Lucene入门及实际项目应用场景
导入maven依赖
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | <dependency> <groupId>org.apache.lucene</groupId> <artifactId>lucene-core</artifactId> <version>5.3.1</version></dependency><dependency> <groupId>org.apache.lucene</groupId> <artifactId>lucene-queryparser</artifactId> <version>5.3.1</version></dependency><dependency> <groupId>org.apache.lucene</groupId> <artifactId>lucene-analyzers-common</artifactId> <version>5.3.1</version></dependency> |
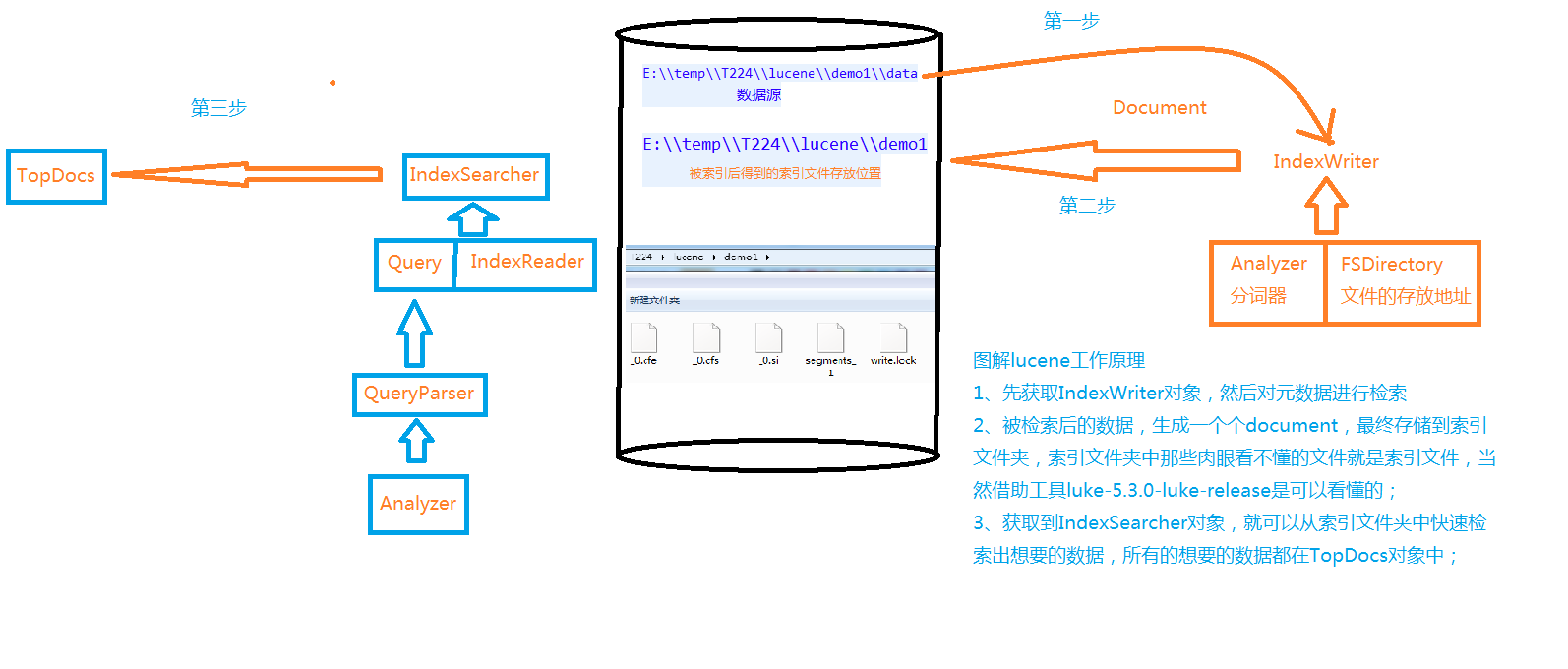
生成索引
目的:索引数据目录,在指定目录生成索引文件
1、构造方法 实例化IndexWriter
u 获取索引文件存放地址对象
u 获取输出流
设置输出流的对应配置
给输出流配置设置分词器
2、关闭索引输出流
3、索引指定路径下的所有文件
4、索引指定的文件
5、获取文档(索引文件中包含的重要信息,key-value的形式)
6、测试
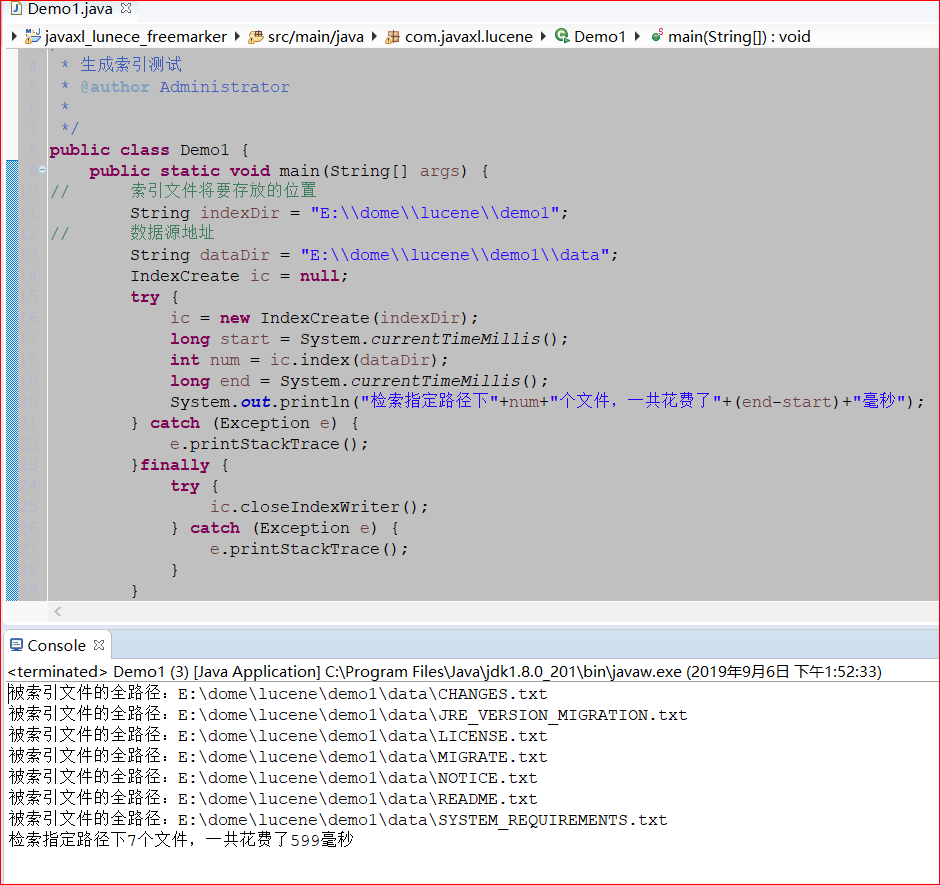
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 | package com.javaxl.lucene;import java.io.File;import java.io.FileReader;import java.nio.file.Paths;import org.apache.lucene.analysis.Analyzer;import org.apache.lucene.analysis.standard.StandardAnalyzer;import org.apache.lucene.document.Document;import org.apache.lucene.document.Field;import org.apache.lucene.document.TextField;import org.apache.lucene.index.IndexWriter;import org.apache.lucene.index.IndexWriterConfig;import org.apache.lucene.store.FSDirectory;/** * 配合Demo1.java进行lucene的helloword实现 * @author Administrator * */public class IndexCreate { private IndexWriter indexWriter; /** * 1、构造方法 实例化IndexWriter * @param indexDir * @throws Exception */ public IndexCreate(String indexDir) throws Exception{// 获取索引文件的存放地址对象 FSDirectory dir = FSDirectory.open(Paths.get(indexDir));// 标准分词器(针对英文) Analyzer analyzer = new StandardAnalyzer();// 索引输出流配置对象 IndexWriterConfig conf = new IndexWriterConfig(analyzer); indexWriter = new IndexWriter(dir, conf); } /** * 2、关闭索引输出流 * @throws Exception */ public void closeIndexWriter() throws Exception{ indexWriter.close(); } /** * 3、索引指定路径下的所有文件 * @param dataDir * @return * @throws Exception */ public int index(String dataDir) throws Exception{ File[] files = new File(dataDir).listFiles(); for (File file : files) { indexFile(file); } return indexWriter.numDocs(); } /** * 4、索引指定的文件 * @param file * @throws Exception */ private void indexFile(File file) throws Exception{ System.out.println("被索引文件的全路径:"+file.getCanonicalPath()); Document doc = getDocument(file); indexWriter.addDocument(doc); } /** * 5、获取文档(索引文件中包含的重要信息,key-value的形式) * @param file * @return * @throws Exception */ private Document getDocument(File file) throws Exception{ Document doc = new Document(); doc.add(new TextField("contents", new FileReader(file)));// Field.Store.YES是否存储到硬盘 doc.add(new TextField("fullPath", file.getCanonicalPath(),Field.Store.YES)); doc.add(new TextField("fileName", file.getName(),Field.Store.YES)); return doc; }}package com.javaxl.lucene;/** * 生成索引测试 * @author Administrator * */public class Demo1 { public static void main(String[] args) {// 索引文件将要存放的位置 String indexDir = "E:\\dome\\lucene\\demo1";// 数据源地址 String dataDir = "E:\\dome\\lucene\\demo1\\data"; IndexCreate ic = null; try { ic = new IndexCreate(indexDir); long start = System.currentTimeMillis(); int num = ic.index(dataDir); long end = System.currentTimeMillis(); System.out.println("检索指定路径下"+num+"个文件,一共花费了"+(end-start)+"毫秒"); } catch (Exception e) { e.printStackTrace(); }finally { try { ic.closeIndexWriter(); } catch (Exception e) { e.printStackTrace(); } } }} |
结果:
使用索引
从索引文件中拿数据
1、获取输入流(通过dirReader)
2、获取索引搜索对象(通过输入流来拿)
3、获取查询对象(通过查询解析器来获取,解析器是通过分词器获取)
4、获取包含关键字排前面的文档对象集合
5、可以获取对应文档的内容
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 | package com.javaxl.lucene;import java.nio.file.Paths;import org.apache.lucene.analysis.Analyzer;import org.apache.lucene.analysis.standard.StandardAnalyzer;import org.apache.lucene.document.Document;import org.apache.lucene.index.DirectoryReader;import org.apache.lucene.index.IndexReader;import org.apache.lucene.queryparser.classic.QueryParser;import org.apache.lucene.search.IndexSearcher;import org.apache.lucene.search.Query;import org.apache.lucene.search.ScoreDoc;import org.apache.lucene.search.TopDocs;import org.apache.lucene.store.FSDirectory;/** * 配合Demo2.java进行lucene的helloword实现 * @author Administrator * */public class IndexUse { /** * 通过关键字在索引目录中查询 * @param indexDir 索引文件所在目录 * @param q 关键字 */ public static void search(String indexDir, String q) throws Exception{ FSDirectory indexDirectory = FSDirectory.open(Paths.get(indexDir));// 注意:索引输入流不是new出来的,是通过目录读取工具类打开的 IndexReader indexReader = DirectoryReader.open(indexDirectory);// 获取索引搜索对象 IndexSearcher indexSearcher = new IndexSearcher(indexReader); Analyzer analyzer = new StandardAnalyzer(); QueryParser queryParser = new QueryParser("contents", analyzer);// 获取符合关键字的查询对象 Query query = queryParser.parse(q); long start=System.currentTimeMillis();// 获取关键字出现的前十次 TopDocs topDocs = indexSearcher.search(query , 10); long end=System.currentTimeMillis(); System.out.println("匹配 "+q+" ,总共花费"+(end-start)+"毫秒"+"查询到"+topDocs.totalHits+"个记录"); for (ScoreDoc scoreDoc : topDocs.scoreDocs) { int docID = scoreDoc.doc;// 索引搜索对象通过文档下标获取文档 Document doc = indexSearcher.doc(docID); System.out.println("通过索引文件:"+doc.get("fullPath")+"拿数据"); } indexReader.close(); }} |
