低光图像增强论文 Kindling the Darkness: A Practical Low-light Image Enhancer 阅读笔记
文章概述
这篇文章来自 ACM MM 2019。本文建立了一个简单而有效的点燃黑暗(表示为 KinD)的网络,它受 Retinex 理论的启发,将原始图像分解为反射率和光照两个部分,其中光照负责光的调节,而反射率负责去除退化。通过这种方式,原始空间被解耦成两个较小的子空间,期望得到更好的学习。整个网络由两个组件组成,分别用于处理反射率和光照。从功能上看,还可以分为图层分解、反射率恢复、光照调节三个模块。其中层分解网络包含两个分支,分别对应于反射率和光照,反射率分支采用经典的5层 U-Net,之后是卷积层和 Sigmoid 层;光照分支由两个 conv+ReLU 层和一个 conv 组成,它们连接在来自反射率分支的特征图上,最后是一个 Sigmoid 层。
层分解网络利用 Retinex 理论,将输入图像分解为反射率和光照;光照调节网络可以通过参数 α 灵活调整亮度,输出调整后的光照分量;反射率恢复网络负责将之前分解网络得到的反射率分量和光照调节网络的输出结合,得到最终的增强图像。
网络使用 paired 数据集,输入两张曝光不同的同场景照片,但是并不是以正常曝光的照片作为 ground truth,而是以正常曝光照片的反射率分量作为 ground truth。根据 Retinex 理论,一张图片可以分成反射率分量和光照分量两部分,不同曝光的图片如果不考虑退化(噪声、颜色失真等),则两者的反射率分量应该相同,不同的是光照分量,所以作者使用正常曝光图片的反射率分量作为 ground truth。
同时,作者在不同的网络部分中,使用了不同的组合的 loss,如 MSE loss、SSIM loss 等。实验证明,论文的结果在视觉上和定性定量的实验上,都取得了 SOTA 的效果。
项目地址:https://github.com/zhangyhuaee/KinD。
一、摘要
在弱光条件下拍摄的图像通常(部分)能见度较差。除了不满意的光线,多种类型的退化,如噪音和颜色失真,由于相机的质量有限,这些退化隐藏在黑暗中。换句话说,仅仅提高黑暗区域的亮度将不可避免地放大隐藏的退化。这项工作建立了一个简单而有效的点燃黑暗(表示为 KinD)的网络,它受 Retinex 理论的启发,将图像分解为两个组件。一个组件(光照)负责光的调节,而另一个组件(反射率)负责去除退化。通过这种方式,原始空间被解耦成两个更小的子空间,期望得到更好的正则化/学习。值得注意的是,我们的网络是通过在不同曝光条件下拍摄的成对图像进行训练的,而不是使用任何地面实况反射率和光照信息。我们进行了大量的实验来证明我们的设计的有效性和它优于最先进的技术。我们的产品可以抵抗严重的视觉缺陷,并且用户可以任意调节光线的亮度。此外,我们的模型在 2080Ti GPU 上处理 VGA 分辨率的图像花费不到 50ms。以上优点使我们的产品具有实用价值。
二、引言
在昏暗的光线条件下捕捉高质量的图像一直都是一个挑战。虽然一些操作,如设置高 ISO,长曝光和闪光灯,可以适用于这种情况,但他们有不同的缺点。例如,高 ISO 增加了图像传感器对光的灵敏度,但噪声也会被放大,从而导致低信噪比。长时间曝光仅限于拍摄静态场景,否则很可能会遇到模糊的结果。使用闪光灯可以在某种程度上照亮环境,然而,这经常会给照片带来意想不到的光晕和光线不平衡问题,让照片看起来很不舒服。在实践中,因为拍照工具有限,普通用户甚至可能没有上述选项和有限的摄影工具,例如嵌入便携式设备中的相机。虽然在过去的几年里,低光图像增强一直是一个长期存在的问题,并取得了很大的进展,但开发一个实用的低光图像增强器仍然具有挑战性,因为如何灵活地照亮黑暗,有效地消除退化,以及如何提高效率都是需要考虑的问题。
基于深度学习的方法在去噪、超分辨率等数值底层视觉任务中表现优异,但其中大部分都需要训练数据包含 ground-truth。对于特定问题,比如低光图像增强,虽然可以确定光强的大小顺序,但是不存在 ground-truth 真实数据。因为,从用户的角度来看,不同的人/需求所喜欢的光照等级可能是多种多样的。换句话说,一个人不能说什么光的条件是最好的/最真实的。因此,仅将图像映射到具有特定光线水平的版本并不是很合适。
(1)低光图像增强面临的挑战
如何从单个图像中有效地估计出光照分量,并灵活地调整光照?
