
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <stdio.h>
#include <stdlib.h>
#include <iostream>
using namespace std;
//thread 1D
__global__ void testThread1(int *c, const int *a, const int *b)
{
int i = threadIdx.x;
c[i] = b[i] - a[i];
}
//thread 2D
__global__ void testThread2(int *c, const int *a, const int *b)
{
int i = threadIdx.x + threadIdx.y*blockDim.x;
c[i] = b[i] - a[i];
}
//thread 3D
__global__ void testThread3(int *c, const int *a, const int *b)
{
int i = threadIdx.x + threadIdx.y*blockDim.x + threadIdx.z*blockDim.x*blockDim.y;
c[i] = b[i] - a[i];
}
//block 1D
__global__ void testBlock1(int *c, const int *a, const int *b)
{
int i = blockIdx.x;
c[i] = b[i] - a[i];
}
//block 2D
__global__ void testBlock2(int *c, const int *a, const int *b)
{
int i = blockIdx.x + blockIdx.y*gridDim.x;
c[i] = b[i] - a[i];
}
//block 3D
__global__ void testBlock3(int *c, const int *a, const int *b)
{
int i = blockIdx.x + blockIdx.y*gridDim.x + blockIdx.z*gridDim.x*gridDim.y;
c[i] = b[i] - a[i];
}
//block-thread 1D-1D
__global__ void testBlockThread1(int *c, const int *a, const int *b)
{
int i = threadIdx.x + blockDim.x*blockIdx.x;
c[i] = b[i] - a[i];
}
//block-thread 1D-2D
__global__ void testBlockThread2(int *c, const int *a, const int *b)
{
int threadId_2D = threadIdx.x + threadIdx.y*blockDim.x;
int i = threadId_2D+ (blockDim.x*blockDim.y)*blockIdx.x;
c[i] = b[i] - a[i];
}
//block-thread 1D-3D
__global__ void testBlockThread3(int *c, const int *a, const int *b)
{
int threadId_3D = threadIdx.x + threadIdx.y*blockDim.x + threadIdx.z*blockDim.x*blockDim.y;
int i = threadId_3D + (blockDim.x*blockDim.y*blockDim.z)*blockIdx.x;
c[i] = b[i] - a[i];
}
//block-thread 2D-1D
__global__ void testBlockThread4(int *c, const int *a, const int *b)
{
int blockId_2D = blockIdx.x + blockIdx.y*gridDim.x;
int i = threadIdx.x + blockDim.x*blockId_2D;
c[i] = b[i] - a[i];
}
//block-thread 3D-1D
__global__ void testBlockThread5(int *c, const int *a, const int *b)
{
int blockId_3D = blockIdx.x + blockIdx.y*gridDim.x + blockIdx.z*gridDim.x*gridDim.y;
int i = threadIdx.x + blockDim.x*blockId_3D;
c[i] = b[i] - a[i];
}
//block-thread 2D-2D
__global__ void testBlockThread6(int *c, const int *a, const int *b)
{
int threadId_2D = threadIdx.x + threadIdx.y*blockDim.x;
int blockId_2D = blockIdx.x + blockIdx.y*gridDim.x;
