

In a typical Hadoop MapReduce job, input files are read from HDFS. Data are usually compressed to reduce the file sizes. After decompression, serialized bytes are transformed into Java objects before being passed to a user-defined map() function. Conversely, output records are serialized, compressed, and eventually pushed back to HDFS. This seemingly simple, two-way process is in fact much more complicated due to a few reasons:
在一个典型的hadoop mapreduce job 输入文件是从hdfs当中读取的.数据往往是经过压缩的来减少文件的大小.在解压后,被传递到用户定义的map()函数之前被转换成Java对象序列化字节。相反,输出记录序列化,压缩,并最终推后到HDFS。这个看似简单的,双向的过程,实际上复杂得多,由于几个原因:
•压缩和减压,通常是通过本地的库代码。
•最终到终端的读或写时总是验证或计算CRC32校验。
•缓冲区管理是复杂的,由于各种接口限制。
在这个博客后,我尝试,分解和分析详细的Hadoop的I / O管道,并探讨可能的优化。为了保持讨论的具体,我要使用的行记录/ gzip压缩文本文件的阅读和写作无处不在的例子。我不会进入管道DataNode上的细节,而不是主要集中在客户端(Map / Reduce的任务流程)。最后,所有的描述都是基于Hadoop的0.21在写这篇文章的时间,这意味着你可能会看到不同的事情,如果您使用的是旧或较新版本的Hadoop的主干。
读输入
图1说明了阅读由gzip压缩的文本文件,使用TextInputFormat行记录时的I / O管道。这个数字除以在双方隔开薄的差距。左侧显示的DataNode的过程中,右侧应用过程中(即map任务)。从底部到顶部,有缓冲区分配或操纵三个区域:内核空间,本机代码的空间,和JVM空间。应用过程中,由左到右,有一个数据块需要遍历的软件层。用不同颜色的盒子是各种各样的缓冲区。两箱之间的箭头表示数据传输或复制缓冲区。箭头的重量表示正在传输的数据量。在每一个箱子的标签显示缓冲区的大致位置(变量引用的缓冲区,缓冲区分配模块)。如果可用,缓冲区的大小是在方括号中。如果缓冲区的大小是可配置的,然后配置属性和默认大小显示。我的标签每个数据传输与数字的一步转移发生的地方:
 |
1.Data转移从DataNode MapTask过程。 DBlk文件数据块; CBlk文件的校验块。文件数据传送到客户端通过Java NIO transferTo(又名UNIX的sendfile系统调用)。校验数据先提取DataNode JVM的缓冲区,然后推到客户端(细节未显示)。这两个文件中的数据和校验数据被捆绑在HDFS的数据包(通常是64KB)的格式:{数据包报头|校验字节|数据字节}。
2.Data收到从插座一个BufferedInputStream缓冲,想必内核系统调用的数量减少的目的。这实际上涉及到两个缓冲区副本:第一,数据将被复制在JDK代码直接到一个临时缓冲区从内核缓冲区;第二,数据是直接从临时缓冲区复制到BufferedInputStream的拥有[]缓冲区的字节。 []在BufferedInputStream的字节大小是由配置属性“io.file.buffer.size”,并默认为4K。在我们的生产环境,这个参数是自定义为128K。
3.Through BufferedInputStream的校验字节保存到内部的ByteBuffer(其大小大约是(PACKETSIZE / 512 * 4)或512B),并存入到字节的文件字节(压缩数据)[]减压提供的缓冲区层。由于校验和计算,需要一个完整的512字节的块,而用户的请求可能不会被一个块边界对齐,512B字节[]缓冲区是用来对齐局部块复制到用户提供的字节[]缓冲区之前输入。另外请注意,数据复制缓冲区512字节块(由FSInputChecker API)。最后,所有的校验字节复制到FSInputChecker执行校验和验证的4个字节的数组。总体而言,这一步需要额外的缓冲区拷贝。
4,减压层使用一个byte [] DFSClient层接收数据的缓冲区。 DecompressorStream副本从byte []的缓冲区数据到一个64K的直接缓冲区,调用本机库的代码,解压缩字节的数据和存储在另一个64K的直接缓冲区。这一步涉及到两个缓冲区拷贝。
5.LineReader维护一个内部的缓冲,吸收来自下游的数据。从缓冲区中,发现行分隔符和行字节被复制到表单中的文本对象。这一步需要两个缓冲区副本。
Optimizing Input Pipeline
Adding everything up, including a "copy" for decompressing bytes, the whole read pipeline involves seven buffer-copies to deliver a record to MapTask's map() function since data are received in the process's kernel buffer. There are a couple of things that could be improved in the above process:
优化输入管道
添加一切,包括解压缩字节的“复制”,整个读取管道涉及7个缓冲区副本提供一个记录,因为数据在进程的内核缓冲区收到MapTask的map()函数。有很多情侣在上述过程中,可以改善的东西:
•Many buffer-copies are needed simply to convert between direct buffer and byte[] buffer.
