Kafka学习笔记
 Kafka的相关知识入门到精通
Kafka的相关知识入门到精通
--------
快速入门
--------
1. 概述
Kafka 是基于发布与订阅的消息系统。它最初由 LinkedIn 公司开发,之后成为 Apache 项目的一部分。
因为朋友已经写了一篇很不错的 Kafka 入门文章,所以艿艿就可以光明正大的偷懒了。对 Kafka 不了解的胖友,可以先阅读 《消息队列之 Kafka》 文章的 「1. Kafka 特点」 和 「2. Kafka 中的基本概念」 两个小节。😜
2. 单机部署
操作系统:macOS 10.14
其它系统,基本一致的。
Kafka 依赖 ZooKeeper 服务,所以胖友先自行安装并启动一个 ZooKeeper 服务。不会的胖友,可以参考阅读下 《ZooKeeper 极简入门》 文章的 「2. 单机部署」 小节。这里,艿艿在本机 127.0.0.1:2181 启动了一个 ZooKeeper 单节点。
2.1 下载软件包
打开 Kafka Download 页面,我们可以看到 Kafka 所有的发布版本。这里,我们选择最新的 Kafka 2.3.1 版本。这里,我们可以看到两种发布版本:
- Source: kafka-2.3.1-src.tgz
- Binary: kafka_2.12-2.3.1.tgz
一般情况下,我们可以直接使用 Binary 版本,它是 Kafka 已经编译好,可以直接使用的 Kafka 软件包。
下面,我们开始下载 Kafka Binary 软件包。命令行操作如下:
# 创建目录
$ mkdir -p /Users/yunai/Kafka
$ cd /Users/yunai/Kafka
# 下载
$ wget http://mirrors.tuna.tsinghua.edu.cn/apache/kafka/2.3.1/kafka_2.12-2.3.1.tgz
# 解压
$ unzip kafka_2.12-2.3.1.tgz
# 查看 Kafka 软件包的目录
$ kafka_2.12-2.3.1
$ ls -ls
total 72
64 -rw-r--r-- 1 yunai staff 32216 Oct 18 08:10 LICENSE
8 -rw-r--r-- 1 yunai staff 337 Oct 18 08:10 NOTICE
0 drwxr-xr-x 33 yunai staff 1056 Oct 18 08:12 bin # 执行脚本
0 drwxr-xr-x 16 yunai staff 512 Oct 18 08:12 config # 配置文件
0 drwxr-xr-x 94 yunai staff 3008 Oct 18 08:12 libs # Kafka jar 包
0 drwxr-xr-x 9 yunai staff 288 Dec 5 14:50 logs # 日志文件
0 drwxr-xr-x 3 yunai staff 96 Oct 18 08:12 site-docs # 文档
2.2 配置文件
在 config 目录下,提供了 Kafka 各个组件的配置文件。如下:
$ ls -ls config
total 136
8 -rw-r--r-- 1 yunai staff 906 Oct 18 08:10 connect-console-sink.properties
8 -rw-r--r-- 1 yunai staff 909 Oct 18 08:10 connect-console-source.properties
16 -rw-r--r-- 1 yunai staff 5321 Oct 18 08:10 connect-distributed.properties
8 -rw-r--r-- 1 yunai staff 883 Oct 18 08:10 connect-file-sink.properties
8 -rw-r--r-- 1 yunai staff 881 Oct 18 08:10 connect-file-source.properties
8 -rw-r--r-- 1 yunai staff 1552 Oct 18 08:10 connect-log4j.properties
8 -rw-r--r-- 1 yunai staff 2262 Oct 18 08:10 connect-standalone.properties
8 -rw-r--r-- 1 yunai staff 1221 Oct 18 08:10 consumer.properties
16 -rw-r--r-- 1 yunai staff 4727 Oct 18 08:10 log4j.properties
8 -rw-r--r-- 1 yunai staff 1925 Oct 18 08:10 producer.properties
16 -rw-r--r-- 1 yunai staff 6851 Oct 18 08:10 server.properties
8 -rw-r--r-- 1 yunai staff 1032 Oct 18 08:10 tools-log4j.properties
8 -rw-r--r-- 1 yunai staff 1169 Oct 18 08:10 trogdor.conf
8 -rw-r--r-- 1 yunai staff 1023 Oct 18 08:10 zookeeper.properties
这里,我们先创建一个 data 目录,然后编辑 conf/server.properties 配置文件,修改数据目录为新创建的 data 目录,即 log.dirs=/Users/yunai/Kafka/kafka_2.12-2.3.1/data 。
😈 当然,因为单机部署是学习或者测试之用,所以不改也问题不大。
2.3 启动 Kafka
启动一个 Kafka Broker 服务。命令行操作如下:
$ nohup bin/kafka-server-start.sh config/server.properties &
启动完成后,查看日志。
# 查看 Kafka Broker 日志。
$ tail -f logs/server.log
[2019-12-07 19:34:27,983] INFO Kafka version: 2.3.1 (org.apache.kafka.common.utils.AppInfoParser)
[2019-12-07 19:34:27,983] INFO Kafka commitId: 18a913733fb71c01 (org.apache.kafka.common.utils.AppInfoParser)
[2019-12-07 19:34:27,983] INFO Kafka startTimeMs: 1575545667980 (org.apache.kafka.common.utils.AppInfoParser)
[2019-12-07 19:34:27,985] INFO [KafkaServer id=0] started (kafka.server.KafkaServer)
- 默认情况下,Kafka Broker 日志文件所在地址为
logs/server.log。如果想要自定义,可以通过config/log4j.properties配置文件来进行修改。
😈 至此,我们已经完成了 Kafka 单机部署。下面,我们开始进行下消息的发送和消费的测试。
2.4 创建 Topic
在发送和消费消息之前,我们先来创建 Topic 。我们可以使用 bin/kafka-topics.sh 脚本,来进行 Kafka Topic 的管理。
# 创建名字为 TestTopic 的 Topic 。
# @param replication-factor 参数:Topic 副本数
# @param partitions 参数:Topic 分区数
# 关于两个参数的详细解释,可以看看 https://www.cnblogs.com/liuys635/p/10806665.html
$ bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic TestTopic
# 查询 Topic 列表
$ bin/kafka-topics.sh --list --zookeeper 127.0.0.1:2181
TestTopic
2.5 测试发送消息
通过使用 bin/kafka-console-producer.sh 脚本,实现测试发送消息。命令行操作如下:
# 执行 kafka-console-producer.sh 脚本,进入使用命令行发送消息的模式。
$ bin/kafka-console-producer.sh --broker-list 127.0.0.1:9092 --topic TestTopic
# 每输入一行,敲回车,都会发送一条消息
> yudaoyuanma
> nicai
> hahaha
完成发送三条测试消息后,我们使用「command + C」终止当前脚本,退出。
2.6 测试消费消息
通过使用 bin/kafka-console-consumer.sh 脚本,实现测试消费消息。命令行操作如下:
# 执行 kafka-console-consumer.sh 脚本,进入使用命令行消费消息
$ bin/kafka-console-consumer.sh --bootstrap-server 127.0.0.1:9092 --topic TestTopic --from-beginning
# 执行后,看到刚发送的三条消息,被成功消费,并打印在终端上。
yudaoyuanma
nicai
hahaha
至此,我们已经完成单机部署的 Kafka 的测试,舒服~
3. 集群部署
咳咳咳,偷懒下。胖友可以先看艿艿朋友写的 《消息队列之 Kafka》 文章的 「6. Kafka 集群配置」 小节。
在生产环境下,必须搭建 Kafka 高可用集群,不然简直是找死。
4. Kafka Manager
Kafka Manager 是由 Yahoo 雅虎开源的 Kafka 管理工具。它支持如下功能:
打开有道词典,一顿翻译。不过相信胖友,大体意思是能看的懂的。
- Manage multiple clusters
- Easy inspection of cluster state (topics, consumers, offsets, brokers, replica distribution, partition distribution)
- Run preferred replica election
- Generate partition assignments with option to select brokers to use
- Run reassignment of partition (based on generated assignments)
- Create a topic with optional topic configs (0.8.1.1 has different configs than 0.8.2+)
- Delete topic (only supported on 0.8.2+ and remember set delete.topic.enable=true in broker config)
- Topic list now indicates topics marked for deletion (only supported on 0.8.2+)
- Batch generate partition assignments for multiple topics with option to select brokers to use
- Batch run reassignment of partition for multiple topics
- Add partitions to existing topic
- Update config for existing topic
- Optionally enable JMX polling for broker level and topic level metrics.
- Optionally filter out consumers that do not have ids/ owners/ & offsets/ directories in zookeeper.
下面,让我们来搭建一个 Kafka Manager 。
4.1 下载软件包
Kafka Manager 在 Releases 中,暂时只提供源码 Source 包,未提供编译好的二进制 Binary 包。
考虑到 Kafka Manager 需要使用 sbt 进行构造,所以我们就暂时不考虑编译源码的方式。而是,从热心“网友”提供的Kafka Manager 安装包下载 ,美滋滋。这里,我们使用 Kafka Manager 2.0.0.2 版本。操作流程如下:
$ 下载。可能很慢,可以考虑采用迅雷下载。
$ wget https://github.com/wolfogre/kafka-manager-docker/releases/download/2.0.0.2/kafka-manager-2.0.0.2.zip
$ 解压
$ unzip kafka-manager-2.0.0.2.zip
# 查看 Kafka Manager 软件包的目录
$ cd kafka-manager-2.0.0.2
$ ls -ls
total 24
24 -rw-r--r--@ 1 yunai staff 8686 Apr 11 2019 README.md
0 drwxr-xr-x@ 14 yunai staff 448 Dec 5 23:17 bin # 执行脚本
0 drwxr-xr-x@ 7 yunai staff 224 Dec 5 23:17 conf # 配置文件
0 drwxr-xr-x@ 103 yunai staff 3296 Dec 5 23:17 lib # Kafka Manager jar 包
0 drwxr-xr-x@ 3 yunai staff 96 Dec 5 23:17 share
4.2 配置文件
编辑 conf/application.conf 配置文件,修改配置项为 kafka-manager.zkhosts="127.0.0.1:2181" 。此处,填写的是胖友的 ZooKeeper 地址。因为艿艿是本地启的 ZooKeeper 服务,所以填写了 "127.0.0.1:2181" 。
4.3 启动 Kafka Manager
启动一个 Kafka Manager 服务。命令行操作如下:
$ nohup bin/kafka-manager &
启动完成后,查看日志。
# 查看 Kafka Broker 日志。
$ tail -f logs/application.log
Application started (Prod)
2019-12-07 23:32:17,845 - [INFO] - from play.core.server.AkkaHttpServer in main
Listening for HTTP on /0:0:0:0:0:0:0:0:9000
4.4 添加 Kafka 集群
使用浏览器,访问 http://127.0.0.1:9000/ 地址,我们就可以看到 Kafka Manager 的界面。如下图:
点击导航栏的「Cluster」按钮,选择「Add Cluster」选项,进入 http://127.0.0.1:9000/addCluster 地址。在该界面,我们配置新增 Kafka 集群。如下图: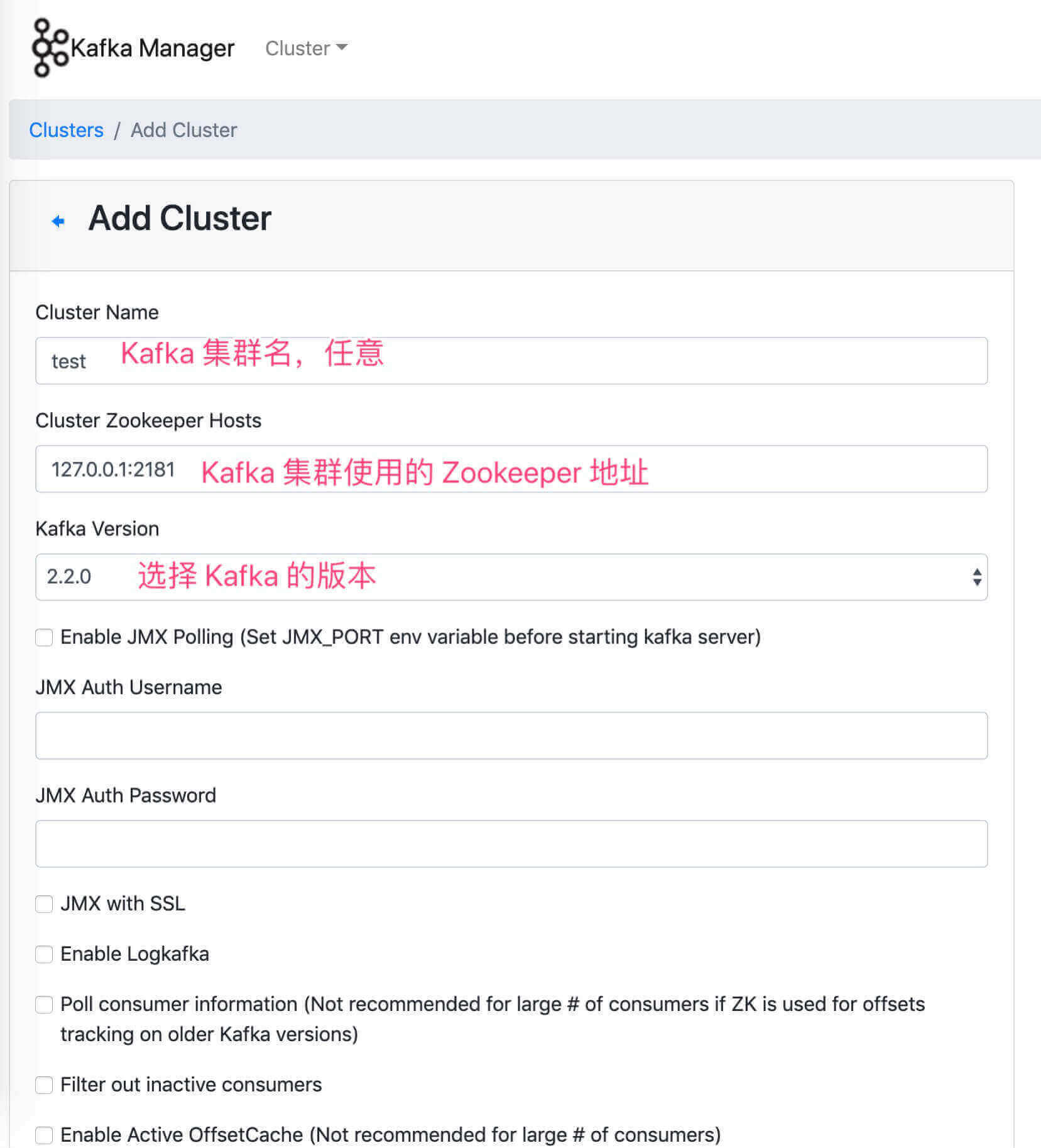
填写完成后,拉到表单最底部,点击「Save」按钮,保存 Kafka 集群。保存成功后,我们重新访问 http://127.0.0.1:9000/ 地址,就可以看到我们新添加的 Kafka 集群。如下图:
点击「test」Kafka 集群,我们就可以管理该 Kafka 集群。如下图: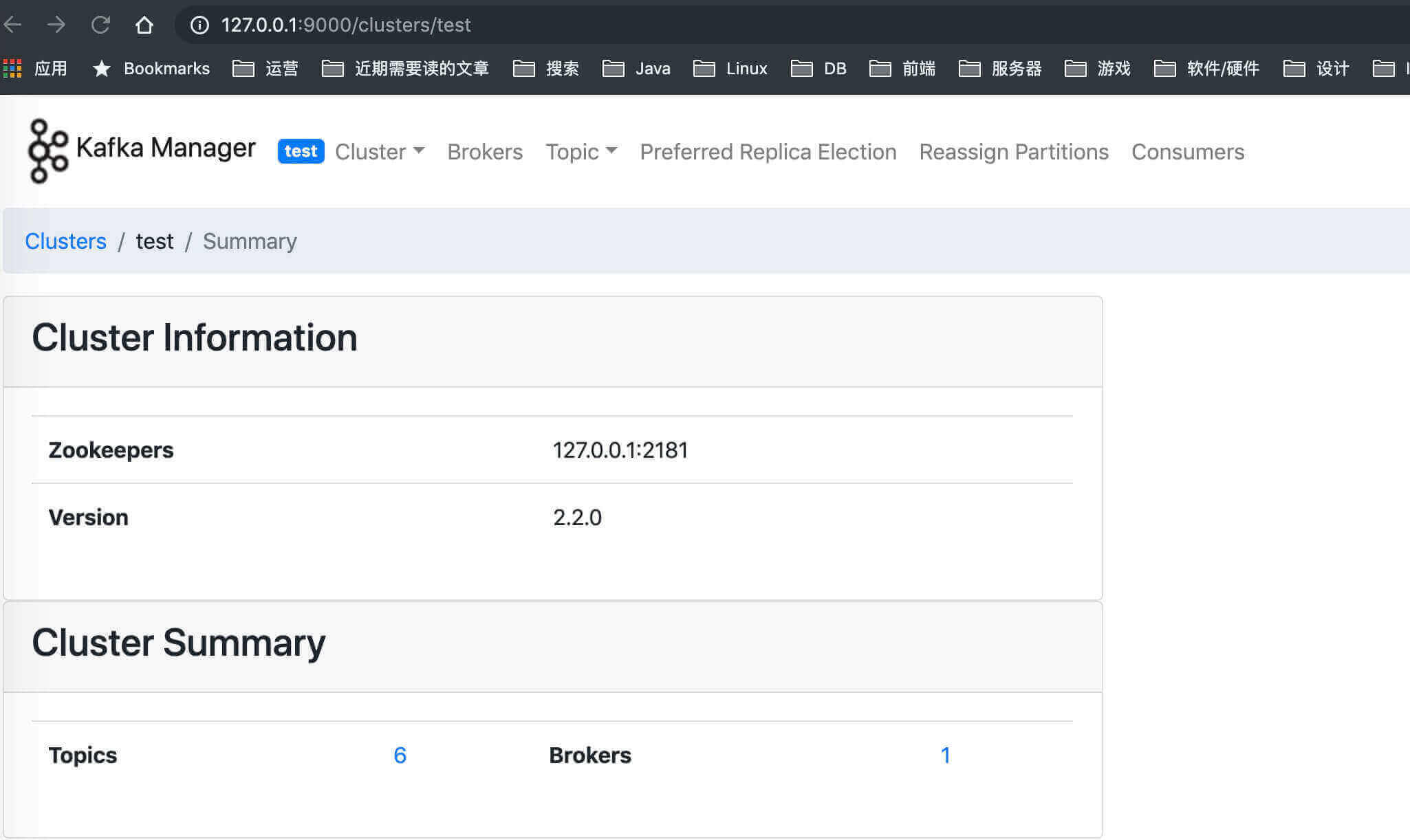
具体的功能,胖友可以自己多多体验,艿艿就不啰嗦赘述了。
5. 简单示例
示例代码对应仓库:lab-03-kafka-native 。
本小节,我们来看看在 Java 中,如何使用生产者 Producer 发送消息,和消费者 Consumer 消费消息。
5.1 引入依赖
在 pom.xml 文件中,引入相关依赖。
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<artifactId>lab-03-kafka-native</artifactId>
<dependencies>
<!-- 引入 Kafka 客户端依赖 -->
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.3.1</version>
</dependency>
</dependencies>
</project>
具体每个依赖的作用,胖友自己认真看下艿艿添加的所有注释噢。
5.2 ProducerMain
创建 ProducerMain 类,使用 KafkaProducer 发送消息。代码如下:
// ProducerMain.java
public class ProducerMain {
private static Producer<String, String> createProducer() {
// 设置 Producer 的属性
Properties properties = new Properties();
properties.put("bootstrap.servers", "127.0.0.1:9092"); // 设置 Broker 的地址
properties.put("acks", "1"); // 0-不应答。1-leader 应答。all-所有 leader 和 follower 应答。
properties.put("retries", 3); // 发送失败时,重试发送的次数
// properties.put("batch.size", 16384);
// properties.put("linger.ms", 1);
// properties.put("client.id", "DemoProducer");
// properties.put("buffer.memory", 33554432);
properties.put("key.serializer", StringSerializer.class.getName()); // 消息的 key 的序列化方式
properties.put("value.serializer", StringSerializer.class.getName()); // 消息的 value 的序列化方式
// 创建 KafkaProducer 对象
// 因为我们消息的 key 和 value 都使用 String 类型,所以创建的 Producer 是 <String, String> 的泛型。
return new KafkaProducer<>(properties);
}
public static void main(String[] args) throws ExecutionException, InterruptedException {
// 创建 KafkaProducer 对象
Producer<String, String> producer = createProducer();
// 创建消息。传入的三个参数,分别是 Topic ,消息的 key ,消息的 message 。
ProducerRecord<String, String> message = new ProducerRecord<>("TestTopic", "key", "yudaoyuanma");
// 同步发送消息
Future<RecordMetadata> sendResultFuture = producer.send(message);
RecordMetadata result = sendResultFuture.get();
System.out.println("message sent to " + result.topic() + ", partition " + result.partition() + ", offset " + result.offset());
}
}
- 代码比较简单,胖友根据艿艿添加的注释,理解下哈。
执行 #main(args) 方法,发送消息到 Kafka 。执行结果如下:
message sent to TestTopic, partition 0, offset 8
- 发送消息成功。
5.3 ConsumerMain
创建 ConsumerMain 类,使用 KafkaConsumer 消费消息。代码如下:
// ConsumerMain.java
public class ConsumerMain {
private static Consumer<String, String> createConsumer() {
// 设置 Producer 的属性
Properties properties = new Properties();
properties.put("bootstrap.servers", "127.0.0.1:9092"); // 设置 Broker 的地址
properties.put("group.id", "demo-consumer-group"); // 消费者分组
properties.put("auto.offset.reset", "earliest"); // 设置消费者分组最初的消费进度为 earliest 。可参考博客 https://blog.csdn.net/lishuangzhe7047/article/details/74530417 理解
properties.put("enable.auto.commit", true); // 是否自动提交消费进度
properties.put("auto.commit.interval.ms", "1000"); // 自动提交消费进度频率
properties.put("key.deserializer", StringDeserializer.class.getName()); // 消息的 key 的反序列化方式
properties.put("value.deserializer", StringDeserializer.class.getName()); // 消息的 value 的反序列化方式
// 创建 KafkaProducer 对象
// 因为我们消息的 key 和 value 都使用 String 类型,所以创建的 Producer 是 <String, String> 的泛型。
return new KafkaConsumer<>(properties);
}
public static void main(String[] args) {
// 创建 KafkaConsumer 对象
Consumer<String, String> consumer = createConsumer();
// 订阅消息
consumer.subscribe(Collections.singleton("TestTopic"));
// 拉取消息
while (true) {
// 拉取消息。如果拉取不到消息,阻塞等待最多 10 秒,或者等待拉取到消息。
ConsumerRecords records = consumer.poll(Duration.ofSeconds(10));
// 遍历处理消息
records.forEach(new java.util.function.Consumer<ConsumerRecord>() {
@Override
public void accept(ConsumerRecord record) {
System.out.println(record.key() + "\t" + record.value());
}
});
}
}
}
- 代码比较简单,胖友根据艿艿添加的注释,理解下哈。
执行 #main(args) 方法,从 Kafka 消费消息。执行结果如下:
null 123
null fsf
null 123
null 123
null nicai
null 1232321
null 3213231
key yudaoyuanma
key yudaoyuanma
- 😈 有一部分消息是艿艿之前做测试发的,可以忽略哈。此时,我们已经成功消费。
--------
SpringBoot中的Kafka
--------
本文在提供完整代码示例,可见 https://github.com/YunaiV/SpringBoot-Labs 的 lab-03-kafka 目录。
原创不易,给点个 Star 嘿,一起冲鸭!
1. 概述
如果胖友还没了解过分布式消息队列 Apache Kafka ,建议先阅读下艿艿写的 《芋道 Kafka 极简入门》 文章。虽然这篇文章标题是安装部署,实际可以理解成《一文带你快速入门 Kafka》,哈哈哈。
考虑这是 Kafka 如何在 Spring Boot 整合与使用的文章,所以还是简单介绍下 Kafka 是什么?
FROM 《分布式发布订阅消息系统 Kafka》
Kafka 是一种高吞吐量的分布式发布订阅消息系统,她有如下特性:
- 通过 O(1) 的磁盘数据结构提供消息的持久化,这种结构对于即使数以TB的消息存储也能够保持长时间的稳定性能。
- 高吞吐量:即使是非常普通的硬件kafka也可以支持每秒数十万的消息。
- 支持通过 Kafka 服务器和消费机集群来分区消息。
在本文中,我们会比 《芋道 Kafka 极简入门》 提供更多的生产者 Producer 和消费者 Consumer 的使用示例。例如说:
- Producer 三种发送消息的方式。
- Producer 发送顺序消息,Consumer 顺序消费消息。
- Producer 发送定时消息。(暂不支持)
- Producer 批量发送消息。
- Producer 发送事务消息。
- Consumer 批量消费消息。
- Consumer 广播和集群消费消息。
胖友你就说,艿艿是不是很良心。😜
2. Spring-Kafka
在 Spring 生态中,提供了 Spring-Kafka 项目,让我们更简便的使用 Kafka 。其官网介绍如下:
The Spring for Apache Kafka (spring-kafka) project applies core Spring concepts to the development of Kafka-based messaging solutions.
Spring for Apache Kafka (spring-kafka) 项目将 Spring 核心概念应用于基于 Kafka 的消息传递解决方案的开发。It provides a "template" as a high-level abstraction for sending messages.
它提供了一个“模板”作为发送消息的高级抽象。It also provides support for Message-driven POJOs with @KafkaListener annotations and a "listener container".
它还通过 @KafkaListener 注解和“侦听器容器(listener container)”为消息驱动的 POJO 提供支持。These libraries promote the use of dependency injection and declarative.
这些库促进了依赖注入和声明的使用。In all of these cases, you will see similarities to the JMS support in the Spring Framework and RabbitMQ support in Spring AMQP.
