python tesseract图片识别
1. 下载Tesseract-OCR,下载地址为:tesseract下载地址 https://digi.bib.uni-mannheim.de/tesseract/ ,下载之后下一步下一步傻瓜式安装即可。随后将其添加到环境变量。在环境变量和系统变量的path中添加;D:\tesseract\Tesseract-OCR(tesseract的安装目录)。在cmd命令中执行tesseract -v,若出现以下页面,便是成功了。
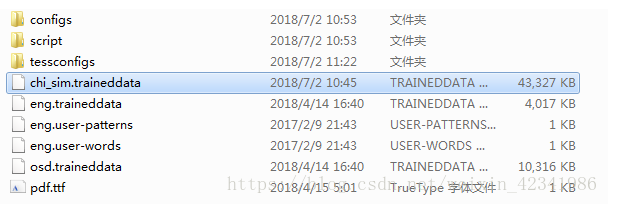
2. 下载简体字识别包,地址为: https://github.com/tesseract-ocr/tessdata,下载chi_sim.traineddata即可,如果需要识别其他字体,也可以下载相应字体。下载好的字体放入Tesseract-OCR\tessdata文件夹下。图为:
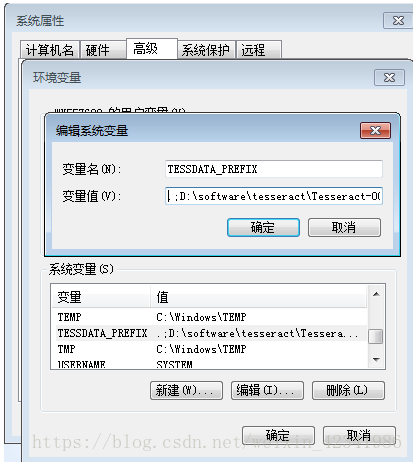
3. 在系统变量中新建一个配置信息,命名为:TESSDATA_PREFIX,变量值为安装路径D:Tesseract-OCR
4. 安装tesseract,cmd输入'pip install pytesseract'
5. 安装pillow, cmd输入'pip install Pillow'
6. 修改tesseract_cmd,打开D:\Python\Lib\site-packages\pytesseract中的pytesseract.py文件,ctrl+f搜索tesseract_cmd,将其改为简体中文包所在文件目录。'D:/tesseract/Tesseract-OCR/tesseract'。

7.代码测试

原文链接:https://blog.csdn.net/weixin_42341986/article/details/80882413

 浙公网安备 33010602011771号
浙公网安备 33010602011771号