SQL 优化 - 多层嵌套逻辑先行
近段时间就是忙得不亦乐乎, 一个人搞项目, 中途几经崩溃, 一个是业务方案有问题, 被带跑偏了整整一周, 最后尝试去挑战, 才重新回到正轨. 然后就是自己搞崩盘, sql 这块的处理, 嵌套写太深了, sql 有问题了, 各种查询不出来, 但也不报异常... 无奈之下, 只能全部重写, 果然吃了没有写大 sql 的亏, 这里就是想记录一把, 反例 sql , 引以为鉴. 就是各种嵌套, 然后可读性极差, 自己都维护不了那种.
因为涉及安全问题, 字段, 逻辑, 背景啥的都进行脱敏了, 截取了一段 sql 的匹配逻辑来说明这个问题.
需求
就是对一个前期处理好的表, 进行匹配其他维度信息, 然后又多个匹配表, 多次匹配, 且有顺序, 大致是这样的.
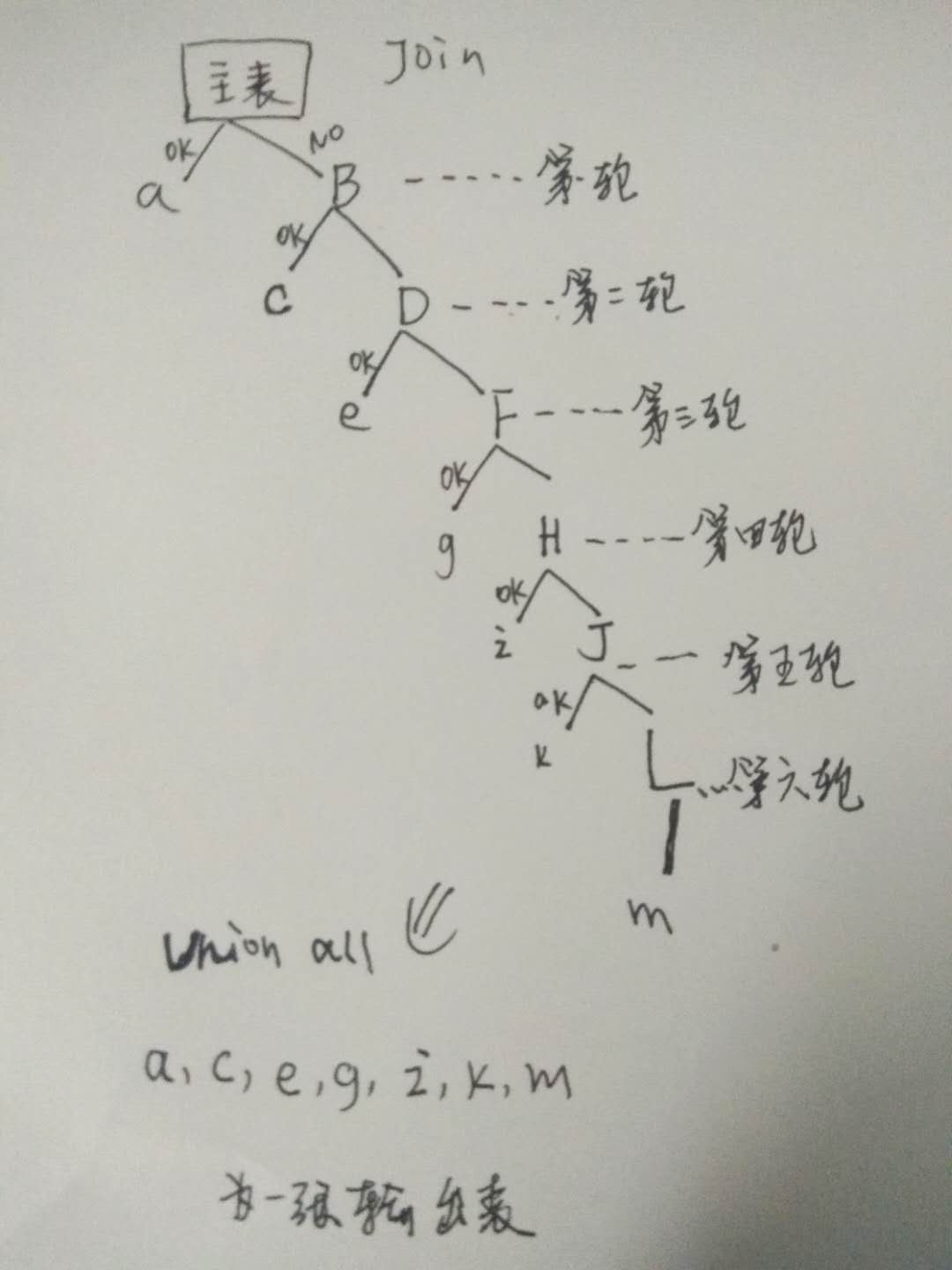
缺失的信息,要从我处理好的 6 个视图去做关联, 匹配出对应的字段信息, 当然, 条件是不同的, 有次序. 这在业务是会经常出现, 老是说, 先从这里找.. 找不到的再从另外找....这样几轮的匹配下去... 如图, 我还是简化了的, 就只有两种情况, 匹配上, 和没匹配上的情况, 这样不断查询.