在所有这些用例中,你将看到 Spring Framework 中的 JMS 支持,以及和 Spring AMQP 中的 RabbitMQ 支持的相似之处。
- 😈 注意,Spring-Kafka 是基于 Spring Message 来实现 Kafka 的发送端和接收端。
Features(功能特性)
- KafkaTemplate
- KafkaMessageListenerContainer
- @KafkaListener
- KafkaTransactionManager
spring-kafka-testjar with embedded kafka server(带嵌入式 Kafka 服务器的spring-kafka-testjar 包)
3. 快速入门
示例代码对应仓库:lab-31-kafka-demo 。
本小节,我们先来对 Kafka-Spring 做一个快速入门,实现 Producer 三种发送消息的方式的功能,同时创建一个 Consumer 消费消息。
考虑到一个应用既可以使用生产者 Producer ,又可以使用消费者 Consumer ,所以示例就做成一个 lab-31-kafka-demo 项目。
3.1 引入依赖
在 pom.xml 文件中,引入相关依赖。
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.2.1.RELEASE</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<modelVersion>4.0.0</modelVersion>
<artifactId>lab-03-kafka-demo</artifactId>
<dependencies>
<!-- 引入 Spring-Kafka 依赖 -->
<!-- 已经内置 kafka-clients 依赖,所以无需重复引入 -->
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
<version>2.3.3.RELEASE</version>
</dependency>
<!-- 实现对 JSON 的自动化配置 -->
<!-- 因为,Kafka 对复杂对象的 Message 序列化时,我们会使用到 JSON -->
<!--
同时,spring-boot-starter-json 引入了 spring-boot-starter ,而 spring-boot-starter 又引入了 spring-boot-autoconfigure 。
spring-boot-autoconfigure 实现了 Spring-Kafka 的自动化配置
-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-json</artifactId>
</dependency>
<!-- 方便等会写单元测试 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
</project>
- 具体每个依赖的作用,胖友自己认真看下艿艿添加的所有注释噢。
- 不过有点很奇怪的是,Spring Boot 已经提供了 Kafka 的自动化配置的支持,但是竟然没有提供 spring-boot-kafka-starter 包,有点神奇~
3.2 应用配置文件
在 resources 目录下,创建 application.yaml 配置文件。配置如下:
spring:
# Kafka 配置项,对应 KafkaProperties 配置类
kafka:
bootstrap-servers: 127.0.0.1:9092 # 指定 Kafka Broker 地址,可以设置多个,以逗号分隔
# Kafka Producer 配置项
producer:
acks: 1 # 0-不应答。1-leader 应答。all-所有 leader 和 follower 应答。
retries: 3 # 发送失败时,重试发送的次数
key-serializer: org.apache.kafka.common.serialization.StringSerializer # 消息的 key 的序列化
value-serializer: org.springframework.kafka.support.serializer.JsonSerializer # 消息的 value 的序列化
# Kafka Consumer 配置项
consumer:
auto-offset-reset: earliest # 设置消费者分组最初的消费进度为 earliest 。可参考博客 https://blog.csdn.net/lishuangzhe7047/article/details/74530417 理解
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.springframework.kafka.support.serializer.JsonDeserializer
properties:
spring:
json:
trusted:
packages: cn.iocoder.springboot.lab03.kafkademo.message
# Kafka Consumer Listener 监听器配置
listener:
missing-topics-fatal: false # 消费监听接口监听的主题不存在时,默认会报错。所以通过设置为 false ,解决报错
logging:
level:
org:
springframework:
kafka: ERROR # spring-kafka INFO 日志太多了,所以我们限制只打印 ERROR 级别
apache:
kafka: ERROR # kafka INFO 日志太多了,所以我们限制只打印 ERROR 级别
-
在
spring.kafka配置项,设置 Kafka 的配置,对应 KafkaProperties 配置类。 -
Spring Boot 提供的 KafkaAutoConfiguration 自动化配置类,实现 Kafka 的自动配置,创建相应的 Producer 和 Consumer 。
-
spring.kafka.bootstrap-servers配置项,设置 Kafka Broker 地址。如果多个,使用逗号分隔。 -
spring.kafka.producer配置项,一看就知道是 Kafka Producer 所独有。
value-serializer配置,我们使用了 Spring-Kafka 提供的 JsonSerializer 序列化类,因为稍后我们要使用 JSON 的方式,序列化复杂的 Message 消息。- 其它配置,一般默认即可。
-
spring.kafka.consumer配置项,一看就知道是 Kafka Consumer 所独有。
value-serializer配置,我们使用了 Spring-Kafka 提供的 JsonDeserializer 反序列化类,因为稍后我们要使用 JSON 的方式,反序列化复杂的 Message 消息。properties.spring.json.trusted.packages配置,配置信任cn.iocoder.springboot.lab03.kafkademo.message包下的 Message 类们。因为 JsonDeserializer 在反序列化消息时,考虑到安全性,只反序列化成信任的 Message 类。😈 想要尝试下效果的胖友,可以选择去掉这个配置,很酸爽。
3.3 Application
创建 Application.java 类,配置 @SpringBootApplication 注解即可。代码如下:
// Application.java
@SpringBootApplication
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
}
3.4 Demo01Message
在 cn.iocoder.springboot.lab03.kafkademo.message 包下,创建 Demo01Message 消息类,提供给当前示例使用。代码如下:
// Demo01Message.java
public class Demo01Message {
public static final String TOPIC = "DEMO_01";
/**
* 编号
*/
private Integer id;
// ... 省略 set/get/toString 方法
}
TOPIC静态属性,我们设置该消息类对应 Topic 为"DEMO_01"。
3.5 Demo01Producer
在 cn.iocoder.springboot.lab03.kafkademo.producer 包下,创建 Demo01Producer 类,它会使用 Kafka-Spring 封装提供的 KafkaTemplate ,实现三种发送消息的方式。代码如下:
// Demo01Producer.java
@Component
public class Demo01Producer {
@Resource
private KafkaTemplate<Object, Object> kafkaTemplate;
public SendResult syncSend(Integer id) throws ExecutionException, InterruptedException {
// 创建 Demo01Message 消息
Demo01Message message = new Demo01Message();
message.setId(id);
// 同步发送消息
return kafkaTemplate.send(Demo01Message.TOPIC, message).get();
}
public ListenableFuture<SendResult<Object, Object>> asyncSend(Integer id) {
// 创建 Demo01Message 消息
Demo01Message message = new Demo01Message();
message.setId(id);
// 异步发送消息
return kafkaTemplate.send(Demo01Message.TOPIC, message);
}
}
#asyncSend(...)方法,异步发送消息。在方法内部,会调用KafkaTemplate#send(topic, data)方法,异步发送消息,返回 Spring ListenableFuture 对象,一个可以通过监听执行结果的 Future 增强。#syncSend(...)方法,同步发送消息。在方法内部,也是调用KafkaTemplate#send(topic, data)方法,异步发送消息。不过,因为我们后面调用了 ListenableFuture 对象的#get()方法,阻塞等待发送结果,从而实现同步的效果。- 暂时未提供 oneway 发送消息的方式。因为需要配置 Producer 的
acks = 0,才可以使用这种发送方式。😈 当然,实际场景下,基本不会使用 oneway 的方式来发送消息,所以直接先忽略吧。
对于胖友来说,可能最关心的是,消息 Message 是怎么序列化的。
- 在序列化时,我们使用了 JsonSerializer 序列化 Message 消息对象,它会在 Kafka 消息 Headers 的
__TypeId__上,值为 Message 消息对应的类全名。 - 在反序列化时,我们使用了 JsonDeserializer 序列化出 Message 消息对象,它会根据 Kafka 消息 Headers 的
__TypeId__的值,反序列化消息内容成该 Message 对象。
3.6 Demo01Consumer
在 cn.iocoder.springboot.lab03.kafkademo.consumer 包下,创建 Demo01Consumer 类,消费消息。代码如下:
// Demo01Consumer.java
@Component
public class Demo01Consumer {
private Logger logger = LoggerFactory.getLogger(getClass());
@KafkaListener(topics = Demo01Message.TOPIC,
groupId = "demo01-consumer-group-" + Demo01Message.TOPIC)
public void onMessage(Demo01Message message) {
logger.info("[onMessage][线程编号:{} 消息内容:{}]", Thread.currentThread().getId(), message);
}
}
- 在方法上,添加了
@KafkaListener注解,声明消费的 Topic 是"DEMO_01",消费者分组是"demo01-consumer-group-DEMO_01"。一般情况下,我们建议一个消费者分组,仅消费一个 Topic 。这样做会有个好处:每个消费者分组职责单一,只消费一个 Topic 。 - 方法参数,使用消费 Topic 对应的消息类即可。这里,我们使用了 「3.4 Demo01Message」 。
- 虽然说,
@KafkaListener注解是方法级别的,艿艿还是建议一个类,对应一个方法,消费消息。😈 简单清晰~
3.7 Demo01AConsumer
在 cn.iocoder.springboot.lab03.kafkademo.consumer 包下,创建 Demo01AConsumer 类,消费消息。代码如下:
// Demo01AConsumer.java
@Component
public class Demo01AConsumer {
private Logger logger = LoggerFactory.getLogger(getClass());
@KafkaListener(topics = Demo01Message.TOPIC,
groupId = "demo01-A-consumer-group-" + Demo01Message.TOPIC)
public void onMessage(ConsumerRecord<Integer, String> record) {
logger.info("[onMessage][线程编号:{} 消息内容:{}]", Thread.currentThread().getId(), record);
}
}
- 整体和 「3.6 Demo01Consumer」 是一致的,主要有两个差异点,也是为什么我们又额外创建了这个消费者的原因。
差异一,在方法上,添加了 @KafkaListener 注解,声明消费的 Topic 还是 "DEMO_01" ,消费者分组修改成了 "demo01-A-consumer-group-DEMO_01" 。这样,我们就可以测试 Kafka 集群消费的特性。
集群消费(Clustering):集群消费模式下,相同 Consumer Group 的每个 Consumer 实例平均分摊消息。
- 也就是说,如果我们发送一条 Topic 为
"DEMO_01"的消息,可以分别被"demo01-A-consumer-group-DEMO_01"和"demo01-consumer-group-DEMO_01"都消费一次。 - 但是,如果我们启动两个该示例的实例,则消费者分组
"demo01-A-consumer-group-DEMO_01"和"demo01-consumer-group-DEMO_01"都会有多个 Consumer 示例。此时,我们再发送一条 Topic 为"DEMO_01"的消息,只会被"demo01-A-consumer-group-DEMO_01"的一个 Consumer 消费一次,也同样只会被"demo01-A-consumer-group-DEMO_01"的一个 Consumer 消费一次。
好好理解上述的两段话,非常重要。
通过集群消费的机制,我们可以实现针对相同 Topic ,不同消费者分组实现各自的业务逻辑。例如说:用户注册成功时,发送一条 Topic 为 "USER_REGISTER" 的消息。然后,不同模块使用不同的消费者分组,订阅该 Topic ,实现各自的拓展逻辑:
- 积分模块:判断如果是手机注册,给用户增加 20 积分。
- 优惠劵模块:因为是新用户,所以发放新用户专享优惠劵。
- 站内信模块:因为是新用户,所以发送新用户的欢迎语的站内信。
- ... 等等
这样,我们就可以将注册成功后的业务拓展逻辑,实现业务上的解耦,未来也更加容易拓展。同时,也提高了注册接口的性能,避免用户需要等待业务拓展逻辑执行完成后,才响应注册成功。
差异二,方法参数,设置消费的消息对应的类不是 Demo01Message 类,而是 Kafka 内置的 ConsumerRecord 类。通过 ConsumerRecord 类,我们可以获取到消费的消息的更多信息,例如说消息的所属队列、创建时间等等属性,不过消息的内容(value)就需要自己去反序列化。当然,一般情况下,我们不会使用 ConsumerRecord 类。
3.8 简单测试
创建 Demo01ProducerTest 测试类,编写二个单元测试方法,调用 Demo01Producer 二个发送消息的方式。代码如下:
@RunWith(SpringRunner.class)
@SpringBootTest(classes = Application.class)
public class Demo01ProducerTest {
private Logger logger = LoggerFactory.getLogger(getClass());
@Autowired
private Demo01Producer producer;
@Test
public void testSyncSend() throws ExecutionException, InterruptedException {
int id = (int) (System.currentTimeMillis() / 1000);
SendResult result = producer.syncSend(id);
logger.info("[testSyncSend][发送编号:[{}] 发送结果:[{}]]", id, result);
// 阻塞等待,保证消费
new CountDownLatch(1).await();
}
@Test
public void testASyncSend() throws InterruptedException {
int id = (int) (System.currentTimeMillis() / 1000);
producer.asyncSend(id).addCallback(new ListenableFutureCallback<SendResult<Object, Object>>() {
@Override
public void onFailure(Throwable e) {
logger.info("[testASyncSend][发送编号:[{}] 发送异常]]", id, e);
}
@Override
public void onSuccess(SendResult<Object, Object> result) {
logger.info("[testASyncSend][发送编号:[{}] 发送成功,结果为:[{}]]", id, result);
}
});
// 阻塞等待,保证消费
new CountDownLatch(1).await();
}
}
- 比较简单,胖友自己看下三个单元测试方法。
我们来执行 #testSyncSend() 方法,测试同步发送消息。控制台输出如下:
# Producer 同步发送消息成功。注意 __TypeId__
2019-12-08 18:14:11.174 INFO 89529 --- [ main] c.i.s.l.k.producer.Demo01ProducerTest : [testSyncSend][发送编号:[1575627250] 发送结果:[SendResult [producerRecord=ProducerRecord(topic=DEMO_01, partition=null, headers=RecordHeaders(headers = [RecordHeader(key = __TypeId__, value = [99, 110, 46, 105, 111, 99, 111, 100, 101, 114, 46, 115, 112, 114, 105, 110, 103, 98, 111, 111, 116, 46, 108, 97, 98, 48, 51, 46, 107, 97, 102, 107, 97, 100, 101, 109, 111, 46, 109, 101, 115, 115, 97, 103, 101, 46, 68, 101, 109, 111, 48, 49, 77, 101, 115, 115, 97, 103, 101])], isReadOnly = true), key=null, value=Demo01Message{id=1575627250}, timestamp=null), recordMetadata=DEMO_01-0@0]]]
# Demo01AConsumer 消费了一次该消息
2019-12-08 18:14:11.217 INFO 89529 --- [ntainer#0-0-C-1] c.i.s.l.k.consumer.Demo01AConsumer : [onMessage][线程编号:16 消息内容:ConsumerRecord(topic = DEMO_01, partition = 0, leaderEpoch = 0, offset = 0, CreateTime = 1575627251158, serialized key size = -1, serialized value size = 17, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = Demo01Message{id=1575627250})]
# Demo01Consumer 消费了一次该消息
2019-12-08 18:14:11.220 INFO 89529 --- [ntainer#1-0-C-1] c.i.s.l.k.consumer.Demo01Consumer : [onMessage][线程编号:18 消息内容:Demo01Message{id=1575627250}]
- 通过日志我们可以看到,我们发送的消息,分别被 Demo01AConsumer 和 Demo01Consumer 两个消费者(消费者分组)都消费了一次。
- 同时,两个消费者在不同的线程中,消费了这条消息。
我们来执行 #testASyncSend() 方法,测试异步发送消息。控制台输出如下:
友情提示:注意,不要关闭
#testSyncSend()单元测试方法,因为我们要模拟每个消费者集群,都有多个 Consumer 节点。
// Producer 异步发送消息成功
2019-12-08 18:20:34.096 INFO 89818 --- [ad | producer-1] c.i.s.l.k.producer.Demo01ProducerTest : [testASyncSend][发送编号:[1575627633] 发送成功,结果为:[SendResult [producerRecord=ProducerRecord(topic=DEMO_01, partition=null, headers=RecordHeaders(headers = [RecordHeader(key = __TypeId__, value = [99, 110, 46, 105, 111, 99, 111, 100, 101, 114, 46, 115, 112, 114, 105, 110, 103, 98, 111, 111, 116, 46, 108, 97, 98, 48, 51, 46, 107, 97, 102, 107, 97, 100, 101, 109, 111, 46, 109, 101, 115, 115, 97, 103, 101, 46, 68, 101, 109, 111, 48, 49, 77, 101, 115, 115, 97, 103, 101])], isReadOnly = true), key=null, value=Demo01Message{id=1575627633}, timestamp=null), recordMetadata=DEMO_01-0@2]]]
# Demo01AConsumer 消费了一次该消息
2019-12-08 18:20:34.139 INFO 89818 --- [ntainer#0-0-C-1] c.i.s.l.k.consumer.Demo01AConsumer : [onMessage][线程编号:16 消息内容:ConsumerRecord(topic = DEMO_01, partition = 0, leaderEpoch = 0, offset = 2, CreateTime = 1575627634079, serialized key size = -1, serialized value size = 17, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = Demo01Message{id=1575627633})
# Demo01Consumer 消费了一次该消息
2019-12-08 18:20:34.142 INFO 89818 --- [ntainer#1-0-C-1] c.i.s.l.k.consumer.Demo01Consumer : [onMessage][线程编号:18 消息内容:Demo01Message{id=1575627633}]
- 和
#testSyncSend()方法执行的结果,是一致的。此时,我们打开#testSyncSend()方法所在的控制台,不会看到有消息消费的日志。说明,符合集群消费的机制:集群消费模式下,相同 Consumer Group 的每个 Consumer 实例平均分摊消息。。 - 😈 不过如上的日志,也可能出现在
#testSyncSend()方法所在的控制台,而不在#testASyncSend()方法所在的控制台。
3.9 @KafkaListener
在 「3.6 Demo01Consumer」 中,我们已经使用了 @KafkaListener 注解,设置每个 Kafka 消费者 Consumer 的消息监听器的配置。
@KafkaListener 注解的常用属性如下:
/**
* 监听的 Topic 数组
*
* The topics for this listener.
* The entries can be 'topic name', 'property-placeholder keys' or 'expressions'.
* An expression must be resolved to the topic name.
* This uses group management and Kafka will assign partitions to group members.
* <p>
* Mutually exclusive with {@link #topicPattern()} and {@link #topicPartitions()}.
* @return the topic names or expressions (SpEL) to listen to.
*/
String[] topics() default {};
/**
* 监听的 Topic 表达式
*
* The topic pattern for this listener. The entries can be 'topic pattern', a
* 'property-placeholder key' or an 'expression'. The framework will create a
* container that subscribes to all topics matching the specified pattern to get
* dynamically assigned partitions. The pattern matching will be performed
* periodically against topics existing at the time of check. An expression must
* be resolved to the topic pattern (String or Pattern result types are supported).
* This uses group management and Kafka will assign partitions to group members.
* <p>
* Mutually exclusive with {@link #topics()} and {@link #topicPartitions()}.
* @return the topic pattern or expression (SpEL).
* @see org.apache.kafka.clients.CommonClientConfigs#METADATA_MAX_AGE_CONFIG
*/
String topicPattern() default "";
/**
* @TopicPartition 注解的数组。每个 @TopicPartition 注解,可配置监听的 Topic、队列、消费的开始位置
*
* The topicPartitions for this listener when using manual topic/partition
* assignment.
* <p>
* Mutually exclusive with {@link #topicPattern()} and {@link #topics()}.
* @return the topic names or expressions (SpEL) to listen to.
*/
TopicPartition[] topicPartitions() default {};
/**
* 消费者分组
* Override the {@code group.id} property for the consumer factory with this value
* for this listener only.
* <p>SpEL {@code #{...}} and property place holders {@code ${...}} are supported.
* @return the group id.
* @since 1.3
*/
String groupId() default "";
/**
* 使用消费异常处理器 KafkaListenerErrorHandler 的 Bean 名字
*
* Set an {@link org.springframework.kafka.listener.KafkaListenerErrorHandler} bean
* name to invoke if the listener method throws an exception.
* @return the error handler.
* @since 1.3
*/
String errorHandler() default "";
/**
* 自定义消费者监听器的并发数,这个我们在 TODO 详细解析。
*
* Override the container factory's {@code concurrency} setting for this listener. May
* be a property placeholder or SpEL expression that evaluates to a {@link Number}, in
* which case {@link Number#intValue()} is used to obtain the value.
* <p>SpEL {@code #{...}} and property place holders {@code ${...}} are supported.
* @return the concurrency.
* @since 2.2
*/
String concurrency() default "";
/**
* 是否自动启动监听器。默认情况下,为 true 自动启动。
*
* Set to true or false, to override the default setting in the container factory. May
* be a property placeholder or SpEL expression that evaluates to a {@link Boolean} or
* a {@link String}, in which case the {@link Boolean#parseBoolean(String)} is used to
* obtain the value.
* <p>SpEL {@code #{...}} and property place holders {@code ${...}} are supported.
* @return true to auto start, false to not auto start.
* @since 2.2
*/
String autoStartup() default "";
/**
* Kafka Consumer 拓展属性。
*
* Kafka consumer properties; they will supersede any properties with the same name
* defined in the consumer factory (if the consumer factory supports property overrides).
* <h3>Supported Syntax</h3>
* <p>The supported syntax for key-value pairs is the same as the
* syntax defined for entries in a Java
* {@linkplain java.util.Properties#load(java.io.Reader) properties file}:
* <ul>
* <li>{@code key=value}</li>
* <li>{@code key:value}</li>
* <li>{@code key value}</li>
* </ul>
* {@code group.id} and {@code client.id} are ignored.
* @return the properties.
* @since 2.2.4
* @see org.apache.kafka.clients.consumer.ConsumerConfig
* @see #groupId()
* @see #clientIdPrefix()
*/
String[] properties() default {};
@KafkaListener 注解的不常用属性如下:
/**
* 唯一标识
*
* The unique identifier of the container managing for this endpoint.
* <p>If none is specified an auto-generated one is provided.
* <p>Note: When provided, this value will override the group id property
* in the consumer factory configuration, unless {@link #idIsGroup()}
* is set to false.
* <p>SpEL {@code #{...}} and property place holders {@code ${...}} are supported.
* @return the {@code id} for the container managing for this endpoint.
* @see org.springframework.kafka.config.KafkaListenerEndpointRegistry#getListenerContainer(String)
*/
String id() default "";
/**
* id 唯一标识的前缀
*
* When provided, overrides the client id property in the consumer factory
* configuration. A suffix ('-n') is added for each container instance to ensure
* uniqueness when concurrency is used.
* <p>SpEL {@code #{...}} and property place holders {@code ${...}} are supported.
* @return the client id prefix.
* @since 2.1.1
*/
String clientIdPrefix() default "";
/**
* 当 groupId 未设置时,是否使用 id 作为 groupId
*
* When {@link #groupId() groupId} is not provided, use the {@link #id() id} (if
* provided) as the {@code group.id} property for the consumer. Set to false, to use
* the {@code group.id} from the consumer factory.
* @return false to disable.
* @since 1.3
*/
boolean idIsGroup() default true;
/**
* 使用的 KafkaListenerContainerFactory Bean 的名字。
* 若未设置,则使用默认的 KafkaListenerContainerFactory Bean 。
*
* The bean name of the {@link org.springframework.kafka.config.KafkaListenerContainerFactory}
* to use to create the message listener container responsible to serve this endpoint.
* <p>If not specified, the default container factory is used, if any.
* @return the container factory bean name.
*/
String containerFactory() default "";
/**
* 所属 MessageListenerContainer Bean 的名字。
*
* If provided, the listener container for this listener will be added to a bean
* with this value as its name, of type {@code Collection<MessageListenerContainer>}.
* This allows, for example, iteration over the collection to start/stop a subset
* of containers.
* <p>SpEL {@code #{...}} and property place holders {@code ${...}} are supported.
* @return the bean name for the group.
*/
String containerGroup() default "";
/**
* 真实监听容器的 Bean 名字,需要在名字前加 "__" 。
*
* A pseudo bean name used in SpEL expressions within this annotation to reference
* the current bean within which this listener is defined. This allows access to
* properties and methods within the enclosing bean.
* Default '__listener'.
* <p>
* Example: {@code topics = "#{__listener.topicList}"}.
* @return the pseudo bean name.
* @since 2.1.2
*/
String beanRef() default "__listener";
@TopicPartition注解@PartitionOffset注解@KafkaListeners注解,允许我们在其中,同时添加多个@KafkaListener注解。
4. 批量发送消息
示例代码对应仓库:lab-03-kafka-demo-batch 。
在一些业务场景下,我们希望使用 Producer 批量发送消息,提高发送性能。不同于我们在《芋道 Spring Boot 消息队列 RocketMQ 入门》 的「4. 批量发送消息」 功能,RocketMQ 是提供了一个可以批量发送多条消息的 API 。而 Kafka 提供的批量发送消息,它提供了一个 RecordAccumulator 消息收集器,将发送给相同 Topic 的相同 Partition 分区的消息们,“偷偷”收集在一起,当满足条件时候,一次性批量发送提交给 Kafka Broker 。如下是三个条件,满足任一即会批量发送:
- 【数量】
batch-size:超过收集的消息数量的最大条数。 - 【空间】
buffer-memory:超过收集的消息占用的最大内存。 - 【时间】
linger.ms:超过收集的时间的最大等待时长,单位:毫秒。
下面,我们来实现一个 Producer 批量发送消息的示例。考虑到不污染「3. 快速入门」 的示例,我们新建一个 lab-03-kafka-demo-batch 项目。
4.1 引入依赖
4.2 应用配置文件
在 resources 目录下,创建 application.yaml 配置文件。配置如下:
spring:
# Kafka 配置项,对应 KafkaProperties 配置类
kafka:
bootstrap-servers: 127.0.0.1:9092 # 指定 Kafka Broker 地址,可以设置多个,以逗号分隔
# Kafka Producer 配置项
producer:
acks: 1 # 0-不应答。1-leader 应答。all-所有 leader 和 follower 应答。
retries: 3 # 发送失败时,重试发送的次数
key-serializer: org.apache.kafka.common.serialization.StringSerializer # 消息的 key 的序列化
value-serializer: org.springframework.kafka.support.serializer.JsonSerializer # 消息的 value 的序列化
batch-size: 16384 # 每次批量发送消息的最大数量
buffer-memory: 33554432 # 每次批量发送消息的最大内存
properties:
linger:
ms: 30000 # 批处理延迟时间上限。这里配置为 30 * 1000 ms 过后,不管是否消息数量是否到达 batch-size 或者消息大小到达 buffer-memory 后,都直接发送一次请求。
# Kafka Consumer 配置项
consumer:
auto-offset-reset: earliest # 设置消费者分组最初的消费进度为 earliest 。可参考博客 https://blog.csdn.net/lishuangzhe7047/article/details/74530417 理解
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.springframework.kafka.support.serializer.JsonDeserializer
properties:
spring:
json:
trusted:
packages: cn.iocoder.springboot.lab03.kafkademo.message
# Kafka Consumer Listener 监听器配置
listener:
missing-topics-fatal: false # 消费监听接口监听的主题不存在时,默认会报错。所以通过设置为 false ,解决报错
logging:
level:
org:
springframework:
kafka: ERROR # spring-kafka INFO 日志太多了,所以我们限制只打印 ERROR 级别
apache:
kafka: ERROR # kafka INFO 日志太多了,所以我们限制只打印 ERROR 级别
-
相比
「3.2 应用配置文件」
来说,额外三个参数,就是我们说的 Producer 批量发送的三个条件:
spring.kafka.producer.batch-sizespring.kafka.producer.buffer-memoryspring.kafka.producer.properties.linger.ms
-
具体的数值配置多少,根据自己的应用来。这里,我们故意将
linger.ms配置成了 30 秒,主要为了演示之用。
4.3 Demo02Message
在 cn.iocoder.springboot.lab03.kafkademo.message 包下,创建 Demo02Message 消息类,提供给当前示例使用。代码如下:
// Demo02Message.java
public class Demo02Message {
public static final String TOPIC = "DEMO_012";
/**
* 编号
*/
private Integer id;
// ... 省略 set/get/toString 方法
}
TOPIC静态属性,我们设置该消息类对应 Topic 为"DEMO_02"。- 其它都和 「3.4 Demo01Message」 是一样的。
4.4 Demo02Producer
在 cn.iocoder.springboot.lab03.kafkademo.producer 包下,创建 Demo02Producer 类,它会使用 Kafka-Spring 封装提供的 KafkaTemplate ,实现一个异步发送消息的方法。代码如下:
// Demo02Producer.java
@Component
public class Demo02Producer {
@Resource
private KafkaTemplate<Object, Object> kafkaTemplate;
public ListenableFuture<SendResult<Object, Object>> asyncSend(Integer id) {
// 创建 Demo02Message 消息
Demo02Message message = new Demo02Message();
message.setId(id);
// 异步发送消息
return kafkaTemplate.send(Demo02Message.TOPIC, message);
}
}
- 看起来和我们在「3.5 Demo01Producer」提供的异步发送消息的方法,除了换成了 Demo02Message 消息对象,其它都是一模一样的。😈 对的,这也是为什么艿艿在上文说到,Kafka 是“偷偷”收集来实现批量发送,对于我们使用发送消息的方法,还是一致的。
- 因为我们发送的消息 Topic 是自动创建的,所以其 Partition 分区大小是 1 。这样,就能保证我每次调用这个方法,满足批量发送消息的一个前提,相同 Topic 的相同 Partition 分区的消息们。
4.5 Demo02Consumer
在 cn.iocoder.springboot.lab03.kafkademo.consumer 包下,创建 Demo02Consumer 类,消费消息。代码如下:
// Demo02Consumer.java
@Component
public class Demo02Consumer {
private Logger logger = LoggerFactory.getLogger(getClass());
@KafkaListener(topics = Demo02Message.TOPIC,
groupId = "demo02-consumer-group-" + Demo02Message.TOPIC)
public void onMessage(Demo02Message message) {
logger.info("[onMessage][线程编号:{} 消息内容:{}]", Thread.currentThread().getId(), message);
}
}
- 和「3.6 Demo01Consumer」基本一直,除了是不同的消费者分组,消费了不同的 Topic 。
4.6 简单测试
创建 Demo02ProducerTest 测试类,编写单元测试方法,测试 Producer 批量发送消息的效果。代码如下:
// Demo02ProducerTest.java
@RunWith(SpringRunner.class)
@SpringBootTest(classes = Application.class)
public class Demo02ProducerTest {
private Logger logger = LoggerFactory.getLogger(getClass());
@Autowired
private Demo02Producer producer;
@Test
public void testASyncSend() throws InterruptedException {
logger.info("[testASyncSend][开始执行]");
for (int i = 0; i < 3; i++) {
int id = (int) (System.currentTimeMillis() / 1000);
producer.asyncSend(id).addCallback(new ListenableFutureCallback<SendResult<Object, Object>>() {
@Override
public void onFailure(Throwable e) {
logger.info("[testASyncSend][发送编号:[{}] 发送异常]]", id, e);
}
@Override
public void onSuccess(SendResult<Object, Object> result) {
logger.info("[testASyncSend][发送编号:[{}] 发送成功,结果为:[{}]]", id, result);
}
});
// 故意每条消息之间,隔离 10 秒
Thread.sleep(10 * 1000L);
}
// 阻塞等待,保证消费
new CountDownLatch(1).await();
}
}
- 异步发送三条消息,每次发送消息之间,都故意 sleep 10 秒。😈 目的是,恰好满足我们配置的
linger.ms最大等待时长。
我们来执行 #testASyncSend() 方法,测试批量发送消息。控制台输出如下:
# 打印 testASyncSend 方法开始执行的日志
2019-12-08 21:43:02.330 INFO 94957 --- [ main] c.i.s.l.k.producer.Demo02ProducerTest : [testASyncSend][开始执行]
# 30 秒后,满足批量消息的最大等待时长,所以 3 条消息被 Producer 批量发送。
# 因此我们配置的是 acks=1 ,需要等待发送成功后,才会回调 ListenableFutureCallback 的方法。
2019-12-08 21:43:32.424 INFO 94957 --- [ad | producer-1] c.i.s.l.k.producer.Demo02ProducerTest : [testASyncSend][发送编号:[1575639782] 发送成功,结果为:[SendResult [producerRecord=ProducerRecord(topic=DEMO_02, partition=null, headers=RecordHeaders(headers = [RecordHeader(key = __TypeId__, value = [99, 110, 46, 105, 111, 99, 111, 100, 101, 114, 46, 115, 112, 114, 105, 110, 103, 98, 111, 111, 116, 46, 108, 97, 98, 48, 51, 46, 107, 97, 102, 107, 97, 100, 101, 109, 111, 46, 109, 101, 115, 115, 97, 103, 101, 46, 68, 101, 109, 111, 48, 50, 77, 101, 115, 115, 97, 103, 101])], isReadOnly = true), key=null, value=Demo01Message{id=1575639782}, timestamp=null), recordMetadata=DEMO_02-0@37]]]
2019-12-08 21:43:32.425 INFO 94957 --- [ad | producer-1] c.i.s.l.k.producer.Demo02ProducerTest : [testASyncSend][发送编号:[1575639792] 发送成功,结果为:[SendResult [producerRecord=ProducerRecord(topic=DEMO_02, partition=null, headers=RecordHeaders(headers = [RecordHeader(key = __TypeId__, value = [99, 110, 46, 105, 111, 99, 111, 100, 101, 114, 46, 115, 112, 114, 105, 110, 103, 98, 111, 111, 116, 46, 108, 97, 98, 48, 51, 46, 107, 97, 102, 107, 97, 100, 101, 109, 111, 46, 109, 101, 115, 115, 97, 103, 101, 46, 68, 101, 109, 111, 48, 50, 77, 101, 115, 115, 97, 103, 101])], isReadOnly = true), key=null, value=Demo01Message{id=1575639792}, timestamp=null), recordMetadata=DEMO_02-0@38]]]
2019-12-08 21:43:32.425 INFO 94957 --- [ad | producer-1] c.i.s.l.k.producer.Demo02ProducerTest : [testASyncSend][发送编号:[1575639802] 发送成功,结果为:[SendResult [producerRecord=ProducerRecord(topic=DEMO_02, partition=null, headers=RecordHeaders(headers = [RecordHeader(key = __TypeId__, value = [99, 110, 46, 105, 111, 99, 111, 100, 101, 114, 46, 115, 112, 114, 105, 110, 103, 98, 111, 111, 116, 46, 108, 97, 98, 48, 51, 46, 107, 97, 102, 107, 97, 100, 101, 109, 111, 46, 109, 101, 115, 115, 97, 103, 101, 46, 68, 101, 109, 111, 48, 50, 77, 101, 115, 115, 97, 103, 101])], isReadOnly = true), key=null, value=Demo01Message{id=1575639802}, timestamp=null), recordMetadata=DEMO_02-0@39]]]
# 因为 Producer 批量发送完成,所以 Demo02Consumer 消费到消息
2019-12-08 21:43:32.475 INFO 94957 --- [ntainer#0-0-C-1] c.i.s.l.k.consumer.Demo02Consumer : [onMessage][线程编号:16 消息内容:Demo01Message{id=1575639782}]
2019-12-08 21:43:32.475 INFO 94957 --- [ntainer#0-0-C-1] c.i.s.l.k.consumer.Demo02Consumer : [onMessage][线程编号:16 消息内容:Demo01Message{id=1575639792}]
2019-12-08 21:43:32.475 INFO 94957 --- [ntainer#0-0-C-1] c.i.s.l.k.consumer.Demo02Consumer : [onMessage][线程编号:16 消息内容:Demo01Message{id=1575639802}]
- 😈 胖友认真看下艿艿在日志中的注释,理解下整个批量发送消息的过程。不过还是那句话,实际场景下,我们不太会把
linger.ms配置的这么长时间,这里仅仅是演示。
5. 批量消费消息
示例代码对应仓库:lab-03-kafka-demo-batch-consume 。
在一些业务场景下,我们希望使用 Consumer 批量消费消息,提高消费速度。要注意,Consumer 的批量消费消息,和 Producer 的「4. 批量发送消息」 没有直接关联哈。
下面,我们来实现一个 Consumer 批量消费消息的示例。考虑到不污染「4. 批量发送消息」 的示例,我们在 lab-03-kafka-demo-batch 项目的基础上,复制出一个 lab-03-kafka-demo-batch-consume 项目。😈 酱紫,我们也能少写点代码,哈哈哈~
5.1 应用配置文件
修改 application.yaml 配置文件。配置如下:
spring:
# Kafka 配置项,对应 KafkaProperties 配置类
kafka:
bootstrap-servers: 127.0.0.1:9092 # 指定 Kafka Broker 地址,可以设置多个,以逗号分隔
# Kafka Producer 配置项
producer:
acks: 1 # 0-不应答。1-leader 应答。all-所有 leader 和 follower 应答。
retries: 3 # 发送失败时,重试发送的次数
key-serializer: org.apache.kafka.common.serialization.StringSerializer # 消息的 key 的序列化
value-serializer: org.springframework.kafka.support.serializer.JsonSerializer # 消息的 value 的序列化
batch-size: 16384 # 每次批量发送消息的最大数量
buffer-memory: 33554432 # 每次批量发送消息的最大内存
properties:
linger:
ms: 30000 # 批处理延迟时间上限。这里配置为 30 * 1000 ms 过后,不管是否消息数量是否到达 batch-size 或者消息大小到达 buffer-memory 后,都直接发送一次请求。
# Kafka Consumer 配置项
consumer:
auto-offset-reset: earliest # 设置消费者分组最初的消费进度为 earliest 。可参考博客 https://blog.csdn.net/lishuangzhe7047/article/details/74530417 理解
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.springframework.kafka.support.serializer.JsonDeserializer
fetch-max-wait: 10000 # poll 一次拉取的阻塞的最大时长,单位:毫秒。这里指的是阻塞拉取需要满足至少 fetch-min-size 大小的消息
fetch-min-size: 10 # poll 一次消息拉取的最小数据量,单位:字节
max-poll-records: 100 # poll 一次消息拉取的最大数量
properties:
spring:
json:
trusted:
packages: cn.iocoder.springboot.lab03.kafkademo.message
# Kafka Consumer Listener 监听器配置
listener:
type: BATCH # 监听器类型,默认为 SINGLE ,只监听单条消息。这里我们配置 BATCH ,监听多条消息,批量消费
missing-topics-fatal: false # 消费监听接口监听的主题不存在时,默认会报错。所以通过设置为 false ,解决报错
logging:
level:
org:
springframework:
kafka: ERROR # spring-kafka INFO 日志太多了,所以我们限制只打印 ERROR 级别
apache:
kafka: ERROR # kafka INFO 日志太多了,所以我们限制只打印 ERROR 级别
-
相比
「3.2 应用配置文件」
来说,增加了四个配置项,胖友自己根据注释,自己理解下噢。
spring.kafka.listener.typespring.kafka.consumer.max-poll-recordsspring.kafka.consumer.fetch-min-sizespring.kafka.consumer.fetch-max-wait
5.2 Demo02Consumer
修改 Demo02Consumer 消费者,改成批量消费消息。代码如下:
// Demo02Consumer.java
@Component
public class Demo02Consumer {
private Logger logger = LoggerFactory.getLogger(getClass());
@KafkaListener(topics = Demo02Message.TOPIC,
groupId = "demo02-consumer-group-" + Demo02Message.TOPIC)
public void onMessage(List<Demo02Message> messages) {
logger.info("[onMessage][线程编号:{} 消息数量:{}]", Thread.currentThread().getId(), messages.size());
}
}
- 相比「4.5 Demo02Consumer」来说,方法上的参数变成了 List 数组。
5.3 简单测试
还是使用 Demo02ProducerTest 测试类,执行单元测试,输出日志如下:
2019-12-08 23:00:14.274 INFO 98637 --- [ main] c.i.s.l.k.producer.Demo02ProducerTest : [testASyncSend][开始执行]
2019-12-08 23:00:44.385 INFO 98637 --- [ad | producer-1] c.i.s.l.k.producer.Demo02ProducerTest : [testASyncSend][发送编号:[1575644414] 发送成功,结果为:[SendResult [producerRecord=ProducerRecord(topic=DEMO_02, partition=null, headers=RecordHeaders(headers = [RecordHeader(key = __TypeId__, value = [99, 110, 46, 105, 111, 99, 111, 100, 101, 114, 46, 115, 112, 114, 105, 110, 103, 98, 111, 111, 116, 46, 108, 97, 98, 48, 51, 46, 107, 97, 102, 107, 97, 100, 101, 109, 111, 46, 109, 101, 115, 115, 97, 103, 101, 46, 68, 101, 109, 111, 48, 50, 77, 101, 115, 115, 97, 103, 101])], isReadOnly = true), key=null, value=Demo01Message{id=1575644414}, timestamp=null), recordMetadata=DEMO_02-0@55]]]
2019-12-08 23:00:44.386 INFO 98637 --- [ad | producer-1] c.i.s.l.k.producer.Demo02ProducerTest : [testASyncSend][发送编号:[1575644424] 发送成功,结果为:[SendResult [producerRecord=ProducerRecord(topic=DEMO_02, partition=null, headers=RecordHeaders(headers = [RecordHeader(key = __TypeId__, value = [99, 110, 46, 105, 111, 99, 111, 100, 101, 114, 46, 115, 112, 114, 105, 110, 103, 98, 111, 111, 116, 46, 108, 97, 98, 48, 51, 46, 107, 97, 102, 107, 97, 100, 101, 109, 111, 46, 109, 101, 115, 115, 97, 103, 101, 46, 68, 101, 109, 111, 48, 50, 77, 101, 115, 115, 97, 103, 101])], isReadOnly = true), key=null, value=Demo01Message{id=1575644424}, timestamp=null), recordMetadata=DEMO_02-0@56]]]
2019-12-08 23:00:44.387 INFO 98637 --- [ad | producer-1] c.i.s.l.k.producer.Demo02ProducerTest : [testASyncSend][发送编号:[1575644434] 发送成功,结果为:[SendResult [producerRecord=ProducerRecord(topic=DEMO_02, partition=null, headers=RecordHeaders(headers = [RecordHeader(key = __TypeId__, value = [99, 110, 46, 105, 111, 99, 111, 100, 101, 114, 46, 115, 112, 114, 105, 110, 103, 98, 111, 111, 116, 46, 108, 97, 98, 48, 51, 46, 107, 97, 102, 107, 97, 100, 101, 109, 111, 46, 109, 101, 115, 115, 97, 103, 101, 46, 68, 101, 109, 111, 48, 50, 77, 101, 115, 115, 97, 103, 101])], isReadOnly = true), key=null, value=Demo01Message{id=1575644434}, timestamp=null), recordMetadata=DEMO_02-0@57]]]
# 批量消费了 3 条消息
2019-12-08 23:00:44.425 INFO 98637 --- [ntainer#0-0-C-1] c.i.s.l.k.consumer.Demo02Consumer : [onMessage][线程编号:16 消息数量:3]
- 从日志中,我们可以看出,发送的 3 条消息被 Demo02Consumer 批量消费了。
- 😈 为了更好的做对比,胖友可以尝试自行把配置改成
spring.kafka.listener.type=SINGLE,就会发现 Demo02Consumer 只会单条消费了。
6. 定时消息
Kafka 并未提供定时消息的功能,需要我们自行拓展。
例如说《基于 Kafka 的定时消息/任务服》文章,提供的方案。
当然,也可以考虑基于 MySQL 存储定时消息,Job 扫描到达时间的定时消息,发送给 Kafka 。
7. 消费重试
示例代码对应仓库:lab-31-kafka-demo 。
Spring-Kafka 提供消费重试的机制。在消息消费失败的时候,Spring-Kafka 会通过消费重试机制,重新投递该消息给 Consumer ,让 Consumer 有机会重新消费消息,实现消费成功。
当然,Spring-Kafka 并不会无限重新投递消息给 Consumer 重新消费,而是在默认情况下,达到 N 次重试次数时,Consumer 还是消费失败时,该消息就会进入到死信队列。
死信队列用于处理无法被正常消费的消息。当一条消息初次消费失败,Spring-Kafka 会自动进行消息重试;达到最大重试次数后,若消费依然失败,则表明消费者在正常情况下无法正确地消费该消息,此时,Spring-Kafka 不会立刻将消息丢弃,而是将其发送到该消费者对应的特殊队列中。
Spring-Kafka 将这种正常情况下无法被消费的消息称为死信消息(Dead-Letter Message),将存储死信消息的特殊队列称为死信队列(Dead-Letter Queue)。后续,我们可以通过对死信队列中的消息进行重发,来使得消费者实例再次进行消费。
- 在《芋道 Spring Boot 消息队列 RocketMQ 入门》的「6. 消费重试」小节中,我们可以看到,消费重试和死信队列,是 RocketMQ 自带的功能。
- 而在 Kafka 中,消费重试和死信队列,是由 Spring-Kafka 所封装提供的。
每条消息的失败重试,是可以配置一定的间隔时间。具体,我们在示例的代码中,来进行具体的解释。
下面,我们开始本小节的示例。该示例,我们会在「3. 快速入门」的 lab-31-kafka-demo 项目中,继续改造。
7.1 KafkaConfiguration
在 cn.iocoder.springboot.lab03.kafkademo.config 包下,创建 KafkaConfiguration 配置类,增加消费异常的 ErrorHandler 处理器 。代码如下:
// KafkaConfiguration.java
@Configuration
public class KafkaConfiguration {
@Bean
@Primary
public ErrorHandler kafkaErrorHandler(KafkaTemplate<?, ?> template) {
// <1> 创建 DeadLetterPublishingRecoverer 对象
ConsumerRecordRecoverer recoverer = new DeadLetterPublishingRecoverer(template);
// <2> 创建 FixedBackOff 对象
BackOff backOff = new FixedBackOff(10 * 1000L, 3L);
// <3> 创建 SeekToCurrentErrorHandler 对象
return new SeekToCurrentErrorHandler(recoverer, backOff);
}
}
-
Spring-Kafka 的消费重试功能,通过实现自定义的
SeekToCurrentErrorHandler
,在 Consumer 消费消息异常的时候,进行拦截处理:
- 在重试小于最大次数时,重新投递该消息给 Consumer ,让 Consumer 有机会重新消费消息,实现消费成功。
- 在重试到达最大次数时,Consumer 还是消费失败时,该消息就会发送到死信队列。例如说,本小节我们测试的 Topic 是
"DEMO_04",则其对应的死信队列的 Topic 就是"DEMO_04.DLT",即在原有 Topic 加上.DLT后缀,就是其死信队列的 Topic 。
-
<1>处,创建 DeadLetterPublishingRecoverer 对象,它负责实现,在重试到达最大次数时,Consumer 还是消费失败时,该消息就会发送到死信队列。 -
<2>处,创建 FixedBackOff 对象。这里,我们配置了重试 3 次,每次固定间隔 30 秒。当然,胖友可以选择 BackOff 的另一个子类 ExponentialBackOff 实现,提供指数递增的间隔时间。 -
<3>处,创建 SeekToCurrentErrorHandler 对象,负责处理异常,串联整个消费重试的整个过程。
这里,我们来简单说说 SeekToCurrentErrorHandler 是怎么提供消费重试的功能的。
-
在消息消费失败时,SeekToCurrentErrorHandler 会将 调用 Kafka Consumer 的
#seek(TopicPartition partition, long offset)方法,将 Consumer 对于该消息对应的 TopicPartition 分区的本地进度设置成该消息的位置。这样,Consumer 在下次从 Kafka Broker 拉取消息的时候,又能重新拉取到这条消费失败的消息,并且是第一条。 -
同时,Spring-Kafka 使用 FailedRecordTracker 对每个 Topic 的每个 TopicPartition 消费失败次数进行计数,这样相当于对该 TopicPartition 的第一条消费失败的消息的消费失败次数进行计数。😈 这里,胖友好好思考下,结合艿艿在上一点的描述。
-
另外,在 FailedRecordTracker 中,会调用 BackOff 来进行计算,该消息的下一次重新消费的时间,通过
Thread#sleep(...)方法,实现重新消费的时间间隔。 -
有一点需要注意,FailedRecordTracker 提供的计数是客户端级别的,重启 JVM 应用后,计数是会丢失的。所以,如果想要计数进行持久化,需要自己重新实现下 FailedRecordTracker 类,通过 ZooKeeper 存储计数。
😈 RocketMQ 提供的消费重试的计数,目前是服务端级别,已经进行持久化。
对了,SeekToCurrentErrorHandler 是只针对消息的单条消费失败的消费重试处理。如果胖友想要有消息的批量消费失败的消费重试处理,可以使用 SeekToCurrentBatchErrorHandler 。配置方式如下:
@Bean
@Primary
public BatchErrorHandler kafkaBatchErrorHandler() {
// 创建 SeekToCurrentBatchErrorHandler 对象
SeekToCurrentBatchErrorHandler batchErrorHandler = new SeekToCurrentBatchErrorHandler();
// 创建 FixedBackOff 对象
BackOff backOff = new FixedBackOff(10 * 1000L, 3L);
batchErrorHandler.setBackOff(backOff);
// 返回
return batchErrorHandler;
}
- 从代码中我们可以看到,并没有设置 DeadLetterPublishingRecoverer 对象。因为 SeekToCurrentBatchErrorHandler 暂时不支持死信队列的机制。
另外,如果胖友想要自定义 ErrorHandler 或 BatchErrorHandler 实现类,实现对消费异常的自定义的逻辑,也是可以的。
- 实现的代码的示例,可以参考 LoggingErrorHandler 类。
- 配置的方式,和本小节配置 SeekToCurrentErrorHandler 或 SeekToCurrentBatchErrorHandler 是一样的。
- 当然,绝大多数情况下,我们使用 SeekToCurrentErrorHandler 或 SeekToCurrentBatchErrorHandler 是足够的。
艿艿:貌似本小节信息量,略微有一点点大,胖友可以自己好好消化下。同时,也可以调试下整个过程涉及到的源码,更加具象下。「源码之前,了无秘密」。
7.2 Demo04Message
在 cn.iocoder.springboot.lab03.kafkademo.message 包下,创建 Demo04Message 消息类,提供给当前示例使用。代码如下:
// Demo04Message.java
public class Demo04Message {
public static final String TOPIC = "DEMO_04";
/**
* 编号
*/
private Integer id;
// ... 省略 set/get/toString 方法
}
TOPIC静态属性,我们设置该消息类对应 Topic 为"DEMO_04"。
7.3 Demo04Producer
在 cn.iocoder.springboot.lab03.kafkademo.producer 包下,创建 Demo04Producer 类,它会使用 Kafka-Spring 封装提供的 KafkaTemplate ,同步发送消息。代码如下:
// Demo04Producer.java
@Component
public class Demo04Producer {
@Resource
private KafkaTemplate<Object, Object> kafkaTemplate;
public SendResult syncSend(Integer id) throws ExecutionException, InterruptedException {
// 创建 Demo04Message 消息
Demo04Message message = new Demo04Message();
message.setId(id);
// 同步发送消息
return kafkaTemplate.send(Demo04Message.TOPIC, message).get();
}
}
- 和「3.5 Demo01Producer」的同步发送消息的代码是一致的,就是换成了 Demo04Message 。
7.4 Demo04Consumer
在 cn.iocoder.springboot.lab03.kafkademo.consumer 包下,创建 Demo04Consumer 类,消费消息。代码如下:
// Demo04Consumer.java
@Component
public class Demo04Consumer {
private AtomicInteger count = new AtomicInteger(0);
private Logger logger = LoggerFactory.getLogger(getClass());
@KafkaListener(topics = Demo04Message.TOPIC,
groupId = "demo04-consumer-group-" + Demo04Message.TOPIC)
public void onMessage(Demo04Message message) {
logger.info("[onMessage][线程编号:{} 消息内容:{}]", Thread.currentThread().getId(), message);
// <X> 注意,此处抛出一个 RuntimeException 异常,模拟消费失败
throw new RuntimeException("我就是故意抛出一个异常");
}
}
- 在
<X>处,我们在消费消息时候,抛出一个 RuntimeException 异常,模拟消费失败。
7.5 简单测试
创建 Demo04ProducerTest 测试类,编写一个单元测试方法,调用 Demo04Producer 同步发送消息。代码如下:
// Demo04ProducerTest.java
@RunWith(SpringRunner.class)
@SpringBootTest(classes = Application.class)
public class Demo04ProducerTest {
private Logger logger = LoggerFactory.getLogger(getClass());
@Autowired
private Demo04Producer producer;
@Test
public void testSyncSend() throws ExecutionException, InterruptedException {
int id = (int) (System.currentTimeMillis() / 1000);
SendResult result = producer.syncSend(id);
logger.info("[testSyncSend][发送编号:[{}] 发送结果:[{}]]", id, result);
// 阻塞等待,保证消费
new CountDownLatch(1).await();
}
}
我们来执行 #testSyncSend() 方法,同步发送消息。控制台输出如下:
# Producer 同步发送消息成功
2019-12-07 10:24:18.851 INFO 11359 --- [ main] c.i.s.l.k.producer.Demo04ProducerTest : [testSyncSend][发送编号:[1575685458] 发送结果:[SendResult [producerRecord=ProducerRecord(topic=DEMO_04, partition=null, headers=RecordHeaders(headers = [RecordHeader(key = __TypeId__, value = [99, 110, 46, 105, 111, 99, 111, 100, 101, 114, 46, 115, 112, 114, 105, 110, 103, 98, 111, 111, 116, 46, 108, 97, 98, 48, 51, 46, 107, 97, 102, 107, 97, 100, 101, 109, 111, 46, 109, 101, 115, 115, 97, 103, 101, 46, 68, 101, 109, 111, 48, 52, 77, 101, 115, 115, 97, 103, 101])], isReadOnly = true), key=null, value=Demo04Message{id=1575685458}, timestamp=null), recordMetadata=DEMO_04-0@0]]]
# Consumer04 首次消费
2019-12-07 10:24:18.918 INFO 11359 --- [ntainer#2-0-C-1] c.i.s.l.k.consumer.Demo04Consumer : [onMessage][线程编号:16 消息内容:Demo04Message{id=1575685458}]
# 打印异常
2019-12-07 10:24:28.927 ERROR 11359 --- [ntainer#2-0-C-1] essageListenerContainer$ListenerConsumer : Error handler threw an exception
# Consumer04 第一次重试消费
2019-12-07 10:24:28.929 INFO 11359 --- [ntainer#2-0-C-1] c.i.s.l.k.consumer.Demo04Consumer : [onMessage][线程编号:16 消息内容:Demo04Message{id=1575685458}]
# 打印异常
2019-12-07 10:24:38.932 ERROR 11359 --- [ntainer#2-0-C-1] essageListenerContainer$ListenerConsumer : Error handler threw an exception
# Consumer04 第二次重试消费
2019-12-07 10:24:38.934 INFO 11359 --- [ntainer#2-0-C-1] c.i.s.l.k.consumer.Demo04Consumer : [onMessage][线程编号:16 消息内容:Demo04Message{id=1575685458}]
# 打印异常
2019-12-07 10:24:48.939 ERROR 11359 --- [ntainer#2-0-C-1] essageListenerContainer$ListenerConsumer : Error handler threw an exception
# Consumer04 第三次重试消费
2019-12-07 10:24:48.941 INFO 11359 --- [ntainer#2-0-C-1] c.i.s.l.k.consumer.Demo04Consumer : [onMessage][线程编号:16 消息内容:Demo04Message{id=1575685458}]
# 这次不会打印异常日志,直接发到死信队列
- 从日志中,我们可以看出,发送的这条消息被 Demo04Consumer 首次消费失败后,每间隔 10 秒,又消费重试 3 次。
8. 广播消费
示例代码对应仓库:lab-03-kafka-demo-broadcast 。
在上述的示例中,我们看到的都是使用集群消费。而在一些场景下,我们需要使用广播消费。
广播消费模式下,相同 Consumer Group 的每个 Consumer 实例都接收全量的消息。
- 不过 Kafka 并不直接提供内置的广播消费的功能!!!此时,我们只能退而求其次,每个 Consumer 独有一个 Consumer Group ,从而保证都能接收到全量的消息。
例如说,在应用中,缓存了数据字典等配置表在内存中,可以通过 Kafka 广播消费,实现每个应用节点都消费消息,刷新本地内存的缓存。
又例如说,我们基于 WebSocket 实现了 IM 聊天,在我们给用户主动发送消息时,因为我们不知道用户连接的是哪个提供 WebSocket 的应用,所以可以通过 Kafka 广播消费,每个应用判断当前用户是否是和自己提供的 WebSocket 服务连接,如果是,则推送消息给用户。
下面,我们开始本小节的示例。考虑到不污染上述的示例,我们新建一个 lab-03-kafka-demo-broadcast 项目。
8.1 引入依赖
和「3.1 引入依赖」」一致,见 pom.xml 文件。
8.2 应用配置文件
在「3.2 应用配置文件」 是一致的订单,就是修改了配置项 spring.kafka.consumer.auto-offset-reset=latest 。因为在广播订阅下,我们一般情况下,无需消费历史的消息,而是从订阅的 Topic 的队列的尾部开始消费即可,所以配置为 latest 。
完整的配置文件,见 application.yaml 。
8.3 Demo05Message
在 cn.iocoder.springboot.lab03.kafkademo.message 包下,创建 Demo05Message 消息类,提供给当前示例使用。代码如下:
// Demo05Message.java
public class Demo05Message {
public static final String TOPIC = "DEMO_05";
/**
* 编号
*/
private Integer id;
// ... 省略 set/get/toString 方法
}
TOPIC静态属性,我们设置该消息类对应 Topic 为"DEMO_05"。
8.4 Demo05Producer
在 cn.iocoder.springboot.lab03.kafkademo.producer 包下,创建 Demo05Producer 类,它会使用 Kafka-Spring 封装提供的 KafkaTemplate ,同步发送消息。代码如下:
// Demo04Producer.java
@Component
public class Demo05Producer {
@Resource
private KafkaTemplate<Object, Object> kafkaTemplate;
public SendResult syncSend(Integer id) throws ExecutionException, InterruptedException {
// 创建 Demo05Message 消息
Demo05Message message = new Demo05Message();
message.setId(id);
// 同步发送消息
return kafkaTemplate.send(Demo05Message.TOPIC, message).get();
}
}
- 和「3.5 Demo01Producer」的同步发送消息的代码是一致的,就是换成了 Demo05Message 。
8.5 Demo05Consumer
在 cn.iocoder.springboot.lab03.kafkademo.consumer 包下,创建 Demo05Consumer 类,消费消息。代码如下:
// Demo04Consumer.java
@Component
public class Demo05Consumer {
private Logger logger = LoggerFactory.getLogger(getClass());
@KafkaListener(topics = Demo05Message.TOPIC,
groupId = "demo05-consumer-group-" + Demo05Message.TOPIC + "-" + "#{T(java.util.UUID).randomUUID()}") // <X>
public void onMessage(Demo05Message message) {
logger.info("[onMessage][线程编号:{} 消息内容:{}]", Thread.currentThread().getId(), message);
}
}
- 在
<X>处,我们通过 Spring EL 表达式,在每个消费者分组的名字上,使用 UUID 生成其后缀。这样,我们就能保证每个项目启动的消费者分组不同,以达到广播消费的目的。
8.6 简单测试
创建 Demo05ProducerTest 测试类,用于测试广播消费。代码如下:
@RunWith(SpringRunner.class)
@SpringBootTest(classes = Application.class)
public class Demo05ProducerTest {