int i = threadId_2D + (blockDim.x*blockDim.y)*blockId_2D;
c[i] = b[i] - a[i];
}
//block-thread 2D-3D
__global__ void testBlockThread7(int *c, const int *a, const int *b)
{
int threadId_3D = threadIdx.x + threadIdx.y*blockDim.x + threadIdx.z*blockDim.x*blockDim.y;
int blockId_2D = blockIdx.x + blockIdx.y*gridDim.x;
int i = threadId_3D + (blockDim.x*blockDim.y*blockDim.z)*blockId_2D;
c[i] = b[i] - a[i];
}
//block-thread 3D-2D
__global__ void testBlockThread8(int *c, const int *a, const int *b)
{
int threadId_2D = threadIdx.x + threadIdx.y*blockDim.x;
int blockId_3D = blockIdx.x + blockIdx.y*gridDim.x + blockIdx.z*gridDim.x*gridDim.y;
int i = threadId_2D + (blockDim.x*blockDim.y)*blockId_3D;
c[i] = b[i] - a[i];
}
//block-thread 3D-3D
__global__ void testBlockThread9(int *c, const int *a, const int *b)
{
int threadId_3D = threadIdx.x + threadIdx.y*blockDim.x + threadIdx.z*blockDim.x*blockDim.y;
int blockId_3D = blockIdx.x + blockIdx.y*gridDim.x + blockIdx.z*gridDim.x*gridDim.y;
int i = threadId_3D + (blockDim.x*blockDim.y*blockDim.z)*blockId_3D;
c[i] = b[i] - a[i];
}
void addWithCuda(int *c, const int *a, const int *b, unsigned int size)
{
int *dev_a = 0;
int *dev_b = 0;
int *dev_c = 0;
cudaSetDevice(0);
cudaMalloc((void**)&dev_c, size * sizeof(int));
cudaMalloc((void**)&dev_a, size * sizeof(int));
cudaMalloc((void**)&dev_b, size * sizeof(int));
cudaMemcpy(dev_a, a, size * sizeof(int), cudaMemcpyHostToDevice);
cudaMemcpy(dev_b, b, size * sizeof(int), cudaMemcpyHostToDevice);
//testThread1<<<1, size>>>(dev_c, dev_a, dev_b);
//uint3 s;s.x = size/5;s.y = 5;s.z = 1;
//testThread2 <<<1,s>>>(dev_c, dev_a, dev_b);
//uint3 s; s.x = size / 10; s.y = 5; s.z = 2;
//testThread3<<<1, s >>>(dev_c, dev_a, dev_b);
//testBlock1<<<size,1 >>>(dev_c, dev_a, dev_b);
//uint3 s; s.x = size / 5; s.y = 5; s.z = 1;
//testBlock2<<<s, 1 >>>(dev_c, dev_a, dev_b);
//uint3 s; s.x = size / 10; s.y = 5; s.z = 2;
//testBlock3<<<s, 1 >>>(dev_c, dev_a, dev_b);
//testBlockThread1<<<size/10, 10>>>(dev_c, dev_a, dev_b);
//uint3 s1; s1.x = size / 100; s1.y = 1; s1.z = 1;
//uint3 s2; s2.x = 10; s2.y = 10; s2.z = 1;
//testBlockThread2 << <s1, s2 >> >(dev_c, dev_a, dev_b);
//uint3 s1; s1.x = size / 100; s1.y = 1; s1.z = 1;
//uint3 s2; s2.x = 10; s2.y = 5; s2.z = 2;
//testBlockThread3 << <s1, s2 >> >(dev_c, dev_a, dev_b);
//uint3 s1; s1.x = 10; s1.y = 10; s1.z = 1;
