将 Excel 拼接为 SQL 脚本
好像半年前,我就有写过将 Excel 数据, 逐条 或 批量 插入 mysql 数据库, 那时候正在建库嘛, 想着弄个脚本来批量刷新和处理. 工具当时用的 pandas, 这个, 强的一批的工具, 无敌强哦!. 批量导入用 DataFrame.to_sql() 一下子搞定, 课选择是 insert 还是 replace, 确实蛮方便的, 然后逐条就是 用 自己拼接 sql 的方式来一条条导入.
Excel 批量导入Mysql(创建表-追加数据): https://www.cnblogs.com/chenjieyouge/p/11811784.html
Excel 逐条导入Mysql(数据更新): https://www.cnblogs.com/chenjieyouge/p/11812126.html
这都是有控制权的方式下. 但现在我业务中, 我没有执行查询权限的时候, 我总不可能给相关的同事去发代码吧, 因此, 我通常的方式是将数据拼接为一个 sql 脚本, 给相应同事去执行.
需求
将一个 Excel 文件拼接为 sql 脚本 (insert) 进数据库.
思路
就是获取表格的每行, 每列的值, 然后 insert into 表 values (值1, 值2, .....); 存为一个 .sql 的文件, 然后执行这个脚本即可.
不多哔哔, 直接贴上核心代码哦.

栗子
数据预览
还是以我比较熟的 "超市数据" 为例, 这个数据是 Tableau 自带的数据集, 相信如果有用过 Tableau, 就应该对对其非常熟悉了吧, 不熟悉也无妨, 来预览一波这个数据集.
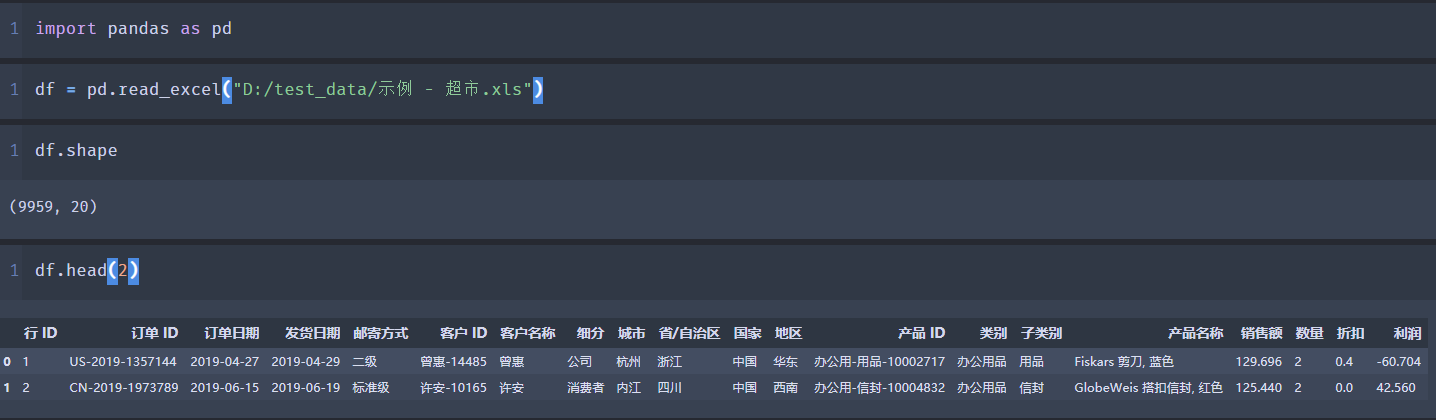
可以看到这个数据集有 9959行, 20个字段. 维度字段(产品, 类别, 字类别, 省, 市, 片区..) 而聚合字段有 销售额, 销量... 还是比较适合用来练习数据分析的哦.
遍历拼接
遍历 DataFrame, 我个人用的最多的, 还是用 iterrows() 的方式. 用 index , value 去 遍历, value 呢, 是一个Series 对象哦, 这就非常灵活了.
df = pd.DataFrame({
'a':[1,2,3],
'b':[4,5,6]
})
print(df)
a b
0 1 4
1 2 5
2 3 6
for _, val in df.iterrows():
print(val)
a 1
b 4
Name: 0, dtype: int64
a 2
b 5
Name: 1, dtype: int64
a 3
b 6
Name: 2, dtype: int64
灵活性就在于遍历的时候, 取值可以 val(0), val(1) ... 也可以 val['a'], val['b'] 想要谁就要谁. 正因为其每行数据作为一个 Series 对象, 那其实只要 调用其 values 属性就全部获取了.
然而我们最后要拼接的 sql 脚本, 要写入文件, 所有的值 必须是字符串, 因此将每个值给强转为字符类型.
val_lst = [str(i) for i in val.values]
这样就变成了, "['a', 'b', 'c'...]" 通过 字符串切片 的方式, 将该字符的首位的 "[", "]" 去掉即可. 需注意的是, 在Python 中 字符串是 不可变对象, 因此修改会返回一个新对象哦.
lst = ['a', 'b', 'c']
lst_str = (str(lst))
print(eval(lst_str[1:-1]))
('a', 'b', 'c')
eval() 和 repr() 这两个"互逆" 内置函数, 虽然原理不难, 在字符处理上, 很多时候还是很香的.
