Mycat(水平拆分——分表 取模 ,mycat的分片"join" , 全局表)
相对于垂直拆分,水平拆分不是将表做分类,而是按照某个字段的某种规则来分散到多个库中。每个表中 包含一部分数据。简单来说,我们可以将数据的水平切分理解为是按照数据行的切分,就是将表中的某些行切分 到一个数据库,而别的某些行又切分到其他的数据库中。
配置分表
取模
1.选择要拆分的表
Mysql单表存储数据条数是有瓶颈的,单表达到1000万条数据时就达到了瓶颈,会影响查询效率,需要进行水平拆分(分表)进行优化。
列如:当orders 和 orders_detail都达到600万行数据,需要进行分表优化。
2.分表字段
以orders 表为列,可以根据不同字段进行分表
| 编号 | 分表字段 | 效果 |
|---|---|---|
| 1 | id(主键、或创建时间) | 查询订单注重时效,历史订单被查询的次数少,如此会形成一个节点访问多,一个节点访问少。 |
| 2 | customer_id(客户id) |
3.修改配置文件schema.xml
#为orders 表设置数据节点dn1,dn2,并指定分片规则mod_rule(自定义的名字) <table name="orders" dataNode="dn1,dn2" rule="mod_rule"></table>

4.修改配置文件rule.xml
#在rule 配置文件里面新增分片规则mod_rule,并指定规则适用字段为customer_id #还有选择分片算法mod-long(对字段取模运算),customer_id对两个节点取模,根据结果分片 #配置算法mod-long参数count为2,两个节点 <tableRule name="mod_rule"> <rule> <columns>customer_id</columns> <algorithm>mod-long</algorithm> </rule> </tableRule>
往下找到算法的具体实现

6.重启mycat。
7.访问mycat实现分片
insert into orders(id,order_type,customer_id,amount)values(1,1,1,1000.00); insert into orders(id,order_type,customer_id,amount)values(2,1,2,1000.00); insert into orders(id,order_type,customer_id,amount)values(3,1,3,1000.00); insert into orders(id,order_type,customer_id,amount)values(4,1,4,1000.00); insert into orders(id,order_type,customer_id,amount)values(5,1,5,1000.00); insert into orders(id,order_type,customer_id,amount)values(6,1,6,1000.00);
查询mycat:
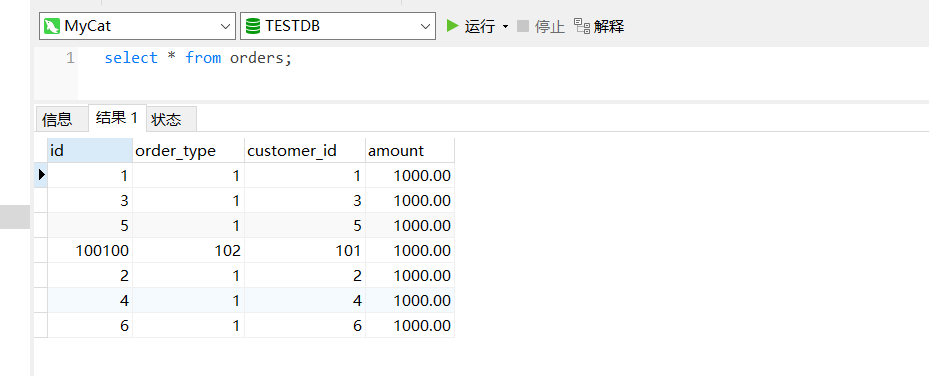
dn1:
dn2:

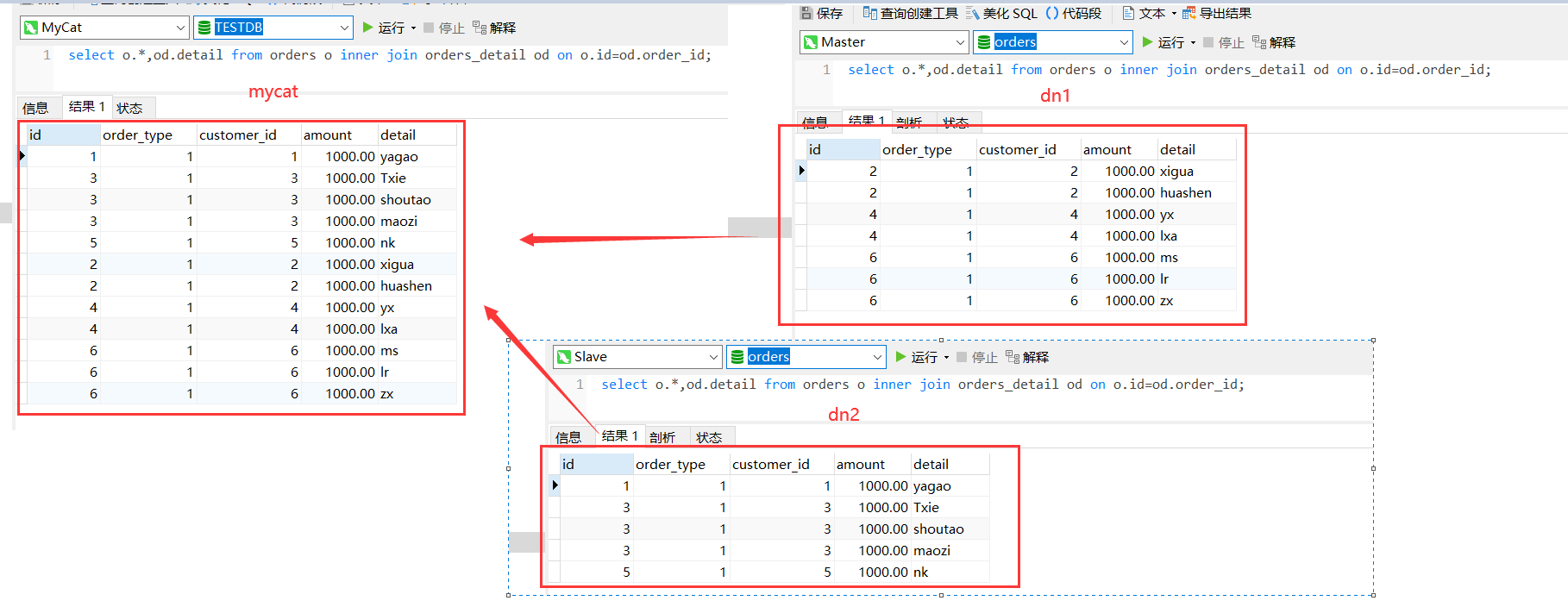
orders 订单表进行了分表操作,合它管理的orders_detail订单怎么进行join查询。
join原理:
应用发送一个sql 到mycat,mycat进行分片分析去数据库里面查询数据,拿到结果后mycat进行数据合并,在返回给应用。
ER表
mycat借鉴了 NewSQL 领域的 Foundation DB 的设计思路,Foundation DB 创新的提出了 Table Group 的概念,其将子表的存储位置依赖于主表,并且物理上紧邻存放,因此彻底解决了JION 的效率和性能问题,根据这一思路,提出了基于E-R 关系的数据分片策略,子表的记录与所关联的父表记录存放在同一个数据分片上。
修改schema.xml配置文件
<childTable name="orders_detail" primaryKey="id" joinKey="order_id" parentKey="id"/>

在dn2中新建orders_detail表
然后重启mycat
测试
mycat 里面插入数据
insert into orders_detail(id,detail,order_id)values(1,"xx",1); insert into orders_detail(id,detail,order_id)values(2,"xx",2); insert into orders_detail(id,detail,order_id)values(3,"xx",2); insert into orders_detail(id,detail,order_id)values(4,"Txie",3); insert into orders_detail(id,detail,order_id)values(5,"shoutao",3); insert into orders_detail(id,detail,order_id)values(6,"maozi",3); insert into orders_detail(id,detail,order_id)values(7,"yx",4); insert into orders_detail(id,detail,order_id)values(8,"lxa",4); insert into orders_detail(id,detail,order_id)values(9,"nk",5); insert into orders_detail(id,detail,order_id)values(10,"ms",6); insert into orders_detail(id,detail,order_id)values(11,"lr",6); insert into orders_detail(id,detail,order_id)values(12,"zx",6);
查看
全局表
在分片的情况下,当业务表因为规模而进行分片以后,业务表与这些附属的字典表之间的关联,就成了比较棘手的问题,考虑到字典表具有以下几个特征:
-
变动不频繁
-
数据量总体变化不大
-
数据规模不大,很少有超过十万条记录
鉴于此,MyCat定义了一种特殊的表,称为“全局表”,全局表具有以下特征:
-
全局表的插入,更新操作会实时在使用节点上执行,保存各个分片的数据一致性
-
全局表的查询操作,只会从一个节点获取
-
全局表可以跟任何一个表进行JION操作
将字典表或者符合字典表特性的一些表定义为全局表,则从另外一个方面,很好的解决了数据JION的难题。通过全局表+基于E-R 关系分片策略,MyCat可以满足80%以上的企业应用开发。
修改配置文件schema.xml
<schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100" dataNode="dn1"> <table name="customer" dataNode="dn2"></table> <table name="orders" dataNode="dn1,dn2" rule="mod_rule"> <childTable name="orders_detail" primaryKey="id" joinKey="order_id" parentKey="id"/> </table> #字典表 <table name="dict_order_type" dataNode="dn1,dn2" type="global"></table> </schema>
在 dn2 创建 dict_order_type表
重启mycat
访问mycat 向dict_order_type 表插入数据
INSERT INTO dict_order_type(id,order_type) VALUES(101,'type1'); INSERT INTO dict_order_type(id,order_type) VALUES(102,'type2');
然后依次查询mycat ,dn1,dn2都有数据。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号