
python学习之-爬虫案例
python学习之-爬虫案例
一、用爬虫去网站上爬取自己想要的数据,一般都需要我们自己去分析寻找这个网站的规律,而对于一些比较简单的网站,用以下方法步骤基本是可以达到我们想要的效果:
【浏览器打开目标网站】-->【右键查看网页源代码】-->【提取关键有规律的下一层数据链接】-->【提取关键有规律的下一层数据链接】-->【层层深入】-->【直到到达想要数据页面】-->【匹配提取数据或使用数据链接下载内容】
以下以mm.taobao.com为例:
1.首先我们要明确自己的目标,要爬取的最终数据,以下链接为例,我最终要拿到的是这个网站的所有图片。
https://mm.taobao.com/search_tstar_model.htm
2.打开我们想要爬取数据的网站,如,我们看到这些:
https://mm.taobao.com/search_tstar_model.htm

3.我们可以看到这些分类及人物列表,那么我们现在就有两个方向可选择:(1)分类 (2)人物列表 【此处使用2方向】
4.那我们继续深入,一层一层的找到自己想要的数据,点击一个人物进入她的页面,可以看到有一个【相册】按钮
https://mm.taobao.com/self/aiShow.htm?spm=719.7763510.1998643336.107.NYjC1U&userId=362438816
5.点击【相册】按钮,得到相册分类列表
https://mm.taobao.com/self/model_album.htm?spm=719.7800510.a312r.17.mlovUF&user_id=362438816
6.再点击其中一个【分类列表】,得到照片排列地址
https://mm.taobao.com/self/album_photo.htm?spm=719.6642053.0.0.Q7NZSL&user_id=362438816&album_id=10001048511&album_flag=0
7.这个时候一般就可以查看源代码,把需要数据的链接地址用正则匹配出来就可以了,但是这个网站是异步加载的,所以你看源代码不会得到你想要的数据信息【是不是很崩溃,干了这么多,瞎搞】
8.但是经过一轮的操作,我们可以明确的知道链接是以user_id为根据进行跳转的,我们便可以着手从user_id下手。
9.我们可以先找到所有模特的user_id,再根据user_id找到她的相册ID,最后通过user_id和相册ID找到图片完整地址
二、那么问题来了,我们怎么去找模特的user_id呢?