//uint3 s2; s2.x = size / 100; s2.y = 1; s2.z = 1;
//testBlockThread4 << <s1, s2 >> >(dev_c, dev_a, dev_b);
//uint3 s1; s1.x = 10; s1.y = 5; s1.z = 2;
//uint3 s2; s2.x = size / 100; s2.y = 1; s2.z = 1;
//testBlockThread5 << <s1, s2 >> >(dev_c, dev_a, dev_b);
//uint3 s1; s1.x = size / 100; s1.y = 10; s1.z = 1;
//uint3 s2; s2.x = 5; s2.y = 2; s2.z = 1;
//testBlockThread6 << <s1, s2 >> >(dev_c, dev_a, dev_b);
//uint3 s1; s1.x = size / 100; s1.y = 5; s1.z = 1;
//uint3 s2; s2.x = 5; s2.y = 2; s2.z = 2;
//testBlockThread7 << <s1, s2 >> >(dev_c, dev_a, dev_b);
//uint3 s1; s1.x = 5; s1.y = 2; s1.z = 2;
//uint3 s2; s2.x = size / 100; s2.y = 5; s2.z = 1;
//testBlockThread8 <<<s1, s2 >>>(dev_c, dev_a, dev_b);
uint3 s1; s1.x = 5; s1.y = 2; s1.z = 2;
uint3 s2; s2.x = size / 200; s2.y = 5; s2.z = 2;
testBlockThread9<<<s1, s2 >>>(dev_c, dev_a, dev_b);
cudaMemcpy(c, dev_c, size*sizeof(int), cudaMemcpyDeviceToHost);
cudaFree(dev_a);
cudaFree(dev_b);
cudaFree(dev_c);
cudaGetLastError();
}
int main()
{
const int n = 1000;
int *a = new int[n];
int *b = new int[n];
int *c = new int[n];
int *cc = new int[n];
for (int i = 0; i < n; i++)
{
a[i] = rand() % 100;
b[i] = rand() % 100;
c[i] = b[i] - a[i];
}
addWithCuda(cc, a, b, n);
FILE *fp = fopen("out.txt", "w");
for (int i = 0; i < n; i++)
fprintf(fp, "%d %d\n", c[i], cc[i]);
fclose(fp);
bool flag = true;
for (int i = 0; i < n; i++)
{
if (c[i] != cc[i])
{
flag = false;
break;
}
}
if (flag == false)
printf("no pass");
else
printf("pass");
cudaDeviceReset();
delete[] a;
delete[] b;
delete[] c;
delete[] cc;
getchar();
return 0;
}Gridsize Blocksizes如何设置?
GPU 的特点是高吞吐高延迟,要尽量保证同一时间流水线上有足够多的指令(同一内存的数据被处理足够多次)。
要到达这个目最简单的方法是让尽量多的线程同时在 SM 上执行,SM 上并发执行的线程数和SM 上最大支持的线程数的比值,被称为 Occupancy,更高的 Occupancy 代表潜在更高的性能。
一个 kernel 的 block_size 应大于 SM 上最大线程数和最大 block 数的比值(对于 RTX 3090 是 block_size->1536 / 16 = 96),否则就无法达到 100% 的 Occupancy(如果小于96 则 block_size*16 < 1536 无法跑满)。
对应不同的架构,这个比值不相同,对于 V100 、 A100、 GTX 1080 Ti 是 2048 / 32 = 64,对于 RTX 3090 是 1536 / 16 = 96,所以为了适配主流架构,如果静态设置 block_size 不应小于 96。
考虑到 block 调度的原子性,那么 block_size 应为 SM 最大线程数的约数,否则也无法达到 100% 的 Occupancy,主流架构的 GPU 的 SM 最大线程数的公约是 512,96 以上的约数还包括 128 和 256,
也就是到目前为止,block_size 的可选值仅剩下 128 / 256 / 512 三个值。
grid_size尽可能大 如dim3 gs(512,512)
dim3 gs(imgWidth_d / block.x, imgHeight_d / block.y);
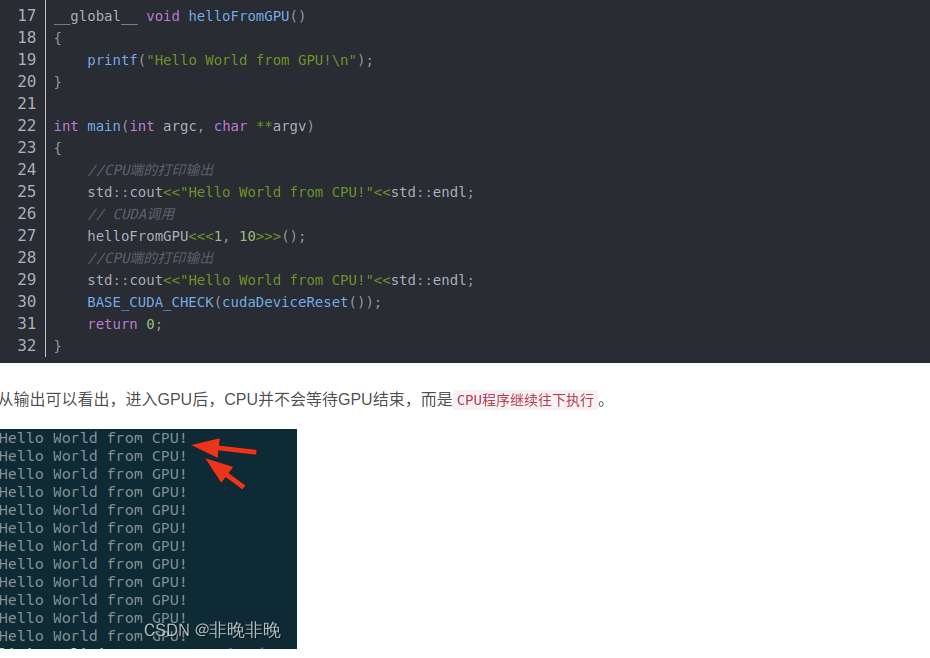
cuda helloworld编程
矩阵相乘的实例:
#include <iostream>
#include "cuda_runtime.h"
const int width = 20;
const int height = 20;
__global__ void MatMulti(float* A, float* B, float* C, int width){
int i = blockIdx.x * blockDim.x + threadIdx.x;
int j = blockIdx.y * blockDim.y + threadIdx.y;
float c{0.0f};
for (int k = 0; k < width; k++){
float a = A[j*width + k];
float b = B[k*width + i];
c += a*b;
}
C[j*width + i] = c;
}
int main() {
float* A;
float* B;
float* C;
float* A_cuda;
float* B_cuda;
float* C_cuda;
// 申请托管内存
cudaMallocManaged((void**)&A_cuda, width*height*sizeof(float));
cudaMallocManaged((void**)&B_cuda, width*height*sizeof(float));
cudaMallocManaged((void**)&C_cuda, width*height*sizeof(float));
// 初始化数据
A = new float[width*height];
B = new float[width*height];
C = new float[width*height];
for (int i = 0; i < width*height; ++i){
A[i] = 1.0;
B[i] = 2.0;
C[i] = 0.0;
}
cudaMemcpy(A_cuda, A, width*height*sizeof(float), cudaMemcpyHostToDevice);
cudaMemcpy(B_cuda, B, width*height*sizeof(float), cudaMemcpyHostToDevice);
// 定义kernel的执行配置
dim3 gs(512, 512); //3090有 82个SM 每个SM上有16个block
dim3 bs(512); //3090 一个block中有1024个线程 有32个warp
// 执行kernel
MatMulti<<<gs, bs>>>(A_cuda, B_cuda, C_cuda, width);
// 同步device 保证结果能正确访问
cudaDeviceSynchronize();
cudaMemcpy(C, C_cuda, width*height*sizeof(float), cudaMemcpyDeviceToHost);
// 检查执行结果
for (int i = 0; i < width*height; ++i){
std::cout << C[i] << "\n";
}
int dev = 0;
cudaDeviceProp devProp;
cudaGetDeviceProperties(&devProp, dev);
std::cout << "使用GPU device " << dev << ": " << devProp.name << std::endl;
std::cout << "SM的数量:" << devProp.multiProcessorCount << std::endl;
std::cout << "每个SM的最大block数 maxBlocksPerMultiProcessor :" << devProp.maxBlocksPerMultiProcessor << std::endl;
std::cout << "每个SM的最大线程数 maxThreadsPerMultiProcessor :" << devProp.maxThreadsPerMultiProcessor << std::endl;
std::cout << "每个线程块的最大线程数 maxThreadsPerBlock :" << devProp.maxThreadsPerBlock << std::endl;
std::cout << "regsPerBlock" << devProp.regsPerBlock << std::endl;
std::cout << "maxGridSize" << devProp.maxGridSize[0] << " " << devProp.maxGridSize[1] << " " << devProp.maxGridSize[2]<< std::endl;
std::cout << "每个线程块的共享内存大小:" << devProp.sharedMemPerBlock / 1024.0 << " KB" << std::endl;
std::cout << "每个SM的最大线程束数 Warp数:" << devProp.maxThreadsPerMultiProcessor / 32 << std::endl;
return 0;
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号