private Logger logger = LoggerFactory.getLogger(getClass());
@Autowired
private Demo05Producer producer;
@Test
public void test() throws InterruptedException {
// 阻塞等待,保证消费
new CountDownLatch(1).await();
}
@Test
public void testSyncSend() throws ExecutionException, InterruptedException {
int id = (int) (System.currentTimeMillis() / 1000);
SendResult result = producer.syncSend(id);
logger.info("[testSyncSend][发送编号:[{}] 发送结果:[{}]]", id, result);
// 阻塞等待,保证消费
new CountDownLatch(1).await();
}
}
首先,执行 #test() 测试方法,先启动一个消费者分组 "demo05-consumer-group-DEMO_05-${UUID1}" 的 Consumer 节点。
然后,执行 #testSyncSend() 测试方法,再启动一个消费者分组 "demo05-consumer-group-DEMO_05-${UUID2}" 的 Consumer 节点。同时,该测试方法,调用 Demo05ProducerTest#syncSend(id) 方法,同步发送了一条消息。控制台输出如下:
// #### testSyncSend 方法对应的控制台 ####
# Producer 同步发送消息成功
2019-12-07 15:00:42.578 INFO 16077 --- [ main] c.i.s.l.k.producer.Demo05ProducerTest : [testSyncSend][发送编号:[1575702042] 发送结果:[SendResult [producerRecord=ProducerRecord(topic=DEMO_05, partition=null, headers=RecordHeaders(headers = [RecordHeader(key = __TypeId__, value = [99, 110, 46, 105, 111, 99, 111, 100, 101, 114, 46, 115, 112, 114, 105, 110, 103, 98, 111, 111, 116, 46, 108, 97, 98, 48, 51, 46, 107, 97, 102, 107, 97, 100, 101, 109, 111, 46, 109, 101, 115, 115, 97, 103, 101, 46, 68, 101, 109, 111, 48, 53, 77, 101, 115, 115, 97, 103, 101])], isReadOnly = true), key=null, value=Demo05Message{id=1575702042}, timestamp=null), recordMetadata=DEMO_05-0@0]]]
# Demo05Consumer 消费了该消息
2019-12-07 15:00:42.618 INFO 16077 --- [ntainer#0-0-C-1] c.i.s.l.k.consumer.Demo05Consumer : [onMessage][线程编号:16 消息内容:Demo05Message{id=1575702042}]
// ### test 方法对应的控制台 ####
# Demo05Consumer 也消费了该消息
2019-12-07 15:00:42.644 INFO 16067 --- [ntainer#0-0-C-1] c.i.s.l.k.consumer.Demo05Consumer : [onMessage][线程编号:16 消息内容:Demo05Message{id=1575702042}]
- 消费者分组
"demo05-consumer-group-DEMO_05-${UUID1}"和demo05-consumer-group-DEMO_05-${UUID2}的两个 Consumer 节点,都消费了这条发送的消息。符合广播消费的预期~
9. 并发消费
示例代码对应仓库:lab-03-kafka-demo-concurrency 。
在上述的示例中,我们配置的每一个 Spring-Kafka @KafkaListener ,都是串行消费的。显然,这在监听的 Topic 每秒消息量比较大的时候,会导致消费不及时,导致消息积压的问题。
虽然说,我们可以通过启动多个 JVM 进程,实现多进程的并发消费,从而加速消费的速度。但是问题是,否能够实现多线程的并发消费呢?答案是有。
在「3.9 @KafkaListener」小节中,我们可以看到该注解有 concurrency 属性,它可以指定并发消费的线程数。例如说,如果设置 concurrency=4 时,Spring-Kafka 就会为该 @KafkaListener 创建 4 个线程,进行并发消费。
考虑到让胖友能够更好的理解 concurrency 属性,我们来简单说说 Spring-Kafka 在这块的实现方式。我们来举个例子:
- 首先,我们来创建一个 Topic 为
"DEMO_06",并且设置其 Partition 分区数为 10 。 - 然后,我们创建一个 Demo06Consumer 类,并在其消费方法上,添加
@KafkaListener(concurrency=2)注解。 - 再然后,我们启动项目。Spring-Kafka 会根据
@KafkaListener(concurrency=2)注解,创建 2 个 Kafka Consumer 。注意噢,是 2 个 Kafka Consumer 呢!!!后续,每个 Kafka Consumer 会被单独分配到一个线程中,进行拉取消息,消费消息。 - 之后,Kafka Broker 会将 Topic 为
"DEMO_06"分配给创建的 2 个 Kafka Consumer 各 5 个 Partition 。😈 如果不了解 Kafka Broker “分配区分”机制单独胖友,可以看看 《Kafka 消费者如何分配分区》 文章。 - 这样,因为
@KafkaListener(concurrency=2)注解,创建 2 个 Kafka Consumer ,就在各自的线程中,拉取各自的 Topic 为"DEMO_06"的 Partition 的消息,各自串行消费。从而,实现多线程的并发消费。
酱紫讲解一下,胖友对 Spring-Kafka 实现多线程的并发消费的机制,是否理解了。不过有一点要注意,不要配置 concurrency 属性过大,则创建的 Kafka Consumer 分配不到消费 Topic 的 Partition 分区,导致不断的空轮询。
友情提示:可以选择不看。
在理解 Spring-Kafka 提供的并发消费机制,花费了好几个小时,主要陷入到了一个误区。
如果胖友有使用过 RocketMQ 的并发消费,会发现只要创建一个 RocketMQ Consumer 对象,然后 Consumer 拉取完消息之后,丢到 Consumer 的线程池中执行消费,从而实现并发消费。
而在 Spring-Kafka 提供的并发消费,会发现需要创建多个 Kafka Consumer 对象,并且每个 Consumer 都单独分配一个线程,然后 Consumer 拉取完消息之后,在各自的线程中执行消费。
又或者说,Spring-Kafka 提供的并发消费,很像 RocketMQ 的顺序消费。😈 从感受上来说,Spring-Kafka 的并发消费像 BIO ,RocketMQ 的并发消费像 NIO 。
不过,理论来说,在原生的 Kafka 客户端,也是能封装出和 RocketMQ Consumer 一样的并发消费的机制。
也因此,在使用 Kafka 的时候,每个 Topic 的 Partition 在消息量大的时候,要注意设置的相对大一些。
下面,我们开始本小节的示例。本示例就是上述举例的具体实现。考虑到不污染上述的示例,我们新建一个 lab-03-kafka-demo-concurrency 项目。
9.1 引入依赖
9.2 应用配置文件
和 3.2 应用配置文件」 一致,见 application.yaml 文件。
实际上,可以通过 spring.kafka.listener.concurrency 配置项,全局设置每个 @KafkaListener 的并发消费的线程数。不过个人建议,还是每个 @KafkaListener 各自配置,毕竟每个 Topic 的 Partition 的数量,都是不同的。当然,也可以结合使用 😈 。
9.3 Demo06Message
在 cn.iocoder.springboot.lab03.kafkademo.message 包下,创建 Demo06Message 消息类,提供给当前示例使用。代码如下:
// Demo06Message.java
public class Demo06Message {
public static final String TOPIC = "DEMO_06";
/**
* 编号
*/
private Integer id;
// ... 省略 set/get/toString 方法
}
TOPIC静态属性,我们设置该消息类对应 Topic 为"DEMO_06"。
注意,记得手动创建一个 "DEMO_06" 的 Partition 大小为 10 。可执行如下命令:
$ bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 10 --topic DEMO_06
9.4 Demo06Producer
在 cn.iocoder.springboot.lab03.kafkademo.producer 包下,创建 Demo06Producer 类,它会使用 Kafka-Spring 封装提供的 KafkaTemplate ,同步发送消息。代码如下:
// Demo06Producer.java
@Component
public class Demo06Producer {
@Resource
private KafkaTemplate<Object, Object> kafkaTemplate;
public SendResult syncSend(Integer id) throws ExecutionException, InterruptedException {
// 创建 Demo01Message 消息
Demo06Message message = new Demo06Message();
message.setId(id);
// 同步发送消息
return kafkaTemplate.send(Demo06Message.TOPIC, message).get();
}
}
- 和「3.5 Demo01Producer」的同步发送消息的代码是一致的,就是换成了 Demo06Message 。
9.5 Demo06Consumer
在 cn.iocoder.springboot.lab03.kafkademo.consumer 包下,创建 Demo06Consumer 类,消费消息。代码如下:
// Demo06Consumer.java
@Component
public class Demo06Consumer {
private Logger logger = LoggerFactory.getLogger(getClass());
@KafkaListener(topics = Demo06Message.TOPIC,
groupId = "demo06-consumer-group-" + Demo06Message.TOPIC,
concurrency = "2")
public void onMessage(Demo06Message message) {
logger.info("[onMessage][线程编号:{} 消息内容:{}]", Thread.currentThread().getId(), message);
}
}
- 在
<X>处,我们在@KafkaListener注解上,添加了concurrency = "2"属性,创建 2 个线程消费"DEMO_06"下的消息。
9.6 简单测试
创建 Demo06ProducerTest 测试类,编写一个单元测试方法,发送 10 条消息,观察并发消费情况。代码如下:
// Demo06ProducerTest.java
@RunWith(SpringRunner.class)
@SpringBootTest(classes = Application.class)
public class Demo06ProducerTest {
private Logger logger = LoggerFactory.getLogger(getClass());
@Autowired
private Demo06Producer producer;
@Test
public void testSyncSend() throws ExecutionException, InterruptedException {
for (int i = 0; i < 10; i++) {
int id = (int) (System.currentTimeMillis() / 1000);
SendResult result = producer.syncSend(id);
// logger.info("[testSyncSend][发送编号:[{}] 发送结果:[{}]]", id, result);
}
// 阻塞等待,保证消费
new CountDownLatch(1).await();
}
}
执行 #testSyncSend() 单元测试,输出日志如下:
# 线程编号为 16
2019-12-07 17:21:16.365 INFO 24303 --- [ntainer#0-0-C-1] c.i.s.l.k.consumer.Demo06Consumer : [onMessage][线程编号:16 消息内容:Demo06Message{id=1575710476}]
2019-12-07 17:21:16.369 INFO 24303 --- [ntainer#0-0-C-1] c.i.s.l.k.consumer.Demo06Consumer : [onMessage][线程编号:16 消息内容:Demo06Message{id=1575710476}]
2019-12-07 17:21:16.369 INFO 24303 --- [ntainer#0-0-C-1] c.i.s.l.k.consumer.Demo06Consumer : [onMessage][线程编号:16 消息内容:Demo06Message{id=1575710476}]
2019-12-07 17:21:16.369 INFO 24303 --- [ntainer#0-0-C-1] c.i.s.l.k.consumer.Demo06Consumer : [onMessage][线程编号:16 消息内容:Demo06Message{id=1575710476}]
2019-12-07 17:21:16.369 INFO 24303 --- [ntainer#0-0-C-1] c.i.s.l.k.consumer.Demo06Consumer : [onMessage][线程编号:16 消息内容:Demo06Message{id=1575710476}]
# 线程编号为 18
2019-12-07 17:21:16.365 INFO 24303 --- [ntainer#0-1-C-1] c.i.s.l.k.consumer.Demo06Consumer : [onMessage][线程编号:18 消息内容:Demo06Message{id=1575710476}]
2019-12-07 17:21:16.369 INFO 24303 --- [ntainer#0-1-C-1] c.i.s.l.k.consumer.Demo06Consumer : [onMessage][线程编号:18 消息内容:Demo06Message{id=1575710476}]
2019-12-07 17:21:16.369 INFO 24303 --- [ntainer#0-1-C-1] c.i.s.l.k.consumer.Demo06Consumer : [onMessage][线程编号:18 消息内容:Demo06Message{id=1575710476}]
2019-12-07 17:21:16.369 INFO 24303 --- [ntainer#0-1-C-1] c.i.s.l.k.consumer.Demo06Consumer : [onMessage][线程编号:18 消息内容:Demo06Message{id=1575710476}]
2019-12-07 17:21:16.369 INFO 24303 --- [ntainer#0-1-C-1] c.i.s.l.k.consumer.Demo06Consumer : [onMessage][线程编号:18 消息内容:Demo06Message{id=1575710476}]
- 我们可以看到,两个线程在消费
"DEMO_06"下的消息。 - 😈 为了更好的做对比,胖友可以尝试自行把配置改成
@KafkaListner的concurrency=1,就会发现 Demo06Consumer 只会单线程消费了。
此时,如果我们使用 Kafka Manager 来查看 "DEMO_06" 的消费者列表: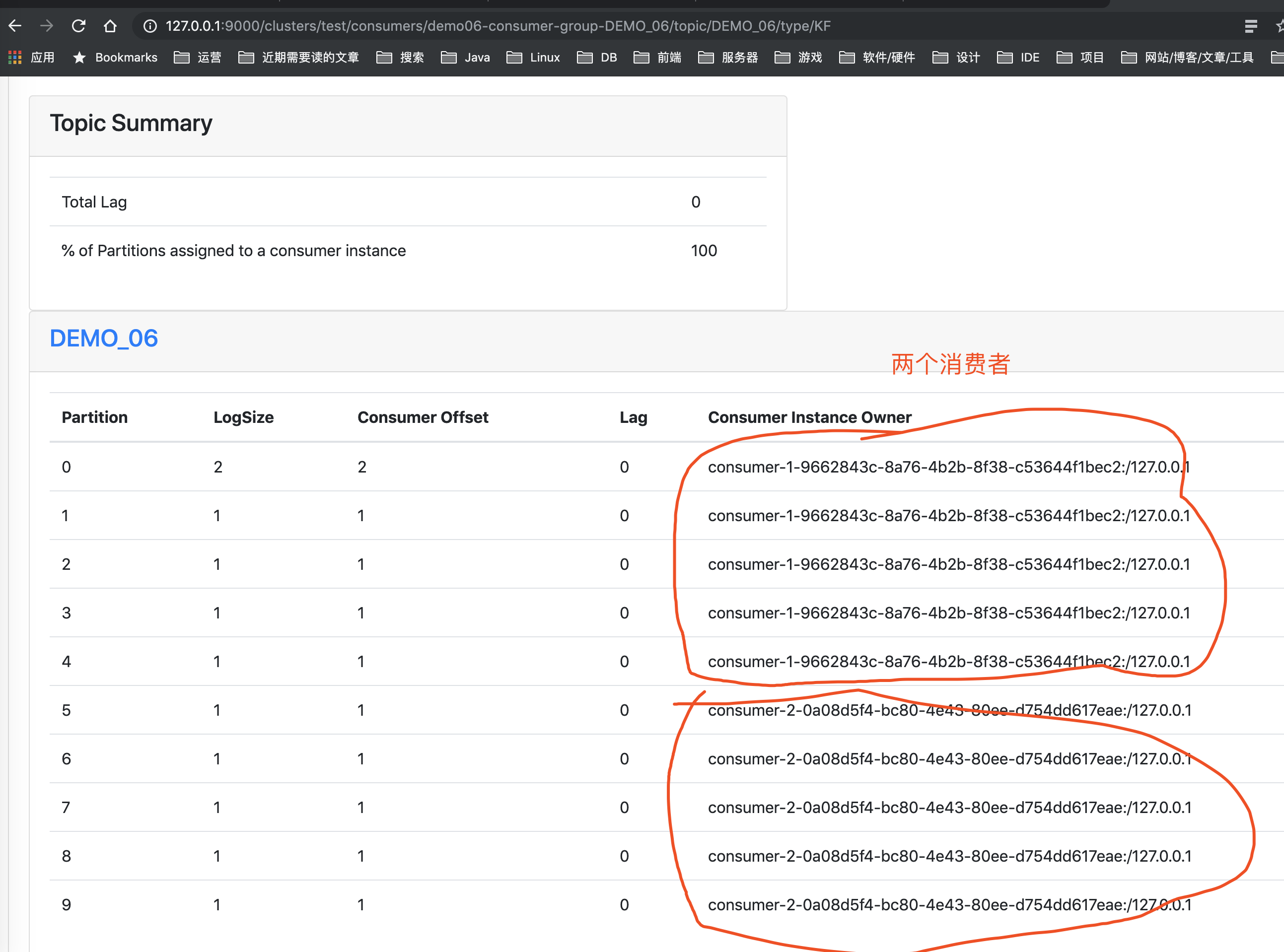
10. 顺序消息
示例代码对应仓库:lab-03-kafka-demo-concurrency 。
我们先来一起了解下顺序消息的顺序消息的定义:
- 普通顺序消息 :Producer 将相关联的消息发送到相同的消息队列。
- 完全严格顺序 :在【普通顺序消息】的基础上,Consumer 严格顺序消费。
在上述的示例中,我们看到 Spring-Kafka 在 Consumer 消费消息时,天然就支持按照 Topic 下的 Partition 下的消息,顺序消费。即使在「9. 并发消费」时,也能保证如此。
那么此时,我们只需要考虑将 Producer 将相关联的消息发送到 Topic 下的相同的 Partition 即可。如果胖友了解 Producer 发送消息的分区策略的话,只要我们发送消息时,指定了消息的 key ,Producer 则会根据 key 的哈希值取模来获取到其在 Topic 下对应的 Partition 。完美~~不了解的 Producer 分区选择策略的胖友,可以看看 《Kafka 发送消息分区选择策略详解》 文章。
下面,我们开始本小节的示例。该示例,我们会在「9. 并发消费」的 lab-03-kafka-demo-concurrency 项目中,继续改造。
10.1 Demo06Producer
修改 Demo06Producer 类,增加顺序发送消息方法。代码如下:
// Demo06Producer.java
public SendResult syncSendOrderly(Integer id) throws ExecutionException, InterruptedException {
// 创建 Demo01Message 消息
Demo06Message message = new Demo06Message();
message.setId(id);
// 同步发送消息
// 因为我们使用 String 的方式序列化 key ,所以需要将 id 转换成 String
return kafkaTemplate.send(Demo06Message.TOPIC, String.valueOf(id), message).get();
}
- 调用 KafkaTemplate 同步发送消息方法时,我们多传入了
id作为消息的 key ,从而实现发送到DEMO_06这个 Topic 下的相同 Partition 中。
10.2 简单测试
修改 Demo06ProducerTest 测试类,新增一个单元测试方法,顺序发送 10 条消息,观察消费情况。代码如下:
// Demo06ProducerTest.java
@Test
public void testSyncSendOrderly() throws ExecutionException, InterruptedException {
for (int i = 0; i < 10; i++) {
int id = 1;
SendResult result = producer.syncSendOrderly(id);
logger.info("[testSyncSend][发送编号:[{}] 发送队列:[{}]]", id, result.getRecordMetadata().partition());
}
// 阻塞等待,保证消费
new CountDownLatch(1).await();
}
执行 #testSyncSendOrderly() 单元测试,输出日志如下:
# Producer 同步发送 10 条顺序消息成功,都发送到了 Topic 为 DEMO_06 ,队列编号为 9 的消息队列上
2019-12-07 18:48:45.866 INFO 31773 --- [ main] c.i.s.l.k.producer.Demo06ProducerTest : [testSyncSend][发送编号:[1] 发送队列:[9]]
2019-12-07 18:48:45.867 INFO 31773 --- [ main] c.i.s.l.k.producer.Demo06ProducerTest : [testSyncSend][发送编号:[1] 发送队列:[9]]
2019-12-07 18:48:45.869 INFO 31773 --- [ main] c.i.s.l.k.producer.Demo06ProducerTest : [testSyncSend][发送编号:[1] 发送队列:[9]]
2019-12-07 18:48:45.870 INFO 31773 --- [ main] c.i.s.l.k.producer.Demo06ProducerTest : [testSyncSend][发送编号:[1] 发送队列:[9]]
2019-12-07 18:48:45.871 INFO 31773 --- [ main] c.i.s.l.k.producer.Demo06ProducerTest : [testSyncSend][发送编号:[1] 发送队列:[9]]
2019-12-07 18:48:45.872 INFO 31773 --- [ main] c.i.s.l.k.producer.Demo06ProducerTest : [testSyncSend][发送编号:[1] 发送队列:[9]]
2019-12-07 18:48:45.873 INFO 31773 --- [ main] c.i.s.l.k.producer.Demo06ProducerTest : [testSyncSend][发送编号:[1] 发送队列:[9]]
2019-12-07 18:48:45.875 INFO 31773 --- [ main] c.i.s.l.k.producer.Demo06ProducerTest : [testSyncSend][发送编号:[1] 发送队列:[9]]
2019-12-07 18:48:45.876 INFO 31773 --- [ main] c.i.s.l.k.producer.Demo06ProducerTest : [testSyncSend][发送编号:[1] 发送队列:[9]]
2019-12-07 18:48:45.877 INFO 31773 --- [ main] c.i.s.l.k.producer.Demo06ProducerTest : [testSyncSend][发送编号:[1] 发送队列:[9]]
# Demo06Consumer 在线程编号为 18 中,顺序消费
2019-12-07 18:48:45.908 INFO 31773 --- [ntainer#0-1-C-1] c.i.s.l.k.consumer.Demo06Consumer : [onMessage][线程编号:18 消息内容:Demo06Message{id=1}]
2019-12-07 18:48:45.911 INFO 31773 --- [ntainer#0-1-C-1] c.i.s.l.k.consumer.Demo06Consumer : [onMessage][线程编号:18 消息内容:Demo06Message{id=1}]
2019-12-07 18:48:45.912 INFO 31773 --- [ntainer#0-1-C-1] c.i.s.l.k.consumer.Demo06Consumer : [onMessage][线程编号:18 消息内容:Demo06Message{id=1}]
2019-12-07 18:48:45.912 INFO 31773 --- [ntainer#0-1-C-1] c.i.s.l.k.consumer.Demo06Consumer : [onMessage][线程编号:18 消息内容:Demo06Message{id=1}]
2019-12-07 18:48:45.912 INFO 31773 --- [ntainer#0-1-C-1] c.i.s.l.k.consumer.Demo06Consumer : [onMessage][线程编号:18 消息内容:Demo06Message{id=1}]
2019-12-07 18:48:45.912 INFO 31773 --- [ntainer#0-1-C-1] c.i.s.l.k.consumer.Demo06Consumer : [onMessage][线程编号:18 消息内容:Demo06Message{id=1}]
2019-12-07 18:48:45.912 INFO 31773 --- [ntainer#0-1-C-1] c.i.s.l.k.consumer.Demo06Consumer : [onMessage][线程编号:18 消息内容:Demo06Message{id=1}]
2019-12-07 18:48:45.912 INFO 31773 --- [ntainer#0-1-C-1] c.i.s.l.k.consumer.Demo06Consumer : [onMessage][线程编号:18 消息内容:Demo06Message{id=1}]
2019-12-07 18:48:45.912 INFO 31773 --- [ntainer#0-1-C-1] c.i.s.l.k.consumer.Demo06Consumer : [onMessage][线程编号:18 消息内容:Demo06Message{id=1}]
2019-12-07 18:48:45.912 INFO 31773 --- [ntainer#0-1-C-1] c.i.s.l.k.consumer.Demo06Consumer : [onMessage][线程编号:18 消息内容:Demo06Message{id=1}]
- 😈 胖友认真看下艿艿在日志中的注释,理解下整个顺序消息的过程。
11. 事务消息
示例代码对应仓库:lab-03-kafka-demo-transaction 。
Kafka 内置提供事务消息的支持。对事务消息的概念不了解的胖友,可以看看 《事务消息组件的套路》 文章。
不过 Kafka 提供的并不是完整的的事务消息的支持,缺少了回查机制。关于这一点,刚推荐的文章也有讲到。目前,常用的分布式消息队列,只有 RocketMQ 提供了完整的事务消息的支持,具体的可以看看《芋道 Spring Boot 消息队列 RocketMQ 入门》 的「9. 事务消息」小节,😈 暂时不拓展开来讲。
下面,我们开始本小节的示例。考虑到不污染上述的示例,我们新建一个 lab-03-kafka-demo-transaction 项目。
11.1 引入依赖
11.2 应用配置文件
在 resources 目录下,创建 application.yaml 配置文件。配置如下:
spring:
# Kafka 配置项,对应 KafkaProperties 配置类
kafka:
bootstrap-servers: 127.0.0.1:9092 # 指定 Kafka Broker 地址,可以设置多个,以逗号分隔
# Kafka Producer 配置项
producer:
acks: all # 0-不应答。1-leader 应答。all-所有 leader 和 follower 应答。
retries: 3 # 发送失败时,重试发送的次数
key-serializer: org.apache.kafka.common.serialization.StringSerializer # 消息的 key 的序列化
value-serializer: org.springframework.kafka.support.serializer.JsonSerializer # 消息的 value 的序列化
transaction-id-prefix: demo. # 事务编号前缀
# Kafka Consumer 配置项
consumer:
auto-offset-reset: earliest # 设置消费者分组最初的消费进度为 earliest 。可参考博客 https://blog.csdn.net/lishuangzhe7047/article/details/74530417 理解
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.springframework.kafka.support.serializer.JsonDeserializer
properties:
spring:
json:
trusted:
packages: cn.iocoder.springboot.lab03.kafkademo.message
isolation:
level: read_committed # 读取已提交的消息
# Kafka Consumer Listener 监听器配置
listener:
missing-topics-fatal: false # 消费监听接口监听的主题不存在时,默认会报错。所以通过设置为 false ,解决报错
logging:
level:
org:
springframework:
kafka: ERROR # spring-kafka INFO 日志太多了,所以我们限制只打印 ERROR 级别
apache:
kafka: ERROR # kafka INFO 日志太多了,所以我们限制只打印 ERROR 级别
-
相比
「3.2 应用配置文件」
来说,修改或增加如下三个参数:
- 修改
spring.kafka.producer.acks=all配置,不然在启动时会报"Must set acks to all in order to use the idempotent producer. Otherwise we cannot guarantee idempotence."错误。因为,Kafka 的事务消息需要基于幂等性来实现,所以必须保证所有节点都写入成功。 - 增加
transaction-id-prefix=demo.配置,事务编号的前缀。需要保证相同应用配置相同,不同应用配置不同。具体可以看看《How to choose Kafka transaction id for several applications》的讨论。 - 增加
spring.kafka.consumer.properties.isolation.level=read_committed配置,Consumer 仅读取已提交的消息。😈 一定要配置!!!被坑惨了,当时以为自己的事务消息怎么就是不生效,原来少加了这个。
- 修改
11.3 Demo07Producer
在 cn.iocoder.springboot.lab03.kafkademo.producer 包下,创建 Demo07Producer 类,它会使用 Kafka-Spring 封装提供的 KafkaTemplate ,实现发送事务消息。代码如下:
// Demo07Producer.java
@Component
public class Demo07Producer {
private Logger logger = LoggerFactory.getLogger(getClass());
public String syncSendInTransaction(Integer id, Runnable runner) throws ExecutionException, InterruptedException {
return kafkaTemplate.executeInTransaction(new KafkaOperations.OperationsCallback<Object, Object, String>() {
@Override
public String doInOperations(KafkaOperations<Object, Object> kafkaOperations) {
// 创建 Demo07Message 消息
Demo07Message message = new Demo07Message();
message.setId(id);
try {
SendResult<Object, Object> sendResult = kafkaOperations.send(Demo07Message.TOPIC, message).get();
logger.info("[doInOperations][发送编号:[{}] 发送结果:[{}]]", id, sendResult);
} catch (Exception e) {
throw new RuntimeException(e);
}
// 本地业务逻辑... biubiubiu
runner.run();
// 返回结果
return "success";
}
});
}
}
-
使用 kafkaTemplate 提交的
#executeInTransaction(OperationsCallback<K, V, T> callback)模板方法,实现在 Kafka 事务中,执行自定义
KafkaOperations.OperationsCallback
操作。
- 在
#executeInTransaction(...)方法中,我们可以通过 KafkaOperations 来执行发送消息等 Kafka 相关的操作,也可以执行自己的业务逻辑。 - 在
#executeInTransaction(...)方法的开始,它会自动动创建 Kafka 的事务;然后执行我们定义的 KafkaOperations 的逻辑;如果成功,则提交 Kafka 事务;如果失败,则回滚 Kafka 事务。
- 在
-
另外,我们定义了一个
runner参数,用于表示本地业务逻辑~
注意,如果 Kafka Producer 开启了事务的功能,则所有发送的消息,都必须处于 Kafka 事务之中,否则会抛出 " No transaction is in process; possible solutions: run the template operation within the scope of a template.executeInTransaction() operation, start a transaction with @Transactional before invoking the template method, run in a transaction started by a listener container when consuming a record" 异常。
所以,如果胖友的业务中,即存在需要事务的情况,也存在不需要事务的情况,需要分别定义两个 KafkaTemplate(Kafka Producer)。
11.4 Demo07Consumer
在 cn.iocoder.springboot.lab03.kafkademo.consumer 包下,创建 Demo07Consumer 类,消费消息。代码如下:
// Demo07Consumer.java
@Component
public class Demo07Consumer {
private Logger logger = LoggerFactory.getLogger(getClass());
@KafkaListener(topics = Demo07Message.TOPIC,
groupId = "demo07-consumer-group-" + Demo07Message.TOPIC)
public void onMessage(Demo07Message message) {
logger.info("[onMessage][线程编号:{} 消息内容:{}]", Thread.currentThread().getId(), message);
}
}
- 和「3.6 Demo1Consumer.java」 一致,差别只在于消费 Topic 为
DEMO_07的消息。
11.5 简单测试
创建 Demo07ProducerTest 测试类,编写单元测试方法,调用 Demo07Producer 发送事务消息的方式。代码如下:
// Demo07ProducerTest.java
@RunWith(SpringRunner.class)
@SpringBootTest(classes = Application.class)
public class Demo07ProducerTest {
private Logger logger = LoggerFactory.getLogger(getClass());
@Autowired
private Demo07Producer producer;
@Test
public void testSyncSendInTransaction() throws ExecutionException, InterruptedException {
int id = (int) (System.currentTimeMillis() / 1000);
producer.syncSendInTransaction(id, new Runnable() {
@Override
public void run() {
logger.info("[run][我要开始睡觉了]");
try {
Thread.sleep(10 * 1000L);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
logger.info("[run][我睡醒了]");
}
});
// 阻塞等待,保证消费
new CountDownLatch(1).await();
}
}
- 故意创建一个执行逻辑为 sleep 10 秒的 Runnable 对象,来让我们测试验证,事务消息在提交后,才会被 Consumer 消费到。
执行 #testSyncSendInTransaction() 单元测试,输出日志如下:
# Producer 同步发送消息成功。
2019-12-07 21:10:20.496 INFO 37455 --- [ main] c.i.s.l.k.producer.Demo07Producer : [doInOperations][发送编号:[1575724220] 发送结果:[SendResult [producerRecord=ProducerRecord(topic=DEMO_07, partition=null, headers=RecordHeaders(headers = [RecordHeader(key = __TypeId__, value = [99, 110, 46, 105, 111, 99, 111, 100, 101, 114, 46, 115, 112, 114, 105, 110, 103, 98, 111, 111, 116, 46, 108, 97, 98, 48, 51, 46, 107, 97, 102, 107, 97, 100, 101, 109, 111, 46, 109, 101, 115, 115, 97, 103, 101, 46, 68, 101, 109, 111, 48, 55, 77, 101, 115, 115, 97, 103, 101])], isReadOnly = true), key=null, value=Demo07Message{id=1575724220}, timestamp=null), recordMetadata=DEMO_07-0@14]]]
# 故意 sleep 10 秒,延迟事务消息的提交
2019-12-07 21:10:20.496 INFO 37455 --- [ main] c.i.s.l.k.producer.Demo07ProducerTest : [run][我要开始睡觉了]
2019-12-07 21:10:30.500 INFO 37455 --- [ main] c.i.s.l.k.producer.Demo07ProducerTest : [run][我睡醒了]
# 在事务消息提交之后,事务消息才被 Consumer 消费到
2019-12-07 21:10:30.558 INFO 37455 --- [ntainer#0-0-C-1] c.i.s.l.k.consumer.Demo07Consumer : [onMessage][线程编号:16 消息内容:Demo07Message{id=1575724220}]
- 成功观察到,发送的事务消息,在提交之后才被 Consumer 消费到。
11.6 集成到 Spring Transaction 体系
Spring-Kafka 提供了对 Spring Transaction 的集成,所以在实际开发中,我们只需要配合使用 @Transactional 注解,来声明事务即可,而无需使用 KafkaTemplate 提供的 #executeInTransaction(...) 模板方法。😈 是不是便捷很多呢!
具体的使用示例,艿艿就暂时不提供了,感兴趣的胖友可以看看 《使用Kafka 事务的两种方式》 文章。
12. 消费进度的提交机制
示例代码对应仓库:lab-03-kafka-demo-ack 。
原生 Kafka Consumer 消费端,有两种消费进度提交的提交机制:
- 【默认】自动提交,通过配置
enable.auto.commit=true,每过auto.commit.interval.ms时间间隔,都会自动提交消费消费进度。而提交的时机,是在 Consumer 的#poll(...)方法的逻辑里完成,在每次从 Kafka Broker 拉取消息时,会检查是否到达自动提交的时间间隔,如果是,那么就会提交上一次轮询拉取的位置。 - 手动提交,通过配置
enable.auto.commit=false,后续通过 Consumer 的#commitSync(...)或#commitAsync(...)方法,同步或异步提交消费进度。
Spring-Kafka Consumer 消费端,提供了更丰富的消费者进度的提交机制,更加灵活。当然,也是分成自动提交和手动提交两个大类。在 AckMode 枚举类中,可以看到每一种具体的方式。代码如下:
// ContainerProperties#AckMode.java
public enum AckMode {
// ========== 自动提交 ==========
/**
* Commit after each record is processed by the listener.
*/
RECORD, // 每条消息被消费完成后,自动提交
/**
* Commit whatever has already been processed before the next poll.
*/
BATCH, // 每一次消息被消费完成后,在下次拉取消息之前,自动提交
/**
* Commit pending updates after
* {@link ContainerProperties#setAckTime(long) ackTime} has elapsed.
*/
TIME, // 达到一定时间间隔后,自动提交。
// 不过要注意,它并不是一到就立马提交,如果此时正在消费某一条消息,需要等这条消息被消费完成,才能提交消费进度。
/**
* Commit pending updates after
* {@link ContainerProperties#setAckCount(int) ackCount} has been
* exceeded.
*/
COUNT, // 消费成功的消息数到达一定数量后,自动提交。
// 不过要注意,它并不是一到就立马提交,如果此时正在消费某一条消息,需要等这条消息被消费完成,才能提交消费进度。
/**
* Commit pending updates after
* {@link ContainerProperties#setAckCount(int) ackCount} has been
* exceeded or after {@link ContainerProperties#setAckTime(long)
* ackTime} has elapsed.
*/
COUNT_TIME, // TIME 和 COUNT 的结合体,满足任一都会自动提交。
// ========== 手动提交 ==========
/**
* User takes responsibility for acks using an
* {@link AcknowledgingMessageListener}.
*/
MANUAL, // 调用时,先标记提交消费进度。等到当前消息被消费完成,然后在提交消费进度。
/**
* User takes responsibility for acks using an
* {@link AcknowledgingMessageListener}. The consumer
* immediately processes the commit.
*/
MANUAL_IMMEDIATE, // 调用时,立即提交消费进度。
}
- 看下每种方式,艿艿都添加了注释哟。
那么,既然现在存在原生 Kafka 和 Spring-Kafka 提供的两种消费进度的提交机制,我们应该怎么配置呢?