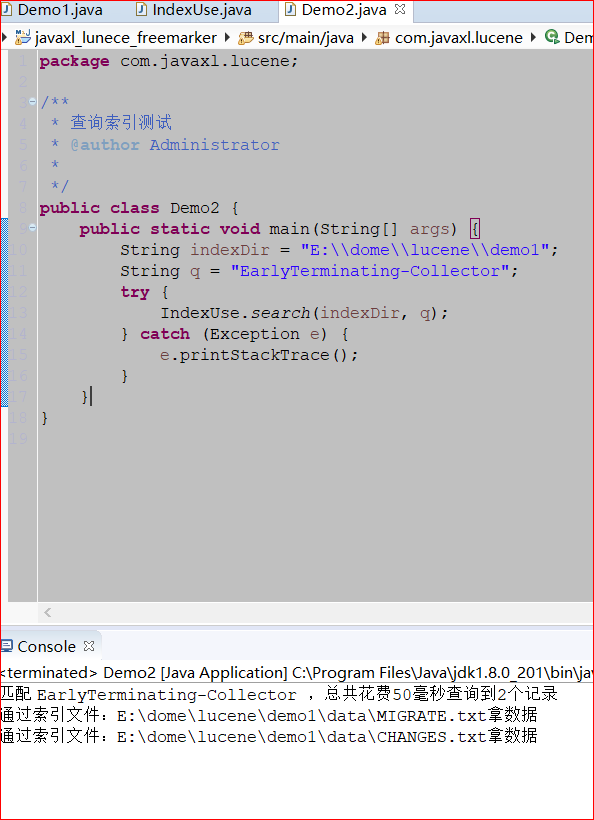
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | package com.javaxl.lucene;/** * 查询索引测试 * @author Administrator * */public class Demo2 { public static void main(String[] args) { String indexDir = "E:\\dome\\lucene\\demo1"; String q = "EarlyTerminating-Collector"; try { IndexUse.search(indexDir, q); } catch (Exception e) { e.printStackTrace(); } }} |
结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 | package com.javaxl.lucene;import java.nio.file.Paths;import org.apache.lucene.analysis.Analyzer;import org.apache.lucene.analysis.standard.StandardAnalyzer;import org.apache.lucene.document.Document;import org.apache.lucene.document.Field;import org.apache.lucene.document.StringField;import org.apache.lucene.document.TextField;import org.apache.lucene.index.IndexWriter;import org.apache.lucene.index.IndexWriterConfig;import org.apache.lucene.index.Term;import org.apache.lucene.store.FSDirectory;import org.junit.Before;import org.junit.Test;/** * 构建索引 * 对索引的增删改 * @author Administrator * */public class Demo3 { private String ids[]={"1","2","3"}; private String citys[]={"qingdao","nanjing","shanghai"}; private String descs[]={ "Qingdao is a beautiful city.", "Nanjing is a city of culture.", "Shanghai is a bustling city." }; private FSDirectory dir; /** * 每次都生成索引文件 * @throws Exception */ @Before public void setUp() throws Exception { dir = FSDirectory.open(Paths.get("E:\\dome\\lucene\\demo2\\indexDir")); IndexWriter indexWriter = getIndexWriter(); for (int i = 0; i < ids.length; i++) { Document doc = new Document(); doc.add(new StringField("id", ids[i], Field.Store.YES)); doc.add(new StringField("city", citys[i], Field.Store.YES)); doc.add(new TextField("desc", descs[i], Field.Store.NO)); indexWriter.addDocument(doc); } indexWriter.close(); } /** * 获取索引输出流 * @return * @throws Exception */ private IndexWriter getIndexWriter() throws Exception{ Analyzer analyzer = new StandardAnalyzer(); IndexWriterConfig conf = new IndexWriterConfig(analyzer); return new IndexWriter(dir, conf ); } /** * 测试写了几个索引文件 * @throws Exception */ @Test public void getWriteDocNum() throws Exception { IndexWriter indexWriter = getIndexWriter(); System.out.println("索引目录下生成"+indexWriter.numDocs()+"个索引文件"); } /** * 打上标记,该索引实际并未删除 * @throws Exception */ @Test public void deleteDocBeforeMerge() throws Exception { IndexWriter indexWriter = getIndexWriter(); System.out.println("最大文档数:"+indexWriter.maxDoc()); indexWriter.deleteDocuments(new Term("id", "1")); indexWriter.commit(); System.out.println("最大文档数:"+indexWriter.maxDoc()); System.out.println("实际文档数:"+indexWriter.numDocs()); indexWriter.close(); } /** * 对应索引文件已经删除,但是该版本的分词会保留 * @throws Exception */ @Test public void deleteDocAfterMerge() throws Exception {// https://blog.csdn.net/asdfsadfasdfsa/article/details/78820030// org.apache.lucene.store.LockObtainFailedException: Lock held by this virtual machine:indexWriter是单例的、线程安全的,不允许打开多个。 IndexWriter indexWriter = getIndexWriter(); System.out.println("最大文档数:"+indexWriter.maxDoc()); indexWriter.deleteDocuments(new Term("id", "1")); indexWriter.forceMergeDeletes(); //强制删除 indexWriter.commit(); System.out.println("最大文档数:"+indexWriter.maxDoc()); System.out.println("实际文档数:"+indexWriter.numDocs()); indexWriter.close(); } /** * 测试更新索引 * @throws Exception */ @Test public void testUpdate()throws Exception{ IndexWriter writer=getIndexWriter(); Document doc=new Document(); doc.add(new StringField("id", "1", Field.Store.YES)); doc.add(new StringField("city","qingdao",Field.Store.YES)); doc.add(new TextField("desc", "dsss is a city.", Field.Store.NO)); writer.updateDocument(new Term("id","1"), doc); writer.close(); }} |
新增索引
控制台:

删除索引
控制台输出
合并前
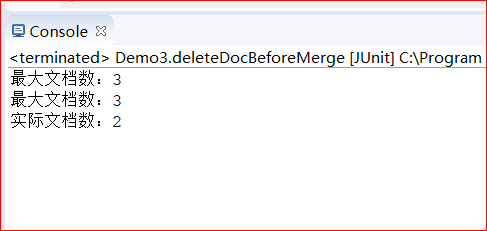
合并后
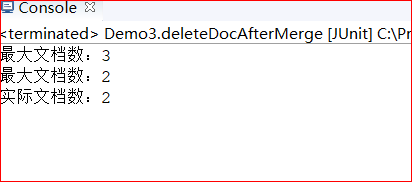
注意:
大数据时用合并前的删除,知识给索引文件打标,定时清理打标的索引文件。
数据量不是特别大的时候,可以及时删除索引文件。
修改索引
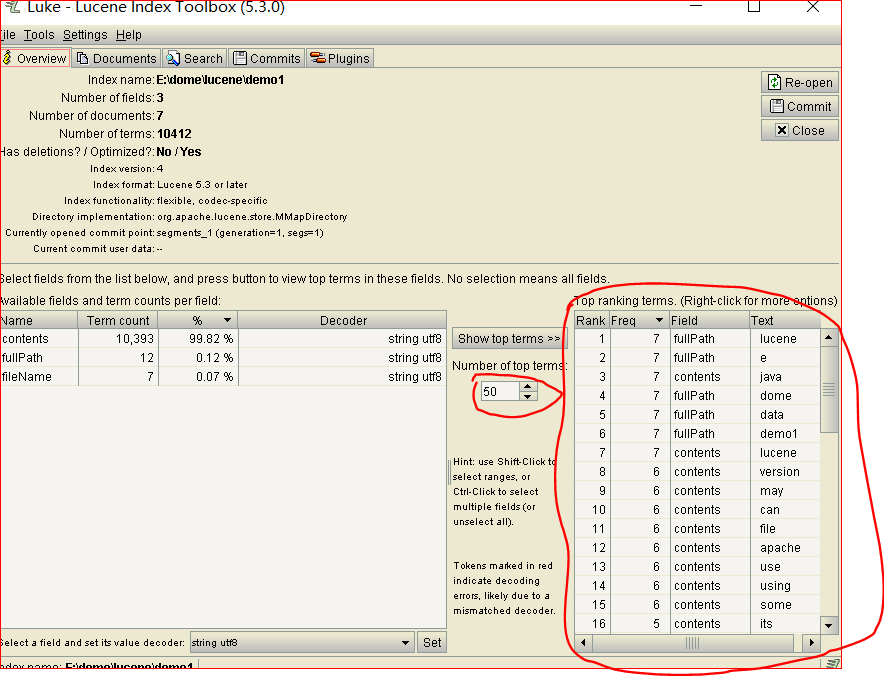
通过可视化工具可发现

文档域加权