拼接 sql 为文件
def excel_to_sql_script(file_name, out_file_name, tb_name):
import pandas as pd
df = pd.read_excel(file_name)
with open(out_file_name, 'w', encoding='utf-8') as f:
for _, val in df.iterrows():
# 将每行值, 每个元素都转为 str, 整体也套为 str
val_str = str([str(i) for i in val.values])
# 通过切片, 将 "['a', 'b']" => "'a', 'b'" => 再来 eval 就ok了
sql_value = eval(val_str[1:-1])
f.write(f'insert into {tb_name} values {sql_value};' + '\n')
print("ok!")
# test
excel_to_sql_script("D:/test_data/示例 - 超市.xls", "D:/market.sql", "super_market")
win 下 GBK 编码问题:
with open(out_file_name, 'w', encoding='utf-8') , 一定要把这个 encoding='utf-8' 给加上哦
代码运行挺快了, 我这大致1000行嘛, 不到 1s 就读写完毕了, 也可能我新换的电脑比较给力的原因, 总体上也不会很慢的, 笔记就是一个读写文件而已嘛.
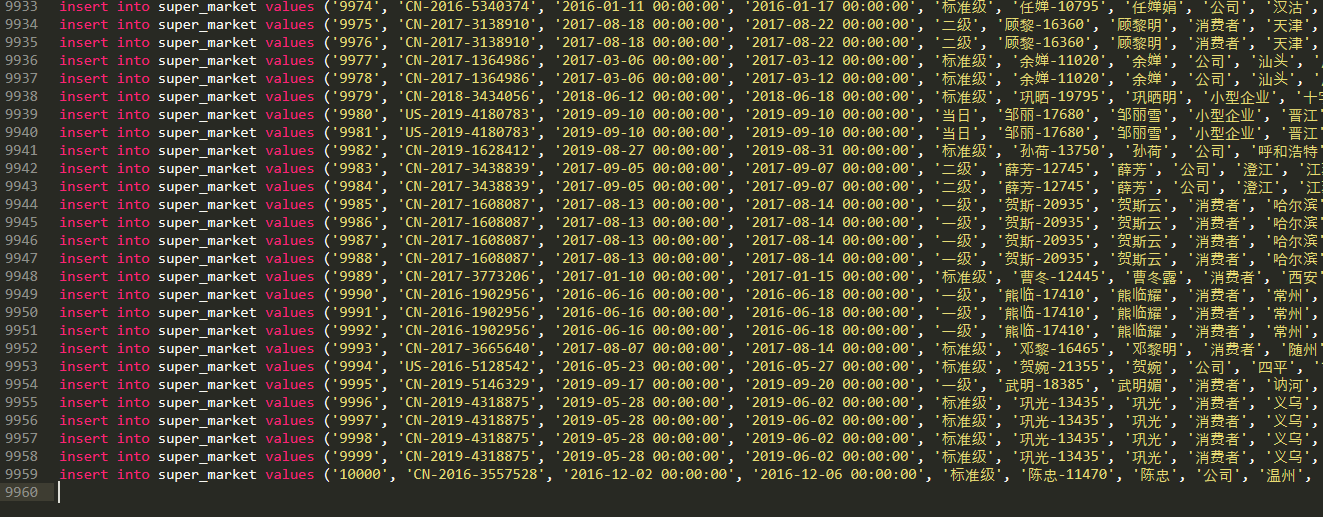
预览 sql 脚本
字段太多, 就展示下行数和部分字段啦, 如上代码, 脚本, 存在了我的 "D:/market.sql"
(编辑器用的 sublime , 当然, 用记事本打开也可以, 不过比较丑罢了).
执行 sql 脚本
既然能拼接sql , 自然也是可以自动建表的, 但我没有做这个操作, 嗯, 主要是我觉得, 建表还是手动一个个字段写比较好, 目的是熟悉每个字段名字, 类型. (当然自动也行, 后面整个全自动的).
drop table if exists super_market;
create table super_market(
id int primary key auto_increment,
order_id varchar(30),
order_date datetime,
ship_date datetime, -- 发货日期
ship_mode varchar(30), -- 邮寄方式
customer_id varchar(30),
customer_name varchar(30),
segment varchar(30), -- 细分 (公司, 消费者,微企...)