优化前
真的是缺乏经验, 但是我又强大的逻辑, 就直接一个 大 sql 给拼了出来. 原理就是, 匹配上的, 即 inner join 嘛, 匹不上的就 做 left join 后, 再 where 出 右表为 null 的那些 左表的部分... 不断循环此过程. 最后, 将查询集存为物理表.
然后我就哐哐哐, 写了一段, 神仙一般的 反例sql, 有点 "惊为天人", 然后贻笑大方了.
------------ 优化前 ------------------------------------
-- 之前在列数据库写的套娃, 各种嵌套, 崩溃 IQ
-- 用一段代码逻辑, 将所有的结果拼接起来, 查询集存为一个物理表
select
*
into cj_main
from (
-- ------------------------------------------main----------------------------------
-- 查询集, 6 轮匹配, 不断 union all
-- 查询的表,都是一个个有逻辑的视图哦, 字段都用 '*', 所有字段都要, 简化书写
select
a.*,
b.*
-- 内连接第1个视图
from cj_tmp_main as a, cj_view_01 as b
where upper(a.pp_name + country) = upper(b.foo_key)
-- 第二轮匹配, 基于第一轮匹不上的
union all
select
c.*,
d.*
from (
select
a.*
from cj_tmp_main as a
left join cj_view_01 as b
on upper(a.pp_name + country) = upper(b.foo_key)
where b.foo_key is null
) as c
-- 内连接第2个视图
, cj_view_02 as d
where upper(c.ppp_name + country) = upper(d.foo_key)
union all
-- 第三轮匹配, 基于前两轮
select
e.*,
f.*
from (
select
c.*,
d.*
from (
select
a.*
from cj_tmp_main as a
left join cj_view_01 as b
on upper(a.pp_name + country) = upper(b.foo_key)
where b.foo_key is null
) as c
-- 挑出没披上的
left join cj_view_02 as d
on upper(c.ppp_name + country) = upper(d.foo_key)
where d.foo_key is null
) as e
-- 内连接第3个视图
, cj_view_03 as f
where upper(e.pp_name + country) = upper(f.foo_key)
-- e 的 country 能 在 f 的 country, 值(aaa,bbbb,ccc) 中出现过哦, 没出现则索返回 0
and charindex(e.contry, f.country) != 0
and f.cj_flag = 'N'
union all
-- 第四轮匹配, 基于前三轮
select
g.*,
h.*
from (
select
e.*,
f.*
from (
select
c.*,
d.*
from (
select
a.*
from cj_tmp_main as a
left join cj_view_01 as b
on upper(a.pp_name + country) = upper(b.foo_key)
where b.foo_key is null
) as c
left join cj_view_02 as d
on upper(c.ppp_name + country) = upper(d.foo_key)
where d.foo_key is null
) as e
left join cj_view_03 as f
on upper(e.pp_name + country) = upper(f.foo_key)
and charindex(e.contry, f.country) != 0
and f.cj_flag = 'N'
where f.foo_key if null
) as g
-- 内连接第 4 个视图
, cj_view_04 as h
where upper(g.pp_key) = upper(h.foo_key)
union all
-- 第五轮匹配, 基于前4轮
select
i.*,
j.*
from (
select
g.*,
h.*
from (
select
e.*,
f.*
from (
select
c.*,
d.*
from (
select
a.*
from cj_tmp_main as a
left join cj_view_01 as b
on upper(a.pp_name + country) = upper(b.foo_key)
where b.foo_key is null
) as c
left join cj_view_02 as d
on upper(c.ppp_name + country) = upper(d.foo_key)
where d.foo_key is null
) as e
left join cj_view_03 as f
on upper(e.pp_name + country) = upper(f.foo_key)
and charindex(e.contry, f.country) != 0
and f.cj_flag = 'N'
where f.foo_key if null
) as g
-- 挑出没匹上的
left join cj_view_04 as h
on upper(g.pp_key) = upper(h.foo_key)
where h.foo_key is null
) as i
-- 内连接第 5 个视图
, cj_view_05 as j
where upper(i.foo_key + country) = upper(j.foo_key)
union all
-- 第六轮, 剩余的都是没有匹配上, 则再关联一个维表补充信息
select
k.*,
l.*
from (
select
i.*,
j.*
from (
select
g.*,
h.*
from (
select
e.*,
f.*
from (
select
c.*,
d.*
from (
select
a.*
from cj_tmp_main as a
left join cj_view_01 as b
on upper(a.pp_name + country) = upper(b.foo_key)
where b.foo_key is null
) as c
left join cj_view_02 as d
on upper(c.ppp_name + country) = upper(d.foo_key)
where d.foo_key is null
) as e
left join cj_view_03 as f
on upper(e.pp_name + e.country) = upper(f.foo_key)
and charindex(e.contry, f.country) != 0
and f.cj_flag = 'N'
where f.foo_key if null
) as g
left join cj_view_04 as h
on upper(g.pp_key) = upper(h.foo_key)
where h.foo_key is null
) as i
-- 挑出 5轮都没有匹上的顽固兄弟
left join cj_view_05 as j
on upper(i.foo_key + i.country) = upper(j.foo_key)
where j.foo_key is null
) as k
-- 最后的匹配
left join cj_view_06 as l
on upper(k.pp_key) = l.foo_key
-- -------------------------------------main -------------------------
) as m
脱敏处理了一下哈, 也就示意一下, 不能透露过多细节呢. 我发现, 我现在经常喜欢这样写 sql, 又长, 又很多嵌套, 又不好维护, 自己都看不懂, 隔了一段时间. 结果, 测试准备上线的时候, 就突然崩了了, 也不知道是哪一段逻辑的问题...... 这时候才想到了 sql 优化. 我觉得, 优化, 首先是要在逻辑上, 在算法上优先, 而不是那些, 什么鬼写法啥的....