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 | package com.javaxl.lucene;import java.nio.file.Paths;import org.apache.lucene.analysis.Analyzer;import org.apache.lucene.analysis.standard.StandardAnalyzer;import org.apache.lucene.document.Document;import org.apache.lucene.document.Field;import org.apache.lucene.document.StringField;import org.apache.lucene.document.TextField;import org.apache.lucene.index.DirectoryReader;import org.apache.lucene.index.IndexReader;import org.apache.lucene.index.IndexWriter;import org.apache.lucene.index.IndexWriterConfig;import org.apache.lucene.index.Term;import org.apache.lucene.search.IndexSearcher;import org.apache.lucene.search.Query;import org.apache.lucene.search.ScoreDoc;import org.apache.lucene.search.TermQuery;import org.apache.lucene.search.TopDocs;import org.apache.lucene.store.Directory;import org.apache.lucene.store.FSDirectory;import org.junit.Before;import org.junit.Test;/** * 文档域加权 * @author Administrator * */public class Demo4 { private String ids[]={"1","2","3","4"}; private String authors[]={"Jack","Marry","John","Json"}; private String positions[]={"accounting","technician","salesperson","boss"}; private String titles[]={"Java is a good language.","Java is a cross platform language","Java powerful","You should learn java"}; private String contents[]={ "If possible, use the same JRE major version at both index and search time.", "When upgrading to a different JRE major version, consider re-indexing. ", "Different JRE major versions may implement different versions of Unicode,", "For example: with Java 1.4, `LetterTokenizer` will split around the character U+02C6," }; private Directory dir;//索引文件目录 @Before public void setUp()throws Exception { dir = FSDirectory.open(Paths.get("E:\\dome\\lucene\\demo3\\indexDir")); IndexWriter writer = getIndexWriter(); for (int i = 0; i < authors.length; i++) { Document doc = new Document(); doc.add(new StringField("id", ids[i], Field.Store.YES)); doc.add(new StringField("author", authors[i], Field.Store.YES)); doc.add(new StringField("position", positions[i], Field.Store.YES)); TextField textField = new TextField("title", titles[i], Field.Store.YES); // Json投钱做广告,把排名刷到第一了 if("boss".equals(positions[i])) { textField.setBoost(2f);//设置权重,默认为1 } doc.add(textField);// TextField会分词,StringField不会分词 doc.add(new TextField("content", contents[i], Field.Store.NO)); writer.addDocument(doc); } writer.close(); } private IndexWriter getIndexWriter() throws Exception{ Analyzer analyzer = new StandardAnalyzer(); IndexWriterConfig conf = new IndexWriterConfig(analyzer); return new IndexWriter(dir, conf); } @Test public void index() throws Exception{ IndexReader reader = DirectoryReader.open(dir); IndexSearcher searcher = new IndexSearcher(reader); String fieldName = "title"; String keyWord = "java"; Term t = new Term(fieldName, keyWord); Query query = new TermQuery(t); TopDocs hits = searcher.search(query, 10); System.out.println("关键字:‘"+keyWord+"’命中了"+hits.totalHits+"次"); for (ScoreDoc scoreDoc : hits.scoreDocs) { Document doc = searcher.doc(scoreDoc.doc); System.out.println(doc.get("author")); } } } |
文档域加权前结果
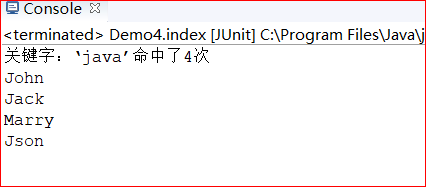
文档域加权后结果:

索引搜索功能
特定项搜索
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 | package com.javaxl.lucene;import java.io.IOException;import java.nio.file.Paths;import org.apache.lucene.analysis.standard.StandardAnalyzer;import org.apache.lucene.document.Document;import org.apache.lucene.index.DirectoryReader;import org.apache.lucene.index.IndexReader;import org.apache.lucene.index.Term;import org.apache.lucene.queryparser.classic.ParseException;import org.apache.lucene.queryparser.classic.QueryParser;import org.apache.lucene.search.IndexSearcher;import org.apache.lucene.search.NumericRangeQuery;import org.apache.lucene.search.ScoreDoc;import org.apache.lucene.search.TermQuery;import org.apache.lucene.search.TopDocs;import org.apache.lucene.store.FSDirectory;import org.junit.Before;import org.junit.Test;/** * 特定项搜索 * 查询表达式(queryParser) * @author Administrator * */public class Demo5 { @Before public void setUp() { // 索引文件将要存放的位置 String indexDir = "E:\\dome\\lucene\\demo4"; // 数据源地址 String dataDir = "E:\\dome\\lucene\\demo4\\data"; IndexCreate ic = null; try { ic = new IndexCreate(indexDir); long start = System.currentTimeMillis(); int num = ic.index(dataDir); long end = System.currentTimeMillis(); System.out.println("检索指定路径下" + num + "个文件,一共花费了" + (end - start) + "毫秒"); } catch (Exception e) { e.printStackTrace(); } finally { try { ic.closeIndexWriter(); } catch (Exception e) { e.printStackTrace(); } } } /** * 特定项搜索 */ @Test public void testTermQuery() { String indexDir = "E:\\dome\\lucene\\demo4"; String fld = "contents"; String text = "indexformattoooldexception";// 特定项片段名和关键字 Term t = new Term(fld , text); TermQuery tq = new TermQuery(t ); try { FSDirectory indexDirectory = FSDirectory.open(Paths.get(indexDir));// 注意:索引输入流不是new出来的,是通过目录读取工具类打开的 IndexReader indexReader = DirectoryReader.open(indexDirectory);// 获取索引搜索对象 IndexSearcher is = new IndexSearcher(indexReader); TopDocs hits = is.search(tq, 100);// System.out.println(hits.totalHits); for(ScoreDoc scoreDoc: hits.scoreDocs) { Document doc = is.doc(scoreDoc.doc); System.out.println("文件"+doc.get("fullPath")+"中含有该关键字"); } } catch (IOException e) { e.printStackTrace(); } } } |