city varchar(30),
province varchar(20),
country varchar(20),
region varchar(20), -- 片区
product_id varchar(30),
category varchar(30),
sub_category varchar(30), -- 子类别
product_name varchar(50),
sales decimal(8,2),
quantity int,
discount decimal(5,2),
profit decimal(8,2)
);
查看建表:
mysql> desc super_market;
+---------------+--------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+---------------+--------------+------+-----+---------+----------------+
| id | int(11) | NO | PRI | NULL | auto_increment |
| order_id | varchar(30) | YES | | NULL | |
| order_date | datetime | YES | | NULL | |
| ship_date | datetime | YES | | NULL | |
| ship_mode | varchar(30) | YES | | NULL | |
| customer_id | varchar(30) | YES | | NULL | |
| customer_name | varchar(30) | YES | | NULL | |
| segment | varchar(30) | YES | | NULL | |
| city | varchar(30) | YES | | NULL | |
| province | varchar(20) | YES | | NULL | |
| country | varchar(20) | YES | | NULL | |
| region | varchar(20) | YES | | NULL | |
| product_id | varchar(30) | YES | | NULL | |
| category | varchar(30) | YES | | NULL | |
| sub_category | varchar(30) | YES | | NULL | |
| product_name | varchar(50) | YES | | NULL | |
| sales | decimal(8,2) | YES | | NULL | |
| quantity | int(11) | YES | | NULL | |
| discount | decimal(5,2) | YES | | NULL | |
| profit | decimal(8,2) | YES | | NULL | |
+---------------+--------------+------+-----+---------+----------------+
20 rows in set (0.00 sec)
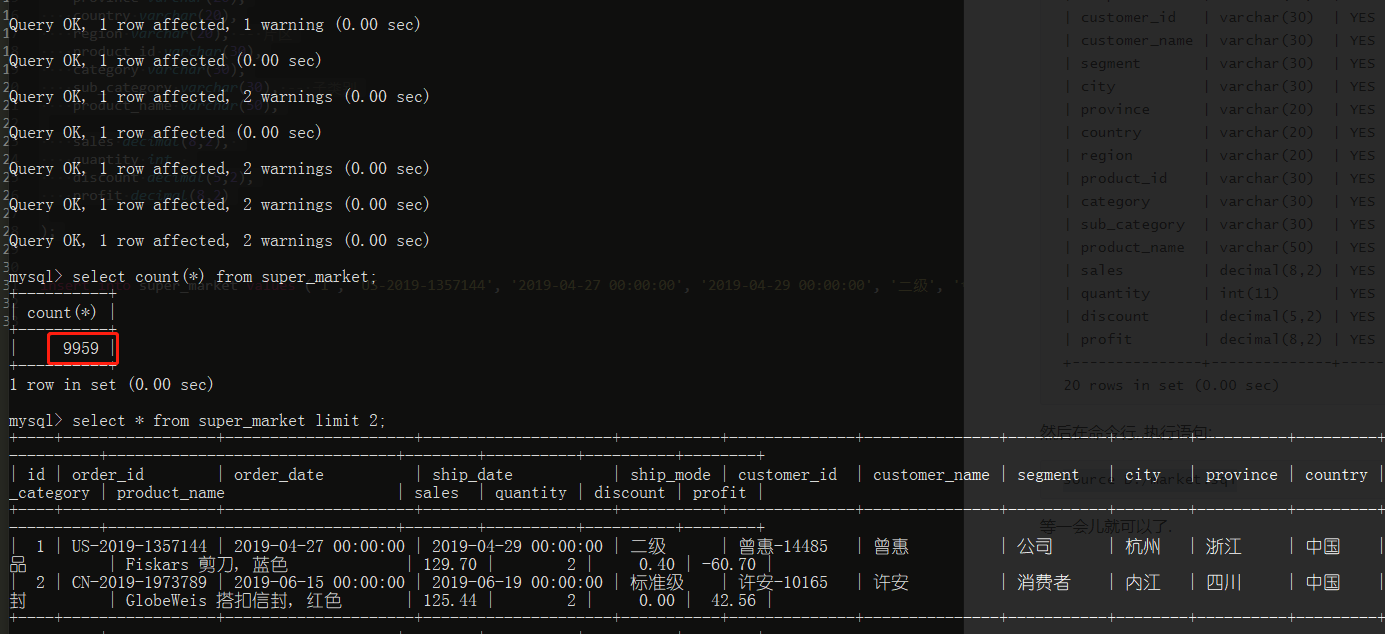
然后在命令行, 执行语句:
source D:/market.sql
等一会儿就可以了. (可以看到屏幕在疯狂闪动, 酷酷的), 原理就是一行行地执行 sql 语句而已呀.
小结
- 读取文件用的 pandas, 遍历用了 df.iterrows(). 每行会被当做 Series 对象, 下标和key 的方式都可以取值
- win下的文件读写bug, 对于中文编码错误, 一定要在 open 内 传入 encoding="utf-8"
- 拼接 sql, 可以先将其全转为 str, 然后通过 切片 sql_str[1:-1] 取出 列表中的元素.
最后想了下, 自动把表也给建号, 作为一个可选参数, 然后将这个应用 打包成 exe 文件, 也是可以的. 后面看有需要就弄一个吧, 无妨.