- 使用原生 Kafka 的方式,通过配置
spring.kafka.consumer.enable-auto-commit=true。然后,通过spring.kafka.consumer.auto-commit-interval设置自动提交的频率。 - 使用 Spring-Kafka 的方式,通过配置
spring.kafka.consumer.enable-auto-commit=false。然后通过spring.kafka.listener.ack-mode设置具体模式。另外,还有spring.kafka.listener.ack-time和spring.kafka.listener.ack-count可以设置自动提交的时间间隔和消息条数。
默认什么都不配置的情况下,使用 Spring-Kafka 的 BATCH 模式:每一次消息被消费完成后,在下次拉取消息之前,自动提交。
下面,我们开始本小节的示例,实现一个手动提交消息进度的消费者。考虑到不污染上述的示例,我们新建一个 lab-03-kafka-demo-ack 项目。
12.1 引入依赖
和「3.1 引入依赖」」一致,见 pom.xml 文件
12.2 应用配置文件
在 resources 目录下,创建 application.yaml 配置文件。配置如下:
spring:
# Kafka 配置项,对应 KafkaProperties 配置类
kafka:
bootstrap-servers: 127.0.0.1:9092 # 指定 Kafka Broker 地址,可以设置多个,以逗号分隔
# Kafka Producer 配置项
producer:
acks: 1 # 0-不应答。1-leader 应答。all-所有 leader 和 follower 应答。
retries: 3 # 发送失败时,重试发送的次数
key-serializer: org.apache.kafka.common.serialization.StringSerializer # 消息的 key 的序列化
value-serializer: org.springframework.kafka.support.serializer.JsonSerializer # 消息的 value 的序列化
# Kafka Consumer 配置项
consumer:
auto-offset-reset: earliest # 设置消费者分组最初的消费进度为 earliest 。可参考博客 https://blog.csdn.net/lishuangzhe7047/article/details/74530417 理解
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.springframework.kafka.support.serializer.JsonDeserializer
enable-auto-commit: false # 使用 Spring-Kafka 的消费进度的提交机制
properties:
spring:
json:
trusted:
packages: cn.iocoder.springboot.lab03.kafkademo.message
# Kafka Consumer Listener 监听器配置
listener:
missing-topics-fatal: false # 消费监听接口监听的主题不存在时,默认会报错。所以通过设置为 false ,解决报错
ack-mode: MANUAL
logging:
level:
org:
springframework:
kafka: ERROR # spring-kafka INFO 日志太多了,所以我们限制只打印 ERROR 级别
apache:
kafka: ERROR # kafka INFO 日志太多了,所以我们限制只打印 ERROR 级别
-
相比
「3.2 应用配置文件」
来说,增加如下两个参数:
- 添加
spring.kafka.consumer.enable-auto-commit=false配置,使用 Spring-Kafka 的消费进度的提交机制。😈 设计情况下,不添加该配置项也是可以的,因为false是默认值。 - 添加
spring.kafka.listener.ack-mode=MANUAL配置,使用 MANUAL 模式:调用时,先标记提交消费进度。等到当前消息被消费完成,然后在提交消费进度。
- 添加
12.3 Demo08Message
在 cn.iocoder.springboot.lab03.kafkademo.message 包下,创建 Demo08Message 消息类,提供给当前示例使用。代码如下:
// Demo04Message.java
public class Demo08Message {
public static final String TOPIC = "DEMO_08";
/**
* 编号
*/
private Integer id;
// ... 省略 set/get/toString 方法
}
TOPIC静态属性,我们设置该消息类对应 Topic 为"DEMO_08"。
12.4 Demo08Producer
在 cn.iocoder.springboot.lab03.kafkademo.producer 包下,创建 Demo08Producer 类,它会使用 Kafka-Spring 封装提供的 KafkaTemplate ,同步发送消息。代码如下:
// Demo08Producer.java
@Component
public class Demo08Producer {
@Resource
private KafkaTemplate<Object, Object> kafkaTemplate;
public SendResult syncSend(Integer id) throws ExecutionException, InterruptedException {
// 创建 Demo08Message 消息
Demo08Message message = new Demo08Message();
message.setId(id);
// 同步发送消息
return kafkaTemplate.send(Demo08Message.TOPIC, message).get();
}
}
- 和「3.5 Demo01Producer」的同步发送消息的代码是一致的,就是换成了 Demo08Message 。
12.5 Demo08Consumer
在 cn.iocoder.springboot.lab03.kafkademo.consumer 包下,创建 Demo08Consumer 类,消费消息。代码如下:
// Demo08Consumer.java
@Component
public class Demo08Consumer {
private Logger logger = LoggerFactory.getLogger(getClass());
@KafkaListener(topics = Demo08Message.TOPIC,
groupId = "demo08-consumer-group-" + Demo08Message.TOPIC)
public void onMessage(Demo08Message message, Acknowledgment acknowledgment) {
logger.info("[onMessage][线程编号:{} 消息内容:{}]", Thread.currentThread().getId(), message);
// 提交消费进度
if (message.getId() % 2 == 1) {
acknowledgment.acknowledge();
}
}
}
- 在消费方法上,我们增加了第二个方法参数,类型为 Acknowledgment 类。通过调用其
#acknowledge()方法,可以提交当前消息的 Topic 的 Partition 的消费进度。 - 在消费逻辑中,我们故意只提交消费的消息的
Demo08Message.id为奇数的消息。😈 这样,我们只需要发送一条id=1,一条id=2的消息,如果第二条的消费进度没有被提交,就可以说明手动提交消费进度成功。
12.6 简单测试
创建 Demo08ProducerTest 测试类,编写单元测试方法,测试手动提交消费进度。代码如下:
// Demo08ProducerTest.java
@RunWith(SpringRunner.class)
@SpringBootTest(classes = Application.class)
public class Demo08ProducerTest {
private Logger logger = LoggerFactory.getLogger(getClass());
@Autowired
private Demo08Producer producer;
@Test
public void testSyncSend() throws ExecutionException, InterruptedException {
for (int id = 1; id <= 2; id++) {
SendResult result = producer.syncSend(id);
logger.info("[testSyncSend][发送编号:[{}] 发送结果:[{}]]", id, result);
}
// 阻塞等待,保证消费
new CountDownLatch(1).await();
}
}
执行 #testSyncSend() 单元测试,输出日志如下:
// Producer 同步发送 2 条消息成功
2019-12-07 23:41:20.914 INFO 43412 --- [ main] c.i.s.l.k.producer.Demo08ProducerTest : [testSyncSend][发送编号:[1] 发送结果:[SendResult [producerRecord=ProducerRecord(topic=DEMO_08, partition=null, headers=RecordHeaders(headers = [RecordHeader(key = __TypeId__, value = [99, 110, 46, 105, 111, 99, 111, 100, 101, 114, 46, 115, 112, 114, 105, 110, 103, 98, 111, 111, 116, 46, 108, 97, 98, 48, 51, 46, 107, 97, 102, 107, 97, 100, 101, 109, 111, 46, 109, 101, 115, 115, 97, 103, 101, 46, 68, 101, 109, 111, 48, 56, 77, 101, 115, 115, 97, 103, 101])], isReadOnly = true), key=null, value=Demo08Message{id=1}, timestamp=null), recordMetadata=DEMO_08-0@0]]]
2019-12-07 23:41:20.916 INFO 43412 --- [ main] c.i.s.l.k.producer.Demo08ProducerTest : [testSyncSend][发送编号:[2] 发送结果:[SendResult [producerRecord=ProducerRecord(topic=DEMO_08, partition=null, headers=RecordHeaders(headers = [RecordHeader(key = __TypeId__, value = [99, 110, 46, 105, 111, 99, 111, 100, 101, 114, 46, 115, 112, 114, 105, 110, 103, 98, 111, 111, 116, 46, 108, 97, 98, 48, 51, 46, 107, 97, 102, 107, 97, 100, 101, 109, 111, 46, 109, 101, 115, 115, 97, 103, 101, 46, 68, 101, 109, 111, 48, 56, 77, 101, 115, 115, 97, 103, 101])], isReadOnly = true), key=null, value=Demo08Message{id=2}, timestamp=null), recordMetadata=DEMO_08-0@1]]]
// Demo08Consumer 消费 2 条消息成功
2019-12-07 23:41:21.006 INFO 43412 --- [ntainer#0-0-C-1] c.i.s.l.k.consumer.Demo08Consumer : [onMessage][线程编号:16 消息内容:Demo08Message{id=1}]
2019-12-07 23:41:21.006 INFO 43412 --- [ntainer#0-0-C-1] c.i.s.l.k.consumer.Demo08Consumer : [onMessage][线程编号:16 消息内容:Demo08Message{id=2}]
此时,如果我们使用 Kafka Manager 来查看 "DEMO_08" 的消费者列表:
- 第 2 条消息的消费进度,未被提交,符合预期~
--------
SpringCloud中的Kafka
--------
本文在提供完整代码示例,可见 https://github.com/YunaiV/SpringBoot-Labs 的 labx-11-spring-cloud-stream-kafka 目录。
原创不易,给点个 Star 嘿,一起冲鸭!
1. 概述
本文我们来学习 Spring Cloud Stream Kafka 组件,基于 Spring Cloud Stream 的编程模型,接入 Kafka 作为消息中间件,实现消息驱动的微服务。
FROM 《分布式发布订阅消息系统 Kafka》
Kafka 是一种高吞吐量的分布式发布订阅消息系统,她有如下特性:
- 通过 O(1) 的磁盘数据结构提供消息的持久化,这种结构对于即使数以TB的消息存储也能够保持长时间的稳定性能。
- 高吞吐量:即使是非常普通的硬件kafka也可以支持每秒数十万的消息。
- 支持通过 Kafka 服务器和消费机集群来分区消息。
在开始本文之前,胖友需要对 Kafka 进行简单的学习。可以阅读《Kafka 极简入门》文章,将第一二小节看完,在本机搭建一个 Kafka 服务。
2. Spring Cloud Stream 介绍
Spring Cloud Stream 是一个用于构建基于消息的微服务应用框架,使用 Spring Integration 与 Broker 进行连接。
友情提示:可能有胖友对 Broker 不太了解,我们来简单解释下。
一般来说,消息队列中间件都有一个 Broker Server(代理服务器),消息中转角色,负责存储消息、转发消息。
例如说在 RocketMQ 中,Broker 负责接收从生产者发送来的消息并存储、同时为消费者的拉取请求作准备。另外,Broker 也存储消息相关的元数据,包括消费者组、消费进度偏移和主题和队列消息等。
Spring Cloud Stream 提供了消息中间件的统一抽象,推出了 publish-subscribe、consumer groups、partition 这些统一的概念。
Spring Cloud Stream 内部有两个概念:Binder 和 Binding。
① Binder,跟消息中间件集成的组件,用来创建对应的 Binding。各消息中间件都有自己的 Binder 具体实现。
public interface Binder<T,
C extends ConsumerProperties, // 消费者配置
P extends ProducerProperties> { // 生产者配置
// 创建消费者的 Binding
Binding<T> bindConsumer(String name, String group, T inboundBindTarget, C consumerProperties);
// 创建生产者的 Binding
Binding<T> bindProducer(String name, T outboundBindTarget, P producerProperties);
}
- Kafka 实现了 KafkaMessageChannelBinder
- RabbitMQ 实现了 RabbitMessageChannelBinder
- RocketMQ 实现了 RocketMQMessageChannelBinder
② Binding,包括 Input Binding 和 Output Binding。Binding 在消息中间件与应用程序提供的 Provider 和 Consumer 之间提供了一个桥梁,实现了开发者只需使用应用程序的 Provider 或 Consumer 生产或消费数据即可,屏蔽了开发者与底层消息中间件的接触。
最终整体交互如下图所示: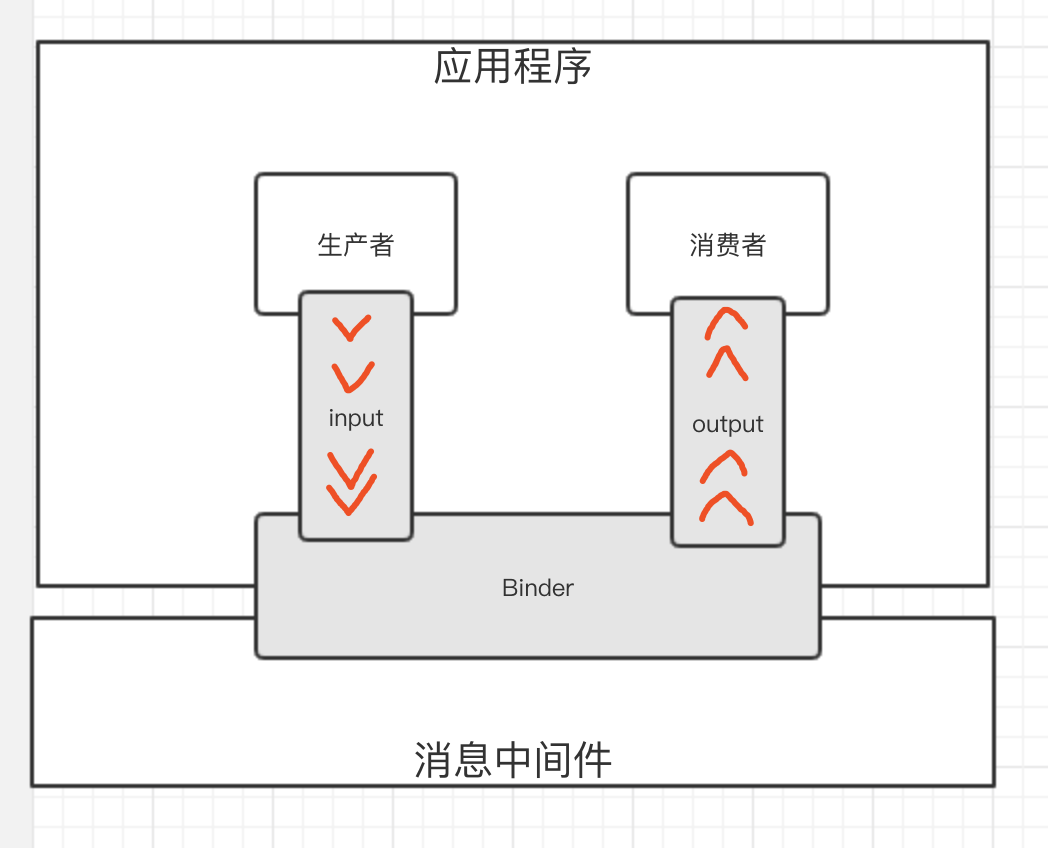
可能看完之后,胖友对 Spring Cloud Stream 还是有点懵逼,并且觉得概念怎么这么多呢?不要慌,我们先来快速入个门,会有更加具象的感受。
3. 快速入门
示例代码对应仓库:
友情提示:这可能是一个信息量有点大的入门内容,请保持耐心~
本小节,我们一起来快速入门下,会创建 2 个项目,分别作为生产者和消费者。最终项目如下图所示:
3.1 搭建生产者
创建 labx-11-sc-stream-kafka-producer-demo 项目,作为生产者。
3.1.1 引入依赖
创建 pom.xml 文件中,引入 Spring Cloud Stream Kafka 相关依赖。
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>labx-11</artifactId>
<groupId>cn.iocoder.springboot.labs</groupId>
<version>1.0-SNAPSHOT</version>
</parent>
<modelVersion>4.0.0</modelVersion>
<artifactId>labx-11-sc-stream-kafka-producer-demo</artifactId>
<properties>
<maven.compiler.target>1.8</maven.compiler.target>
<maven.compiler.source>1.8</maven.compiler.source>
<spring.boot.version>2.2.4.RELEASE</spring.boot.version>
<spring.cloud.version>Hoxton.SR1</spring.cloud.version>
</properties>
<!--
引入 Spring Boot、Spring Cloud、Spring Cloud Alibaba 三者 BOM 文件,进行依赖版本的管理,防止不兼容。
在 https://dwz.cn/mcLIfNKt 文章中,Spring Cloud Alibaba 开发团队推荐了三者的依赖关系
-->
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>${spring.boot.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>${spring.cloud.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<!-- 引入 SpringMVC 相关依赖,并实现对其的自动配置 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- 引入 Spring Cloud Stream Kafka 相关依赖,将 Kafka 作为消息队列,并实现对其的自动配置 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-stream-kafka</artifactId>
</dependency>
</dependencies>
</project>
通过引入 spring-cloud-starter-stream-kafka 依赖,引入并实现 Stream Kafka 的自动配置。在该依赖中,已经帮我们自动引入 Kafka 的大量依赖,非常方便,如下图所示:
3.1.2 配置文件
创建 application.yaml 配置文件,添加 Spring Cloud Stream Kafka 相关配置。
spring:
application:
name: demo-producer-application
cloud:
# Spring Cloud Stream 配置项,对应 BindingServiceProperties 类
stream:
# Binder 配置项,对应 BinderProperties Map
# binders:
# Binding 配置项,对应 BindingProperties Map
bindings:
demo01-output:
destination: DEMO-TOPIC-01 # 目的地。这里使用 Kafka Topic
content-type: application/json # 内容格式。这里使用 JSON
# Spring Cloud Stream Kafka 配置项
kafka:
# Kafka Binder 配置项,对应 KafkaBinderConfigurationProperties 类
binder:
brokers: 127.0.0.1:9092 # 指定 Kafka Broker 地址,可以设置多个,以逗号分隔
# Kafka 自定义 Binding 配置项,对应 KafkaBindingProperties Map
bindings:
demo01-output:
# Kafka Producer 配置项,对应 KafkaProducerProperties 类
producer:
sync: true # 是否同步发送消息,默认为 false 异步。
server:
port: 18080
① spring.cloud.stream 为 Spring Cloud Stream 配置项,对应 BindingServiceProperties 类。配置的层级有点深,我们一层一层来看看。
② spring.cloud.stream.bindings 为 Binding 配置项,对应 BindingProperties Map。其中,key 为 Binding 的名字。要注意,虽然说 Binding 分成 Input 和 Output 两种类型,但是在配置项中并不会体现出来,而是要在稍后搭配 @Input 还是 @Output 注解,才会有具体的区分。
这里,我们配置了一个名字为 demo01-output 的 Binding。从命名上,我们的意图是想作为 Output Binding,用于生产者发送消息。
-
destination:目的地。在 Kafka 中,使用 Topic 作为目的地。这里我们设置为DEMO-TOPIC-01。Topic(主题):每条发布到 Kafka 的消息都有一个类别,这个类别被称为 Topic。
-
content-type:内容格式。这里使用 JSON 格式,因为稍后我们将发送消息的类型为 POJO,使用 JSON 进行序列化。
③ spring.cloud.stream.kafka 为 Spring Cloud Stream Kafka 配置项。
④ spring.cloud.stream.kafka.binder 为 Kafka Binder 配置项,对应 KafkaBinderConfigurationProperties 类。
-
brokers:指定 Kafka Broker 地址,可以设置多个,以逗号分隔。Broker:Kafka 集群中的一台或多台服务器统称为 Broker。
⑤ spring.cloud.stream.kafka.bindings 为 Kafka 自定义 Binding 配置项,用于对通用的 spring.cloud.stream.bindings 配置项的增强,实现 Kafka Binding 独特的配置。该配置项对应 KafkaBindingProperties Map,其中 key 为 Binding 的名字,需要对应上噢。
这里,我们对名字为 demo01-output 的 Binding 进行增强,进行 Producer 的配置。其中,producer 为 Kafka Producer 配置项,对应 KafkaProducerProperties 类。
sync:是否同步发送消息,默认为false异步。一般业务场景下,使用同步发送消息较多,所以这里我们设置为true同步消息。
3.1.3 MySource
创建 MySource 接口,声明名字为 Output Binding。代码如下:
public interface MySource {
@Output("demo01-output")
MessageChannel demo01Output();
}
这里,我们通过 @Output 注解,声明了一个名字为 demo01-output 的 Output Binding。注意,这个名字要和我们配置文件中的 spring.cloud.stream.bindings 配置项对应上。
同时,@Output 注解的方法的返回结果为 MessageChannel 类型,可以使用它发送消息。MessageChannel 提供的发送消息的方法如下:
@FunctionalInterface
public interface MessageChannel {
long INDEFINITE_TIMEOUT = -1;
default boolean send(Message<?> message) {
return send(message, INDEFINITE_TIMEOUT);
}
boolean send(Message<?> message, long timeout);
}
那么,我们是否要实现 MySource 接口呢?答案是不需要,全部交给 Spring Cloud Stream 的 BindableProxyFactory 来解决。BindableProxyFactory 会通过动态代理,自动实现 MySource 接口。 而 @Output 注解的方法的返回值,BindableProxyFactory 会扫描带有 @Output 注解的方法,自动进行创建。
例如说,#demo01Output() 方法被自动创建返回结果为 DirectWithAttributesChannel,它是 MessageChannel 的子类。
友情提示:感兴趣的胖友,可以在 BindableProxyFactory 的
#afterPropertiesSet()和#invoke(MethodInvocation invocation)方法上,都打上一个断点,然后进行愉快的调试。
3.1.4 Demo01Message
创建 Demo01Message 类,示例 Message 消息。代码如下:
public class Demo01Message {
/**
* 编号
*/
private Integer id;
// ... 省略 setter/getter/toString 方法
}
3.1.5 Demo01Controller
创建 Demo01Controller 类,提供发送消息的 HTTP 接口。代码如下:
@RestController
@RequestMapping("/demo01")
public class Demo01Controller {
@Autowired
private MySource mySource; // <X>
@GetMapping("/send")
public boolean send() {
// <1> 创建 Message
Demo01Message message = new Demo01Message()
.setId(new Random().nextInt());
// <2> 创建 Spring Message 对象
Message<Demo01Message> springMessage = MessageBuilder.withPayload(message)
.build();
// <3> 发送消息
return mySource.demo01Output().send(springMessage);
}
}
<X>处,使用@Autowired注解,注入 MySource Bean。<1>处,创建 Demo01Message 对象。<2>处,使用 MessageBuilder 创建 Spring Message 对象,并设置消息内容为 Demo01Message 对象。<3>处,通过 MySource 获得 MessageChannel 对象,然后发送消息。
3.1.6 ProducerApplication
创建 ProducerApplication 类,启动应用。代码如下:
@SpringBootApplication
@EnableBinding(MySource.class)
public class ProducerApplication {
public static void main(String[] args) {
SpringApplication.run(ProducerApplication.class, args);
}
}
使用 @EnableBinding 注解,声明指定接口开启 Binding 功能,扫描其 @Input 和 @Output 注解。这里,我们设置为 MySource 接口。
3.2 搭建消费者
创建 labx-11-sc-stream-kafka-consumer-demo 项目,作为消费者。
3.2.1 引入依赖
创建 pom.xml 文件中,引入 Spring Cloud Alibaba Kafka 相关依赖。
友情提示:和「3.1.1 引入依赖」基本一样,点击 链接 查看。
3.2.2 配置文件
创建 application.yaml 配置文件,添加 Spring Cloud Stream Kafka 相关配置。
spring:
application:
name: demo-consumer-application
cloud:
# Spring Cloud Stream 配置项,对应 BindingServiceProperties 类
stream:
# Binder 配置项,对应 BinderProperties Map
# binders:
# Binding 配置项,对应 BindingProperties Map
bindings:
demo01-input:
destination: DEMO-TOPIC-01 # 目的地。这里使用 Kafka Topic
content-type: application/json # 内容格式。这里使用 JSON
group: demo01-consumer-group # 消费者分组
# Spring Cloud Stream Kafka 配置项
kafka:
# Kafka Binder 配置项,对应 KafkaBinderConfigurationProperties 类
binder:
brokers: 127.0.0.1:9092 # 指定 Kafka Broker 地址,可以设置多个,以逗号分隔
server:
port: ${random.int[10000,19999]} # 随机端口,方便启动多个消费者
总体来说,和「3.1.2 配置文件」是比较接近的,所以我们只说差异点噢。
① spring.cloud.stream.bindings 为 Binding 配置项。
这里,我们配置了一个名字为 demo01-input 的 Binding。从命名上,我们的意图是想作为 Input Binding,用于消费者消费消息。
-
group:消费者分组。消费者组(Consumer Group):同一类 Consumer 的集合,这类 Consumer 通常消费同一类消息且消费逻辑一致。消费者组使得在消息消费方面,实现负载均衡和容错的目标变得非常容易。要注意的是,消费者组的消费者实例必须订阅完全相同的 Topic。
对于消费队列的消费者,会有两种消费模式:集群消费(Clustering)和广播消费(Broadcasting)。
- 集群消费(Clustering):集群消费模式下,相同 Consumer Group 的每个 Consumer 实例平均分摊消息。
- 广播消费(Broadcasting):广播消费模式下,相同 Consumer Group 的每个 Consumer 实例都接收全量的消息。
Kafka 的消费者两种模式都支持。因为这里我们配置了消费者组,所以采用集群消费。至于如何使用广播消费,我们稍后举例子。
这里一点要注意!!!艿艿加了三个感叹号,一定要理解集群消费和广播消费的差异。我们来举个例子,以有两个消费者分组 A 和 B 的场景举例子:
- 假设每个消费者分组各启动一个实例,此时我们发送一条消息,该消息会被两个消费者分组
"consumer_group_01"和"consumer_group_02"都各自消费一次。 - 假设每个消费者分组各启动一个实例,此时我们发送一条消息,该消息会被分组 A 的某个实例消费一次,被分组 B 的某个实例也消费一次
通过集群消费的机制,我们可以实现针对相同 Topic ,不同消费者分组实现各自的业务逻辑。例如说:用户注册成功时,发送一条 Topic 为 "USER_REGISTER" 的消息。然后,不同模块使用不同的消费者分组,订阅该 Topic ,实现各自的拓展逻辑:
- 积分模块:判断如果是手机注册,给用户增加 20 积分。
- 优惠劵模块:因为是新用户,所以发放新用户专享优惠劵。
- 站内信模块:因为是新用户,所以发送新用户的欢迎语的站内信。
- ... 等等
这样,我们就可以将注册成功后的业务拓展逻辑,实现业务上的解耦,未来也更加容易拓展。同时,也提高了注册接口的性能,避免用户需要等待业务拓展逻辑执行完成后,才响应注册成功。
同时,相同消费者分组的多个实例,可以实现高可用,保证在一个实例意外挂掉的情况下,其它实例能够顶上。并且,多个实例都进行消费,能够提升消费速度。
友情提示:如果还不理解的话,没有关系,我们下面会演示下我们上面举的例子。
② 考虑到稍后我们要测试集群消费,所以我们要给 DEMO-TOPIC-01 Topic 创建多个 Partition。在 Kafka 中,Topic 是基于 Partition 分配到相同消费组下的消费者,从而进行消费消息的。如下图所示: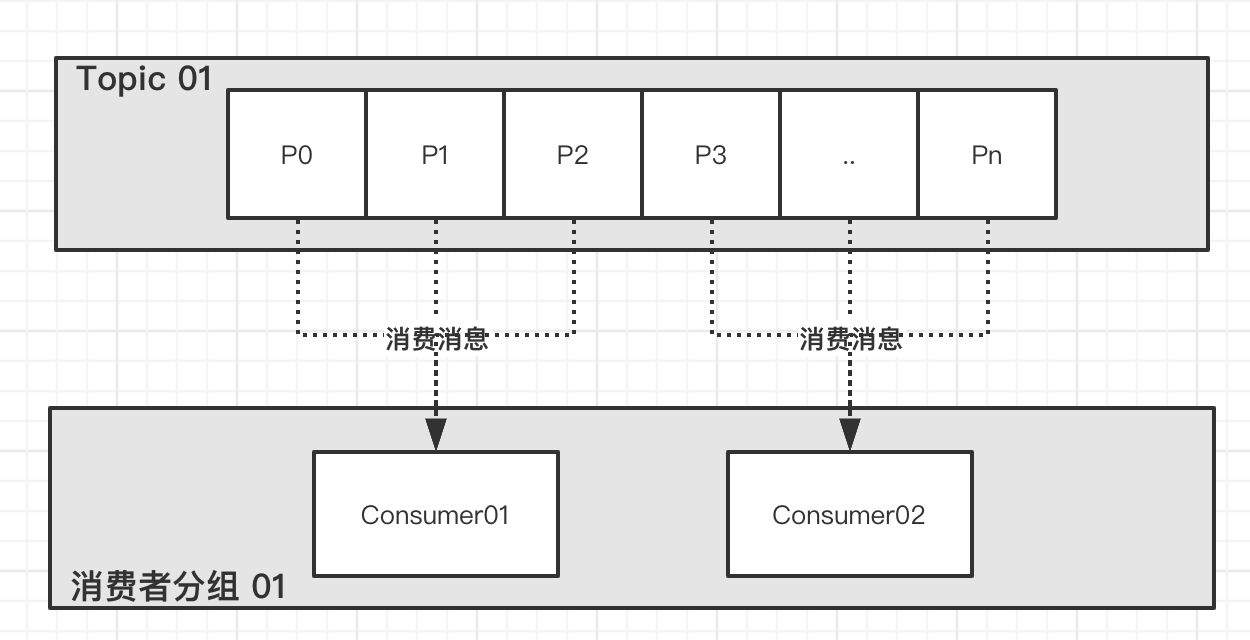
Partition(分区):Topic 物理上的分组,一个 Topic 可以分为多个 Partition ,每个 Partition 是一个有序的队列。Partition 中的每条消息都会被分配一个有序的 id(offset)。
这里,我们给 DEMO-TOPIC-01 Topic 创建 Partition 大小为 10。操作命令如下:
# 情况一,如果 `DEMO-TOPIC-01` Topic 未创建,则进行创建:
$ bin/kafka-topics.sh --zookeeper 127.0.0.1:2181 --create --topic my-topic --partitions 10 --replication-factor 1
# 情况二,如果 `DEMO-TOPIC-01` Topic 未创建,则进行修改 Partition 大小:
$ bin/kafka-topics.sh --zookeeper 127.0.0.1:2181 -alter --partitions 10 --topic DEMO-TOPIC-01
3.2.3 MySink
创建 MySink 接口,声明名字为 Input Binding。代码如下:
public interface MySink {
String DEMO01_INPUT = "demo01-input";
@Input(DEMO01_INPUT)
SubscribableChannel demo01Input();
}
这里,我们通过 @Input 注解,声明了一个名字为 demo01-input 的 Input Binding。注意,这个名字要和我们配置文件中的 spring.cloud.stream.bindings 配置项对应上。
同时,@Input 注解的方法的返回结果为 SubscribableChannel 类型,可以使用它订阅消息来消费。MessageChannel 提供的订阅消息的方法如下:
public interface SubscribableChannel extends MessageChannel {
boolean subscribe(MessageHandler handler); // 订阅
boolean unsubscribe(MessageHandler handler); // 取消订阅
}
那么,我们是否要实现 MySink 接口呢?答案也是不需要,还是全部交给 Spring Cloud Stream 的 BindableProxyFactory 大兄弟来解决。BindableProxyFactory 会通过动态代理,自动实现 MySink 接口。 而 @Input 注解的方法的返回值,BindableProxyFactory 会扫描带有 @Input 注解的方法,自动进行创建。
例如说,#demo01Input() 方法被自动创建返回结果为 DirectWithAttributesChannel,它也是 SubscribableChannel 的子类。
友情提示:感兴趣的胖友,可以在 BindableProxyFactory 的
#afterPropertiesSet()和#invoke(MethodInvocation invocation)方法上,都打上一个断点,然后进行愉快的调试。
3.2.4 Demo01Message
创建 Demo01Message 类,示例 Message 消息。
友情提示:和「3.1.4 Demo01Message」基本一样,点击 链接 查看。