控制台结果:
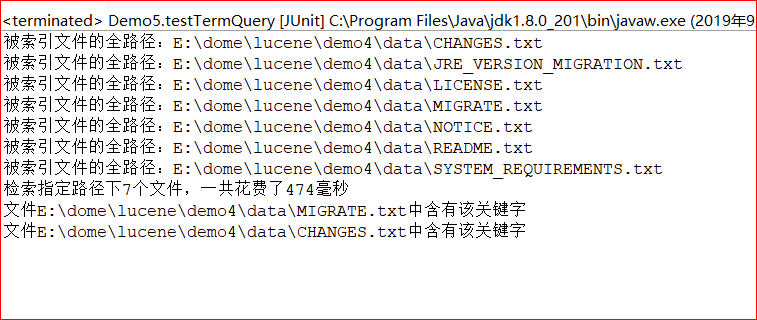
1 | 查询表达式 |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 | /** * 查询表达式(queryParser) */ @Test public void testQueryParser() { String indexDir = "E:\\dome\\lucene\\demo4";// 获取查询解析器(通过哪种分词器去解析哪种片段) QueryParser queryParser = new QueryParser("contents", new StandardAnalyzer()); try { FSDirectory indexDirectory = FSDirectory.open(Paths.get(indexDir));// 注意:索引输入流不是new出来的,是通过目录读取工具类打开的 IndexReader indexReader = DirectoryReader.open(indexDirectory);// 获取索引搜索对象 IndexSearcher is = new IndexSearcher(indexReader); // 由解析器去解析对应的关键字 TopDocs hits = is.search(queryParser.parse("indexformattoooldexception") , 100); for(ScoreDoc scoreDoc: hits.scoreDocs) { Document doc = is.doc(scoreDoc.doc); System.out.println("文件"+doc.get("fullPath")+"中含有该关键字"); } } catch (IOException e) { e.printStackTrace(); } catch (ParseException e) { // TODO Auto-generated catch block e.printStackTrace(); } } |
注意:与特定项搜索结果一样的。但是,特定项搜索是没有指定分词器的。
其他查询方法
u 指定数字范围查询(numbericRangeQuery)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 | package com.javaxl.lucene;import java.nio.file.Paths;import org.apache.lucene.analysis.Analyzer;import org.apache.lucene.analysis.standard.StandardAnalyzer;import org.apache.lucene.document.Document;import org.apache.lucene.document.Field;import org.apache.lucene.document.IntField;import org.apache.lucene.document.StringField;import org.apache.lucene.document.TextField;import org.apache.lucene.index.DirectoryReader;import org.apache.lucene.index.IndexReader;import org.apache.lucene.index.IndexWriter;import org.apache.lucene.index.IndexWriterConfig;import org.apache.lucene.index.Term;import org.apache.lucene.search.BooleanClause;import org.apache.lucene.search.BooleanQuery;import org.apache.lucene.search.IndexSearcher;import org.apache.lucene.search.NumericRangeQuery;import org.apache.lucene.search.PrefixQuery;import org.apache.lucene.search.ScoreDoc;import org.apache.lucene.search.TopDocs;import org.apache.lucene.store.FSDirectory;import org.junit.Before;import org.junit.Test;/** * 指定数字范围查询 * 指定字符串开头字母查询(prefixQuery) * @author Administrator * */public class Demo6 { private int ids[]={1,2,3}; private String citys[]={"qingdao","nanjing","shanghai"}; private String descs[]={ "Qingdao is a beautiful city.", "Nanjing is a city of culture.", "Shanghai is a bustling city." }; private FSDirectory dir; /** * 每次都生成索引文件 * @throws Exception */ @Before public void setUp() throws Exception { dir = FSDirectory.open(Paths.get("E:\\dome\\lucene\\demo2\\indexDir")); IndexWriter indexWriter = getIndexWriter(); for (int i = 0; i < ids.length; i++) { Document doc = new Document(); doc.add(new IntField("id", ids[i], Field.Store.YES)); doc.add(new StringField("city", citys[i], Field.Store.YES)); doc.add(new TextField("desc", descs[i], Field.Store.YES)); indexWriter.addDocument(doc); } indexWriter.close(); } /** * 获取索引输出流 * @return * @throws Exception */ private IndexWriter getIndexWriter() throws Exception{ Analyzer analyzer = new StandardAnalyzer(); IndexWriterConfig conf = new IndexWriterConfig(analyzer); return new IndexWriter(dir, conf ); } /** * 指定数字范围查询 * @throws Exception */ @Test public void testNumericRangeQuery()throws Exception{ IndexReader reader = DirectoryReader.open(dir); IndexSearcher is = new IndexSearcher(reader); NumericRangeQuery<Integer> query=NumericRangeQuery.newIntRange("id", 1, 2, true, true); TopDocs hits=is.search(query, 10); for(ScoreDoc scoreDoc:hits.scoreDocs){ Document doc=is.doc(scoreDoc.doc); System.out.println(doc.get("id")); System.out.println(doc.get("city")); System.out.println(doc.get("desc")); } } /** * 指定字符串开头字母查询(prefixQuery) * @throws Exception */ @Test public void testPrefixQuery()throws Exception{ IndexReader reader = DirectoryReader.open(dir); IndexSearcher is = new IndexSearcher(reader); PrefixQuery query=new PrefixQuery(new Term("city","n")); TopDocs hits=is.search(query, 10); for(ScoreDoc scoreDoc:hits.scoreDocs){ Document doc=is.doc(scoreDoc.doc); System.out.println(doc.get("id")); System.out.println(doc.get("city")); System.out.println(doc.get("desc")); } } /** * 组合查询 * @throws Exception */ @Test public void testBooleanQuery()throws Exception{ IndexReader reader = DirectoryReader.open(dir); IndexSearcher is = new IndexSearcher(reader); NumericRangeQuery<Integer> query1=NumericRangeQuery.newIntRange("id", 1, 2, true, true); //区分大小写 PrefixQuery query2=new PrefixQuery(new Term("city","n")); BooleanQuery.Builder booleanQuery=new BooleanQuery.Builder(); booleanQuery.add(query1,BooleanClause.Occur.MUST); booleanQuery.add(query2,BooleanClause.Occur.MUST); TopDocs hits=is.search(booleanQuery.build(), 10); for(ScoreDoc scoreDoc:hits.scoreDocs){ Document doc=is.doc(scoreDoc.doc); System.out.println(doc.get("id")); System.out.println(doc.get("city")); System.out.println(doc.get("desc")); } }} |
