十五、双向链表的实现
单链表的每个结点增加一个指针域,用于指向结点的前驱
单链表的另一个缺陷:
- 单向性:只能从头结点开始高效访问链表中的数据元素
- 缺陷:如果需要逆向访问单链表中的数据元素将及其低效
int main()
{
LinkList<int> l;
for(int i = 0; i < 5; i++) // O(n)
{
l.insert(0, i); // 时间复杂度为O(1),往单链表0结点插入元素,耗时为常数
}
// 逆向遍历的时候,非常低效
for(int i = l.length()-1; i >=0; i--) // O(n^2)
{
cout << l.get(i) << endl;
}
}
新的线性表,设计思路:
在“单链表”的结点中增加一个指针pre,用于指向当前结点的前驱结点。
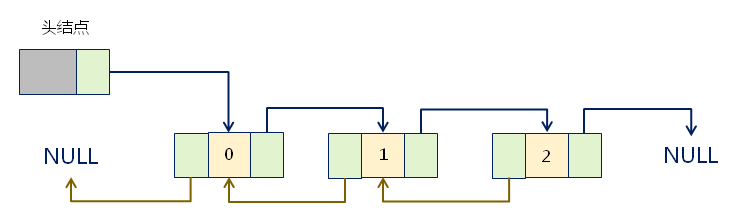
好处:不管游标目前为与哪个位置上,都可以通过next指针访问后继结点,通过pre指针访问前驱结点。
双向链表的继承层次结构
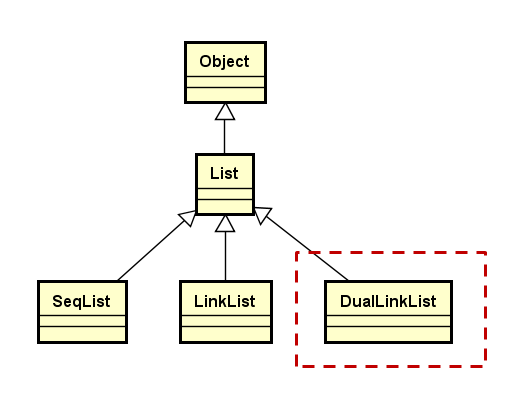
因为双向链表在内部的实现上与单链表有较大差异,所以将其与单链表放在了同级,而不是单链表的子类。用单链表的地方可以完全用双向链表来代替。
DualLinkList的实现
#ifndef DUALLINKLIST_H
#define DUALLINKLIST_H
namespace DTLib
{
template <typename T>
class DualLinkList : public List<T>
{
protected:
struct Node : public Object
{
T value; // 数据域
Node* next; // 指针域
Node* pre;
};
// 头结点,是不是弄成指针更方便点儿
// mutable Node m_header;
// 创建m_header时,会调用T value,用泛指类型创建头结点的数据域,当泛指类型为用户自定义类型时,用用户自定义的类类型在库中创建对象,就有可能出错了,而且在外部看来,并没有用该类型创建对象,问题定位很麻烦
// 解决办法:构造头结点时,不调用泛指类型创建头结点,而是按内存分布自己重新构造
// 在内存布局上和之前没有差异,差异在于不管泛指类型是什么,都不会去调用泛指类型的构造函数了
// 虽然内存布局上是一样的,但是是个空类型,不能直接用,要进行类型转换
// 同样要继承于Object
mutable struct : public Object
{
char reserved[sizeof(T)]; // 没实际作用,占空间
Node* next;
Node* pre;
} m_header;
int m_length; // 记录链表长度
int m_step;
Node* m_current;
Node* position(int i) const // O(n)
{
Node* ret = reinterpret_cast<Node*>(&m_header);
for(int p = 0; p < i; p++)
{
ret = ret->next;
}
return ret;
}
// 封装下
virtual Node* create()
{
return new Node();
}
virtual void destory(Node* pn)
{
delete pn;
}
public:
DualLinkList()
{
m_header.next = NULL;
m_header.pre = NULL;
m_length = 0;
m_step = 1;
m_current = NULL;
}
bool insert(const T& e)
{
return insert(m_length, e);
}
bool insert(int i, const T& e) // O(n)
{
// 注意i的范围
bool ret = ((i>=0) && (i<=m_length));
if (ret)
{
// Node* node = new Node();
Node* node = create(); // 这里的create动态决定,是虚函数,根据Node对象的类型来决定
if (node != NULL)
{
// current的目标指向其实都是目标位置的前一个,比如:在第0个位置增加元素,current指向的是header
Node* current = position(i);
Node* next = current->next;
node->value = e;
node->next = next;
current->next = node;
// 注意current是不是头结点
if(current != reinterpret_cast<Node*>(&m_header))
{
node->pre = current;
}
else
{
node->pre = NULL;
}
if(next != NULL)
{// 在最后插入
next->pre = node;
}
m_length++;
}
else
{
THROW_EXCEPTION(NoEnoughMemoryException, "No memory to insert new element");
}
}
return ret;
}
bool remove(int i) // O(n)
{
// 注意i的范围
bool ret = ((i>=0) && (i<m_length));
if (ret)
{
Node* current = position(i);
Node* toDel = current->next;
Node* next = toDel->next;
if(m_current == toDel)
{
m_current = next;
}
current->next = next;
if(next != NULL)
{
next->pre = toDel->pre;
}
m_length--;
destory(toDel);
}
return ret;
}