3.2.5 Demo01Consumer
创建 Demo01Consumer 类,消费消息。代码如下:
@Component
public class Demo01Consumer {
private Logger logger = LoggerFactory.getLogger(getClass());
@StreamListener(MySink.DEMO01_INPUT)
public void onMessage(@Payload Demo01Message message) {
logger.info("[onMessage][线程编号:{} 消息内容:{}]", Thread.currentThread().getId(), message);
}
}
在方法上,添加 @StreamListener 注解,声明对应的 Input Binding。这里,我们使用 MySink.DEMO01_INPUT。
又因为我们消费的消息是 POJO 类型,所以我们需要添加 @Payload 注解,声明需要进行反序列化成 POJO 对象。
3.2.6 ConsumerApplication
创建 ConsumerApplication 类,启动应用。代码如下:
@SpringBootApplication
@EnableBinding(MySink.class)
public class ConsumerApplication {
public static void main(String[] args) {
SpringApplication.run(ConsumerApplication.class, args);
}
}
使用 @EnableBinding 注解,声明指定接口开启 Binding 功能,扫描其 @Input 和 @Output 注解。这里,我们设置为 MySink 接口。
3.3 测试单集群多实例的场景
本小节,我们会在一个消费者集群启动两个实例,测试在集群消费的情况下的表现。
① 执行 ConsumerApplication 两次,启动两个消费者的实例,从而实现在消费者分组 demo01-consumer-group 下有两个消费者实例。
友情提示:因为 IDEA 默认同一个程序只允许启动 1 次,所以我们需要配置 DemoProviderApplication 为
Allow parallel run。如下图所示:

② 执行 ProducerApplication,启动生产者的实例。
之后,请求 http://127.0.0.1:18080/demo01/send 接口十次,发送十条消息。此时在 IDEA 控制台看到消费者打印日志如下:
// ConsumerApplication 控制台 01
2020-03-08 20:59:50.461 INFO 65124 --- [container-0-C-1] c.i.s.l.k.c.listener.Demo01Consumer : [onMessage][线程编号:27 消息内容:Demo01Message{id=1983864145}]
2020-03-08 20:59:53.081 INFO 65124 --- [container-0-C-1] c.i.s.l.k.c.listener.Demo01Consumer : [onMessage][线程编号:27 消息内容:Demo01Message{id=-2014337623}]
2020-03-08 20:59:53.475 INFO 65124 --- [container-0-C-1] c.i.s.l.k.c.listener.Demo01Consumer : [onMessage][线程编号:27 消息内容:Demo01Message{id=-250644839}]
2020-03-08 20:59:53.844 INFO 65124 --- [container-0-C-1] c.i.s.l.k.c.listener.Demo01Consumer : [onMessage][线程编号:27 消息内容:Demo01Message{id=2143820238}]
2020-03-08 20:59:54.289 INFO 65124 --- [container-0-C-1] c.i.s.l.k.c.listener.Demo01Consumer : [onMessage][线程编号:27 消息内容:Demo01Message{id=1421045645}]
// ConsumerApplication 控制台 02
2020-03-08 20:59:51.009 INFO 65177 --- [container-0-C-1] c.i.s.l.k.c.listener.Demo01Consumer : [onMessage][线程编号:25 消息内容:Demo01Message{id=132504622}]
2020-03-08 20:59:51.416 INFO 65177 --- [container-0-C-1] c.i.s.l.k.c.listener.Demo01Consumer : [onMessage][线程编号:25 消息内容:Demo01Message{id=2052532135}]
2020-03-08 20:59:51.824 INFO 65177 --- [container-0-C-1] c.i.s.l.k.c.listener.Demo01Consumer : [onMessage][线程编号:25 消息内容:Demo01Message{id=-223534414}]
2020-03-08 20:59:52.262 INFO 65177 --- [container-0-C-1] c.i.s.l.k.c.listener.Demo01Consumer : [onMessage][线程编号:25 消息内容:Demo01Message{id=1525635094}]
2020-03-08 20:59:52.666 INFO 65177 --- [container-0-C-1] c.i.s.l.k.c.listener.Demo01Consumer : [onMessage][线程编号:25 消息内容:Demo01Message{id=-688399661}]
符合预期。从日志可以看出,每条消息仅被消费一次。
3.4 测试多集群多实例的场景
本小节,我们会在二个消费者集群各启动两个实例,测试在集群消费的情况下的表现。
① 执行 ConsumerApplication 两次,启动两个消费者的实例,从而实现在消费者分组 demo01-consumer-group 下有两个消费者实例。
② 修改 labx-11-sc-stream-kafka-consumer-demo 项目的配置文件,修改 spring.cloud.stream.bindings.demo01-input.group 配置项,将消费者分组改成 demo02-consumer-group。
然后,执行 ConsumerApplication 两次,再启动两个消费者的实例,从而实现在消费者分组 demo02-consumer-group 下有两个消费者实例。
③ 执行 ProducerApplication,启动生产者的实例。
之后,请求 http://127.0.0.1:18080/demo01/send 接口十次,发送十条消息。此时在 IDEA 控制台看到消费者打印日志如下:
// 消费者分组 `demo01-consumer-group` 的 ConsumerApplication 控制台 01
2020-03-08 21:07:34.728 INFO 65124 --- [container-0-C-1] c.i.s.l.k.c.listener.Demo01Consumer : [onMessage][线程编号:27 消息内容:Demo01Message{id=-1737808914}]
2020-03-08 21:07:37.728 INFO 65124 --- [container-0-C-1] c.i.s.l.k.c.listener.Demo01Consumer : [onMessage][线程编号:27 消息内容:Demo01Message{id=-2140451405}]
2020-03-08 21:07:38.203 INFO 65124 --- [container-0-C-1] c.i.s.l.k.c.listener.Demo01Consumer : [onMessage][线程编号:27 消息内容:Demo01Message{id=813702607}]
2020-03-08 21:07:38.601 INFO 65124 --- [container-0-C-1] c.i.s.l.k.c.listener.Demo01Consumer : [onMessage][线程编号:27 消息内容:Demo01Message{id=-1028557655}]
2020-03-08 21:07:39.024 INFO 65124 --- [container-0-C-1] c.i.s.l.k.c.listener.Demo01Consumer : [onMessage][线程编号:27 消息内容:Demo01Message{id=-399853121}]
// 消费者分组 `demo01-consumer-group` 的 ConsumerApplication 控制台 02
2020-03-08 21:07:35.196 INFO 65177 --- [container-0-C-1] c.i.s.l.k.c.listener.Demo01Consumer : [onMessage][线程编号:25 消息内容:Demo01Message{id=-1461873560}]
2020-03-08 21:07:35.717 INFO 65177 --- [container-0-C-1] c.i.s.l.k.c.listener.Demo01Consumer : [onMessage][线程编号:25 消息内容:Demo01Message{id=-1947944757}]
2020-03-08 21:07:36.176 INFO 65177 --- [container-0-C-1] c.i.s.l.k.c.listener.Demo01Consumer : [onMessage][线程编号:25 消息内容:Demo01Message{id=151575160}]
2020-03-08 21:07:36.789 INFO 65177 --- [container-0-C-1] c.i.s.l.k.c.listener.Demo01Consumer : [onMessage][线程编号:25 消息内容:Demo01Message{id=88228856}]
2020-03-08 21:07:37.272 INFO 65177 --- [container-0-C-1] c.i.s.l.k.c.listener.Demo01Consumer : [onMessage][线程编号:25 消息内容:Demo01Message{id=790199000}]
// 消费者分组 `demo02-consumer-group` 的 ConsumerApplication 控制台 01
2020-03-08 21:07:35.196 INFO 65419 --- [container-0-C-1] c.i.s.l.k.c.listener.Demo01Consumer : [onMessage][线程编号:25 消息内容:Demo01Message{id=-1461873560}]
2020-03-08 21:07:35.717 INFO 65419 --- [container-0-C-1] c.i.s.l.k.c.listener.Demo01Consumer : [onMessage][线程编号:25 消息内容:Demo01Message{id=-1947944757}]
2020-03-08 21:07:36.176 INFO 65419 --- [container-0-C-1] c.i.s.l.k.c.listener.Demo01Consumer : [onMessage][线程编号:25 消息内容:Demo01Message{id=151575160}]
2020-03-08 21:07:36.789 INFO 65419 --- [container-0-C-1] c.i.s.l.k.c.listener.Demo01Consumer : [onMessage][线程编号:25 消息内容:Demo01Message{id=88228856}]
2020-03-08 21:07:37.272 INFO 65419 --- [container-0-C-1] c.i.s.l.k.c.listener.Demo01Consumer : [onMessage][线程编号:25 消息内容:Demo01Message{id=790199000}]
// 消费者分组 `demo02-consumer-group` 的 ConsumerApplication 控制台 02
2020-03-08 21:07:34.728 INFO 65422 --- [container-0-C-1] c.i.s.l.k.c.listener.Demo01Consumer : [onMessage][线程编号:25 消息内容:Demo01Message{id=-1737808914}]
2020-03-08 21:07:37.728 INFO 65422 --- [container-0-C-1] c.i.s.l.k.c.listener.Demo01Consumer : [onMessage][线程编号:25 消息内容:Demo01Message{id=-2140451405}]
2020-03-08 21:07:38.204 INFO 65422 --- [container-0-C-1] c.i.s.l.k.c.listener.Demo01Consumer : [onMessage][线程编号:25 消息内容:Demo01Message{id=813702607}]
2020-03-08 21:07:38.601 INFO 65422 --- [container-0-C-1] c.i.s.l.k.c.listener.Demo01Consumer : [onMessage][线程编号:25 消息内容:Demo01Message{id=-1028557655}]
2020-03-08 21:07:39.024 INFO 65422 --- [container-0-C-1] c.i.s.l.k.c.listener.Demo01Consumer : [onMessage][线程编号:25 消息内容:Demo01Message{id=-399853121}]
符合预期。从日志可以看出,每条消息被每个消费者集群都进行了消费,且仅被消费一次。
3.5 小结
至此,我们已经完成了 Stream Kafka 的快速入门,是不是还是蛮简答的噢。现在胖友可以在回过头看看 Binder 和 Binding 的概念,是不是就清晰一些了。
4. 定时消息
Kafka 并未提供定时消息的功能,需要我们自行拓展。
例如说《基于 Kafka 的定时消息/任务服》文章,提供的方案。
当然,也可以考虑基于 MySQL 存储定时消息,Job 扫描到达时间的定时消息,发送给 Kafka 。
5. 消费重试
示例代码对应仓库:
Spring-Kafka 提供消费重试的机制。在消息消费失败的时候,Spring-Kafka 会通过消费重试机制,重新投递该消息给 Consumer ,让 Consumer 有机会重新消费消息,实现消费成功。
友情提示:Spring Cloud Stream Kafka 是基于 Spring-Kafka 操作 Kafka,它仅仅是上层的封装哟。
当然,Spring-Kafka 并不会无限重新投递消息给 Consumer 重新消费,而是在默认情况下,达到 N 次重试次数时,Consumer 还是消费失败时,该消息就会进入到死信队列。
死信队列用于处理无法被正常消费的消息。当一条消息初次消费失败,Spring-Kafka 会自动进行消息重试;达到最大重试次数后,若消费依然失败,则表明消费者在正常情况下无法正确地消费该消息,此时,Spring-Kafka 不会立刻将消息丢弃,而是将其发送到该消费者对应的特殊队列中。
Spring-Kafka 将这种正常情况下无法被消费的消息称为死信消息(Dead-Letter Message),将存储死信消息的特殊队列称为死信队列(Dead-Letter Queue)。后续,我们可以通过对死信队列中的消息进行重发,来使得消费者实例再次进行消费。
- 在《芋道 Spring Boot 消息队列 RocketMQ 入门》的「6. 消费重试」小节中,我们可以看到,消费重试和死信队列,是 RocketMQ 自带的功能。
- 而在 Kafka 中,消费重试和死信队列,是由 Spring-Kafka 所封装提供的。
每条消息的失败重试,是可以配置一定的间隔时间。具体,我们在示例的代码中,来进行具体的解释。
下面,我们来实现一个 Consumer 消费重试的示例。最终项目如下图所示: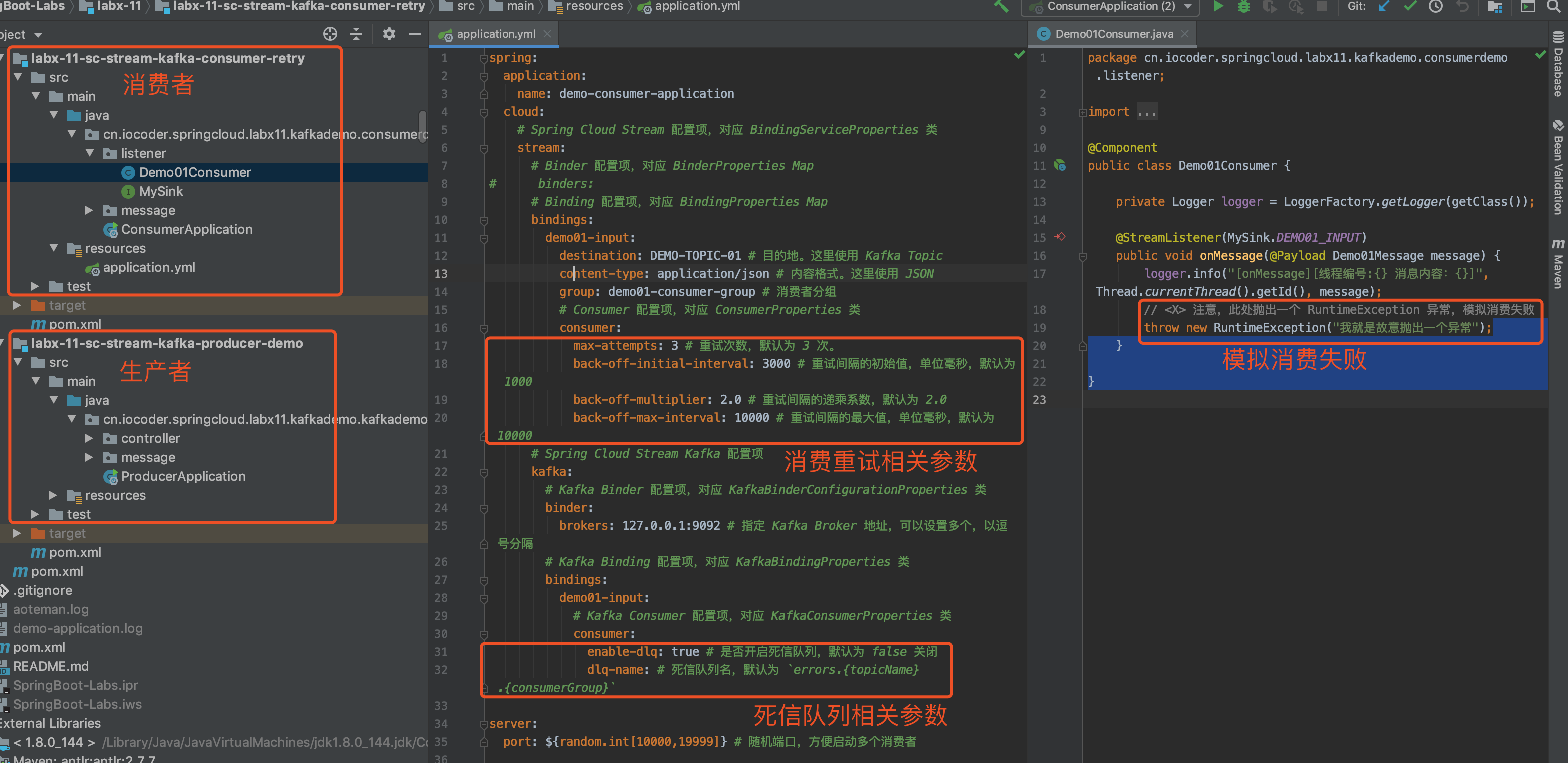
5.1 搭建生产者
直接使用「3. 快速入门」小节的 labx-11-sc-stream-kafka-producer-demo 项目即可。
5.2 搭建消费者
从「3. 快速入门」小节的 labx-11-sc-stream-kafka-consumer-demo 项目,复制出 labx-11-sc-stream-kafka-consumer-retry 项目作为消费者。
5.2.1 配置文件
修改 application.yml 配置文件,增加消费重试相关的配置项。最终配置如下:
spring:
application:
name: demo-consumer-application
cloud:
# Spring Cloud Stream 配置项,对应 BindingServiceProperties 类
stream:
# Binder 配置项,对应 BinderProperties Map
# binders:
# Binding 配置项,对应 BindingProperties Map
bindings:
demo01-input:
destination: DEMO-TOPIC-01 # 目的地。这里使用 Kafka Topic
content-type: application/json # 内容格式。这里使用 JSON
group: demo01-consumer-group # 消费者分组
# Consumer 配置项,对应 ConsumerProperties 类
consumer:
max-attempts: 3 # 重试次数,默认为 3 次。
back-off-initial-interval: 3000 # 重试间隔的初始值,单位毫秒,默认为 1000
back-off-multiplier: 2.0 # 重试间隔的递乘系数,默认为 2.0
back-off-max-interval: 10000 # 重试间隔的最大值,单位毫秒,默认为 10000
# Spring Cloud Stream Kafka 配置项
kafka:
# Kafka Binder 配置项,对应 KafkaBinderConfigurationProperties 类
binder:
brokers: 127.0.0.1:9092 # 指定 Kafka Broker 地址,可以设置多个,以逗号分隔
# Kafka Binding 配置项,对应 KafkaBindingProperties 类
bindings:
demo01-input:
# Kafka Consumer 配置项,对应 KafkaConsumerProperties 类
consumer:
enable-dlq: true # 是否开启死信队列,默认为 false 关闭
dlq-name: # 死信队列名,默认为 `errors.{topicName}.{consumerGroup}`
server:
port: ${random.int[10000,19999]} # 随机端口,方便启动多个消费者
① spring.cloud.stream.bindings.<bindingName>.consumer 为 Spring Cloud Stream Consumer 通用配置项,对应 ConsumerProperties 类。
-
max-attempts:最大重试次数,默认为 3 次。如果想要禁用掉重试,可以设置为 1。max-attempts配置项要注意,是一条消息一共尝试消费总共max-attempts次,包括首次的正常消费。 -
back-off-initial-interval:重试间隔的初始值,单位毫秒,默认为 1000。 -
back-off-multiplier:重试间隔的递乘系数,默认为 2.0。 -
back-off-max-interval:重试间隔的最大值,单位毫秒,默认为 10000。
将四个参数组合在一起,我们来看一个消费重试的过程:
- 第一次 00:00:00:首次消费,失败。
- 第二次 00:00:03:3 秒后重试,因为重试间隔的初始值为
back-off-initial-interval,等于 3000 毫秒。 - 第三次 00:00:09:6 秒后重试,因为有重试间隔的递乘系数
back-off-multiplier,所以是2.0 * 3000等于 6000 毫秒。 - 第四次,没有,因为到达最大重试次数,等于 3。
② spring.cloud.stream.kafka.bindings.<bindingName>.consumer 为 Spring Cloud Stream Kafka Consumer 专属配置项,我们新增了两个配置项:
enable-dlq:是否开启死信队列,默认为false关闭。这里,问问们设置为true来进行开启。dlq-name:死信队列名,默认为errors.{topicName}.{consumerGroup}。这里我们并未设置,直接使用默认,即本小节的示例对应errors.DEMO-TOPIC-01.demo01-consumer-group。
5.2.2 Demo01Consumer
修改 Demo01Consumer 类,直接抛出异常,模拟消费失败,从而演示消费重试的功能。代码如下:
@Component
public class Demo01Consumer {
private Logger logger = LoggerFactory.getLogger(getClass());
@StreamListener(MySink.DEMO01_INPUT)
public void onMessage(@Payload Demo01Message message) {
logger.info("[onMessage][线程编号:{} 消息内容:{}]", Thread.currentThread().getId(), message);
// <X> 注意,此处抛出一个 RuntimeException 异常,模拟消费失败
throw new RuntimeException("我就是故意抛出一个异常");
}
}
5.3 简单测试
① 执行 ConsumerApplication,启动一个消费者的实例。
我们打开 Kafka 运维界面,可以看到多了一个 errors.DEMO-TOPIC-01.demo01-consumer-group Topic,即本小节的死信队列。如下图所示: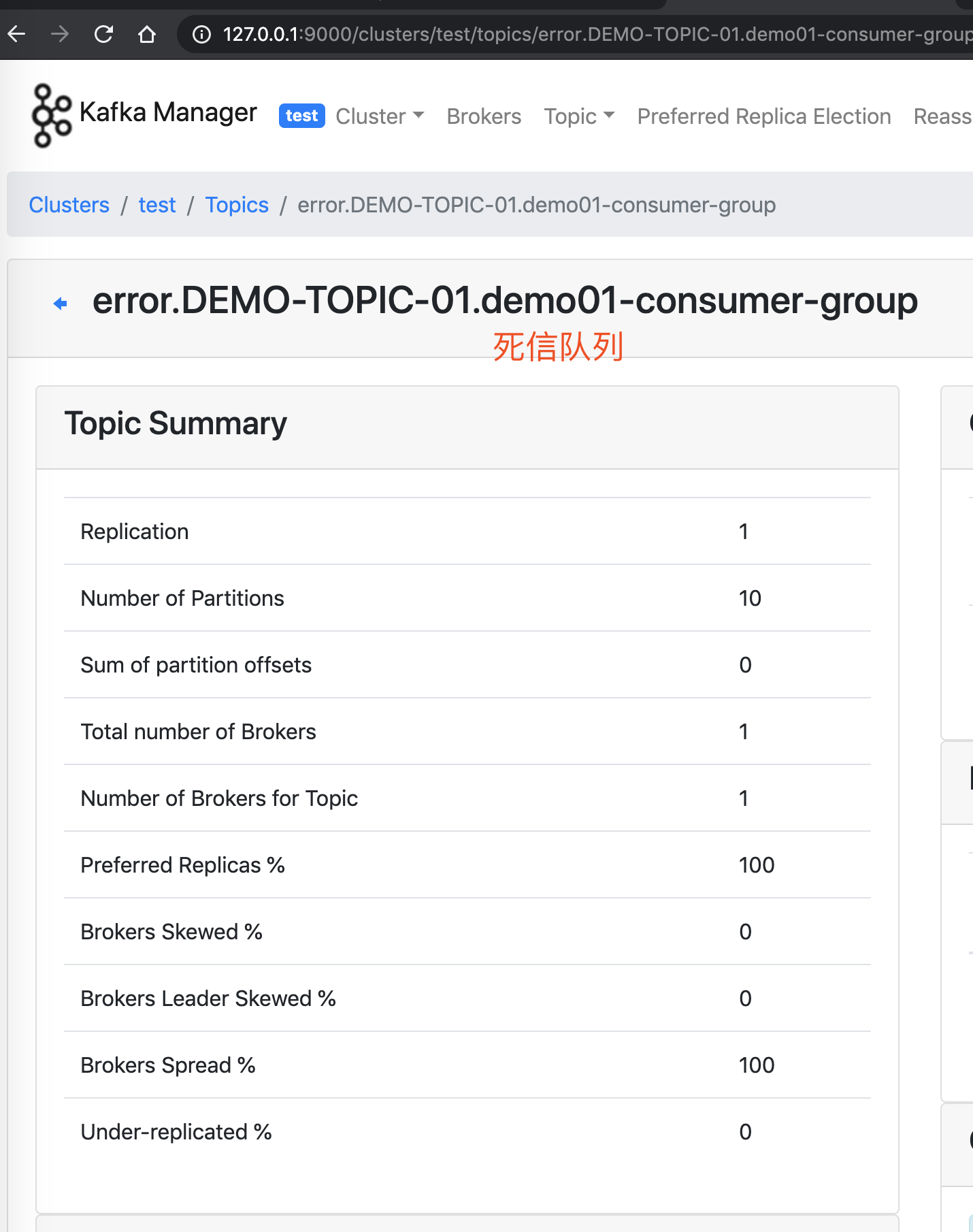
友情提示:Kafka 运维界面,可以看看《芋道 Kafka 极简入门》文章的「4. Kafka Manager」小节。
② 执行 ProducerApplication,启动生产者的实例。
之后,请求 http://127.0.0.1:18080/demo01/send 接口,发送消息。IDEA 控制台输出日志如下:
// 第一次消费
2020-03-08 22:14:55.465 INFO 67252 --- [container-0-C-1] c.i.s.l.k.c.listener.Demo01Consumer : [onMessage][线程编号:27 消息内容:Demo01Message{id=-1264911073}]
// 第二次消费,3 秒后
2020-03-08 22:14:58.467 INFO 67252 --- [container-0-C-1] c.i.s.l.k.c.listener.Demo01Consumer : [onMessage][线程编号:27 消息内容:Demo01Message{id=-1264911073}]
// 第三次消费,6 秒后
2020-03-08 22:15:04.471 INFO 67252 --- [container-0-C-1] c.i.s.l.k.c.listener.Demo01Consumer : [onMessage][线程编号:27 消息内容:Demo01Message{id=-1264911073}]
// 内置的 LoggingHandler 打印异常日志
2020-03-08 22:15:04.473 ERROR 67252 --- [container-0-C-1] o.s.integration.handler.LoggingHandler : org.springframework.messaging.MessagingException: Exception thrown while invoking Demo01Consumer#onMessage[1 args]; nested exception is java.lang.RuntimeException: 我就是故意抛出一个异常 // ... 省略异常堆栈
Caused by: java.lang.RuntimeException: 我就是故意抛出一个异常 // ... 省略异常堆栈
测试 Consumer 消费重试成功~
不过要注意,目前我们看到的重试方案,是通过 RetryTemplate 来实现客户端级别的消费冲水。而 RetryTemplate 又是通过 sleep 来实现消费间隔的时候,这样将影响 Consumer 的整体消费速度,毕竟 sleep 会占用掉线程。
6. 消费异常处理机制
示例代码对应仓库:
在 Spring Cloud Stream 中,提供了通用的消费异常处理机制,可以拦截到消费者消费消息时发生的异常,进行自定义的处理逻辑。
下面,我们来搭建一个 Spring Cloud Stream 消费异常处理机制的示例。最终项目如下图所示: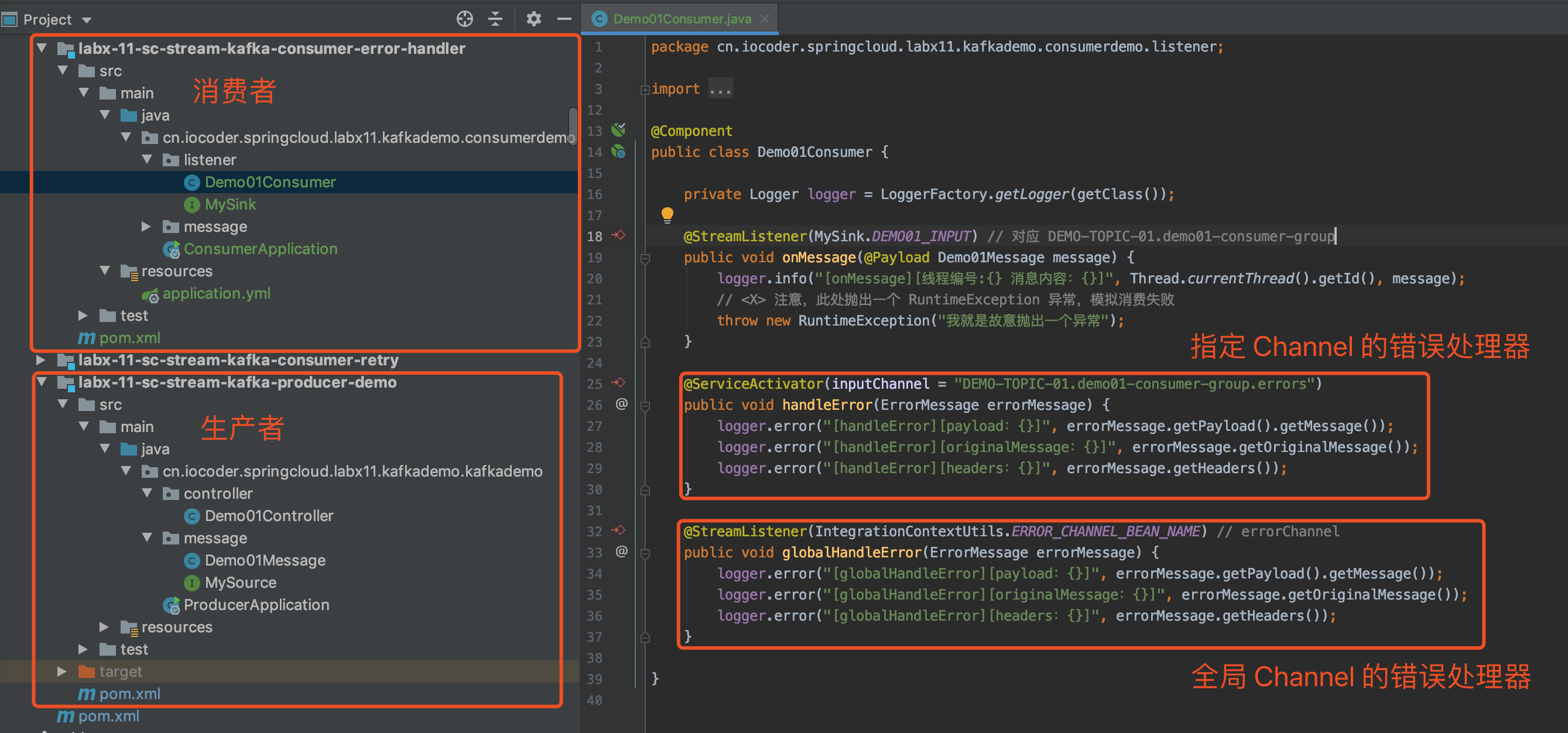
6.1 搭建生产者
直接使用「3. 快速入门」小节的 labx-11-sc-stream-kafka-producer-demo 项目即可。
6.2 搭建消费者
从「5. 消费重试」小节的 labx-11-sc-stream-kafka-consumer-retry 项目,复制出 labx-11-sc-stream-kafka-consumer-error-handler 项目作为消费者。
6.2.1 Demo01Consumer
修改 Demo01Consumer 类,增加消费异常处理方法。完整代码如下:
@Component
public class Demo01Consumer {
private Logger logger = LoggerFactory.getLogger(getClass());
@StreamListener(MySink.DEMO01_INPUT)
public void onMessage(@Payload Demo01Message message) {
logger.info("[onMessage][线程编号:{} 消息内容:{}]", Thread.currentThread().getId(), message);
// <X> 注意,此处抛出一个 RuntimeException 异常,模拟消费失败
throw new RuntimeException("我就是故意抛出一个异常");
}
@ServiceActivator(inputChannel = "DEMO-TOPIC-01.demo01-consumer-group.errors")
public void handleError(ErrorMessage errorMessage) {
logger.error("[handleError][payload:{}]", errorMessage.getPayload().getMessage());
logger.error("[handleError][originalMessage:{}]", errorMessage.getOriginalMessage());
logger.error("[handleError][headers:{}]", errorMessage.getHeaders());
}
@StreamListener(IntegrationContextUtils.ERROR_CHANNEL_BEAN_NAME) // errorChannel
public void globalHandleError(ErrorMessage errorMessage) {
logger.error("[globalHandleError][payload:{}]", errorMessage.getPayload().getMessage());
logger.error("[globalHandleError][originalMessage:{}]", errorMessage.getOriginalMessage());
logger.error("[globalHandleError][headers:{}]", errorMessage.getHeaders());
}
}
① 在 Spring Integration 的设定中,若 #onMessage(@Payload Demo01Message message) 方法消费消息发生异常时,会发送错误消息(ErrorMessage)到对应的错误 Channel(<destination>.<group>.errors)*中。同时,所有错误 Channel 都桥接到了 Spring Integration 定义的*全局错误 Channel(errorChannel)。
友情提示:先暂时记住 Spring Integration 这样的设定,艿艿也没去深究 T T,也是一脸懵逼。
因此,我们有两种方式来实现异常处理:
- 局部的异常处理:通过订阅指定错误 Channel
- 全局的异常处理:通过订阅全局错误 Channel
② 在 #handleError(ErrorMessage errorMessage) 方法上,我们声明了 @ServiceActivator 注解,订阅指定错误 Channel的错误消息,实现 #onMessage(@Payload Demo01Message message) 方法的局部异常处理。如下图所示: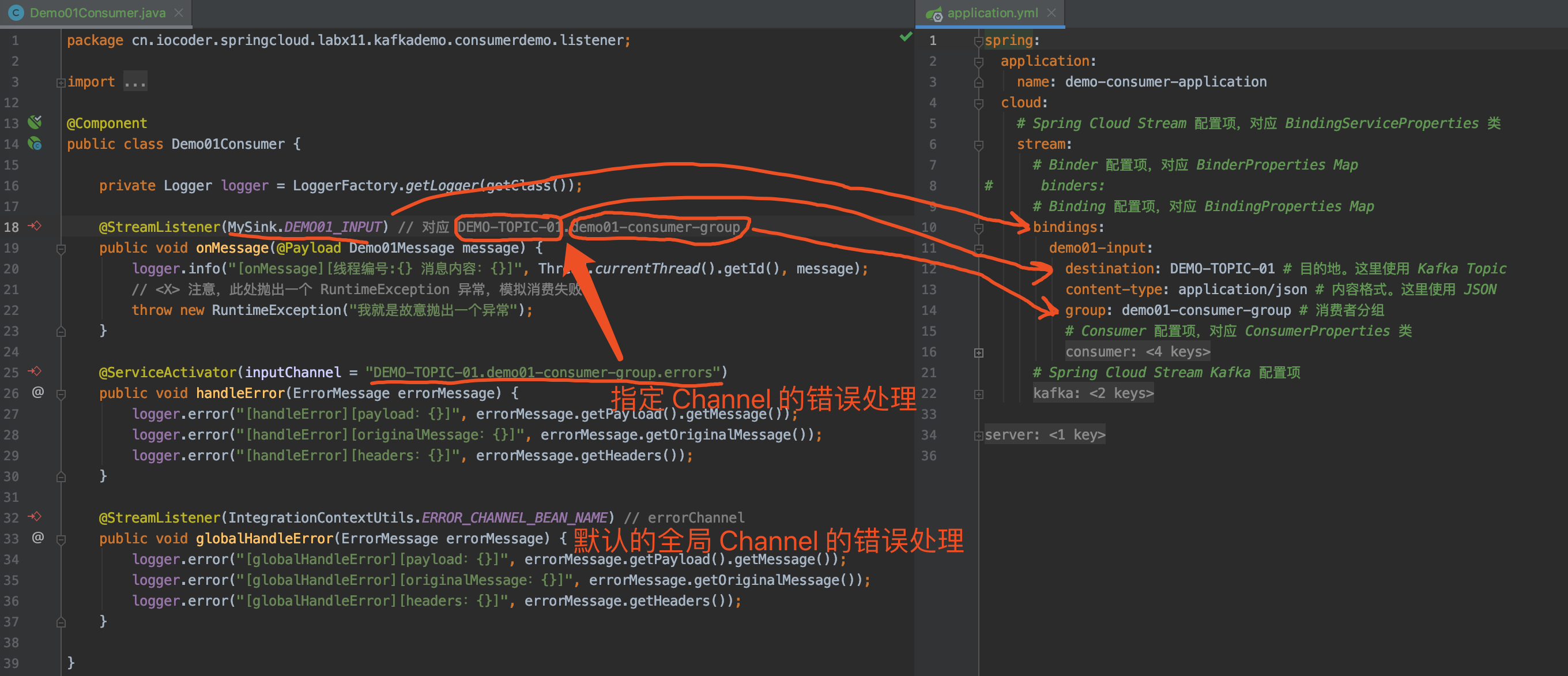
③ 在 #globalHandleError(ErrorMessage errorMessage) 方法上,我们声明了 @StreamListener 注解,订阅全局错误 Channel的错误消息,实现全局异常处理。
④ 在全局和局部异常处理都定义的情况下,错误消息仅会被符合条件的局部错误异常处理。如果没有符合条件的,错误消息才会被全局异常处理。
6.3 简单测试
① 执行 ConsumerApplication,启动消费者的实例。
② 执行 ProducerApplication,启动生产者的实例。
之后,请求 http://127.0.0.1:18080/demo01/send 接口,发送一条消息。IDEA 控制台输出日志如下:
// onMessage 方法,一共 3 次,包括重试
2020-03-09 07:38:23.037 INFO 68126 --- [container-0-C-1] c.i.s.l.k.c.listener.Demo01Consumer : [onMessage][线程编号:28 消息内容:Demo01Message{id=-1512001860}]
2020-03-09 07:38:26.045 INFO 68126 --- [container-0-C-1] c.i.s.l.k.c.listener.Demo01Consumer : [onMessage][线程编号:28 消息内容:Demo01Message{id=-1512001860}]
2020-03-09 07:38:32.046 INFO 68126 --- [container-0-C-1] c.i.s.l.k.c.listener.Demo01Consumer : [onMessage][线程编号:28 消息内容:Demo01Message{id=-1512001860}]
// handleError 方法
2020-03-09 07:38:32.054 ERROR 68126 --- [container-0-C-1] c.i.s.l.k.c.listener.Demo01Consumer : [handleError][payload:Exception thrown while invoking Demo01Consumer#onMessage[1 args]; nested exception is java.lang.RuntimeException: 我就是故意抛出一个异常]
2020-03-09 07:38:32.054 ERROR 68126 --- [container-0-C-1] c.i.s.l.k.c.listener.Demo01Consumer : [handleError][originalMessage:GenericMessage [payload=byte[18], headers={kafka_offset=45, scst_nativeHeadersPresent=true, kafka_consumer=org.apache.kafka.clients.consumer.KafkaConsumer@e32f669, deliveryAttempt=3, kafka_timestampType=CREATE_TIME, kafka_receivedMessageKey=null, kafka_receivedPartitionId=0, contentType=application/json, kafka_receivedTopic=DEMO-TOPIC-01, kafka_receivedTimestamp=1583710702910, kafka_groupId=demo01-consumer-group}]]
2020-03-09 07:38:32.054 ERROR 68126 --- [container-0-C-1] c.i.s.l.k.c.listener.Demo01Consumer : [handleError][headers:{kafka_data=ConsumerRecord(topic = DEMO-TOPIC-01, partition = 0, leaderEpoch = 0, offset = 45, CreateTime = 1583710702910, serialized key size = -1, serialized value size = 18, headers = RecordHeaders(headers = [RecordHeader(key = contentType, value = [34, 97, 112, 112, 108, 105, 99, 97, 116, 105, 111, 110, 47, 106, 115, 111, 110, 34]), RecordHeader(key = spring_json_header_types, value = [123, 34, 99, 111, 110, 116, 101, 110, 116, 84, 121, 112, 101, 34, 58, 34, 106, 97, 118, 97, 46, 108, 97, 110, 103, 46, 83, 116, 114, 105, 110, 103, 34, 125])], isReadOnly = false), key = null, value = [B@57ae40f0), id=e6852311-62b5-cc85-1f63-cef9a01847a2, sourceData=ConsumerRecord(topic = DEMO-TOPIC-01, partition = 0, leaderEpoch = 0, offset = 45, CreateTime = 1583710702910, serialized key size = -1, serialized value size = 18, headers = RecordHeaders(headers = [RecordHeader(key = contentType, value = [34, 97, 112, 112, 108, 105, 99, 97, 116, 105, 111, 110, 47, 106, 115, 111, 110, 34]), RecordHeader(key = spring_json_header_types, value = [123, 34, 99, 111, 110, 116, 101, 110, 116, 84, 121, 112, 101, 34, 58, 34, 106, 97, 118, 97, 46, 108, 97, 110, 103, 46, 83, 116, 114, 105, 110, 103, 34, 125])], isReadOnly = false), key = null, value = [B@57ae40f0), timestamp=1583710712046}]
😆 不过要注意,如果异常处理方法成功,没有重新抛出异常,会认定为该消息被消费成功,所以就不会发到死信队列了噢。
7. 广播消费
示例代码对应仓库:
在上述的示例中,我们看到的都是使用集群消费。而在一些场景下,我们需要使用广播消费。
广播消费模式下,相同 Consumer Group 的每个 Consumer 实例都接收全量的消息。
使用场景?