1 | 指定数字范围查询指定字符串开头:组合查询: |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | public void testBooleanQuery()throws Exception{ IndexReader reader = DirectoryReader.open(dir); IndexSearcher is = new IndexSearcher(reader); NumericRangeQuery<Integer> query1=NumericRangeQuery.newIntRange("id", 1, 2, true, true); //区分大小写 PrefixQuery query2=new PrefixQuery(new Term("city","n")); BooleanQuery.Builder booleanQuery=new BooleanQuery.Builder(); booleanQuery.add(query1,BooleanClause.Occur.MUST); booleanQuery.add(query2,BooleanClause.Occur.MUST); TopDocs hits=is.search(booleanQuery.build(), 10); for(ScoreDoc scoreDoc:hits.scoreDocs){ Document doc=is.doc(scoreDoc.doc); System.out.println(doc.get("id")); System.out.println(doc.get("city")); System.out.println(doc.get("desc")); } } |
中文分词&&高亮显示
1 |
1 2 3 4 5 6 7 | private Integer ids[] = { 1, 2, 3 };private String citys[] = { "青岛", "南京", "上海" }; private String descs[]={ "青岛是个美丽的城市。", "南京是个有文化的城市。", "上海市个繁华的城市。" }; |
1 | 为了查看高亮显示效果 |
青岛是个美丽的城市。南京是一个文化的城市南京,简称宁,是江苏省会,地处中国东部地区,长江下游,濒江近海。全市下辖11个区,总面积6597平方公里,2013年建成区面积752.83平方公里,常住人口818.78万,其中城镇人口659.1万人。[1-4] “江南佳丽地,金陵帝王州”,南京拥有着6000多年文明史、近2600年建城史和近500年的建都史,是中国四大古都之一,有“六朝古都”、“十朝都会”之称,是中华文明的重要发祥地,历史上曾数次庇佑华夏之正朔,长期是中国南方的政治、经济、文化中心,拥有厚重的文化底蕴和丰富的历史遗存。[5-7] 南京是国家重要的科教中心,自古以来就是一座崇文重教的城市,有“天下文枢”、“东南第一学”的美誉。截至2013年,南京有高等院校75所,其中211高校8所,仅次于北京上海;国家重点实验室25所、国家重点学科169个、两院院士83人,均居中国第三。[8-10]上海市个繁华的城市
1 |
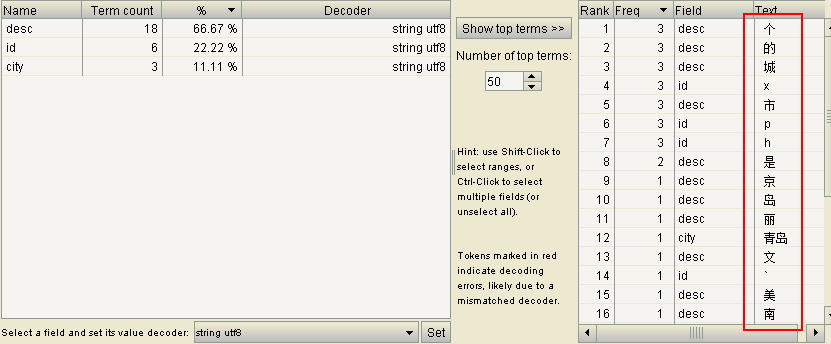
把每个字都当作了一个词,并没有达到我们想要的效果,也就是说标准分词器StandardAnalyzer已经不能满足我们的开发需要了。
中文分词
依赖:
1 2 3 4 5 | <dependency> <groupId>org.apache.lucene</groupId> <artifactId>lucene-highlighter</artifactId> <version>5.3.1</version></dependency> |
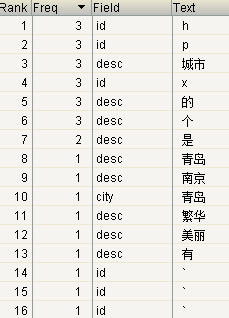
将标准分词器换成中文分词器
private IndexWriter getIndexWriter() throws Exception { // Analyzer analyzer = new StandardAnalyzer(); //中文分词器 Analyzer analyzer = new SmartChineseAnalyzer(); IndexWriterConfig conf = new IndexWriterConfig(analyzer); return new IndexWriter(dir, conf); }
结果:
高亮显示
依赖:
1 2 3 4 5 | <dependency> <groupId>org.apache.lucene</groupId> <artifactId>lucene-highlighter</artifactId> <version>5.3.1</version></dependency> |
高亮显示的步奏:
1、通过查询对象,获取查询得分对象
2、通过得分对象,获取对应的片段
3、实例化一个html格式化对象
4、通过html格式化实例和查询得分实例,来实例化Lucene提供的高亮显示类对象。
5、将前面获取到的得分片段,设置到高亮显示的的实例对象中。
6、通过分词器获取TokenStream令牌流对象
7、通过令牌和原有的片段,去拿高亮展示后的片段
1 |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 | package com.javaxl.lucene;import java.io.StringReader;import java.nio.file.Paths;import org.apache.lucene.analysis.Analyzer;import org.apache.lucene.analysis.TokenStream;import org.apache.lucene.analysis.cn.smart.SmartChineseAnalyzer;import org.apache.lucene.analysis.standard.StandardAnalyzer;import org.apache.lucene.document.Document;import org.apache.lucene.document.Field;import org.apache.lucene.document.IntField;import org.apache.lucene.document.StringField;import org.apache.lucene.document.TextField;import org.apache.lucene.index.DirectoryReader;import org.apache.lucene.index.IndexReader;import org.apache.lucene.index.IndexWriter;import org.apache.lucene.index.IndexWriterConfig;import org.apache.lucene.queryparser.classic.QueryParser;import org.apache.lucene.search.IndexSearcher;import org.apache.lucene.search.Query;import org.apache.lucene.search.ScoreDoc;import org.apache.lucene.search.TopDocs;import org.apache.lucene.search.highlight.Highlighter;import org.apache.lucene.search.highlight.QueryScorer;import org.apache.lucene.search.highlight.SimpleHTMLFormatter;import org.apache.lucene.search.highlight.SimpleSpanFragmenter;import org.apache.lucene.store.FSDirectory;import org.junit.Before;import org.junit.Test;/** * 中文分词器 * @author dell * */public class Demo7 { private Integer ids[] = { 1, 2, 3 }; private String citys[] = { "青岛", "南京", "上海" };// private String descs[]={// "青岛是个美丽的城市。",// "南京是个有文化的城市。",// "上海市个繁华的城市。"// }; private String descs[] = { "青岛是个美丽的城市。", "南京是一个文化的城市南京,简称宁,是江苏省会,地处中国东部地区,长江下游,濒江近海。全市下辖11个区,总面积6597平方公里,2013年建成区面积752.83平方公里,常住人口818.78万,其中城镇人口659.1万人。[1-4] “江南佳丽地,金陵帝王州”,南京拥有着6000多年文明史、近2600年建城史和近500年的建都史,是中国四大古都之一,有“六朝古都”、“十朝都会”之称,是中华文明的重要发祥地,历史上曾数次庇佑华夏之正朔,长期是中国南方的政治、经济、文化中心,拥有厚重的文化底蕴和丰富的历史遗存。[5-7] 南京是国家重要的科教中心,自古以来就是一座崇文重教的城市,有“天下文枢”、“东南第一学”的美誉。截至2013年,南京有高等院校75所,其中211高校8所,仅次于北京上海;国家重点实验室25所、国家重点学科169个、两院院士83人,均居中国第三。