

提高索引服务性能
访问某些与[CIndex]表和[CTag]表相关的存储过程时出现严重堵塞,导致数据库服务器的磁盘性能长期高居不下,使得索引服务无法正常运行,其中以temp_GetTCBTag最为严重。以下分析、测试及解决方案均以此存储过程为例。
二、问题分析。
1、 在大数据量检索中,性能的提高主要还是要设计合理的索引,所以此问题的分析还是需要从索引的合理性作为切入点。
2、 为了模拟出较为真实的大量访问场景,编写一个测试工具是必不可少,同时现行索引服务使用的是企业服务组件,为了减少不必要的潜在影响,测试工具需要使用原始的ADO.NET调用存储过程,并且真实输出访问数据。
3、 在测试分析中除了分析修改前后的运行时间外,分析每种查询的执行计划也是十分重要的,因为使用不同检索条件可能产生不同的执行计划。
4、 与存储过程有关的各表的数据级也是分析时的重要数据。
[CIndex] 652167
[CTag] 3923902
[ARanks] 68509
[Privilieges] 79
5、被测试的原始存储过程的编写(处理过)如下:
 ALTER PROCEDURE [dbo].[temp_GetTCBTag]( @clientid nvarchar(50), @tag nvarchar(200), @count int)ASBEGIN SET ROWCOUNT @count SELECT ci.[abc]
ALTER PROCEDURE [dbo].[temp_GetTCBTag]( @clientid nvarchar(50), @tag nvarchar(200), @count int)ASBEGIN SET ROWCOUNT @count SELECT ci.[abc]......
......
FROM dbo.[CIndex] ci INNER JOIN dbo.[ARanks] ar ON (ci.a = ar.a AND ci.cid = ar.cid) INNER JOIN dbo.[CTag] ct ON ct.ctid = ci.id WHERE ar.[rank] >= 0 AND ct.[tag] = @tag AND ci.[clientid] IN( SELECT [sid] FROM dbo.[Privilieges] where [cid = @clientid AND [cr] = 1) ORDER BY ci.[createtime] DESC SET ROWCOUNT 0END测试结果:
|
测试tag数量 |
执行时间 |
Avg. Disk Queue Length |
Processor Time |
|
9000条 |
168.564秒 |
1.973 |
6.875 |
|
9000条 |
221.551秒 |
2.012 |
7.002 |
|
9000条 |
205.672秒 |
1.994 |
6.954 |
|
|
198.596秒 |
1.993 |
6.944 |
(2)、Avg.Disk Queue Length 高居不下。
(3)、执行计划如下图所示。
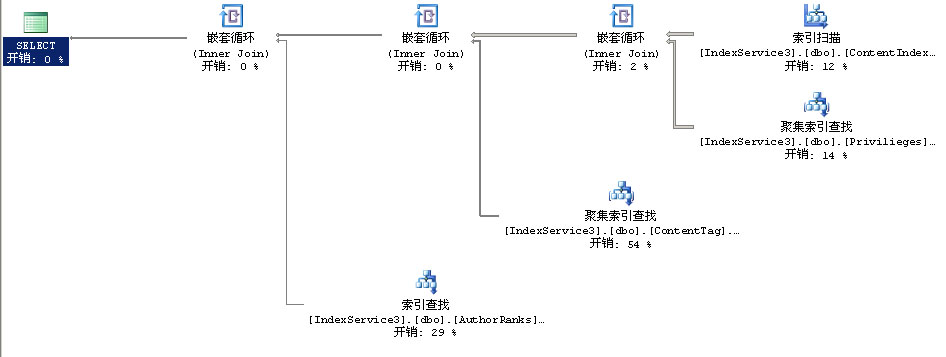
测试分析:检索某些标签出现堵塞现象,磁盘开销高居不下符合真实的生产环境中出现的性能问题的现象。由该执行计划可见对[ContentTag]表的索引查找占去了54%的开销,而该表的数量级接近400万,对于65万条记录的[ContentIndex]表也占有12%的开销,可见大部分的开销都是索引的检索引起的,所以从索引入手提高性能是必然的选择。
6、我们知道在过滤和排序中使用不同的条件可以改变执行计划,但是为了保证对于业务需求的满足不能随便改变过滤条件,但是可以改变排序的方式,因为[ContentIndex]表中带有自增长的id字段,它的排序应该和记录添加时间是一致的,所以我们可以改变为ORDER BY ci.[id] DESC 作进一步的测试。备注:id与createtime都建有索引
7、新存储过程的测试如下:
测试结果:
|
测试tag数量 |
执行时间 |
Avg. Disk Queue Length |
Processor Time |
|
9000条 |
14.094秒 |
0.001 |
2.882 |
|
9000条 |
13.813秒 |
0.003 |
4.926 |
|
9000条 |
13.656秒 |
0.003 |
4.883 |
|
|
13.854秒 |
0.002 |
4.230 |
(1)、执行时间得到大幅减少并且磁盘性能得到有效提高。
(2)、执行计划如下图:

由执行计划可见,因为改变了排序条件使得执行计划发生了改变,针对[ContentTag]表的索引查找开销降到了5%,针对[ContentIndex]表的索引查找为21%,合计也就26%,虽然[authorranks]表的索引查找涨到了51%,但是其记录数并不多,并且其中的一个嵌套联接改为了合并联接。http://book.csdn.net/bookfiles/121/
8、由上面的分析可见,性能的影响是由排序字段的选择不合理引起的,但是也不应该有如此之大的影响,所以分析了一个此两索引的索引碎片如下:
|
索引名称 |
碎片总计 |
页填充度 |
|
idx_cicreatetime |
96.36 % |
92.10 % |
|
idx_id |
0.05 % |
99.49 % |
|
测试tag数量 |
执行时间 |
Avg. Disk Queue Length |
Processor Time |
|
9000条 |
73.656秒 |
1.306 |
5.638 |
|
9000条 |
72.64秒 |
1.313 |
5.815 |
|
9000条 |
73.718秒 |
1.387 |
6.013 |
|
|
73.338秒 |
1.335 |
5.822 |
可见性能确实是得到了提高,但是相对于使用idx_id索引进行排序来说,还是有很大的差距,分析其中的原因是[id]字段的数据类型为int,而[idx_cicreatetime]为datetime,在索引查找中针对int的比较的开销要比使用datetime的开销要小,所以这里就体现了性能上的差异
三、解决方案及总结。
1、 定期分析索引的索引碎片,如果索引碎片过大则需要进行重建工作。
2、 使用不同的过滤条件和排序条件可以得到不一样的执行计划,分析选择更好的执行计划可以得到更好的性能。
3、 在相同的效果下,使用比效成本更低的字段则会得到更好的检索性能。

