为什么MySQL要用B+树?聊聊B+树与硬盘的前世今生【宇哥带你玩转MySQL 索引篇(二)】
为什么MySQL要用B+树?聊聊B+树与硬盘的前世今生
在上一节,我们聊到数据库为了让我们的查询加速,通过索引方式对数据进行冗余并排序,这样我们在使用时就可以在排好序的数据里进行快速的二分查找,使得查询效率指数提升。但是我在结尾同样提到一个问题,就是内存大小一般是很有限的,不可能把一个表所有的数据都加载到内存中,那么我们该如何解决这个问题呢?在解决这个问题之前,需要先简单了解一下硬盘知识
硬盘知识简介
由于机械硬盘的高耐久,低成本,现在仍然是数据存储的主流,所以这里着重讨论机械硬盘,下面是一个机械硬盘结构图

机械硬盘的数据都存放在盘片中,当我们从硬盘读取数据时,我们需要提供一个地址,然后硬盘通过前后移动磁头寻址,最后把地址对应数据返回。
这里有两个过程很重要,一个是寻址,一个是读取数据。以目前机械硬盘的速度,如果我们要从机械硬盘读取一条1KB的数据大概只需要0.01ms(100MB/s),而寻址却平均在10ms左右。通常我们把读取一段连续的数据,不需要多次寻址的操作叫做顺序读,而读取不连续的数据需要多次寻址的操作叫做随机读,用来区分它们之间的性能差距。
为了充分利用机械硬盘的性能,通常把相关数据连续保存,这样就可以一次加载更多的数据,减少磁头的的移动次数。操作系统有很多对此的优化,例如Linux ext3文件系统默认块大小就是4kb。还有linux预加载能力,即当你频繁访问一块数据时,系统会帮你把相邻的数据也加载进来。
MySQL InnoDB与硬盘
了解完机械硬盘的基本知识,现在回到MySQL,MySQL InnoDB引擎也会把数据进行分块存储,默认是16KB。所以我们上一节中的索引结构图在硬盘中的存储就是每16KB为一个块,当一个块快存放快满的时候开辟一个新的块来存放。
以books表为例