[8-10]", "上海市个繁华的城市。" }; private FSDirectory dir; /** * 每次都生成索引文件 * * @throws Exception */ @Before public void setUp() throws Exception { dir = FSDirectory.open(Paths.get("E:\\dome\\lucene\\demo2\\indexDir")); IndexWriter indexWriter = getIndexWriter(); for (int i = 0; i < ids.length; i++) { Document doc = new Document(); doc.add(new IntField("id", ids[i], Field.Store.YES)); doc.add(new StringField("city", citys[i], Field.Store.YES)); doc.add(new TextField("desc", descs[i], Field.Store.YES)); indexWriter.addDocument(doc); } indexWriter.close(); } /** * 获取索引输出流 * * @return * @throws Exception */ private IndexWriter getIndexWriter() throws Exception {// Analyzer analyzer = new StandardAnalyzer(); //中文分词器 Analyzer analyzer = new SmartChineseAnalyzer(); IndexWriterConfig conf = new IndexWriterConfig(analyzer); return new IndexWriter(dir, conf); } /** * luke查看索引生成 * * @throws Exception */ @Test public void testIndexCreate() throws Exception { } /** * 测试高亮 * * @throws Exception */ @Test public void testHeight() throws Exception { IndexReader reader = DirectoryReader.open(dir); IndexSearcher searcher = new IndexSearcher(reader); SmartChineseAnalyzer analyzer = new SmartChineseAnalyzer(); QueryParser parser = new QueryParser("desc", analyzer); // Query query = parser.parse("南京文化"); Query query = parser.parse("南京文明"); TopDocs hits = searcher.search(query, 100); // 查询得分项 QueryScorer queryScorer = new QueryScorer(query); // 得分项对应的内容片段 SimpleSpanFragmenter fragmenter = new SimpleSpanFragmenter(queryScorer); // 高亮显示的样式 SimpleHTMLFormatter htmlFormatter = new SimpleHTMLFormatter("<span color='red'><b>", "</b></span>"); // 高亮显示对象 Highlighter highlighter = new Highlighter(htmlFormatter, queryScorer); // 设置需要高亮显示对应的内容片段 highlighter.setTextFragmenter(fragmenter); for (ScoreDoc scoreDoc : hits.scoreDocs) { Document doc = searcher.doc(scoreDoc.doc); String desc = doc.get("desc"); if (desc != null) { // tokenstream是从doucment的域(field)中抽取的一个个分词而组成的一个数据流,用于分词。 TokenStream tokenStream = analyzer.tokenStream("desc", new StringReader(desc)); System.out.println("高亮显示的片段:" + highlighter.getBestFragment(tokenStream, desc)); } System.out.println("所有内容:" + desc); } }} |
1 |
控制台结果:
南京文明结果:
高亮显示的片段:城镇人口659.1万人。[1-4] “江南佳丽地,金陵帝王州”,<span color='red'><b>南京</b></span>拥有着6000多年<span color='red'><b>文明</b></span>史、近2600年建城史和近500年的建都史,是中国四大古都之一,有“六朝古都”、“十朝都会”之称,是中<spancolor='red'><b>文明</b></span>的所有内容:南京是一个文化的城市南京,简称宁,是江苏省会,地处中国东部地区,长江下游,濒江近海。全市下辖11个区,总面积6597平方公里,2013年建成区面积752.83平方公里,常住人口818.78万,其中城镇人口659.1万人。[1-4] “江南佳丽地,金陵帝王州”,南京拥有着6000多年文明史、近2600年建城史和近500年的建都史,是中国四大古都之一,有“六朝古都”、“十朝都会”之称,是中华文明的重要发祥地,历史上曾数次庇佑华夏之正朔,长期是中国南方的政治、经济、文化中心,拥有厚重的文化底蕴和丰富的历史遗存。[5-7] 南京是国家重要的科教中心,自古以来就是一座崇文重教的城市,有“天下文枢”、“东南第一学”的美誉。截至2013年,南京有高等院校75所,其中211高校8所,仅次于北京上海;国家重点实验室25所、国家重点学科169个、两院院士83人,均居中国第三。[8-10]
综合案例
核心代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 | <properties> <httpclient.version>4.5.2</httpclient.version> <jsoup.version>1.10.1</jsoup.version> <!-- <lucene.version>7.1.0</lucene.version> --> <lucene.version>5.3.1</lucene.version> <ehcache.version>2.10.3</ehcache.version> <junit.version>4.12</junit.version> <log4j.version>1.2.16</log4j.version> <mysql.version>5.1.44</mysql.version> <fastjson.version>1.2.47</fastjson.version> <struts2.version>2.5.16</struts2.version> <servlet.version>4.0.1</servlet.version> <jstl.version>1.2</jstl.version> <standard.version>1.1.2</standard.version> <tomcat-jsp-api.version>8.0.47</tomcat-jsp-api.version> </properties> <dependencies> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>${junit.version}</version> <scope>test</scope> </dependency> <!-- jdbc驱动包 --> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>${mysql.version}</version> </dependency> <!-- 添加Httpclient支持 --> <dependency> <groupId>org.apache.httpcomponents</groupId> <artifactId>httpclient</artifactId> <version>${httpclient.version}</version> </dependency> <!-- 添加jsoup支持 --> <dependency> <groupId>org.jsoup</groupId> <artifactId>jsoup</artifactId> <version>${jsoup.version}</version> </dependency> <!-- 添加日志支持 --> <dependency> <groupId>log4j</groupId> <artifactId>log4j</artifactId> <version>${log4j.version}</version> </dependency> <!-- 添加ehcache支持 --> <dependency> <groupId>net.sf.ehcache</groupId> <artifactId>ehcache</artifactId> <version>${ehcache.version}</version> </dependency> <dependency> <groupId>com.alibaba</groupId> <artifactId>fastjson</artifactId> <version>${fastjson.version}</version> </dependency> <dependency> <groupId>org.apache.struts</groupId> <artifactId>struts2-core</artifactId> <version>${struts2.version}</version> </dependency> <dependency> <groupId>javax.servlet</groupId> <artifactId>javax.servlet-api</artifactId> <version>${servlet.version}</version> <scope>provided</scope> </dependency> <dependency> <groupId>org.apache.lucene</groupId> <artifactId>lucene-core</artifactId> <version>${lucene.version}</version> </dependency> <dependency> <groupId>org.apache.lucene</groupId> <artifactId>lucene-queryparser</artifactId> <version>${lucene.version}</version> </dependency> <!