例如说,在应用中,缓存了数据字典等配置表在内存中,可以通过 Kafka 广播消费,实现每个应用节点都消费消息,刷新本地内存的缓存。
又例如说,我们基于 WebSocket 实现了 IM 聊天,在我们给用户主动发送消息时,因为我们不知道用户连接的是哪个提供 WebSocket 的应用,所以可以通过 Kafka 广播消费,每个应用判断当前用户是否是和自己提供的 WebSocket 服务连接,如果是,则推送消息给用户。
如何实现?
不过 Kafka 并不直接提供内置的广播消费的功能!!!此时,我们只能退而求其次,每个 Consumer 独有一个 Consumer Group ,从而保证都能接收到全量的消息
恰好,Spring Cloud Stream RabbitMQ 在设置 Consumer 的消费者分组为空时,会为该 Consumer 生成一个独有的随机的消费者分组,从而实现广播消费的功能。
下面,我们来实现一个 Consumer 广播消费的示例。最终项目如下图所示: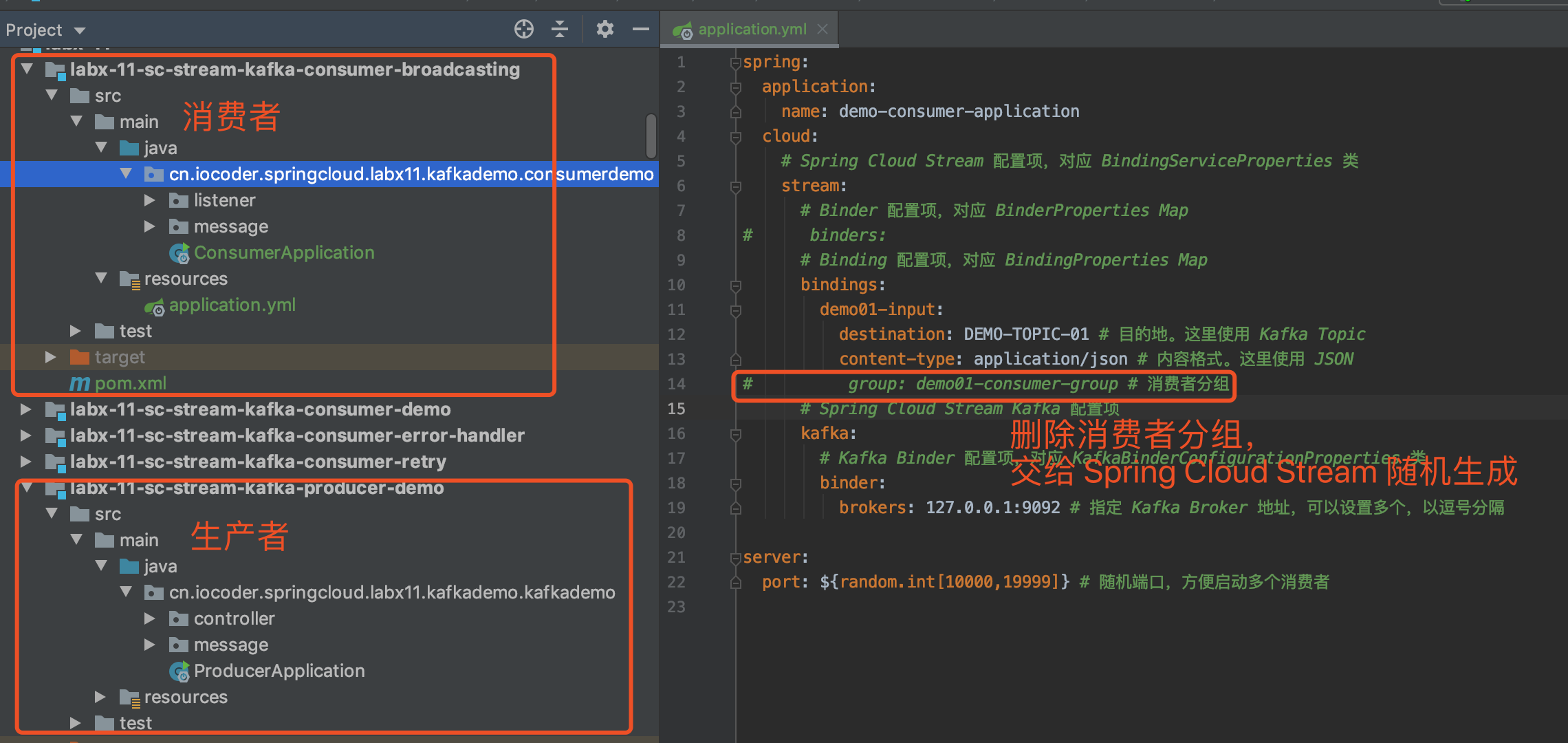
7.1 搭建生产者
直接使用「3. 快速入门」小节的 labx-11-sc-stream-kafka-producer-demo 项目即可。
7.2 搭建消费者
从「3. 快速入门」小节的 labx-11-sc-stream-kafka-consumer-demo 项目,复制出 labx-11-sc-stream-kafka-consumer-broadcasting 项目作为消费者。
7.2.1 配置文件
修改 application.yml 配置文件,删除 Consumer 的消费者分组配置项 group 即可。完整配置如下:
spring:
application:
name: demo-consumer-application
cloud:
# Spring Cloud Stream 配置项,对应 BindingServiceProperties 类
stream:
# Binder 配置项,对应 BinderProperties Map
# binders:
# Binding 配置项,对应 BindingProperties Map
bindings:
demo01-input:
destination: DEMO-TOPIC-01 # 目的地。这里使用 Kafka Topic
content-type: application/json # 内容格式。这里使用 JSON
# group: demo01-consumer-group # 消费者分组
# Spring Cloud Stream Kafka 配置项
kafka:
# Kafka Binder 配置项,对应 KafkaBinderConfigurationProperties 类
binder:
brokers: 127.0.0.1:9092 # 指定 Kafka Broker 地址,可以设置多个,以逗号分隔
server:
port: ${random.int[10000,19999]} # 随机端口,方便启动多个消费者
7.3 简单测试
① 执行 ConsumerApplication 两次,启动两个消费者的实例。
我们打开 Kafka 运维界面,可以看到 Spring Cloud Stream Kafka 生成的以 anonymous. 开头的消费者分组。如下图所示:
同时我们在 IDEA 控制台的日志中,也可以看 Spring Cloud Stream Kafka 生成的以 anonymous. 开头的消费者分组。如下所示:
// ConsumerApplication 控制台 01
2020-03-09 08:13:54.091 INFO 68839 --- [container-0-C-1] c.i.s.l.k.c.listener.Demo01Consumer : [onMessage][线程编号:25 消息内容:Demo01Message{id=-1092051199}]
2020-03-09 08:13:54.422 INFO 68839 --- [container-0-C-1] c.i.s.l.k.c.listener.Demo01Consumer : [onMessage][线程编号:25 消息内容:Demo01Message{id=-618964293}]
2020-03-09 08:13:54.721 INFO 68839 --- [container-0-C-1] c.i.s.l.k.c.listener.Demo01Consumer : [onMessage][线程编号:25 消息内容:Demo01Message{id=94760781}]
// ConsumerApplication 控制台 02
2020-03-09 08:13:54.092 INFO 68852 --- [container-0-C-1] c.i.s.l.k.c.listener.Demo01Consumer : [onMessage][线程编号:26 消息内容:Demo01Message{id=-1092051199}]
2020-03-09 08:13:54.422 INFO 68852 --- [container-0-C-1] c.i.s.l.k.c.listener.Demo01Consumer : [onMessage][线程编号:26 消息内容:Demo01Message{id=-618964293}]
2020-03-09 08:13:54.721 INFO 68852 --- [container-0-C-1] c.i.s.l.k.c.listener.Demo01Consumer : [onMessage][线程编号:26 消息内容:Demo01Message{id=94760781}]
② 执行 ProducerApplication,启动生产者的实例。
之后,请求 http://127.0.0.1:18080/demo01/send 接口三次,发送三条消息。IDEA 控制台输出日志如下:
// ConsumerApplication 控制台 01
2020-03-07 15:43:35.883 INFO 46486 --- [Z-_87KO2Pl-WQ-1] c.i.s.l.r.c.listener.Demo01Consumer : [onMessage][线程编号:28 消息内容:Demo01Message{id=2084635466}]
2020-03-07 15:43:37.278 INFO 46486 --- [Z-_87KO2Pl-WQ-1] c.i.s.l.r.c.listener.Demo01Consumer : [onMessage][线程编号:28 消息内容:Demo01Message{id=-2118253111}]
2020-03-07 15:43:37.652 INFO 46486 --- [Z-_87KO2Pl-WQ-1] c.i.s.l.r.c.listener.Demo01Consumer : [onMessage][线程编号:28 消息内容:Demo01Message{id=1956010289}]
// ConsumerApplication 控制台 02
2020-03-07 15:43:35.884 INFO 46527 --- [2e8iPDhSVKdcg-1] c.i.s.l.r.c.listener.Demo01Consumer : [onMessage][线程编号:28 消息内容:Demo01Message{id=2084635466}]
2020-03-07 15:43:37.278 INFO 46527 --- [2e8iPDhSVKdcg-1] c.i.s.l.r.c.listener.Demo01Consumer : [onMessage][线程编号:28 消息内容:Demo01Message{id=-2118253111}]
2020-03-07 15:43:37.652 INFO 46527 --- [2e8iPDhSVKdcg-1] c.i.s.l.r.c.listener.Demo01Consumer : [onMessage][线程编号:28 消息内容:Demo01Message{id=1956010289}]
符合预期。从日志可以看出,每条消息仅被每个消费者消费了一次。
8. 并发消费
示例代码对应仓库:
在上述的示例中,我们配置的每一个 Binding 的 Consumer,都是串行消费的。显然,这在监听的 Topic 每秒消息量比较大的时候,会导致消费不及时,导致消息积压的问题。
虽然说,我们可以通过启动多个 JVM 进程,实现多进程的并发消费,从而加速消费的速度。但是问题是,否能够实现多线程的并发消费呢?答案是有。
通过在配置文件中的 spring.cloud.stream.bindings.<bindingName>.consumer.concurrency 配置项,可以指定该 Binder 并发消费的线程数。例如说,如果设置 concurrency=10 时,Spring Cloud Stream Kafka 就会为该 Binder 创建 10 个线程,进行并发消费。
考虑到让胖友能够更好的理解 concurrency 属性,我们来简单说说 Spring-Kafka 在这块的实现方式。我们来举个例子:
- 首先,我们来创建一个 Topic 为
"DEMO-TOPIC-01",并且设置其 Partition 分区数为 10 。 - 然后,我们创建一个用于 Consumer 的 Binding 配置,并设置
concurrency配置项为 2。 - 再然后,我们启动项目。Spring-Kafka 会根据 Binding 的
concurrency配置项为 2,为该 Binding 创建 2 个 Kafka Consumer 。注意噢,是 2 个 Kafka Consumer 呢!!!后续,每个 Kafka Consumer 会被单独分配到一个线程中,进行拉取消息,消费消息。 - 之后,Kafka Broker 会将 Topic 为
"DEMO-TOPIC-01"分配给创建的 2 个 Kafka Consumer 各 5 个 Partition 。😈 如果不了解 Kafka Broker “分配区分”机制单独胖友,可以看看 《Kafka 消费者如何分配分区》 文章。 - 这样,因为用于 Consumer 的 Binding 的
concurrency配置项为 2,创建 2 个 Kafka Consumer ,就在各自的线程中,拉取各自的 Topic 为"DEMO-TOPIC-01"的 Partition 的消息,各自串行消费。从而,实现多线程的并发消费。
酱紫讲解一下,胖友对 Spring-Kafka 实现多线程的并发消费的机制,是否理解了。不过有一点要注意,不要配置 concurrency 属性过大,则创建的 Kafka Consumer 分配不到消费 Topic 的 Partition 分区,导致不断的空轮询。
友情提示:可以选择不看。
在理解 Spring-Kafka 提供的并发消费机制,花费了好几个小时,主要陷入到了一个误区。
如果胖友有使用过 RocketMQ 的并发消费,会发现只要创建一个 RocketMQ Consumer 对象,然后 Consumer 拉取完消息之后,丢到 Consumer 的线程池中执行消费,从而实现并发消费。
而在 Spring-Kafka 提供的并发消费,会发现需要创建多个 Kafka Consumer 对象,并且每个 Consumer 都单独分配一个线程,然后 Consumer 拉取完消息之后,在各自的线程中执行消费。
又或者说,Spring-Kafka 提供的并发消费,很像 RocketMQ 的顺序消费。😈 从感受上来说,Spring-Kafka 的并发消费像 BIO ,RocketMQ 的并发消费像 NIO 。
不过,理论来说,在原生的 Kafka 客户端,也是能封装出和 RocketMQ Consumer 一样的并发消费的机制。
也因此,在使用 Kafka 的时候,每个 Topic 的 Partition 在消息量大的时候,要注意设置的相对大一些。
下面,我们来实现一个 Consumer 并发消费的示例。最终项目如下图所示: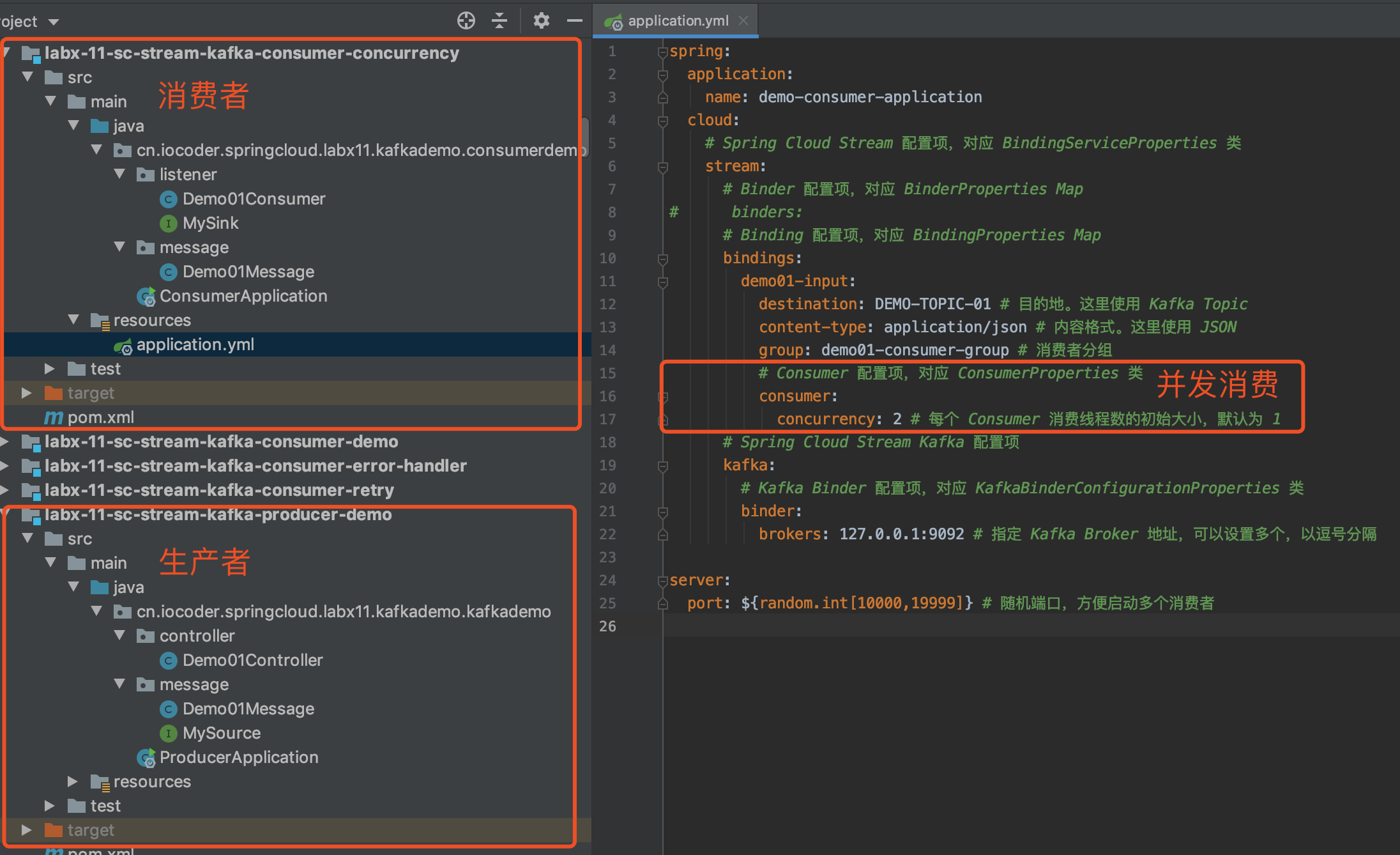
8.1 搭建生产者
直接使用「3. 快速入门」小节的 labx-11-sc-stream-kafka-producer-demo 项目即可。
8.2 搭建消费者
从「3. 快速入门」小节的 labx-11-sc-stream-kafka-consumer-demo 项目,复制出 labx-11-sc-stream-kafka-consumer-concurrency 项目作为消费者。
8.2.1 配置文件
修改 application.yml 配置文件,增加并发消费的配置项。完整配置如下:
spring:
application:
name: demo-consumer-application
cloud:
# Spring Cloud Stream 配置项,对应 BindingServiceProperties 类
stream:
# Binder 配置项,对应 BinderProperties Map
# binders:
# Binding 配置项,对应 BindingProperties Map
bindings:
demo01-input:
destination: DEMO-TOPIC-01 # 目的地。这里使用 Kafka Topic
content-type: application/json # 内容格式。这里使用 JSON
group: demo01-consumer-group # 消费者分组
# Consumer 配置项,对应 ConsumerProperties 类
consumer:
concurrency: 2 # 每个 Consumer 消费线程数的初始大小,默认为 1
# Spring Cloud Stream Kafka 配置项
kafka:
# Kafka Binder 配置项,对应 KafkaBinderConfigurationProperties 类
binder:
brokers: 127.0.0.1:9092 # 指定 Kafka Broker 地址,可以设置多个,以逗号分隔
server:
port: ${random.int[10000,19999]} # 随机端口,方便启动多个消费者
spring.cloud.stream.bindings.<bindingName>.consumer.concurrency 配置项,指定该 Binder 的 Consumer 消费线程数的初始大小,默认为 1。
这里我们设置为 2,表示该 Consumer 初始使用 2 个线程并发消费。
8.3 简单测试
① 执行 ConsumerApplication,启动消费者的实例。
此时我们在 IDEA 控制台的日志中,可以看到创建了两个 Kafka Consumer 和它们所分配到的 Partition,如下所示:
// Spring-Kafka 打印的日志,两个 Consumer 分别消费的 Partition
2020-03-09 08:34:42.039 INFO 69381 --- [container-0-C-1] o.a.k.c.c.internals.ConsumerCoordinator : [Consumer clientId=consumer-2, groupId=demo01-consumer-group] Setting offset for partition DEMO-TOPIC-01-1 to the committed offset FetchPosition{offset=7, offsetEpoch=Optional.empty, currentLeader=LeaderAndEpoch{leader=localhost:9092 (id: 0 rack: null), epoch=0}}
2020-03-09 08:34:42.039 INFO 69381 --- [container-1-C-1] o.a.k.c.c.internals.ConsumerCoordinator : [Consumer clientId=consumer-3, groupId=demo01-consumer-group] Setting offset for partition DEMO-TOPIC-01-9 to the committed offset FetchPosition{offset=7, offsetEpoch=Optional.empty, currentLeader=LeaderAndEpoch{leader=localhost:9092 (id: 0 rack: null), epoch=0}}
2020-03-09 08:34:42.040 INFO 69381 --- [container-1-C-1] o.a.k.c.c.internals.ConsumerCoordinator : [Consumer clientId=consumer-3, groupId=demo01-consumer-group] Setting offset for partition DEMO-TOPIC-01-7 to the committed offset FetchPosition{offset=6, offsetEpoch=Optional.empty, currentLeader=LeaderAndEpoch{leader=localhost:9092 (id: 0 rack: null), epoch=0}}
2020-03-09 08:34:42.040 INFO 69381 --- [container-0-C-1] o.a.k.c.c.internals.ConsumerCoordinator : [Consumer clientId=consumer-2, groupId=demo01-consumer-group] Setting offset for partition DEMO-TOPIC-01-2 to the committed offset FetchPosition{offset=6, offsetEpoch=Optional.empty, currentLeader=LeaderAndEpoch{leader=localhost:9092 (id: 0 rack: null), epoch=0}}
2020-03-09 08:34:42.040 INFO 69381 --- [container-1-C-1] o.a.k.c.c.internals.ConsumerCoordinator : [Consumer clientId=consumer-3, groupId=demo01-consumer-group] Setting offset for partition DEMO-TOPIC-01-8 to the committed offset FetchPosition{offset=5, offsetEpoch=Optional.empty, currentLeader=LeaderAndEpoch{leader=localhost:9092 (id: 0 rack: null), epoch=0}}
2020-03-09 08:34:42.040 INFO 69381 --- [container-0-C-1] o.a.k.c.c.internals.ConsumerCoordinator : [Consumer clientId=consumer-2, groupId=demo01-consumer-group] Setting offset for partition DEMO-TOPIC-01-0 to the committed offset FetchPosition{offset=47, offsetEpoch=Optional.empty, currentLeader=LeaderAndEpoch{leader=localhost:9092 (id: 0 rack: null), epoch=0}}
2020-03-09 08:34:42.040 INFO 69381 --- [container-1-C-1] o.a.k.c.c.internals.ConsumerCoordinator : [Consumer clientId=consumer-3, groupId=demo01-consumer-group] Setting offset for partition DEMO-TOPIC-01-5 to the committed offset FetchPosition{offset=5, offsetEpoch=Optional.empty, currentLeader=LeaderAndEpoch{leader=localhost:9092 (id: 0 rack: null), epoch=0}}
2020-03-09 08:34:42.040 INFO 69381 --- [container-0-C-1] o.a.k.c.c.internals.ConsumerCoordinator : [Consumer clientId=consumer-2, groupId=demo01-consumer-group] Setting offset for partition DEMO-TOPIC-01-3 to the committed offset FetchPosition{offset=5, offsetEpoch=Optional.empty, currentLeader=LeaderAndEpoch{leader=localhost:9092 (id: 0 rack: null), epoch=0}}
2020-03-09 08:34:42.040 INFO 69381 --- [container-1-C-1] o.a.k.c.c.internals.ConsumerCoordinator : [Consumer clientId=consumer-3, groupId=demo01-consumer-group] Setting offset for partition DEMO-TOPIC-01-6 to the committed offset FetchPosition{offset=5, offsetEpoch=Optional.empty, currentLeader=LeaderAndEpoch{leader=localhost:9092 (id: 0 rack: null), epoch=0}}
2020-03-09 08:34:42.040 INFO 69381 --- [container-0-C-1] o.a.k.c.c.internals.ConsumerCoordinator : [Consumer clientId=consumer-2, groupId=demo01-consumer-group] Setting offset for partition DEMO-TOPIC-01-4 to the committed offset FetchPosition{offset=6, offsetEpoch=Optional.empty, currentLeader=LeaderAndEpoch{leader=localhost:9092 (id: 0 rack: null), epoch=0}}
// Spring Cloud Stream Kafka 打印的日志,两个 Consumer 分别消费的 Partition
2020-03-09 08:34:42.045 INFO 69381 --- [container-1-C-1] o.s.c.s.b.k.KafkaMessageChannelBinder$1 : demo01-consumer-group: partitions assigned: [DEMO-TOPIC-01-9, DEMO-TOPIC-01-7, DEMO-TOPIC-01-8, DEMO-TOPIC-01-5, DEMO-TOPIC-01-6]
2020-03-09 08:34:42.045 INFO 69381 --- [container-0-C-1] o.s.c.s.b.k.KafkaMessageChannelBinder$1 : demo01-consumer-group: partitions assigned: [DEMO-TOPIC-01-3, DEMO-TOPIC-01-4, DEMO-TOPIC-01-1, DEMO-TOPIC-01-2, DEMO-TOPIC-01-0]
② 执行 ProducerApplication,启动生产者的实例。
之后,请求 http://127.0.0.1:18080/demo01/send 接口四次,发送四条消息。IDEA 控制台输出日志如下:
// 线程编号为 26
2020-03-09 08:43:07.450 INFO 69381 --- [container-0-C-1] c.i.s.l.k.c.listener.Demo01Consumer : [onMessage][线程编号:26 消息内容:Demo01Message{id=1381530661}]
2020-03-09 08:43:08.239 INFO 69381 --- [container-0-C-1] c.i.s.l.k.c.listener.Demo01Consumer : [onMessage][线程编号:26 消息内容:Demo01Message{id=-1440386434}]
// 线程编号为 28
2020-03-09 08:43:08.626 INFO 69381 --- [container-1-C-1] c.i.s.l.k.c.listener.Demo01Consumer : [onMessage][线程编号:28 消息内容:Demo01Message{id=-279884815}]
2020-03-09 08:43:08.907 INFO 69381 --- [container-1-C-1] c.i.s.l.k.c.listener.Demo01Consumer : [onMessage][线程编号:28 消息内容:Demo01Message{id=-1848103858}]
我们可以看到,两个线程在消费 DEMO-TOPIC-01 Topic 下的消息。
9. 顺序消息
示例代码对应仓库:
我们先来一起了解下顺序消息的顺序消息的定义:
- 普通顺序消息 :Producer 将相关联的消息发送到相同的消息队列。
- 完全严格顺序 :在【普通顺序消息】的基础上,Consumer 严格顺序消费。
消息有序,指的是一类消息消费时,能按照发送的顺序来消费。例如:一个订单产生了三条消息分别是订单创建、订单付款、订单完成。消费时要按照这个顺序消费才能有意义,但是同时订单之间是可以并行消费的。RocketMQ 可以严格的保证消息有序。
顺序消息分为全局顺序消息与分区顺序消息,全局顺序是指某个 Topic 下的所有消息都要保证顺序;部分顺序消息只要保证每一组消息被顺序消费即可。
- 全局顺序:对于指定的一个 Topic,所有消息按照严格的先入先出(FIFO)的顺序进行发布和消费。适用场景:性能要求不高,所有的消息严格按照 FIFO 原则进行消息发布和消费的场景
- 分区顺序:对于指定的一个 Topic,所有消息根据 Sharding key 进行区块分区。 同一个分区内的消息按照严格的 FIFO 顺序进行发布和消费。Sharding key 是顺序消息中用来区分不同分区的关键字段,和普通消息的 Key 是完全不同的概念。适用场景:性能要求高,以 Sharding key 作为分区字段,在同一个区块中严格的按照 FIFO 原则进行消息发布和消费的场景。
注意,分区顺序就是普通顺序消息,全局顺序就是完全严格顺序。
📚 如何实现? 📚
在上述的示例中,我们看到 Spring-Kafka 在 Consumer 消费消息时,天然就支持按照 Topic 下的 Partition 下的消息,顺序消费。即使在「8. 并发消费」时,也能保证如此。
那么此时,我们只需要考虑将 Producer 将相关联的消息发送到 Topic 下的相同的 Partition 即可。在 Spring Cloud Stream 中,支持从消息中获取 Sharding key,从而发送消息到 Topic 下对应的 Partition 中。
下面,我们来实现一个 Spring Cloud Stream RabbitMQ 下的顺序消息的示例。最终项目如下图所示: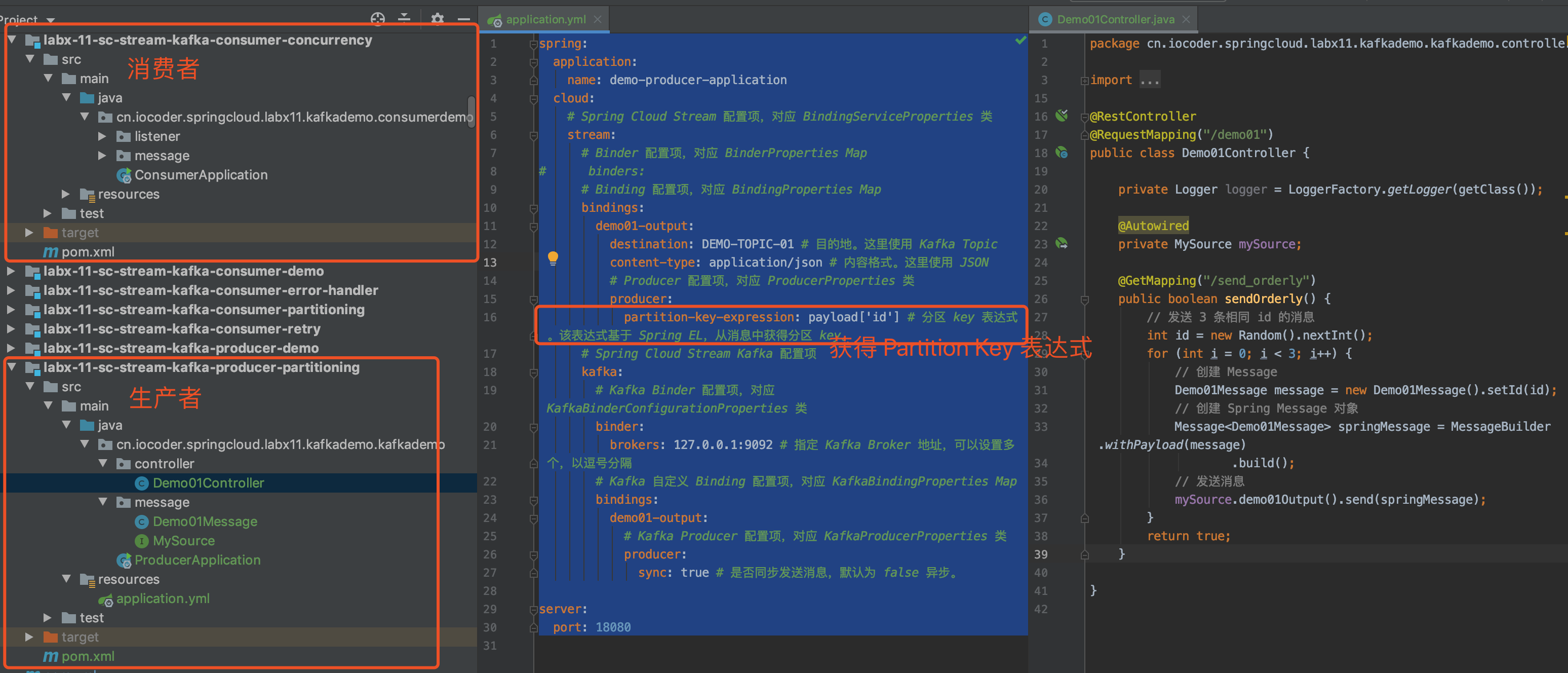
9.1 搭建生产者
从「3. 快速入门」小节的 labx-11-sc-stream-kafka-producer-demo 项目,复制出 labx-11-sc-stream-kafka-producer-partitioning 项目作为生产者。
9.1.1 配置文件
修改 application.yml 配置文件,添加 partition-key-expression 配置项,设置 Producer 发送顺序消息的 Sharding key。完整配置如下:
spring:
application:
name: demo-producer-application
cloud:
# Spring Cloud Stream 配置项,对应 BindingServiceProperties 类
stream:
# Binder 配置项,对应 BinderProperties Map
# binders:
# Binding 配置项,对应 BindingProperties Map
bindings:
demo01-output:
destination: DEMO-TOPIC-01 # 目的地。这里使用 Kafka Topic
content-type: application/json # 内容格式。这里使用 JSON
# Producer 配置项,对应 ProducerProperties 类
producer:
partition-key-expression: payload['id'] # 分区 key 表达式。该表达式基于 Spring EL,从消息中获得分区 key。
# Spring Cloud Stream Kafka 配置项
kafka:
# Kafka Binder 配置项,对应 KafkaBinderConfigurationProperties 类
binder:
brokers: 127.0.0.1:9092 # 指定 Kafka Broker 地址,可以设置多个,以逗号分隔
# Kafka 自定义 Binding 配置项,对应 KafkaBindingProperties Map
bindings:
demo01-output:
# Kafka Producer 配置项,对应 KafkaProducerProperties 类
producer:
sync: true # 是否同步发送消息,默认为 false 异步。
server:
port: 18080
① spring.cloud.stream.bindings.<bindingName>.producer.partition-key-expression 配置项,该表达式基于 Spring EL,从消息中获得 Sharding key。
友情提示:Sharding Key 和 Partition Key 是等价的,有些文章喜欢叫分片键,有些文章喜欢叫分区键。
艿艿自己的习惯,是叫 Sharding Key,奈何 Spring Cloud Stream 是 Partition Key,所以下文胖友看到两个词存在混用的情况,知道是一个意思哈~
这里,我们设置该配置项为 payload['id'],表示从 Spring Message 的 payload 的 id。稍后我们发送的消息的 payload 为 Demo01Message,那么 id 就是 Demo01Message.id。
如果我们想从消息的 headers 中获得 Sharding key,可以设置为 headers['partitionKey']。
② Spring Cloud Stream 使用 PartitionHandler 进行 Sharding key 的获得与计算,最终 Sharding key 的结果为 key.hashCode() % partitionCount。
感兴趣的胖友,可以阅读 PartitionHandler 的
#determinePartition(Message<?> message)方法。
我们以发送一条 id 为 1 的 Demo01Message 消息为示例,最终会发送到对应 Kafka Topic 的 Partition 为 1。计算过程如下:
// 第一步,PartitionHandler 使用 `partition-key-expression` 表达式,从 Message 中获得 Sharding key
key => 1
// 第二步,PartitionHandler 计算最终的 Sharding key
// 这里 Partition 数量为 10 的原因是,在「3. 快速入门」小节,我设置 `DEMO-TOPIC-01` Topic 的 Partition 大小为 10.
