Python namedtuple(命名元组)使用实例
Python namedtuple(命名元组)使用实例
#!/usr/bin/python3
import collections
MyTupleClass = collections.namedtuple('MyTupleClass',['name', 'age', 'job'])
obj = MyTupleClass("Tomsom",12,'Cooker')
print(obj.name)
print(obj.age)
print(obj.job)
执行结果:
Tomsom 12 Cooker

namedtuple对象就如它的名字说定义的那样,你可以给tuple命名,具体看下面的例子:
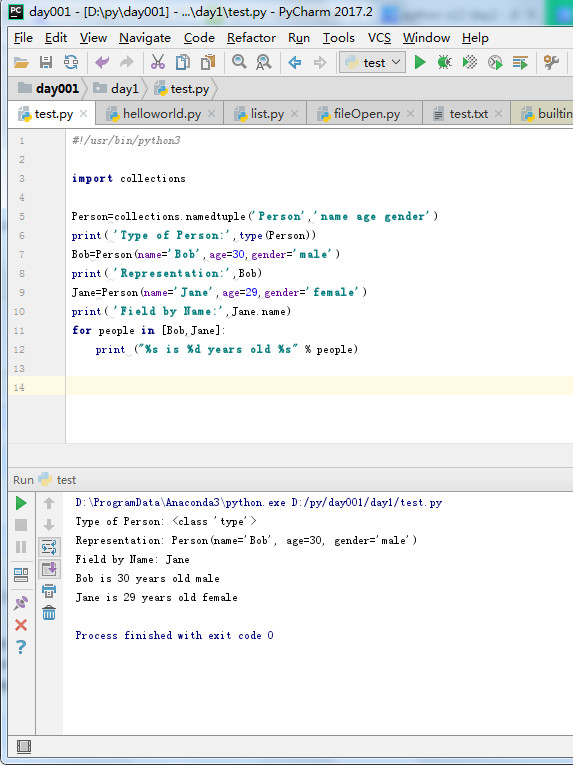
#!/usr/bin/python3
import collections
Person=collections.namedtuple('Person','name age gender')
print( 'Type of Person:',type(Person))
Bob=Person(name='Bob',age=30,gender='male')
print( 'Representation:',Bob)
Jane=Person(name='Jane',age=29,gender='female')
print( 'Field by Name:',Jane.name)
for people in [Bob,Jane]:
print ("%s is %d years old %s" % people)
执行结果:
Type of Person: <class 'type'> Representation: Person(name='Bob', age=30, gender='male') Field by Name: Jane Bob is 30 years old male Jane is 29 years old female
来解释一下nametuple的几个参数,以Person=collections.namedtuple(‘Person’,'name age gender’)为例,其中’Person’是这个namedtuple的名称,后面的’name age gender’这个字符串中三个用空格隔开的字符告诉我们,我们的这个namedtuple有三个元素,分别名为name,age和gender。我们在 创建它的时候可以通过Bob=Person(name=’Bob’,age=30,gender=’male’)这种方式,这类似于Python中类对象 的使用。而且,我们也可以像访问类对象的属性那样使用Jane.name这种方式访问namedtuple的元素。其输出结果如下:
但是在使用namedtyuple的时候要注意其中的名称不能使用Python的关键字,如:class def等;而且也不能有重复的元素名称,比如:不能有两个’age age’。如果出现这些情况,程序会报错。但是,在实际使用的时候可能无法避免这种情况,比如:可能我们的元素名称是从数据库里读出来的记录,这样很难保 证一定不会出现Python关键字。这种情况下的解决办法是将namedtuple的重命名模式打开,这样如果遇到Python关键字或者有重复元素名 时,自动进行重命名。
看下面的代码:
import collections
with_class=collections.namedtuple('Person','name age class gender',rename=True)
print with_class._fields
two_ages=collections.namedtuple('Person','name age gender age',rename=True)
print two_ages._fields
其输出结果为:
('name', 'age', '_2', 'gender')
('name', 'age', 'gender', '_3')
我们使用rename=True的方式打开重命名选项。可以看到第一个集合中的class被重命名为 ‘_2' ; 第二个集合中重复的age被重命名为 ‘_3'这是因为namedtuple在重命名的时候使用了下划线 _ 加元素所在索引数的方式进行重命名。
附两段官方文档代码实例:
1) namedtuple基本用法
>>> # Basic example
>>> Point = namedtuple('Point', ['x', 'y'])
>>> p = Point(11, y=22) # instantiate with positional or keyword arguments
>>> p[0] + p[1] # indexable like the plain tuple (11, 22)
33
>>> x, y = p # unpack like a regular tuple
>>> x, y
(11, 22)
>>> p.x + p.y # fields also accessible by name
33
>>> p # readable __repr__ with a name=value style
Point(x=11, y=22)
2) namedtuple结合csv和sqlite用法
EmployeeRecord = namedtuple('EmployeeRecord', 'name, age, title, department, paygrade')
import csv
for emp in map(EmployeeRecord._make, csv.reader(open("employees.csv", "rb"))):
print(emp.name, emp.title)
import sqlite3
conn = sqlite3.connect('/companydata')
cursor = conn.cursor()
cursor.execute('SELECT name, age, title, department, paygrade FROM employees')
for emp in map(EmployeeRecord._make, cursor.fetchall()):
print(emp.name, emp.title)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号