-- <dependency> <groupId>org.apache.lucene</groupId> <artifactId>lucene-analyzers-common</artifactId> <version>${lucene.version}</version> </dependency> --> <dependency> <groupId>org.apache.lucene</groupId> <artifactId>lucene-analyzers-smartcn</artifactId> <version>${lucene.version}</version> </dependency> <dependency> <groupId>org.apache.lucene</groupId> <artifactId>lucene-highlighter</artifactId> <version>${lucene.version}</version> </dependency> <!-- 5.3、jstl、standard --> <dependency> <groupId>jstl</groupId> <artifactId>jstl</artifactId> <version>${jstl.version}</version> </dependency> <dependency> <groupId>taglibs</groupId> <artifactId>standard</artifactId> <version>${standard.version}</version> </dependency> <!-- 5.4、tomcat-jsp-api --> <dependency> <groupId>org.apache.tomcat</groupId> <artifactId>tomcat-jsp-api</artifactId> <version>${tomcat-jsp-api.version}</version> </dependency> </dependencies> |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 | package com.javaxl.blog.web;import java.util.ArrayList;import java.util.HashMap;import java.util.List;import java.util.Map;import javax.servlet.http.HttpServletRequest;import org.apache.lucene.analysis.cn.smart.SmartChineseAnalyzer;import org.apache.lucene.document.Document;import org.apache.lucene.index.DirectoryReader;import org.apache.lucene.queryparser.classic.QueryParser;import org.apache.lucene.search.IndexSearcher;import org.apache.lucene.search.Query;import org.apache.lucene.search.ScoreDoc;import org.apache.lucene.search.TopDocs;import org.apache.lucene.search.highlight.Highlighter;import org.apache.lucene.store.Directory;import org.apache.struts2.ServletActionContext;import com.javaxl.blog.dao.BlogDao;import com.javaxl.blog.util.LuceneUtil;import com.javaxl.blog.util.PropertiesUtil;import com.javaxl.blog.util.StringUtils;/** * IndexReader * IndexSearcher * Highlighter * @author Administrator * */public class BlogAction { private String title; private BlogDao blogDao = new BlogDao(); public String getTitle() { return title; } public void setTitle(String title) { this.title = title; } public String list() { try { HttpServletRequest request = ServletActionContext.getRequest(); if (StringUtils.isBlank(title)) { List<Map<String, Object>> blogList = this.blogDao.list(title, null); request.setAttribute("blogList", blogList); }else { Directory directory = LuceneUtil.getDirectory(PropertiesUtil.getValue("indexPath")); DirectoryReader reader = LuceneUtil.getDirectoryReader(directory); IndexSearcher searcher = LuceneUtil.getIndexSearcher(reader); SmartChineseAnalyzer analyzer = new SmartChineseAnalyzer();// 拿一句话到索引目中的索引文件中的词库进行关键词碰撞 Query query = new QueryParser("title", analyzer).parse(title); Highlighter highlighter = LuceneUtil.getHighlighter(query, "title"); TopDocs topDocs = searcher.search(query , 100); //处理得分命中的文档 List<Map<String, Object>> blogList = new ArrayList<>(); Map<String, Object> map = null; ScoreDoc[] scoreDocs = topDocs.scoreDocs; for (ScoreDoc scoreDoc : scoreDocs) { map = new HashMap<>(); Document doc = searcher.doc(scoreDoc.doc); map.put("id", doc.get("id")); String titleHighlighter = doc.get("title"); if(StringUtils.isNotBlank(titleHighlighter)) { titleHighlighter = highlighter.getBestFragment(analyzer, "title", titleHighlighter); } map.put("title", titleHighlighter); map.put("url", doc.get("url")); blogList.add(map); } request.setAttribute("blogList", blogList); } } catch (Exception e) { e.printStackTrace(); } return "blogList"; }} |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 | package com.javaxl.blog.web;import java.io.IOException;import java.nio.file.Paths;import java.sql.SQLException;import java.util.List;import java.util.Map;import org.apache.lucene.analysis.cn.smart.SmartChineseAnalyzer;import org.apache.lucene.document.Document;import org.apache.lucene.document.Field;import org.apache.lucene.document.StringField;import org.apache.lucene.document.TextField;import org.apache.lucene.index.IndexWriter;import org.apache.lucene.index.IndexWriterConfig;import org.apache.lucene.store.Directory;import org.apache.lucene.store.FSDirectory;import com.javaxl.blog.dao.BlogDao;import com.javaxl.blog.util.PropertiesUtil;/** * 构建lucene索引 * @author Administrator * 1。