文本-多行匹配和非贪婪 (03)
什么 520 , 跟我有什么关系? 单身狗不配过节, 只有默默地加班, 还有腾出点时间来, 练习一些基础代码来维持手感. 毕竟代码这块, 一直要保持良好的手感和时刻准备着, 嗯... 唯手熟尔. 希望, 下个520 , 能找个对象, 虽然看上去有点困难, 但, 万一实现了呢?
但毕竟, 这也是一个毕竟特殊的日期嘛, 2020-5-20. 虽然我一个人, 但, 浪漫还是要有的呀, 起码画个心来表示一下, 代码网上随便抄的哈, 不要在乎这些细节.
import matplotlib.pyplot as plt
import numpy as np
import math
t = np.linspace(0, math.pi, 1000)
x = np.sin(t)
y = np.cos(t) + np.power(x, 2.0 / 3)
plt.scatter(x,y,c=y,cmap=plt.cm.Reds,edgecolor='none', s=40)
plt.scatter(-x,y,c=y,cmap=plt.cm.Reds,edgecolor='none', s=40)
plt.axis([-2,2,-2,2])
plt.xlabel('Hi~ i am youge, nice to meet you~', fontsize=14)
plt.ylabel('2020-05-20',fontsize=14)
plt.title("dy / (I love you) = 0 ",fontsize=30)
plt.show()
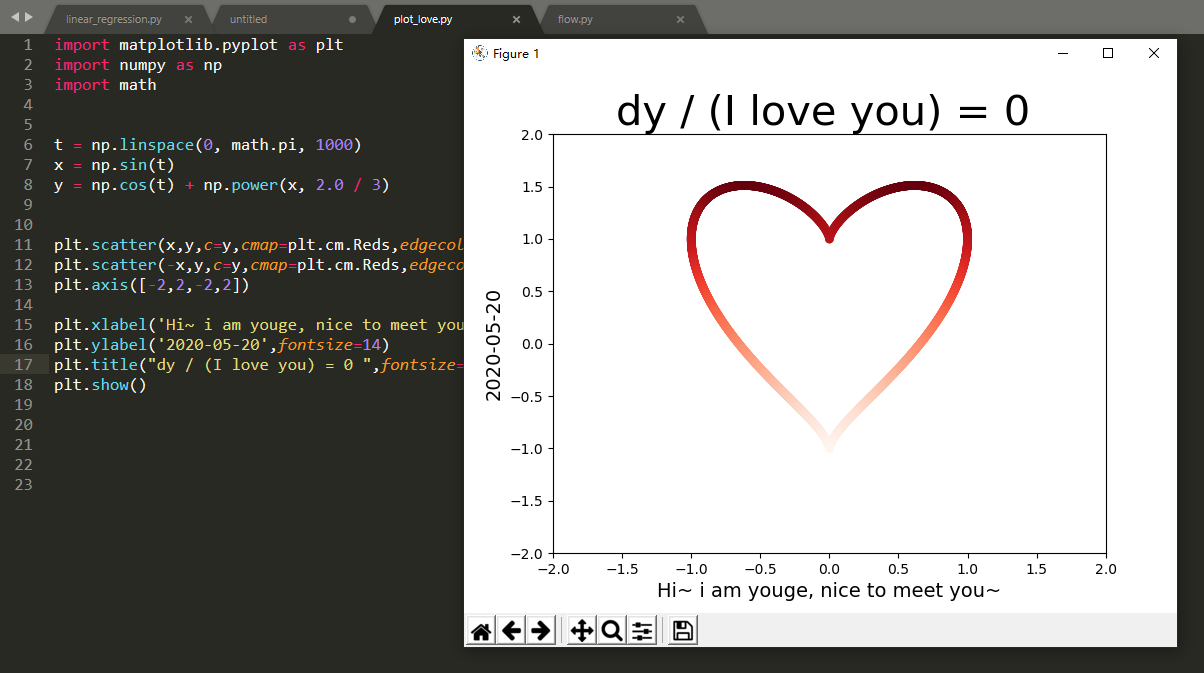
兄弟们, 这虽然成本低, 朴实无华, 但, 这难到不更加浪漫吗?
兄弟a: 代码报错了.
兄弟b: "i love you " 是一个常量
我想说: "人生若只如初见" -> "我心永恒"
...
兄弟a: 代码通常从右往左看...这尼玛, 渣男.
我想说: 还是跟IT的兄弟们, 沟通快乐得一批 !
文本非贪婪匹配
需求
基于某个文本匹配模式, 修改其匹配最短符合条件的文本, 即非贪婪匹配.
方案
Python 中的正则支持, 是贪婪匹配的, 即尽可能地多匹配数据, 像其他语言可能是不一样的, 好像 js 就是非贪婪的, 我有点忘了. 但有的时候呢, 我们需要尽可能少匹配, 目的就是为了灵活地满足自身需求.
通常, 该问题一般出现在需要匹配一对 分隔符 之间的文本的时候, 比如引号包含的字符:
# 匹配被双引号 " xxx" 包围的文本 '\' 是转义双引号的
str_pat = re.compile(r'\"(.*)\"')
text1 = 'Computer says "no. "'
print(str_pat.findall(text1))
text2 = 'Computer says "no." Phone says "yes."'
print(str_pat.findall(text2))
['no. ']
['no." Phone says "yes.']
可以从 text2 的匹配结果中看出, Python 默认是贪婪的, 也不能严格这样说, 跟正则表达式自身也有关系.
在正则中, " * " 操作符是贪婪的, 匹配任意个字符(>=0) . 如果要对其进行限制, 比如只匹配一次, 则用 问号 "?" 来进行限定修饰即可.
# 尽可能少匹配, "xxx" 里面的内容
str_pat = re.compile(r'\"(.*?)\"')
# text2 中有2处匹配的地方, 每处尽可能少匹配
print(str_pat.findall(text2))
['no.', 'yes.']
正则表达式的灵活使用,就基本语法层, 比如 * . ? {n} 分组, 转义 .... 等的基本操作, 是必须要熟练的, 因为, 真的太强大的呀. 也是我最为推崇备至的技术之一.
文本多行匹配
需求
用正则匹配的时候, 需要跨行去进行多行匹配
方案
这个问题, 当在使用 (.) 去匹配任意字符的时候, 就会突然忘了 (.) 不能匹配换行符的事实.
# 匹配注释 /* 这是注释 */ , \* 表示对 * 进行转义
comment = re.compile(r'/\*(.*?)\*/')
text1 = '/* this is a comment */'
text2 = '''
/* this is a
multiline comment */ ...
'''
print(comment.findall(text1))
print(comment.findall(text2))
[' this is a comment ']
[]
可以看到, 对于有换行符的, 跨行匹配就需要特殊处理一下哦, 用非捕获组 (?:.}\n) 这样的形式来限定.
# 跨行匹配, 设置一个不捕获 \n 的修饰
comment = re.compile(r'/\*((?:.|\n)*?)\*/')
print(comment.findall(text2))
[' this is a \n multiline comment ']



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通