反射式跨站黑白盒测试
黑盒测试
- 查找API的输入、输出点,按照正常输入规则使用,观察响应及GET/POST等http请求消息。
1.1 GET和POST方法、URL参数、HTTP请求头、Body参数、带外通道、文件上传下载都要考虑
2.2 注意应用程序是否将Referer[附1]、User-Agent[附1]消息头复制到错误消息页面,也可能存在漏洞
3.3 有表单(form)的页面、错误页面(404, 500等)如果将用户指定的URL Path写入响应页面,也可能存在XSS漏洞,URL Path也是个输入点。
- 根据上下文语法构造嵌入脚本代码
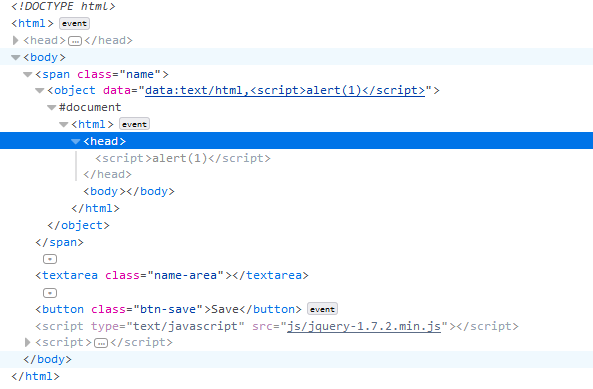
1.1 脚本标签[^附3] <script>alert(1)</script> <object data="data:text/html,<script>alert(1)</script>">
2.2 事件处理器 <img src=none.gif onerror=alert(1)>
3.3 脚本伪协议 <iframe src=javascript:alert(1)>
4.4 动态求值表达式 <x style=x:expression(alert(1))>
- 探查应用程序的防御逻辑,主要分为3种:过滤、净化、长度限制
1.1 过滤[^附4](主要检查对哪些字符进行过滤,然后再尝试用多层编码、空字节、非标准语法等绕过)确定服务器对哪些字段/表达式进行了过滤。如对<script>标签进行了过滤,可尝试将<scrpit>改成<ScRipt>或加入空格的方式、对<scrpit>alert(1)</script>进行编码后再输入或通过事件处理器与标签结合使用<img onerror=alert(1) src=a>来绕过。当对事件处理器方式也可能存在过滤:可通过改变字符大小写<iMG onerror=alert(1) src=a>、在任意位置插入NULL字节<[%00]i[%00]MG onerror=alert(1) src=a>.如对特定标签名称有过滤,可改成<x onclick=alert(1) src=a>Click here</x>。当对标签括号进行过滤时可尝试使用 %3cimg onerror=alert(1) src=a%3e
2.2 净化(如将<变成<)首先确定对哪些字符或表达式进行了净化,再尝试绕过(与过滤方法类似)。当只有使用已被净化的输入才能实施攻击时,则检查净化过滤的效率。如净化过滤可能仅替换第一个匹配的表达式(如<script>,则可尝试使用<script><script>alert(1)</script>或<scr<script>ipt>alert(1)</script> 当对引号字符前插入反斜线字符时。如 var a ='foo';可输入foo';alert(1);来绕过。当反斜线字符被正确转义,但尖括号没有净化时,可使用</script><script>alert(1)</script>。当脚本位于事件处理程序内时,可对引号进行HTML编码来避开对引号或其他字符的净化。如将foo值位于:<a href="#" onclick="var a ='foo';.....且应用程序正确转义输入中的引号及反斜线,则可输入foo';alert(1);//来实施攻击。这是利用某些浏览器在将事件处理程序作为 javascript执行前会执行HTML解码。<a href="#" onclick="var a='foo';alert(1);//'
3.3 长度限制
a) 使用最短可能的攻击脚本
b) 将攻击有效负载分布到不同的位置上
c) 将一个反射型XSS漏洞转换成基于DOM的漏洞<script>eval(location.hash.slice(1))</script>
白盒测试
-
参考黑盒测试查找系统的所有输入、输出点
-
找到相关的源码,进行过滤分析。针对具体功能限制参数的长度与字符白名单,输入数据先做归一化,确认空字节是否干扰校验逻辑
附
[1] Referer
Referer提供了引导用户代理到当前页的前一页的地址信息(当前的请求是从哪里链接过来的)
- 我们
google搜索mdn,并点击搜索到的第一条结果
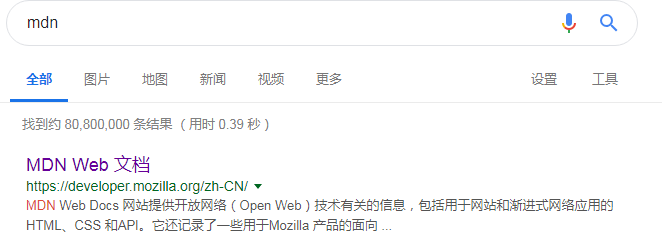
我们可以在看到我们当前请求的页面url是https://developer.mozilla.org/zh-CN/
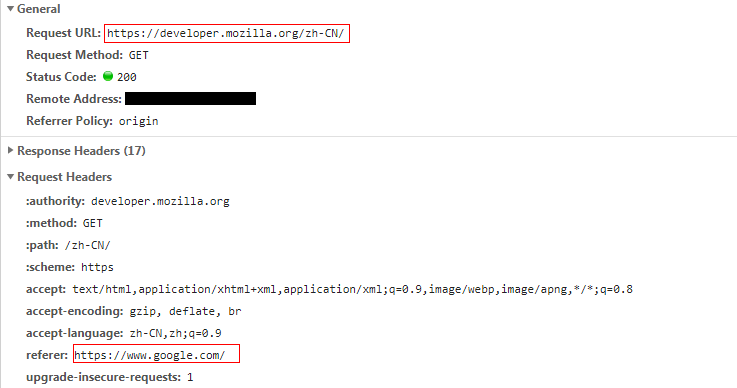
referer是https://www.google.com/表明我们是从google搜索页跳转过来的。
- 当我们直接在地址栏 输入资源url的时候,由于是
凭空产生的请求。并不是某个地方的链接过来的,所以Referer为空。