如何在照亮黑暗区域后去除之前隐藏在黑暗中的噪声和颜色失真等退化?
如何训练一个模型,在没有明确的 ground-truth 条件,只看两个/几个不同的例子情况下增强低光图像?
(2)主要贡献
受 Retinex 理论的启发,该网络将图像分解为反射率和光照两部分,将原空间解耦为两个较小的空间。
该网络使用在不同光/曝光条件下捕获的成对图像进行训练,而不是使用任何 ground-truth 反射率和光照信息。
我们设计的模型提供了一个映射功能,可以根据用户的不同需求灵活地调整光线的等级。
该网络还包括一个模块,能够有效地去除通过亮暗区域放大的视觉缺陷。
我们进行了大量的实验,以验证我们的设计的有效性和它的优越性,可以替代目前最先进的技术。
三、方法
一个理想的低光图像增强器应该能够有效地去除隐藏在黑暗中的退化,并灵活地调整光照/曝光条件。我们建立一个深层的网络,用 KinD 来表示,来达到这个目的。如图所示,网络由两个分支组成,分别用于处理反射率和光照。从功能上看,也可以分为图层分解、反射率恢复、光照调节三个模块。
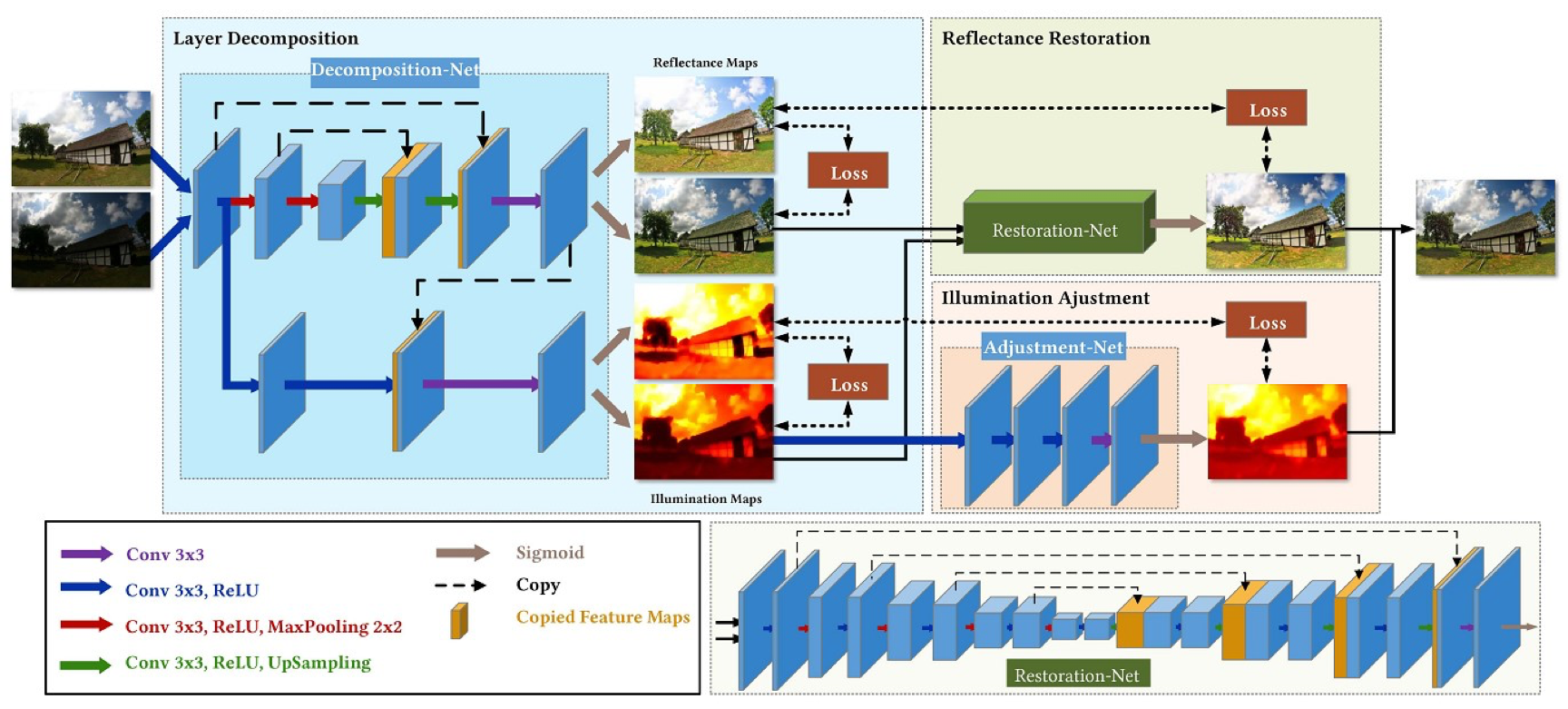
(1)层分解网络
在 Retinex 理论中,I=R ◦L,分解网络将原始输入图像 I 分解成反射分量 R 和光照分量 L,同时假定,在不考虑图片退化(噪声、颜色失真)情况下,相同场景下的不同曝光的图片的 R 应该相同,所以通过分解网络输出的 low reflectance 作为恢复网络的输入,用来生成增强图片,而 high reflectance 用作 ground-truth,有监督地同恢复网络的输出图片计算 loss。
分解网络包含两个分支,分别对应反射率和光照。反射率分支采用典型的5层 U-Net,之后是一个 conv 层和一个 Sigmoid 层。光照分支是由两个 conv+ReLU 层和一个 conv 层组成,它们连接在来自反射率分支的特征图上,最后是一个 Sigmoid 层。