•Checksum calculation can be done in bulk instead of one chunk at a time.
•许多缓冲区副本需要简单地转换之间的直接缓冲区和字节[]缓冲区。
•校验和计算,可以做一次散装,而不是一大块。
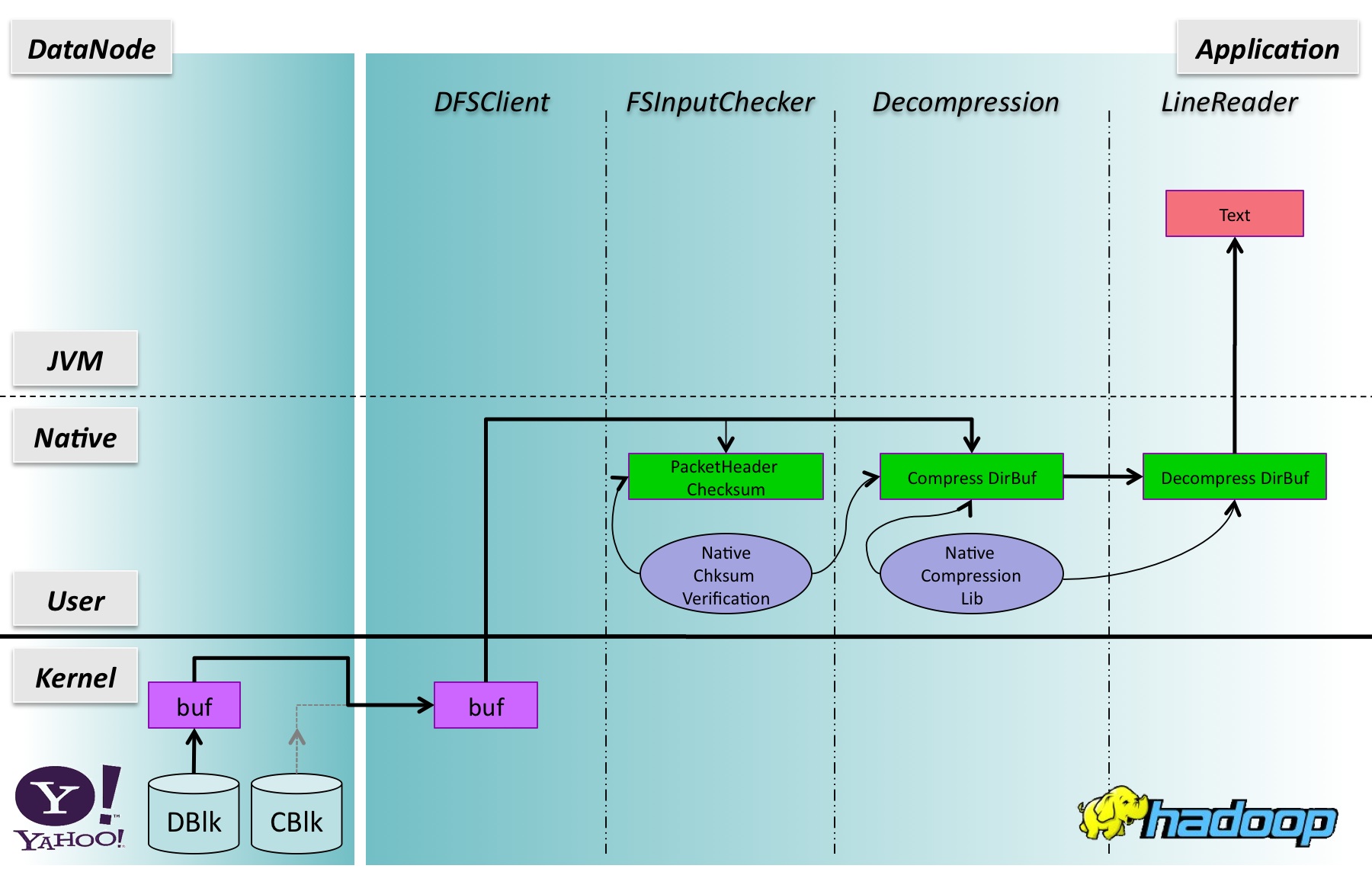 |
Figure 2 shows the post-optimization view where the total number of buffer copies is reduced from seven to three:
1.An input packet is decomposed into the checksum part and the data part, which are scattered into two direct buffers: an internal one for checksum bytes, and the direct buffer owned by the decompression layer to hold compressed bytes. The FSInputChecker accesses both buffers directly.