create table books( id int not null primary key auto_increment, name varchar(255) not null, author varchar(255) not null,
price decimal(12,2) not null, create_date date not null, updated_at datetime not null default current_timestamp on update current_timestamp, index idx_books_create_date_price(create_date,price) )engine=InnoDB;
该表name字段的索引idx_books_create_date_price在硬盘中的存放就如下图
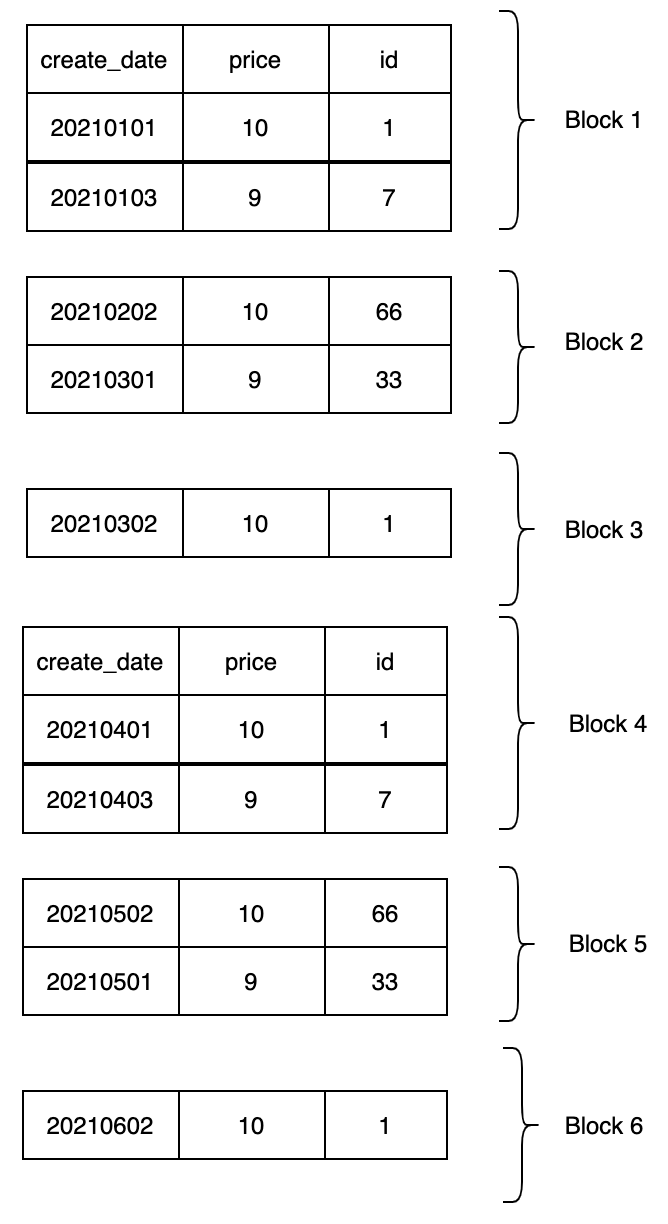
当块越来越多的时候,我们可能无法一次把所有的块都加载到内存,此时就要对每个块再进行索引,如下图:

每个块的上一级都存放着一条指向该块的地址。这样只需要加载顶部的第一块,然后通过区间判断就可以找到下一块的地址。
例如我们查询一条date=20210502的记录,过程如下:
1. 先从左边顶部块开始查找,发现"date=20210502"在"date=20210301"到"date=20210503"区间
2. 加载区间对应的下一级块
3. 发现"date=20210502"在"date=20210403"与"date=20210602"区间,加载区间对应下一级块
4. 发现该块为叶子节点,在该块使用二分搜索进行查询,最终找到记录
如果把上图旋转一个,可以发现,整个图就是一个树,这其实就是B+树。B+树通过对数据块进行索引,使得当数据量很大,无法一次全部加载到内存时,可以先加载一个表的顶部数据块,然后根据数据所在区间再加载下一级的数据块。这样既保证了我们的快速搜索,又减少了内存使用。