构建索引 IndexWriter * 2、读取索引文件,获取命中片段 * 3、使得命中片段高亮显示 * */public class IndexStarter { private static BlogDao blogDao = new BlogDao(); public static void main(String[] args) { IndexWriterConfig conf = new IndexWriterConfig(new SmartChineseAnalyzer()); Directory d; IndexWriter indexWriter = null; try { d = FSDirectory.open(Paths.get(PropertiesUtil.getValue("indexPath"))); indexWriter = new IndexWriter(d , conf ); // 为数据库中的所有数据构建索引 List<Map<String, Object>> list = blogDao.list(null, null); for (Map<String, Object> map : list) { Document doc = new Document(); doc.add(new StringField("id", (String) map.get("id"), Field.Store.YES));// TextField用于对一句话分词处理 java培训机构 doc.add(new TextField("title", (String) map.get("title"), Field.Store.YES)); doc.add(new StringField("url", (String) map.get("url"), Field.Store.YES)); indexWriter.addDocument(doc); } } catch (IOException e) { e.printStackTrace(); } catch (InstantiationException e) { e.printStackTrace(); } catch (IllegalAccessException e) { e.printStackTrace(); } catch (SQLException e) { e.printStackTrace(); }finally { try { if(indexWriter!= null) { indexWriter.close(); } } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } } }} |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 | package com.javaxl.blog.util;import java.io.IOException;import java.nio.file.Paths;import org.apache.lucene.analysis.Analyzer;import org.apache.lucene.index.DirectoryReader;import org.apache.lucene.index.IndexWriter;import org.apache.lucene.index.IndexWriterConfig;import org.apache.lucene.index.IndexWriterConfig.OpenMode;import org.apache.lucene.search.IndexSearcher;import org.apache.lucene.search.Query;import org.apache.lucene.search.highlight.Formatter;import org.apache.lucene.search.highlight.Highlighter;import org.apache.lucene.search.highlight.QueryTermScorer;import org.apache.lucene.search.highlight.Scorer;import org.apache.lucene.search.highlight.SimpleFragmenter;import org.apache.lucene.search.highlight.SimpleHTMLFormatter;import org.apache.lucene.store.Directory;import org.apache.lucene.store.FSDirectory;import org.apache.lucene.store.RAMDirectory;/** * lucene工具类 * @author Administrator * */public class LuceneUtil { /** * 获取索引文件存放的文件夹对象 * * @param path * @return */ public static Directory getDirectory(String path) { Directory directory = null; try { directory = FSDirectory.open(Paths.get(path)); } catch (IOException e) { e.printStackTrace(); } return directory; } /** * 索引文件存放在内存 * * @return */ public static Directory getRAMDirectory() { Directory directory = new RAMDirectory(); return directory; } /** * 文件夹读取对象 * * @param directory * @return */ public static DirectoryReader getDirectoryReader(Directory directory) { DirectoryReader reader = null; try { reader = DirectoryReader.open(directory); } catch (IOException e) { e.printStackTrace(); } return reader; } /** * 文件索引对象 * * @param reader * @return */ public static IndexSearcher getIndexSearcher(DirectoryReader reader) { IndexSearcher indexSearcher = new IndexSearcher(reader); return indexSearcher; } /** * 写入索引对象 * * @param directory * @param analyzer * @return */ public static IndexWriter getIndexWriter(Directory directory, Analyzer analyzer) { IndexWriter iwriter = null; try { IndexWriterConfig config = new IndexWriterConfig(analyzer); config.setOpenMode(OpenMode.CREATE_OR_APPEND); // Sort sort=new Sort(new SortField("content", Type.STRING)); // config.setIndexSort(sort);//排序 config.setCommitOnClose(true); // 自动提交 // config.setMergeScheduler(new ConcurrentMergeScheduler()); // config.setIndexDeletionPolicy(new // SnapshotDeletionPolicy(NoDeletionPolicy.INSTANCE)); iwriter = new IndexWriter(directory, config); } catch (IOException e) { e.printStackTrace(); } return iwriter; } /** * 关闭索引文件生成对象以及文件夹对象 * * @param indexWriter * @param directory */ public static void close(IndexWriter indexWriter, Directory directory) { if (indexWriter != null) { try { indexWriter.close(); } catch (IOException e) { indexWriter = null; } } if (directory != null) { try { directory.close(); } catch (IOException e) { directory = null; } } } /** * 关闭索引文件读取对象以及文件夹对象 * * @param reader * @param directory */ public static void close(DirectoryReader reader, Directory directory) { if (reader != null) { try { reader.close(); } catch (IOException e) { reader = null; } } if (directory != null) { try { directory.close(); } catch (IOException e) { directory = null; } } } /** * 高亮标签 * * @param query * @param fieldName * @return */ public static Highlighter getHighlighter(Query query, String fieldName) { Formatter formatter = new SimpleHTMLFormatter("<span style='color:red'>", "</span>"); Scorer fragmentScorer = new QueryTermScorer(query, fieldName); Highlighter highlighter = new Highlighter(formatter, fragmentScorer); highlighter.setTextFragmenter(new SimpleFragmenter(200)); return highlighter; }} |
结果:
1 | |



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 分享 3 个 .NET 开源的文件压缩处理库,助力快速实现文件压缩解压功能!
· Ollama——大语言模型本地部署的极速利器
· [AI/GPT/综述] AI Agent的设计模式综述