bool set(int i, const T& e) // O(n)
{
// 注意i的范围
bool ret = ((i>=0) && (i<m_length));
if (ret)
{
// Node* current = position(i);
position(i)->next->value = e;
}
return ret;
}
// get函数用起来不方便,重载一下
virtual T get(int i) const // O(n)
{
T ret;
if (get(i, ret))
{
return ret;
}
else
{
THROW_EXCEPTION(IndexOutOfBoundsException, "Invalid parameter i to get element...");
}
}
bool get(int i, T& e) const // O(n)
{
bool ret = ((i>=0) && (i<m_length));
if (ret)
{
// Node* current = position(i);
e = position(i)->next->value;
// get是const成员函数,按理来说不能修改成员变量的值,Node* current=&m_header,会被误认为要更改成员变量的值,故报错
// 解决方案是对m_header加上mutable,开一个例外
}
return ret;
}
int find(const T& e) const // O(n)
{
int ret = -1;
int i = 0;
Node* node = m_header.next;
while(node)
{
if(node->value == e)
{
ret = i;
break;
}
else
{
node = node->next;
i++;
}
}
return ret;
}
int length() const // O(1)
{
return m_length;
}
void clear() // O(n)
{
// 释放每一个结点
while(m_length > 0)
{
remove(0);
}
}
// 遍历操作
// i 目标位置,step 游标每次移动结点的数目
virtual bool move(int i, int step = 1) // O(n)
{
bool ret = ((i >= 0) && (i < m_length) && (step > 0));
if(ret)
{
// 将游标定位到目标位置i的地方
m_current = position(i)->next;
m_step = step;
}
return ret;
}
virtual bool end()
{
return (m_current == NULL);
}
virtual T current()
{
// 返回游标指向的位置的元素值
//if(m_current != NULL)
if(!end())
{
return m_current->value;
}
else
{
THROW_EXCEPTION(InvalidOperationException, "No value at current position...");
}
}
virtual bool next()
{
int i = 0;
while((i<m_step) && !end())
{
m_current = m_current->next;
i++;
}
// i的值和m_step的值是一样的,就表示移动成功
return (i == m_step);
}
virtual bool pre()
{
int i = 0;
while((i<m_step) && !end())
{
m_current = m_current->pre;
i++;
}
// i的值和m_step的值是一样的,就表示移动成功
return (i == m_step);
}
~DualLinkList() // O(n)
{
clear();
}
};
}
#endif // DUALLINKLIST_H
// main.c
#include <iostream>
#include "DualLinkList.h"
using namespace std;
using namespace DTLib;
int main()
{
DualLinkList<int> dl;
for(int i = 0; i < 5; i++)
{
dl.insert(0, i);
dl.insert(0, 5);
}
for(int i = 0; i<dl.length(); i++) // O(n^2)
{
cout << dl.get(i) << endl;
}
for(dl.move(0); !dl.end(); dl.next()) // O(n)
{
cout << dl.current() << endl;
}
cout << "begin" << endl;
for(dl.move(dl.length()-1); !dl.end(); dl.pre()) // O(n)
{
cout << dl.current() << endl;
}
// 删除5数据元素
dl.move(dl.length()-1);
while(!dl.end())
{
if(dl.current() == 5)
{
cout << dl.current() << endl;
dl.remove(dl.find(dl.current()));
}
else
{
dl.pre();
}
}
cout << "end" << endl;
for(dl.move(dl.length()-1); !dl.end(); dl.pre()) // O(n)
{
cout << dl.current() << endl;
}
return 0;
}
小结
双向链表是为了弥补单链表的缺陷而重新设计的
在概念上,双向链表不是单链表,没有继承关系
双向链表中的游标能够直接访问当前结点的前驱和后继
双向链表是线性表概念的最终实现(更贴近理论上的线性表)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号