MySQL InnoDB的聚簇索引和二级索引
了解了B+树,现在就可以很容易区分MySQL的聚簇索引和二级索引。
聚簇索引就是用主键生成B+树,在叶子节点存放这条记录的完整信息
二级索引就是用索引行生成B+树,在叶子节点只存放索引行和该行对应的主键信息
下面是聚簇索引和二级索引的区分图
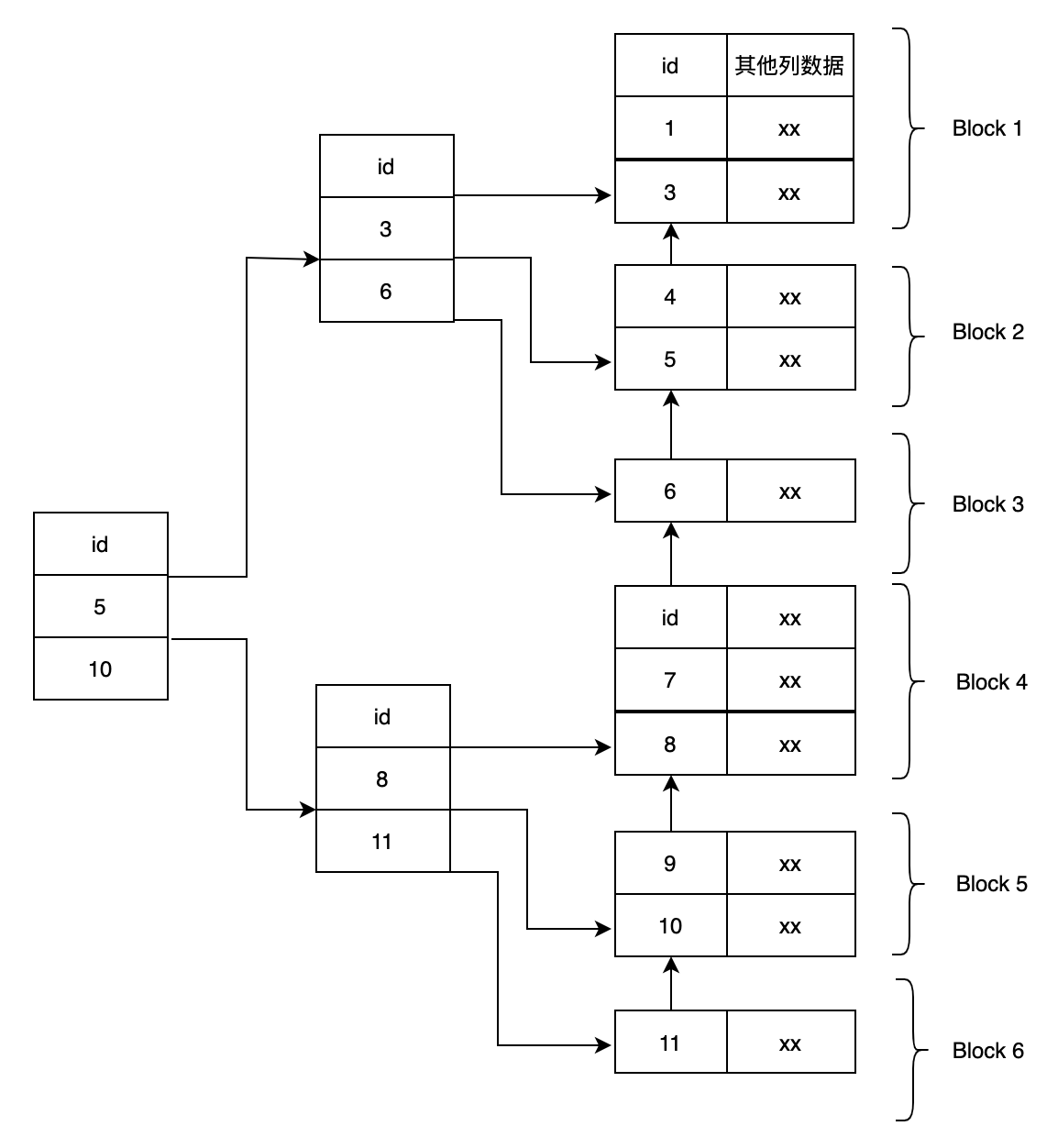

了解上面的知识,对于一个查询,我们就可以大概想象出他的执行步骤
select * from books where name = "name400";
例如上面sql的执行步骤如下:
1. 在二级索引idx_books_name索引中查找name="name400"的字段所对应的主键id
2. 通过主键id在聚簇索引找到此id所对应的记录
3. 返回记录中的所有字段
当我们select的字段在二级索引上不存在时,都需要使用聚簇索引回表查询剩余字段。所以聚簇索引,也就是我们所说的id列,占用空间越小越好, 这样就可以在一个节点中存放更多的id值,减少树的层级,加速查询效率。一般推荐主键使用int或者bigint而不是字符串。同时最好保证插入的id值为递增的,这样就不会造成在一个已经满的节点中插入一条记录造成页分裂,降低查询效率。
小结
这节我们先了解了硬盘的基础知识,知道了机械硬盘的顺序读与随机读的巨大性能差距,以及操作系统为了优化磁盘性能而把数据进行按块存储。然后又学习了MySQL通过使用B+树,把存放索引的多个数据块进行索引,解决了我们上一节使用二分搜索需要先把所有数据都加载到内存的问题。最后,我们了解了聚簇索引和二级索引的区别,以及其中的使用建议。
下一节,我们会聊一聊如何创建一个好的索引,判断一个索引的好坏标准有哪些。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号