1.回到首页【https://mm.taobao.com/search_tstar_model.htm】,F12检查网页元素,F5刷新,会意外发现这么一堆东西json,我的最爱啊【这时你惊讶的发出了尖叫】
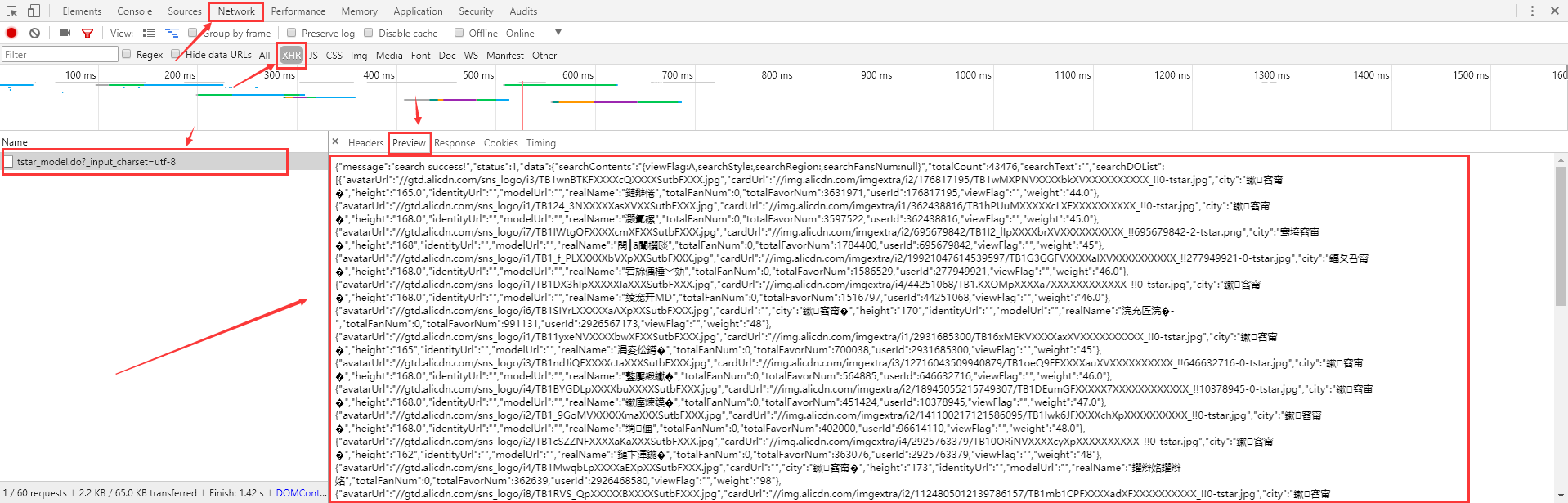
2.让后右键拷贝链接到新窗口打开,得到一堆东西

3.把这堆东西拷贝到json.cn网站,就一目了然了,得到了模特的一堆信息:user_id 和 名字 等
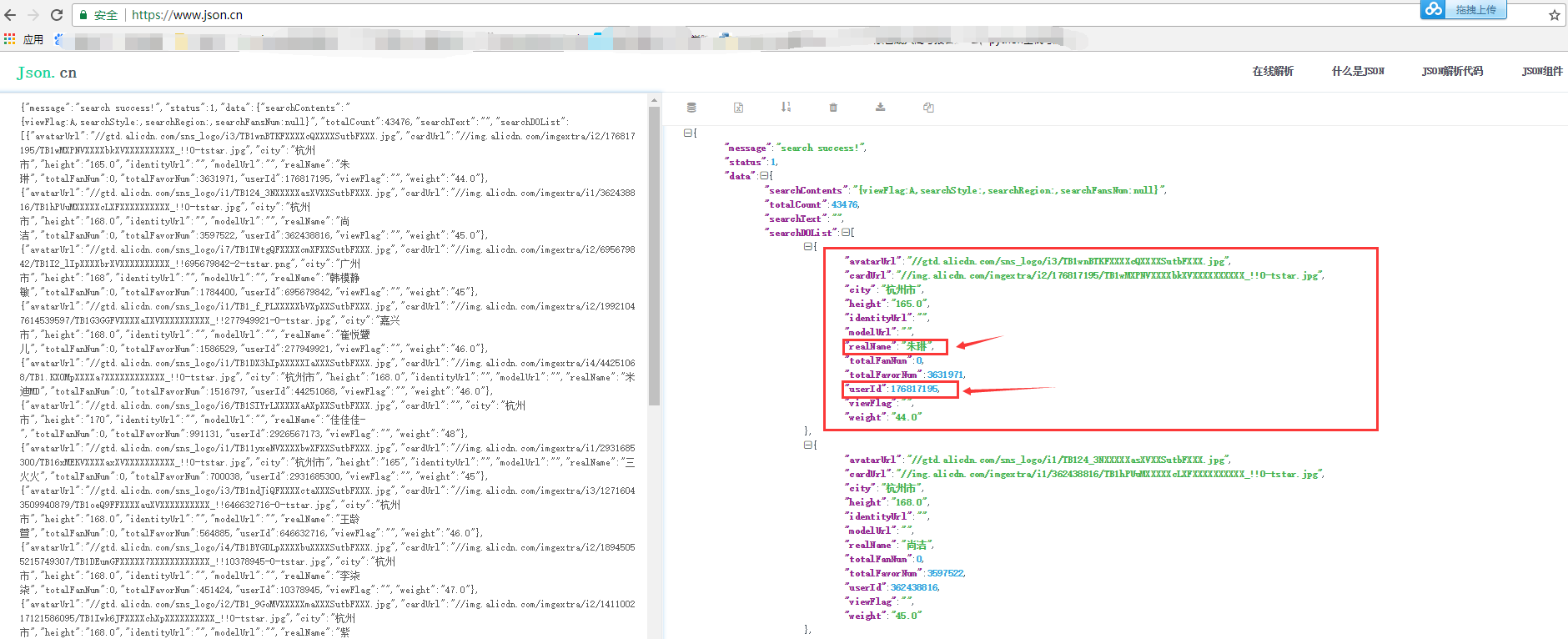
4.这个时候就先可以撸一段代码来获取对应的数据了【当时的我,鸡冻的一笔】
#!/usr/bin/env python # _*_ coding: utf-8 _*_ # author:chenjianwen # version: python3.5 import urllib.request import json heads = { ##定义请求头文件 'user-agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36' } def GetPerionInfo(): ##定义获取人物信息 req = urllib.request.Request('https://mm.taobao.com/tstar/search/tstar_model.do?_input_charset=utf-8',headers=heads) ##请求访问链接 html = urllib.request.urlopen(req).read().decode('gbk') ##读取链接内容 html = json.loads(html) ##把得到内容转换成json格式,方便后面数据提取 return html['data']['searchDOList'] ##返回每个人物的信息字典 for i in GetPerionInfo(): print(i)
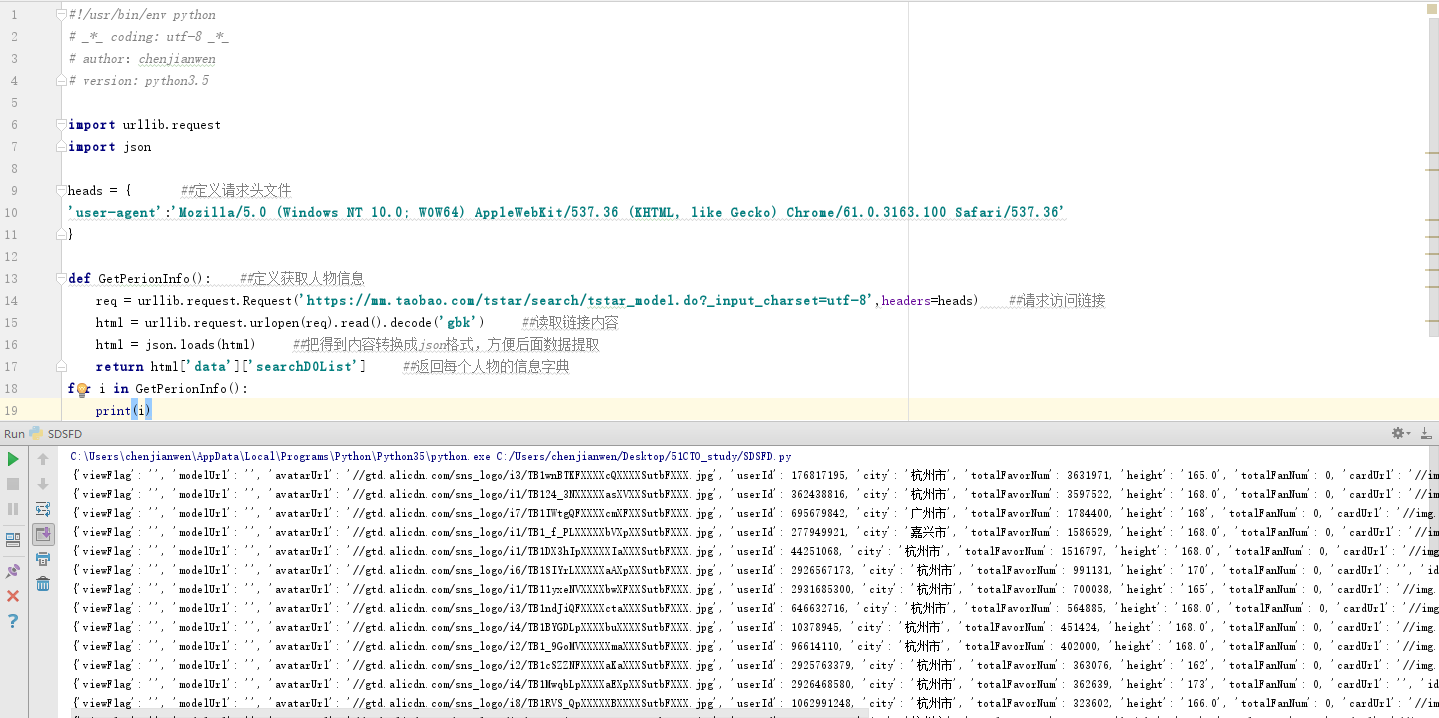
5.上面我们就拿到了人物的userId和realName,那么我们就可以直接杀进他们的相册地址了,得到相册地址:
https://mm.taobao.com/self/album/open_album_list.htm?_charset=utf-8&user_id%20=646632716
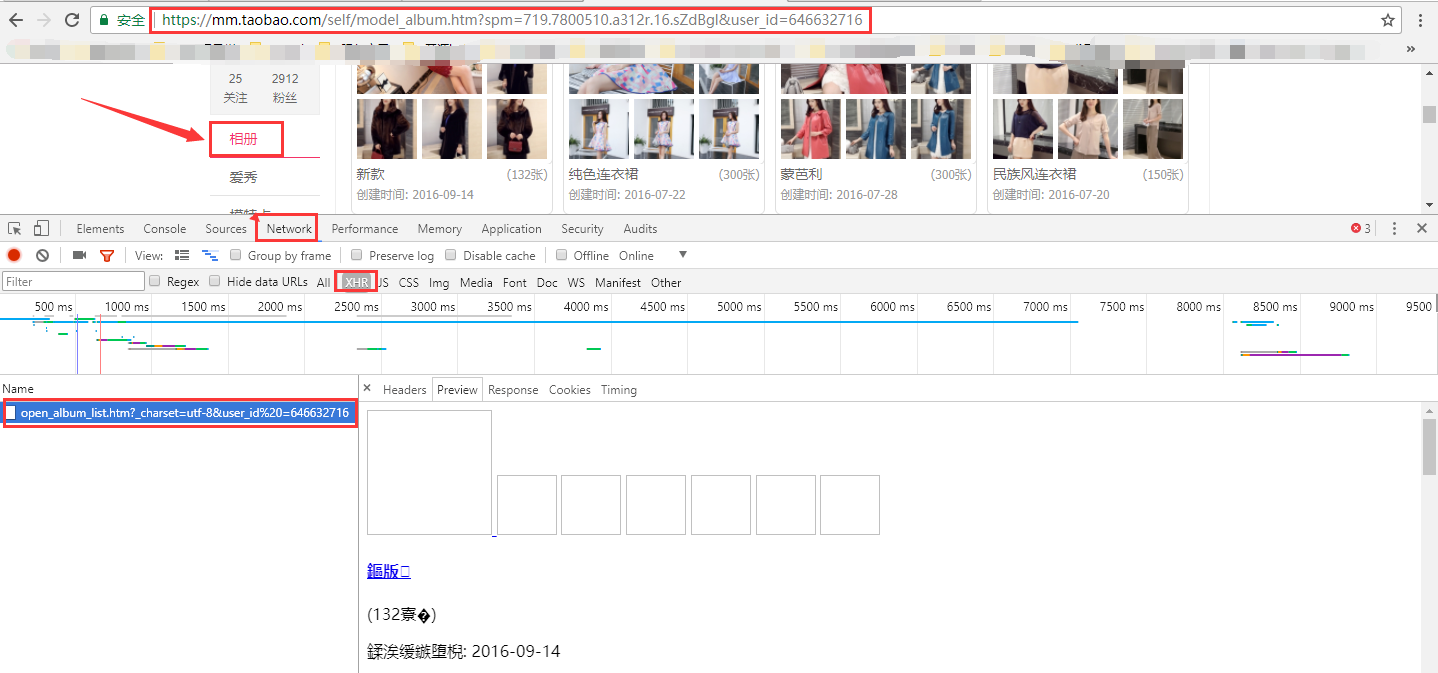