Referer的用途
Referer常被用来用作防盗链,如只允许自己的站点访问自己的图片服务器。图片服务器收到的每次请求都判断一下Referer是不是自己站点的域名。
[2] User-Agent
用户代理,用来向服务器提供所使用的浏览器类型及版本、操作系统及版本、浏览器内核、等信息的标识。
user-agent: Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36
[3] 注入脚本标签
示例:
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title></title>
</head>
<body>
<span class="name"></span>
<textarea class="name-area"></textarea>
<button class="btn-save">Save</button>
</body>
<script type="text/javascript" src="js/jquery-1.7.2.min.js"></script>
<script>
$(function() {
$(".btn-save").on("click", function() {
var val = $(".name-area").val();
$(".name").html(val);
});
});
</script>
</html>
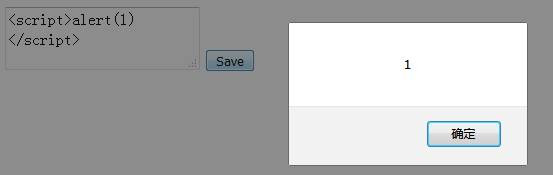
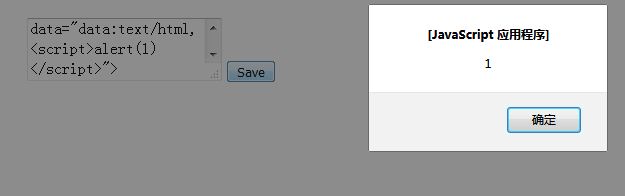
[4] 服务器过滤工具类
import java.net.URLEncoder;
public class EncodeFilter {
//过滤大部分html字符
public static String encode(String input) {
if (input == null) {
return input;
}
StringBuilder sb = new StringBuilder(input.length());
for (int i = 0, c = input.length(); i < c; i++) {
char ch = input.charAt(i);
switch (ch) {
case '&': sb.append("&");
break;
case '<': sb.append("<");
break;
case '>': sb.append(">");
break;
case '"': sb.append(""");
break;
case '\'': sb.append("'");
break;
case '/': sb.append("/");
break;
default: sb.append(ch);
}
}
return sb.toString();
}
//js端过滤
public static String encodeForJS(String input) {
if (input == null) {
return input;
}
StringBuilder sb = new StringBuilder(input.length());
for (int i = 0, c = input.length(); i < c; i++) {
char ch = input.charAt(i);
// do not encode alphanumeric characters and ',' '.' '_'
if (ch >= 'a' && ch <= 'z' || ch >= 'A' && ch <= 'Z' ||
ch >= '0' && ch <= '9' ||
ch == ',' || ch == '.' || ch == '_') {
sb.append(ch);
} else {
String temp = Integer.toHexString(ch);
// encode up to 256 with \\xHH
if (ch < 256) {
sb.append('\\').append('x');
if (temp.length() == 1) {
sb.append('0');
}
sb.append(temp.toLowerCase());
// otherwise encode with \\uHHHH
} else {
sb.append('\\').append('u');
for (int j = 0, d = 4 - temp.length(); j < d; j ++) {
sb.append('0');
}
sb.append(temp.toUpperCase());
