
一张900w得数据表,17秒到300ms得优化语句
(摘抄之别人)👇
原理:就是减少回表操作
有一张财务流水表,未分库分表,目前的数据量为9555695,分页查询使用到了limit(使用条件),优化之前的查询耗时16 s 938 ms (execution: 16 s 831 ms, fetching: 107 ms),按照下文的方式调整SQL后,耗时347 ms (execution: 163 ms, fetching: 184 ms);
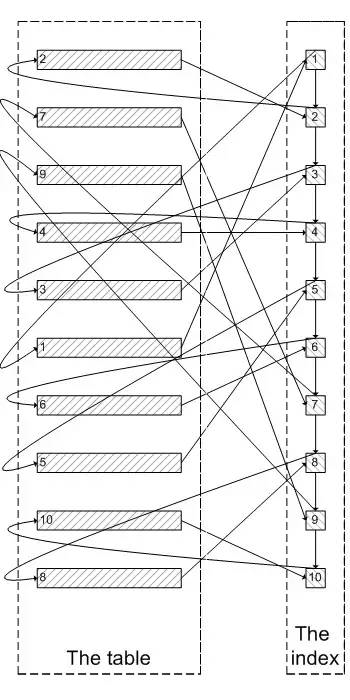
操作:查询条件放到子查询中,子查询只查主键ID,然后使用子查询中确定的主键关联查询其他的属性字段;

第一种:
mysql> select * from test where val=4 limit 300000,5;
+---------+-----+--------+
| id | val | source |
+---------+-----+--------+
| 3327622 | 4 | 4 |
| 3327632 | 4 | 4 |
| 3327642 | 4 | 4 |
| 3327652 | 4 | 4 |
| 3327662 | 4 | 4 |
+---------+-----+--------+
5 rows in set (15.98 sec)
第二种:
mysql> select * from test a inner join (select id from test where val=4 limit 300000,5) b on a.id=b.id;
+---------+-----+--------+---------+
| id | val | source | id |
+---------+-----+--------+---------+
| 3327622 | 4 | 4 | 3327622 |
| 3327632 | 4 | 4 | 3327632 |
| 3327642 | 4 | 4 | 3327642 |
| 3327652 | 4 | 4 | 3327652 |
| 3327662 | 4 | 4 | 3327662 |
+---------+-----+--------+---------+
5 rows in set (0.38 sec)
原理:
第一种语句是这样的,需要每次
第二种:
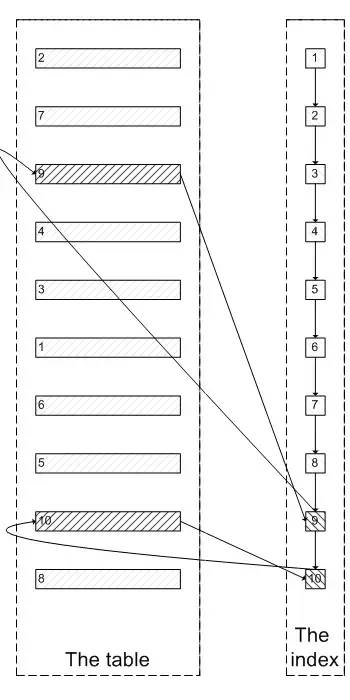
只查询了五次