6.打开相册地址,右键查看网页源代码,此时我们会看到相册名字的标签 https://mm.taobao.com/self/album/open_album_list.htm?_charset=utf-8&user_id%20=646632716

那么我们就可以使用正则去匹配相册的名字和相册ID了,请参考以下代码:
#!/usr/bin/env python # _*_ coding: utf-8 _*_ # author:chenjianwen # version: python3.5 import urllib.request import json import re heads = { ##定义请求头文件 'user-agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36' } def GetPerionInfo(): ##定义获取人物信息 req = urllib.request.Request('https://mm.taobao.com/tstar/search/tstar_model.do?_input_charset=utf-8',headers=heads) ##请求访问链接 html = urllib.request.urlopen(req).read().decode('gbk') ##读取链接内容 html = json.loads(html) ##把得到内容转换成json格式,方便后面数据提取 return html['data']['searchDOList'] ##返回每个人物的信息字典 def GetAlbumInfo(userId): req = urllib.request.Request('https://mm.taobao.com/self/album/open_album_list.htm?_charset=utf-8&user_id%20={}'.format(userId),headers=heads) html = urllib.request.urlopen(req).read().decode('gbk') return re.findall(r'<h4><a href="(.*?)" target="_blank">(.*?)</a></h4>', html, re.S) ##匹配多行内容,匹配人物相册的链接及名字 if __name__ == '__main__': for PerionInfo in GetPerionInfo(): name = PerionInfo['realName'] userId = PerionInfo['userId'] for AlbumInfo in GetAlbumInfo(userId): AlbumUrl = AlbumInfo[0] albumName = AlbumInfo[1].split(' ')[-1] ##以空格分割截取最后一个字符串,以点号分割取第一个字符串,.split(' ')[-1].split('.')[0] 截取两次,这里不能这么干 ##开始提取相册ID # print albumUrl tmp_index = AlbumUrl.find('album_id=') # 查找唯一的一个值 start_index = tmp_index + len('album_id=') # 定义切片起始位置 end_index = AlbumUrl.find('&', start_index) # 定义切片结束位置 albumID = AlbumUrl[start_index:end_index] # 切片【起始位置:结束位置】 print(name,userId,albumName,albumID) break
结果得到:人物名字 人物ID 相册名字 相册ID
7.这个时候,是时候找开始找图片的源地址了【给位看官是不是激动了呢】点击其中一个相册列表进去:https://mm.taobao.com/self/album_photo.htm?user_id=176817195&album_id=10000020885&album_flag=0 可以看到很多图片,再点开图片就是大图了

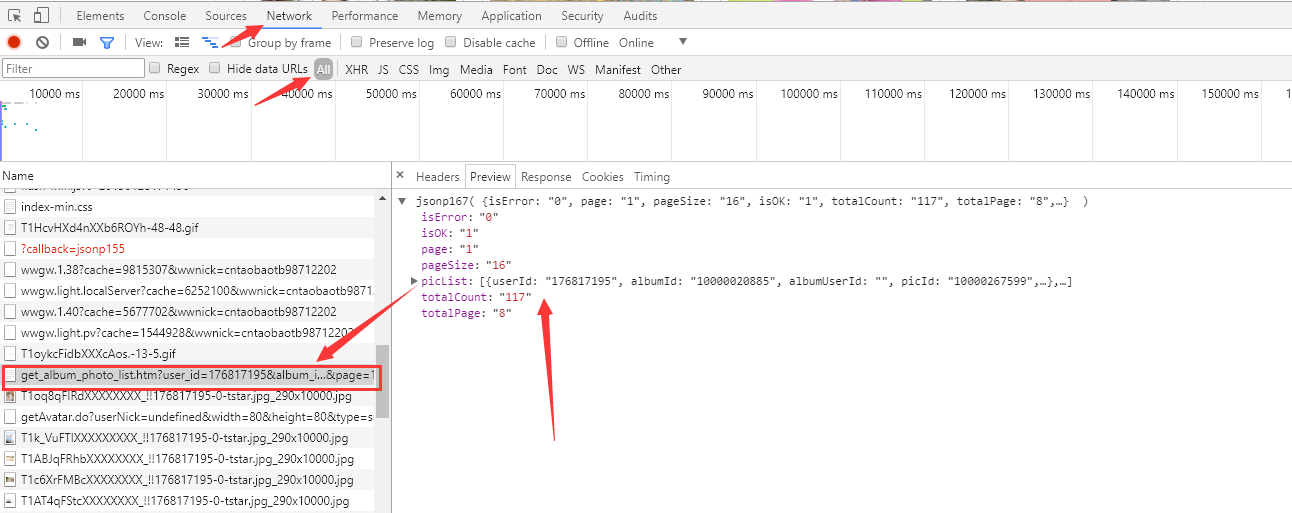
右键复制地址看看,又是一个json
https://mm.taobao.com/album/json/get_album_photo_list.htm?user_id=176817195&album_id=10000020885&top_pic_id=0&cover=%2F%2Fimg.alicdn.com%2Fimgextra%2Fi2%2F176817195%2FT1u3BtFMpXXXXXXXXX_!!176817195-0-tstar.jpg&page=1&_ksTS=1510295447115_166&callback=jsonp167
在这呢
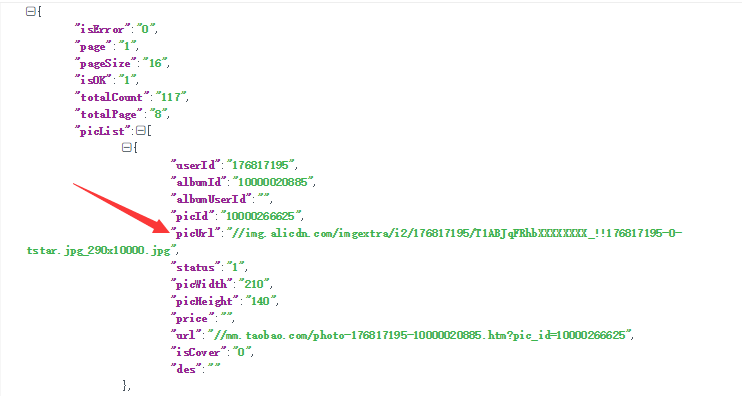
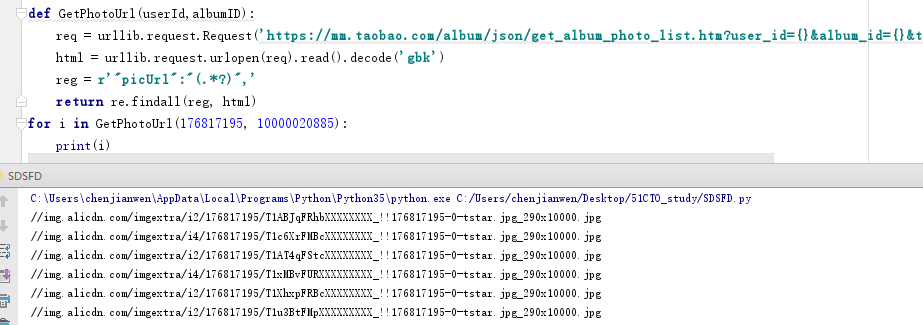
