SQL 日常练习 (十八)
也没啥, 就是入坑 sql 根本停不下来, 势必要达到所谓 "精通" 的地步.
从网上的例子也快搬运完了, 而工作中的 sql 又是万万不能外泄了. 因此想着, 该去哪里搬砖呢, 是有想刷 LeetCode 的冲动, 如果工作的 SB 客户, 不要那么为难我, 搞那些变态的需求, 不然我得挂掉了, 再跟他们这样玩下去的话. 还是抓紧练习 SQL, 万物皆 SQL. 我是万物. 虽然都是些简单的题, 反复练习, 其实也是在接近本质了, 但愿如此, 一步步这样一直走下去, 永不回头.
今天的 sql 练习, 就一题, 然后整一波, 4张表关联, 写套娃.... 一层套一层的那种, 从 a, b, c, d, e, f, g , 层层套,厉害了.
表关系
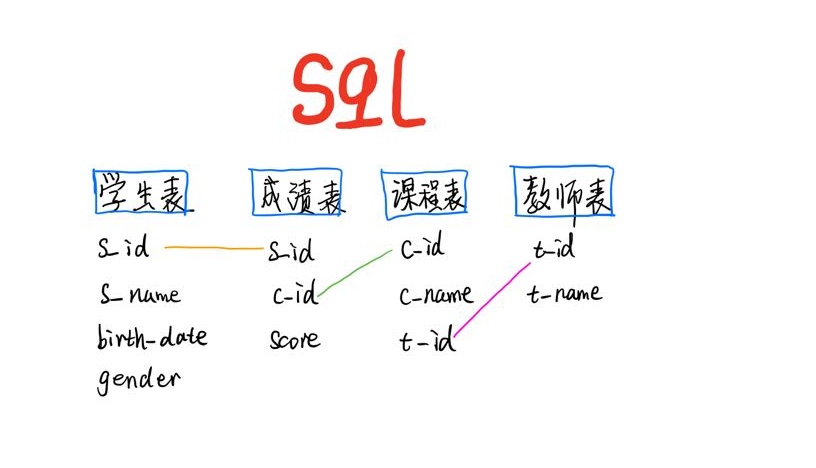
需求 01
查询 不同课程成绩相同 的学生的 学号, 课程号, 课程名称, 成绩
分析
不同成绩相同的 学号 ... 即对 学号, 成绩 进行 group by 即可, 然后再 inner join 上缺失的字段.
select
s_id,
score
from score
group by s_id, score
+------+-------+
| s_id | score |
+------+-------+
| 0001 | 80 |
| 0001 | 90 |
| 0001 | 99 |
| 0002 | 60 |
| 0002 | 80
|
| 0003 | 80 |
+------+-------+
6 rows in set (0.01 sec)
发现, 就只要 0 3 号兄弟是满足要求的, 因为是用 s_id 和 score 来做 group by 的, 003 只出现一次, 说明, 要么他就只是选了一门课, 要么就是 他选的课, 分数都是一样的, 这样才会出现 一条 记录呀. 要的就是它, 给他 having 筛选出
select
s_id,
score
from
(
select
s_id,
score
from score
group by s_id, score
) as a
group by s_id having count(s_id) = 1
+------+-------+
| s_id | score |
+------+-------+
| 0003 | 80 |
+------+-------+
1 row in set (0.00 sec)
还要排除一种情况是, 当他只选了一种可的情况. 即我们真正需要的 s_id 还需要满足这个条件
-- 选课数必须 大于 1
select s_id from score
group by s_id having count(distinct c_id) > 1
+------+
| s_id |
+------+
| 0001 |
| 0002 |
| 0003 |
+------+
3 rows in set (0.00 sec)
将这个条件给加进去, 当然不用 in 这种子查询方式啦, inner join 即可
select
b.s_id,
b.score
from
(
select
s_id,
score
from
(
select
s_id,
score
from score
group by s_id, score
) as a
group by s_id having count(s_id) = 1
) as b
-- 添加条件给 s_id
inner join (
select s_id from score
group by s_id having count(distinct c_id) > 1
) as c
on b.s_id = c.s_id
+------+-------+
| s_id | score |
+------+-------+
| 0003 | 80 |
+------+-------+
1 row in set (0.00 sec)
这个逻辑就会有点稍微复杂了.
select
b.s_id,
d.s_name,
b.score
from
(
select
s_id,
score
from
(
select
s_id,
score
from score
group by s_id, score
) as a
group by s_id having count(s_id) = 1
) as b
-- 添加条件给 s_id
inner join (
select s_id from score
group by s_id having count(distinct c_id) > 1
) as c
on b.s_id = c.s_id
-- 再将学生的信息给 匹配上来
inner join student as d
on c.s_id = d.s_id
+------+-----------+-------+
| s_id | s_name | score |
+------+-----------+-------+
| 0003 | 胡小适 | 80 |
+------+-----------+-------+
1 row in set (0.00 sec)
呀, 还没有完, 还要根据 这个 s_id 去 score 中 查出 选的 c_id, 再根据 c_id 从 course 中查出 c_name.
也是通过 join 的方式, 首先将这个结果集, 弄个套娃, inner join 和 成绩表, 再 inner join 课程表.
select
f.s_id,
e.s_name,
f.c_id,
g.c_name,
e.score
from
(
select
b.s_id,
d.s_name,
b.score
from
(
select
s_id,
score
from
(
select
s_id,
score
from score
group by s_id, score
) as a
group by s_id having count(s_id) = 1
) as b
-- 添加条件给 s_id
inner join (
select s_id from score
group by s_id having count(distinct c_id) > 1
) as c
on b.s_id = c.s_id
-- 再将学生的信息给 匹配上来
inner join student as d
on c.s_id = d.s_id
) as e
-- 匹配上相关的课程id
inner join score as f
on e.s_id = f.s_id
-- 匹配上相关的课程名称
inner join course as g
on f.c_id = g.c_id
+------+-----------+------+--------+-------+
| s_id | s_name | c_id | c_name | score |
+------+-----------+------+--------+-------+
| 0003 | 胡小适 | 0001 | 语文 | 80 |
| 0003 | 胡小适 | 0002 | 数学 | 80 |
| 0003 | 胡小适 | 0003 | 英语 | 80 |
+------+-----------+------+--------+-------+
3 rows in set (0.00 sec)
这个套娃, 就有点东西了,我也是不是一下子写出来的, 跟我平时写代码一样, 一边调试, 一边写. 一点点给堆上去的, 果然写代码, 写sql 都是一样的, 就是搬砖, 一点点往上堆就行了. 惨痛的经验告诉我, 如果事先整体的架构没有搭好, 后面的改动起来就非常麻烦了.
小结
- 写 sql 套娃, 确实是非常锻炼逻辑能力的时刻, 当然我从不考虑性能, 能做出来已经很不错了, 除非真的特别慢
- join 和 子查询相互配合使用, 我现在是更加偏向用 join 多一些, 子查询部分, 体现在 中间的查询集中
- 理清楚整个的逻辑和 代码缩减编排, 可读性上, 我觉得很关键, 不然别人看这就是一堆乱码, 理不清楚, 我现在的风格, 就多别名的那种, 从小写字母 a,b,c,d,e... 这样一直编, 跟着这个逻辑看下去, 肯定没啥问题的.



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通