}
}
}
return sb.toString();
}
/**
* css非法字符过滤
* http://www.w3.org/TR/CSS21/syndata.html#escaped-characters
*/
public static String encodeForCSS(String input) {
if (input == null) {
return input;
}
StringBuilder sb = new StringBuilder(input.length());
for (int i = 0, c = input.length(); i < c; i++) {
char ch = input.charAt(i);
// check for alphanumeric characters
if (ch >= 'a' && ch <= 'z' || ch >= 'A' && ch <= 'Z' ||
ch >= '0' && ch <= '9') {
sb.append(ch);
} else {
// return the hex and end in whitespace to terminate
sb.append('\\').append(Integer.toHexString(ch)).append(' ');
}
}
return sb.toString();
}
/**
* URL参数编码
* http://en.wikipedia.org/wiki/Percent-encoding
*/
public static String encodeURIComponent(String input) {
return encodeURIComponent(input, "utf-8");
}
public static String encodeURIComponent(String input, String encoding) {
if (input == null) {
return input;
}
String result;
try {
result = URLEncoder.encode(input, encoding);
} catch (Exception e) {
result = "";
}
return result;
}
public static boolean isValidURL(String input) {
if (input == null || input.length() < 8) {
return false;
}
char ch0 = input.charAt(0);
if (ch0 == 'h') {
if (input.charAt(1) == 't' &&
input.charAt(2) == 't' &&
input.charAt(3) == 'p') {
char ch4 = input.charAt(4);
if (ch4 == ':') {
if (input.charAt(5) == '/' &&
input.charAt(6) == '/') {
return isValidURLChar(input, 7);
} else {
return false;
}
} else if (ch4 == 's') {
if (input.charAt(5) == ':' &&
input.charAt(6) == '/' &&
input.charAt(7) == '/') {
return isValidURLChar(input, 8);
} else {
return false;
}
} else {
return false;
}
} else {
return false;
}
} else if (ch0 == 'f') {
if( input.charAt(1) == 't' &&
input.charAt(2) == 'p' &&
input.charAt(3) == ':' &&
input.charAt(4) == '/' &&
input.charAt(5) == '/') {
return isValidURLChar(input, 6);
} else {
return false;
}
}
return false;
}
static boolean isValidURLChar(String url, int start) {
for (int i = start, c = url.length(); i < c; i ++) {
char ch = url.charAt(i);
if (ch == '"' || ch == '\'') {
return false;
}
}
return true;
}
}