行吧,又可以撸代码了:
def GetPhotoUrl(userId,albumID): req = urllib.request.Request('https://mm.taobao.com/album/json/get_album_photo_list.htm?user_id={}&album_id={}&top_pic_id=0&cover=%2F%2Fimg.alicdn.com%2Fimgextra%2Fi2%2F176817195%2FT1u3BtFMpXXXXXXXXX_!!176817195-0-tstar.jpg&page=1&_ksTS=1510295447115_166&callback=jsonp167'.format(userId,albumID),headers=heads) html = urllib.request.urlopen(req).read().decode('gbk') reg = r'"picUrl":"(.*?)",' return re.findall(reg, html) for i in GetPhotoUrl(176817195, 10000020885): print(i)
结果如下:
试试复制打开一个链接看看//img.alicdn.com/imgextra/i2/176817195/TB1FTD9HXXXXXaQaFXXXXXXXXXX_!!176817195-0-tstar.jpg_290x10000.jpg
你会发现,马蛋,居然是小图,啊...........
不着急,要不你再试试这个://img.alicdn.com/imgextra/i2/176817195/TB1FTD9HXXXXXaQaFXXXXXXXXXX_!!176817195-0-tstar.jpg,你懂的·····~~~~~~~~~~~~~~
8.基本上就这样就完了,python3下载方法我提供一下,python2的就不赘述了:
def auto_down(realpicurl,downloaddir): #参数:图片地址,路径 try: urllib.request.urlretrieve(realpicurl,downloaddir) except urllib.request.ContentTooShortError: ##异常处理语句 print('Network conditions is not good.Reloading.') auto_down(realpicurl,downloaddir) #若没下载成功,则重新下载