其总 loss 为:

reflectance similarity loss:是 low/high reflectance maps 保持一致
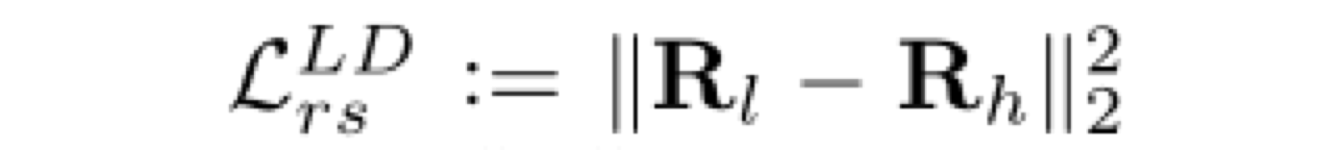
illumination smoothness loss:对于 I 中边缘,L 的惩罚很小;而对于 I 中 smooth 的位置,惩罚变得很大
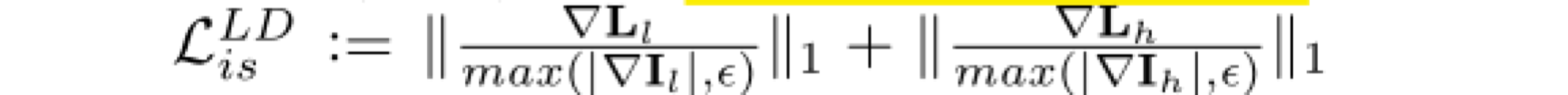
mutual consistency
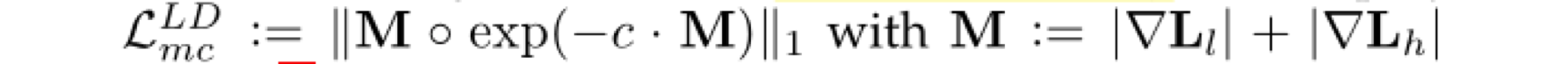
reconstruction error loss

(2)反射率恢复网络
低光图像的反射率分量比正常图片的反射率分量要差很多,所以这里需要用正常图片的反射率分量作为监督,计算损失来约束,同时也需要光照分量提供指导,最终增强图片。
其损失为
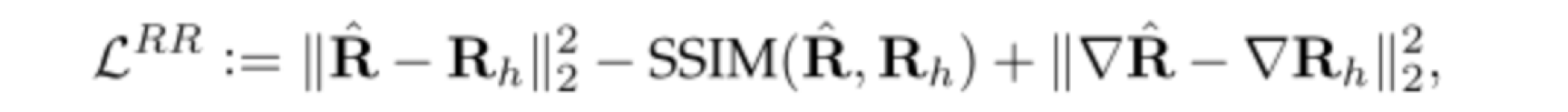
(3)光照调节网络
参数 α 用来调整 illumination maps 的亮度,通过(Lt / Ls)再算平均,得出。t 为 target,s 为 source;当 α> 1时,增亮,α 小于 1 时变暗。最关键的是,这里的参数 α 是可以自己设定的,即想要多亮就要多亮,非常灵活。同时不得不说的是,实际上 α 在网络中实际上是一张 feature map,加权到原有的 illumination maps 上。整个网络非常简单,3层 conv layers 还有一个 sigmoid layer 组成,loss 为


 浙公网安备 33010602011771号
浙公网安备 33010602011771号