Python3 + selenium 获取疫情中高风险区数据
- 背景: 需要动态将疫情风险区数据和区域业务动作想结合, 赋能销售业务, 内部使用非商用哈
- 环境: Python3 + selenium 自动化测试软件中 Chrome 驱动 exe 文件
- 输出: 以 excel 的方式输出到本地E盘文件和Mysql数据库
- 原理: 通过脚本模拟浏览器去点击页面, 通过定位元素位置进行提取
- 风险: 太频繁就会失败, 性能不强, 不够稳定
源代码如下
import time
import pandas as pd
from lxml import etree
from selenium.webdriver import Chrome, ChromeOptions
from sqlalchemy import create_engine
def get_tab_page_data (html_dom):
"""将tab下面的所有页面的数据获取以dataframe方式返回"""
need_click_pages = int(html_dom.xpath(PATH_DATA_PAGES)[0])
print(f'一共 {need_click_pages} 页哦: ')
# 遍历每个区, 提取标题和明细 取所有显示数据
area_data_list = []
for page_num in range(1, need_click_pages):
html_dom = etree.HTML(chrome.page_source)
div_list = html_dom.xpath(PATH_DATA_AREAS)
for div in div_list:
# 获取 标题-到区: [省, 市, 区]
risk_title = div.xpath(PATH_RISK_TITLE)
area_data_list.append(risk_title)
time.sleep(SECONDS)
chrome.find_element_by_id(PATH_NEXT_BUTTON).click()
print(f'正在帮 杰哥 获取 第 {page_num} 页 数据, 一共有 {need_click_pages} 页, 冲鸭!')
# 最后将所有区域数据拼接为一个大的 dataframe
return pd.DataFrame(area_data_list)
# main
# ##################### config #############################
# 点击延迟时间 (秒)
SECONDS = 3
BASE_URL = 'http://bmfw.www.gov.cn/yqfxdjcx/risk.html'
# xpah, 所需数据在页面中的定位
PATH_TIME_UPPDATE = '//p[@class="tabs-header-title"]/text()'
PATH_DATA_PAGES = '//button[7]/text()'
PATH_DATA_AREAS = '//div[@class="risk-info-table"]'
PATH_RISK_TITLE = './div[@class="risk-info-table-title"]//text()'
PATH_NEXT_BUTTON = 'nextPage'
PATH_RISK_MIDDLE = '//div[@class="tabs-header-tab"][1]'
# ##################### config #############################
strat_time = time.time()
print('目标网站是全国卫健委官网: ', BASE_URL)
print('实现方式是通过 selenium 这种测试软件去模拟浏览器行为, 需要安装 driver 的哈')
print('然后通过 xpath 的方式去定位需要的数据并作提取')
print('过程中会在页面刷新和点击的时候设置 sleep 以伪装得更像人为操作')
print('go go go !!!')
print()
print('正在初始化一个浏览器~')
opt = ChromeOptions()
opt.headless = True
chrome = Chrome(options=opt)
# chrome = Chrome()
print('浏览器初始化成功!')
print()
print('正在帮杰哥获取 高风险地区数据, 需要时间去骗过校验, 等待时间较长,请耐心哦~')
chrome.get(BASE_URL)
html_dom = etree.HTML(chrome.page_source)
df_risk_high = get_tab_page_data(html_dom)
print()
print('为保证数据质量, 我先进行浏览器刷新一遍并降低速度以免被识别出来是机器哦~')
print('ok, 现帮杰哥获取 中风险地区数据, 即点击切换顶部的 tab 块获取中风险的数据~')
chrome.find_element_by_xpath(PATH_RISK_MIDDLE).click()
time.sleep(SECONDS)
html_dom = etree.HTML(chrome.page_source)
df_risk_mid = get_tab_page_data(html_dom)
print()
print('正在帮 杰哥 做最后的数据清洗~')
# ##################### data processing #####################################
update_time_str = str(html_dom.xpath(PATH_TIME_UPPDATE))
update_time = update_time_str[4:17] + ":00"
df_risk_area = pd.concat([df_risk_high, df_risk_mid])
df_risk_area.columns = ['area', 'risk_level']
df_expand_col = df_risk_area['area'].str.split(' ', expand=True)
df_risk_area[['province', 'city', 'district']] = df_expand_col
# 单独处理北京的 "城市" 是 "区" 的问题
df_area_bj = df_risk_area[df_risk_area['province'] == '北京市']
tmp_district = df_area_bj['city'].copy(deep=True)
df_area_bj['city'] = df_area_bj['province']
df_area_bj['district'] = tmp_district
df_not_bj = df_risk_area[df_risk_area['province'] != '北京市']
df_ret = pd.concat([df_area_bj, df_not_bj])
df_ret.drop(labels=['area'], axis=1, inplace=True)
df_ret['update_time'] = update_time
df_ret.to_excel('E:/疫情中高风险区明细.xlsx', index=False)
# 同时也存一份到 mysql 数据库中, 以覆盖的方式
engine = create_engine('mysql+pymysql://PWD:USER@HOST:PORT/DATABASE?charset=utf8')
# 每次都删表重写, 只保留最新数据
df_ret.to_sql(con=engine, name="risk_area_covid", if_exists='replace')
pd.read_sql("select * from risk_area_covid", con=engine)
# ##################### data processing #####################################
end_time = time.time()
used_minutes = round((end_time - strat_time) / 60, 1)
chrome.quit()
print()
print('处理成功!, 数据已存储在 E盘 和 Mysql 数据库啦, 快去查看吧!')