逻辑优化
我很快想了一下, 首先从功能上讲, 要对主表, 不断进行 vlookup 嘛. 然后就想到编程思维了, 还好有强大的编程思维支持着我. 这就是要做 逻辑拆分嘛.
先建一个 目标空表, 拆分为几段逻辑, 分别插入即可, 用主表跟我的 6个视图, 分别做 Join, 下一次数据, 基于与当前主表id 互斥. 这样一下就从逻辑上解决了我的问题. 优化如下:
-- ---------------------- 优化版 --------------------------
-- 逻辑上优化, 先建一个结果表, 分部分, 不断往里面插数据即可.
drop table if exists cj_target_main;
create table cj_target_main (
id int identity,
aa varchar(1000) null,
bb varchar(1000) null,
cc varchar(1000) null,
.....
);
-- 分为 6 部分插入, 在视图的部分, 已经事先将字段对齐了~
-- 主表 跟 匹配表 依次连接 6 次, 每次的 动态过滤 id
-- ------------------------第1段插入-----------------
insert into cj_target_main from (
select
a.*,
b.*
from cj_tmp_main as a, cj_view_01 as b
where upper(a.pp_name + country) = upper(b.foo_key)
) as m
-- -------------------------第2段插入------------------
insert into cj_target_main from (
select
a.*,
b.*
from cj_tmp_main as a, cj_view_02 as b
where upper(a.pp_name + country) = upper(b.foo_key)
-- 这里最关键, 写出了编程思思哦..
and a.id not in (select cj_tmp_main)
) as m
-- -------------------------第3段插入------------------
insert into cj_target_main from (
select
a.*,
b.*
from cj_tmp_main as a, cj_view_03 as b
where upper(a.pp_name + country) = upper(b.foo_key)
and a.id not in (select cj_tmp_main)
and charindex(a.contry, b.country) != 0
and b.cj_flag = 'N'
) as m
-- -------------------------第4段插入------------------
insert into cj_target_main from (
select
a.*,
b.*
from cj_tmp_main as a, cj_view_04 as b
where upper(a.pp_key) = upper(b.foo_key)
and a.id not in (select cj_tmp_main)
) as m
-- -------------------------第5段插入------------------
insert into cj_target_main from (
select
a.*,
b.*
from cj_tmp_main as a, cj_view_05 as b
where upper(a.pp_key) = upper(b.foo_key)
and a.id not in (select cj_tmp_main)
) as m
-- -------------------------第6段插入------------------
insert into cj_target_main from (
select
a.*,
b.*
from cj_tmp_main as a, cj_view_06 as b
where upper(a.pp_key) = upper(b.foo_key)
and a.id not in (select cj_tmp_main)
) as m
这样就将多层嵌套逻辑, 稍稍修改了下, 就简单很多了. 当然, 视图很关键, 这里还用 * 了嘛, 在那些视图, 字段啥的我都是已经筛选和处理了, 分担了大部分的逻辑, 这里是主逻辑调用. 如此一来, 就将 sql 写出了, 函数式编程的感觉, 也算是我做一个比较成功的 sql 优化. 优化在处理逻辑上, 而非语句分析上, 是从整体上来优化这个过程呢. 毕竟是自己挖的坑, 也只能自己来填上呀.
小结
- sql 多层嵌套, 性能差, 可读性差, 就很难维护, 尽量要做到原子化一点
- 优化上, 优先考虑整体逻辑, 如分治法, 临时表, 中间表, 再去思考写法啥的
- 唯有多写和不断入坑, 填坑, 才会有真正的经验积累, 所谓经验, 都是采坑过来的
世界上本没有经验, 只是踩的坑多了, 便积累成了经验.



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通