9.为了给位能更快速的爬取所有内容,特别为大伙准备了多线程操作~~~~~~~~~,如下,请笑纳:
if __name__ == '__main__': start_time = time.time() for nu in number: thread_number = threading.active_count() if thread_number > 5: ##控制线程最大数量 time.sleep(5) ##大于控制线程最大数量则等待5秒后继续执行 continue else: name = nu['name'] #这个是我将人物名字和userId生成一个字典,方便在多线程中提取的 userId = nu['userId'] #albumID在Action()函数中得到 t = threading.Thread(target=Action,args=(name,userId)) t.start() t.join() print('All task done.') end_time = time.time() print('ALL RUN %0.2f seconds..' %(end_time - start_time))
10.你们在说什么呢
我:哈哈哈,终于写完了!爽,我要去潇洒了~~~~~~
吃瓜群众:你不许走,要是走我就哭了
我:哎哎,怎么啦?别瞎搞啊~~~~~~
吃瓜群众:好像还没完呀,多页怎么爬呀,我要把所有mm带回家~~~~
我:我靠,真贪心,真是想累死我啊~~~~~
吃瓜群众:呜呜呜呜~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
我:摸着吃瓜群众的头,乖,请持续关注下回分解~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
此时:哭声连连,震耳欲聋,耳膜疼痛,我转过身赶紧离开了这危险之地,免得招惹杀身之祸....................................................................................................
一些事情一直在干,说不定以后就结果了呢
本文来自博客园,作者:chenjianwen,转载请注明原文链接:https://www.cnblogs.com/chenjw-note/articles/7811449.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号