2.The decompression layer deflates the uncompressed bytes to a direct buffer owned by the LineReader.
3.LineReader scans the bytes in the direct buffer, finds the line separators from the buffer, and constructs Text objects.
图2显示了优化后视图缓存副本的总数是从七个减少到三个:
1.An的输入数据包分解成的校验的一部分,数据的一部分,这是分散到两个直接缓冲区:内部校验字节,直接减压层举行压缩字节的缓冲区拥有的之一。直接FSInputChecker访问这两个缓冲区。
2,减压层放气压缩字节LineReader拥有一个直接缓冲区。
3.LineReader在直接缓冲区的字节进行扫描,发现从缓冲区的行分隔符,并构造文本对象。
写作输出
现在,让我们的换档和看故事的写端。图3显示了I / O管道时ReduceTask写入到一个gzip压缩的文本文件,使用TextOutputFormat行记录。与图1类似,每个数据传输标签与数字发生转移的步骤:
图3:写入gzip压缩的文本文件的行记录。
 |
1.TextOutputFormat的RecordWriter是缓冲。当用户发出一个行记录,文本对象的字节被直接复制到一个64KB的直接压缩层所拥有的缓冲区。对于一个很长的的线,它会被复制到这个缓冲区64KB多次的时候。
2.Every时间压缩层收到一条线(或一个很长的线的一部分),被称为本机的压缩代码,并压缩字节存储到另一个64KB直接缓冲区。的数据,然后从直接缓冲区复制到内部字节[]缓冲区,然后倒推DFSClient层压缩层拥有,因为DFSClient层只接受字节[]缓冲区作为输入。重新控制这个缓冲区的大小是由配置属性“io.file.buffer.size”。这一步涉及到两个缓冲区拷贝。
3.FSOutputSummer计算CRC32校验字节[]缓冲区的压缩层和存款数据字节和一个字节的校验和字节[]在包对象的缓冲区。同样,校验和计算,必须完成对整个512B块,以及内部512B字节[]缓冲区是用来保存局部块,可能会导致压缩数据块边界对齐。首先是计算校验和存储在一个字节[]缓冲区之前的数据包被复制到4B。这一步涉及到一个缓冲区拷贝。
4。当一个数据包是完整的,数据包推到一个队列的长度是有限的,以80的。包的大小是由配置属性“dfs.write.packet.size”是默认为64KB。这一步涉及到没有缓冲拷贝。
5.A DataStreamer线程等待队列,每当它收到一个发送数据包套接字。插座是包裹着一个BufferedOutputStream。但字节[]缓冲区是非常小的(不超过512B),它通常是绕过。的数据,但是,仍然需要被复制到一个临时的直接缓冲区拥有JDK代码。这一步需要两个数据副本。
6.Data发送ReduceTask的内核缓冲区的DataNode的内核缓冲区。座的文件和校验文件存储数据之前,有几个DataNode方的缓冲区拷贝。与读的DFS的情况下,这两个文件的数据和校验数据将遍历内核,到JVM土地。这一过程的细节不在这里的讨论,并没有在图中所示
优化输出管道
总体而言,包括压缩字节的“复制”,上述过程需要六个输出线记录缓冲区副本达到ReduceTask的内核缓冲区。我们能做什么来优化写管道?