print(f'累计耗时: {used_minutes} 分钟')
运行过程
目标网站是全国卫健委官网: http://bmfw.www.gov.cn/yqfxdjcx/risk.html
实现方式是通过 selenium 这种测试软件去模拟浏览器行为, 需要安装 driver 的哈
然后通过 xpath 的方式去定位需要的数据并作提取
过程中会在页面刷新和点击的时候设置 sleep 以伪装得更像人为操作
go go go !!!
正在初始化一个浏览器~
浏览器初始化成功!
正在帮杰哥获取 高风险地区数据, 需要时间去骗过校验, 等待时间较长,请耐心哦~
一共 8 页哦:
正在帮 杰哥 获取 第 1 页 数据, 一共有 8 页, 冲鸭!
正在帮 杰哥 获取 第 2 页 数据, 一共有 8 页, 冲鸭!
正在帮 杰哥 获取 第 3 页 数据, 一共有 8 页, 冲鸭!
正在帮 杰哥 获取 第 4 页 数据, 一共有 8 页, 冲鸭!
正在帮 杰哥 获取 第 5 页 数据, 一共有 8 页, 冲鸭!
正在帮 杰哥 获取 第 6 页 数据, 一共有 8 页, 冲鸭!
正在帮 杰哥 获取 第 7 页 数据, 一共有 8 页, 冲鸭!
为保证数据质量, 我先进行浏览器刷新一遍并降低速度以免被识别出来是机器哦~
ok, 现帮杰哥获取 中风险地区数据, 即点击切换顶部的 tab 块获取中风险的数据~
一共 11 页哦:
正在帮 杰哥 获取 第 1 页 数据, 一共有 11 页, 冲鸭!
正在帮 杰哥 获取 第 2 页 数据, 一共有 11 页, 冲鸭!
正在帮 杰哥 获取 第 3 页 数据, 一共有 11 页, 冲鸭!
正在帮 杰哥 获取 第 4 页 数据, 一共有 11 页, 冲鸭!
正在帮 杰哥 获取 第 5 页 数据, 一共有 11 页, 冲鸭!
正在帮 杰哥 获取 第 6 页 数据, 一共有 11 页, 冲鸭!
正在帮 杰哥 获取 第 7 页 数据, 一共有 11 页, 冲鸭!
正在帮 杰哥 获取 第 8 页 数据, 一共有 11 页, 冲鸭!
正在帮 杰哥 获取 第 9 页 数据, 一共有 11 页, 冲鸭!
正在帮 杰哥 获取 第 10 页 数据, 一共有 11 页, 冲鸭!
正在帮 杰哥 做最后的数据清洗~
处理成功!, 数据已存储在 E盘 和 Mysql 数据库啦, 快去查看吧!
累计耗时: 1.5 分钟
结果呈现
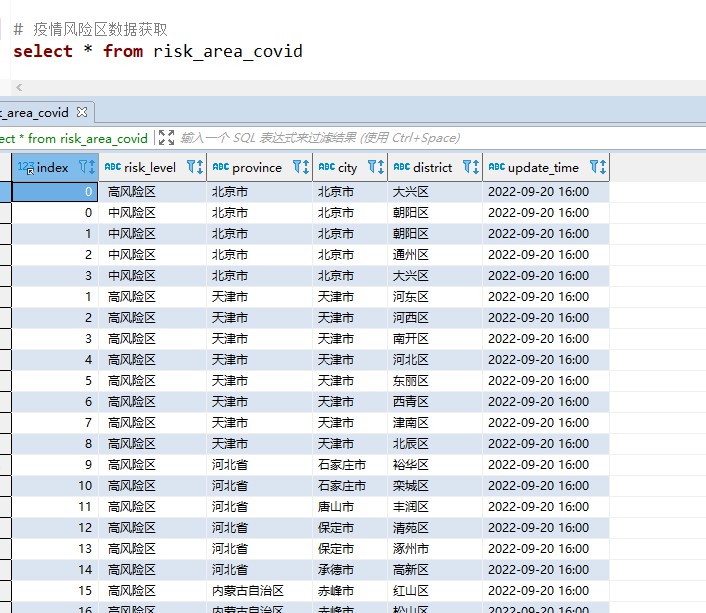
耐心和恒心, 总会获得回报的.



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通