•我们或许可以减少一些缓冲区副本。
•本机的压缩代码可能不经常调用,如果我们把它称为后,才输入缓冲区已满(块像LZO压缩编解码器已经做到这一点)。
•校验和计算,可以做一次散装,而不是一大块。
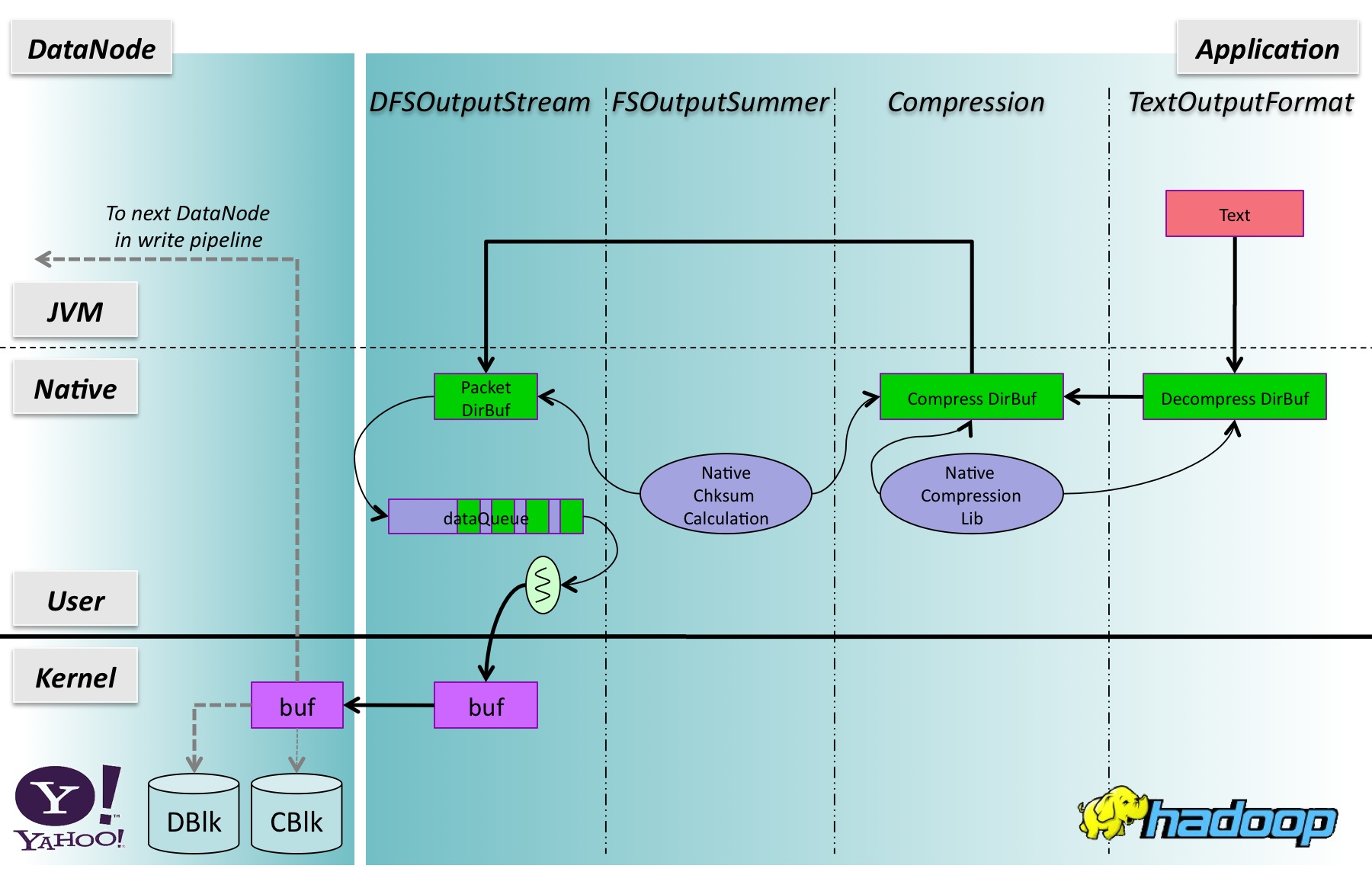 |
图4:优化输出管道
图4:优化输出管道。
图4显示了它是如何看起来像后,这些优化是必要的,共有4个缓冲区拷贝:
1.Bytes从一个用户的文本对象复制到TextOutputFormat层所拥有的的直接缓冲区。
2.Once此缓冲区已满,被称为本地压缩代码,压缩后的数据存入一个压缩层所拥有的的直接缓冲区。
3.FSOutputSummer计算直接从压缩层的缓冲区的字节的校验,并保存到一个数据包的直接缓冲区字节的数据和校验字节。
4.A完整的数据包将被推入队列,背景,DataStreamer线程通过套接字,这副本被复制到内核缓冲区的字节发送数据包。
结论
此博客张贴了一个下午花自问Hadoop的I / O的具体问题,并验证代码中的答案。事实证明,经过梳理后,通过类的类,管道比我们原先想象的更为复杂。虽然我们每个人都熟悉一个或多个组件,我们发现前面的Hadoop的I / O阐明全面的图片,我们希望其他开发者和用户,也。有效上文所述的优化,将是一项艰巨的任务,这是朝着更高性能的Hadoop的第一步

 浙公网安备 33010602011771号
浙公网安备 33010602011771号