key => key.hashCode() % partitionCount = 1.hashCode() % 10 = 1 % 10 = 1
// 第三步,Kafka 发送到 `DEMO-TOPIC-01` Topic 的顺序为 key Partition 中
// 这里,因为 key 为 1,所以 Partition 顺序为 1。
这样,我们就能保证相同 Sharding Key 的消息,发送到相同的对应 Kafka Topic 的 Partition 中。当前,前提是该 Topic 的 Partition 总数不能变噢,不然计算的 Sharding Key 会发生变化。
9.1.2 Demo01Controller
修改 Demo01Controller 类,增加发送 3 条顺序消息的 HTTP 接口。代码如下:
@GetMapping("/send_orderly")
public boolean sendOrderly() {
// 发送 3 条相同 id 的消息
int id = new Random().nextInt();
for (int i = 0; i < 3; i++) {
// 创建 Message
Demo01Message message = new Demo01Message().setId(id);
// 创建 Spring Message 对象
Message<Demo01Message> springMessage = MessageBuilder.withPayload(message)
.build();
// 发送消息
mySource.demo01Output().send(springMessage);
}
return true;
}
每次发送的 3 条消息使用相同的 id,配合上我们使用它作为 Sharding key,就可以发送对应 Topic 的相同 Partition 中。
另外,整列发送的虽然是顺序消息,但是和发送普通消息的代码是一模一样的。
9.2 搭建消费者
直接使用「8. 并发消费」小节的 labx-11-sc-stream-kafka-consumer-concurrency 项目即可。
9.3 简单测试
① 执行 ConsumerApplication,启动消费者的实例。
② 执行 ProducerApplication,启动生产者的实例。
之后,请求 http://127.0.0.1:18080/demo01/send_orderly 接口,发送顺序消息。IDEA 控制台输出日志如下:
2020-03-08 10:37:05.351 INFO 71912 --- [container-0-C-1] c.i.s.l.k.c.listener.Demo01Consumer : [onMessage][线程编号:26 消息内容:Demo01Message{id=1414772641}]
2020-03-08 10:37:05.354 INFO 71912 --- [container-0-C-1] c.i.s.l.k.c.listener.Demo01Consumer : [onMessage][线程编号:26 消息内容:Demo01Message{id=1414772641}]
2020-03-08 10:37:05.358 INFO 71912 --- [container-0-C-1] c.i.s.l.k.c.listener.Demo01Consumer : [onMessage][线程编号:26 消息内容:Demo01Message{id=1414772641}]
id 为 1414772641 的消息被发送到 Kafka Topic 的 Partition 为 1,并且在线程编号为 26 的线程中消费。😈 胖友可以自己在多调用几次接口,继续尝试。
10. 消息过滤
示例代码对应仓库:
Spring Cloud Stream 提供了通用的 Consumer 级别的效率过滤器机制。我们只需要使用 @StreamListener 注解的 condition 属性,设置消息满足指定 Spring EL 表达式的情况下,才进行消费。
下面,我们来实现一个 Spring Cloud Stream Kafka 下的消息过滤的示例。最终项目如下图所示:项目结构
10.1 搭建生产者
直接使用「3. 快速入门」小节的 labx-11-sc-stream-kafka-producer-demo 项目即可。
10.1.1 Demo01Controller
修改 Demo01Controller 类,增加发送 3 条带 tag 消息头的消息的 HTTP 接口。代码如下:
@GetMapping("/send_tag")
public boolean sendTag() {
for (String tag : new String[]{"yunai", "yutou", "tudou"}) {
// 创建 Message
Demo01Message message = new Demo01Message()
.setId(new Random().nextInt());
// 创建 Spring Message 对象
Message<Demo01Message> springMessage = MessageBuilder.withPayload(message)
.setHeader("tag", tag) // <X> 设置 Tag
.build();
// 发送消息
mySource.demo01Output().send(springMessage);
}
return true;
}
在 <X> 处,设置发送消息的 tag 消息头。
10.2 搭建消费者
从「3. 快速入门」小节的 labx-11-sc-stream-kafka-consumer-demo 项目,复制出 labx-11-sc-stream-kafka-consumer-filter 项目作为消费者。
10.2.1 Demo01Consumer
修改 Demo01Consumer 类,使用 @StreamListener 注解的 condition 属性来过滤消息。代码如下:
@Component
public class Demo01Consumer {
private Logger logger = LoggerFactory.getLogger(getClass());
@StreamListener(value = MySink.DEMO01_INPUT, condition = "headers['tag'] == 'yunai'")
public void onMessage(@Payload Demo01Message message) {
logger.info("[onMessage][线程编号:{} 消息内容:{}]", Thread.currentThread().getId(), message);
}
}
这里我们设置消息的 Header 带有的 tag 值为 yunai 时,才进行消费。
10.3 简单测试
① 执行 ConsumerApplication,启动消费者的实例。
② 执行 ProducerApplication,启动生产者的实例。
之后,请求 http://127.0.0.1:18080/demo01/send_tag 接口,发送带有 Tag 的消息。IDEA 控制台输出日志如下:
// 消息头 tag 为 `yunai` 的消息被消费
2020-03-09 19:25:28.495 INFO 80717 --- [container-0-C-1] c.i.s.l.k.c.listener.Demo01Consumer : [onMessage][线程编号:25 消息内容:Demo01Message{id=-8065193}]
// 消息头 tag 为 `yutou` 和 `tudou` 的消息被过滤
2020-03-09 19:25:28.500 WARN 80717 --- [container-0-C-1] .DispatchingStreamListenerMessageHandler : Cannot find a @StreamListener matching for message with id: null
2020-03-09 19:25:28.502 WARN 80717 --- [container-0-C-1] .DispatchingStreamListenerMessageHandler : Cannot find a @StreamListener matching for message with id: null
只消费了一条消息头为 yunai 的消息,而消息头为 yutou 和 tudou 的消息被 Consumer 过滤。要注意,被过滤掉的消息,后续是无法被消费掉了,效果和消费成功是一样的。
11. 事务消息
示例代码对应仓库:
Kafka 内置提供事务消息的支持。对事务消息的概念不了解的胖友,可以看看 《事务消息组件的套路》 文章。
不过 Kafka 提供的并不是完整的的事务消息的支持,缺少了回查机制。关于这一点,刚推荐的文章也有讲到。目前,常用的分布式消息队列,只有 RocketMQ 提供了完整的事务消息的支持,具体的可以看看《芋道 Spring Boot 消息队列 RocketMQ 入门》 的「9. 事务消息」小节,😈 暂时不拓展开来讲。
下面,我们来实现一个 Spring Cloud Stream Kafka 下的事务消息的示例。最终项目如下图所示: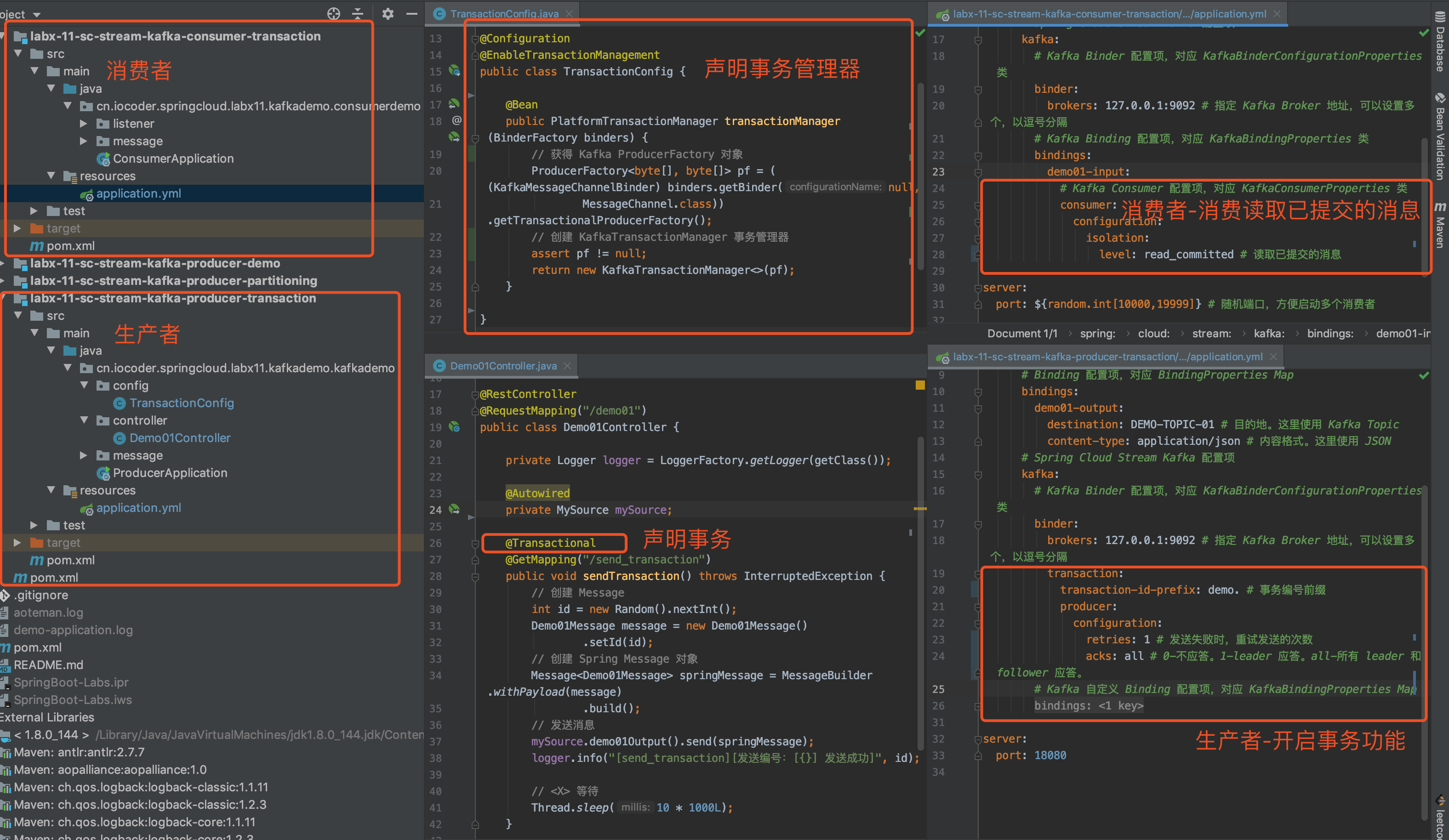
11.1 搭建生产者
从「3. 快速入门」小节的 labx-11-sc-stream-kafka-producer-demo 项目,复制出 labx-11-sc-stream-kafka-producer-transaction 项目作为生产者。
11.1.1 配置文件
修改 application.yml 配置文件,添加事务相关配置项,开启发送事务消息的功能。完整配置如下:
spring:
application:
name: demo-producer-application
cloud:
# Spring Cloud Stream 配置项,对应 BindingServiceProperties 类
stream:
# Binder 配置项,对应 BinderProperties Map
# binders:
# Binding 配置项,对应 BindingProperties Map
bindings:
demo01-output:
destination: DEMO-TOPIC-01 # 目的地。这里使用 Kafka Topic
content-type: application/json # 内容格式。这里使用 JSON
# Spring Cloud Stream Kafka 配置项
kafka:
# Kafka Binder 配置项,对应 KafkaBinderConfigurationProperties 类
binder:
brokers: 127.0.0.1:9092 # 指定 Kafka Broker 地址,可以设置多个,以逗号分隔
transaction:
transaction-id-prefix: demo. # 事务编号前缀
producer:
configuration:
retries: 1 # 发送失败时,重试发送的次数
acks: all # 0-不应答。1-leader 应答。all-所有 leader 和 follower 应答。
# Kafka 自定义 Binding 配置项,对应 KafkaBindingProperties Map
bindings:
demo01-output:
# Kafka Producer 配置项,对应 KafkaProducerProperties 类
producer:
sync: true # 是否同步发送消息,默认为 false 异步。
server:
port: 18080
spring.cloud.stream.kafka.binder.transaction 为 Spring Cloud Stream Kafka 事务配置项,对应 KafkaBinderConfigurationProperties.Transaction 类。
-
transaction-id-prefix配置项,事务编号的前缀。需要保证相同应用配置相同,不同应用配置不同。具体可以看看《How to choose Kafka transaction id for several applications》的讨论。 -
producer配置项,Producer 在事务中的
附加
配置项。
retries配置项,发送失败时,重试发送的次数。acks配置项,必须设置为all,不然在启动时会报"Must set acks to all in order to use the idempotent producer. Otherwise we cannot guarantee idempotence."错误。因为,Kafka 的事务消息需要基于幂等性来实现,所以必须保证所有节点都写入成功。
11.1.2 TransactionConfig
创建 TransactionConfig 类,创建 KafkaTransactionManager Bean,Kafka 的事务管理器,集成到 Spring 的事务体系中,这样就可以使用 @Transactional 声明式事务。代码如下:
@Configuration
@EnableTransactionManagement
public class TransactionConfig {
@Bean
public PlatformTransactionManager transactionManager(BinderFactory binders) {
// 获得 Kafka ProducerFactory 对象
ProducerFactory<byte[], byte[]> pf = ((KafkaMessageChannelBinder) binders.getBinder(null,
MessageChannel.class)).getTransactionalProducerFactory();
// 创建 KafkaTransactionManager 事务管理器
assert pf != null;
return new KafkaTransactionManager<>(pf);
}
}
11.1.3 Demo01Controller
修改 Demo01Controller 类,增加发送事务消息的 HTTP 接口。代码如下:
// Demo01Controller .java
@Transactional
@GetMapping("/send_transaction")
public void sendTransaction() throws InterruptedException {
// 创建 Message
int id = new Random().nextInt();
Demo01Message message = new Demo01Message()
.setId(id);
// 创建 Spring Message 对象
Message<Demo01Message> springMessage = MessageBuilder.withPayload(message)
.build();
// 发送消息
mySource.demo01Output().send(springMessage);
logger.info("[sendTransaction][发送编号:[{}] 发送成功]", id);
// <X> 等待
Thread.sleep(10 * 1000L);
}
在发送消息方法上,我们添加了 @Transactional 注解,声明事务。因为我们创建了 KafkaTransactionManager 事务管理器,所以这里会创建 Kafka 事务。
在 <X> 处,我们故意等待 Thread#sleep(long millis) 10 秒,判断 Kafka 事务是否生效。
- 如果同步发送消息成功后,Consumer 立即消费到该消息,说明未生效。
- 如果 Consumer 是 10 秒之后,才消费到该消息,说明已生效。
11.2 搭建消费者
从「3. 快速入门」小节的 labx-11-sc-stream-kafka-consumer-demo 项目,复制出 labx-11-sc-stream-kafka-consumer-transaction 项目作为消费者。
11.2.1 配置文件
修改 application.yml 配置文件,添加事务相关配置项,仅消费已提交的消息。完整配置如下:
spring:
application:
name: demo-consumer-application
cloud:
# Spring Cloud Stream 配置项,对应 BindingServiceProperties 类
stream:
# Binder 配置项,对应 BinderProperties Map
# binders:
# Binding 配置项,对应 BindingProperties Map
bindings:
demo01-input:
destination: DEMO-TOPIC-01 # 目的地。这里使用 Kafka Topic
content-type: application/json # 内容格式。这里使用 JSON
group: demo01-consumer-group # 消费者分组
# Spring Cloud Stream Kafka 配置项
kafka:
# Kafka Binder 配置项,对应 KafkaBinderConfigurationProperties 类
binder:
brokers: 127.0.0.1:9092 # 指定 Kafka Broker 地址,可以设置多个,以逗号分隔
# Kafka Binding 配置项,对应 KafkaBindingProperties 类
bindings:
demo01-input:
# Kafka Consumer 配置项,对应 KafkaConsumerProperties 类
consumer:
configuration:
isolation:
level: read_committed # 读取已提交的消息
server:
port: ${random.int[10000,19999]} # 随机端口,方便启动多个消费者
添加 spring.cloud.stream.kafka.bindings.<bindingName>.consumer.configuration.isolation.level 为 read_committed,设置 Consumer 仅读取已提交的消息。😈 一定要配置!!!被坑惨了,当时以为自己的事务消息怎么就是不生效,原来少加了这个。
11.3 简单测试
① 执行 ConsumerApplication,启动消费者的实例。
② 执行 ProducerApplication,启动生产者的实例。
之后,请求 http://127.0.0.1:18080/demo01/send_transaction 接口,发送事务消息。IDEA 控制台输出日志如下:
// Producer 成功同步发送了 1 条消息。此时,事务并未提交
2020-03-09 22:31:34.863 INFO 84414 --- [io-18080-exec-1] c.i.s.l.k.k.controller.Demo01Controller : [send_transaction][发送编号:[629326486] 发送成功]
// 10 秒后,Producer 提交事务。
// 此时,Consumer 消费到该消息。
2020-03-09 22:31:44.952 INFO 84408 --- [container-0-C-1] c.i.s.l.k.c.listener.Demo01Consumer : [onMessage][线程编号:27 消息内容:Demo01Message{id=629326486}]
Consumer 在事务消息提交后,消费到该消息。符合预期~
12. 消费进度的提交机制
示例代码对应仓库:
📚 原生 Kafka 的提交机制
原生 Kafka Consumer 消费端,有两种消费进度提交的提交机制:
- 【默认】自动提交,通过配置
enable.auto.commit=true,每过auto.commit.interval.ms时间间隔,都会自动提交消费消费进度。而提交的时机,是在 Consumer 的#poll(...)方法的逻辑里完成,在每次从 Kafka Broker 拉取消息时,会检查是否到达自动提交的时间间隔,如果是,那么就会提交上一次轮询拉取的位置。 - 手动提交,通过配置
enable.auto.commit=false,后续通过 Consumer 的#commitSync(...)或#commitAsync(...)方法,同步或异步提交消费进度。
📚 Spring-Kafka 的提交机制
Spring-Kafka Consumer 消费端,提供了更丰富的消费者进度的提交机制,更加灵活。当然,也是分成自动提交和手动提交两个大类。在 AckMode 枚举类中,可以看到每一种具体的方式。代码如下:
// ContainerProperties#AckMode.java
public enum AckMode {
// ========== 自动提交 ==========
/**
* Commit after each record is processed by the listener.
*/
RECORD, // 每条消息被消费完成后,自动提交
/**
* Commit whatever has already been processed before the next poll.
*/
BATCH, // 每一次消息被消费完成后,在下次拉取消息之前,自动提交
/**
* Commit pending updates after
* {@link ContainerProperties#setAckTime(long) ackTime} has elapsed.
*/
TIME, // 达到一定时间间隔后,自动提交。
// 不过要注意,它并不是一到就立马提交,如果此时正在消费某一条消息,需要等这条消息被消费完成,才能提交消费进度。
/**
* Commit pending updates after
* {@link ContainerProperties#setAckCount(int) ackCount} has been
* exceeded.
*/
COUNT, // 消费成功的消息数到达一定数量后,自动提交。
// 不过要注意,它并不是一到就立马提交,如果此时正在消费某一条消息,需要等这条消息被消费完成,才能提交消费进度。
/**
* Commit pending updates after
* {@link ContainerProperties#setAckCount(int) ackCount} has been
* exceeded or after {@link ContainerProperties#setAckTime(long)
* ackTime} has elapsed.
*/
COUNT_TIME, // TIME 和 COUNT 的结合体,满足任一都会自动提交。
// ========== 手动提交 ==========
/**
* User takes responsibility for acks using an
* {@link AcknowledgingMessageListener}.
*/
MANUAL, // 调用时,先标记提交消费进度。等到当前消息被消费完成,然后在提交消费进度。
/**
* User takes responsibility for acks using an
* {@link AcknowledgingMessageListener}. The consumer
* immediately processes the commit.
*/
MANUAL_IMMEDIATE, // 调用时,立即提交消费进度。
}
- 看下每种方式,艿艿都添加了注释哟。
那么,既然现在存在原生 Kafka 和 Spring-Kafka 提供的两种消费进度的提交机制,我们应该怎么配置呢?
- 使用原生 Kafka 的方式,通过配置
spring.kafka.consumer.enable-auto-commit=true。然后,通过spring.kafka.consumer.auto-commit-interval设置自动提交的频率。 - 使用 Spring-Kafka 的方式,通过配置
spring.kafka.consumer.enable-auto-commit=false。然后通过spring.kafka.listener.ack-mode设置具体模式。另外,还有spring.kafka.listener.ack-time和spring.kafka.listener.ack-count可以设置自动提交的时间间隔和消息条数。
默认什么都不配置的情况下,使用 Spring-Kafka 的 BATCH 模式:每一次消息被消费完成后,在下次拉取消息之前,自动提交。
📚 Spring Cloud Stream Kafka 的提交机制
Spring Cloud Stream Kafka 在 Spring-Kafka 上进一步封装,在 spring.cloud.stream.kafka.bindings.<bindingName>.consumer 下提供了两个配置项:
auto-commit-offset配置项,是否自动提交消费进度,默认为true自动提交。ack-each-record配置项,是否每一条消息都进行提交消费进度,默认为false在每一批消费完成后一起提交。
我们进行下整理,将 Spring Cloud Stream Kafka 这两个配置项,和 Spring-Kafka 的 AckMode 对应上,如下表格:
| AckMode | auto-commit-offset |
ack-each-record |
|---|---|---|
自动 RECORD |
true |
false |
自动 BATCH |
true |
true |
手动 MANUAL |
false |
false |
手动 MANUAL_IMMEDIATE |
false |
true |
因此,默认什么都不配置的情况下,也使用 Spring-Kafka 的 BATCH 模式:每一次消息被消费完成后,在下次拉取消息之前,自动提交。
下面,我们来实现一个 Spring Cloud Stream Kafka 下的手动提交消费进度的示例。最终项目如下图所示:
12.1 搭建生产者
直接使用「3. 快速入门」小节的 labx-11-sc-stream-kafka-producer-demo 项目即可。
12.2 搭建消费者
从「3. 快速入门」小节的 labx-11-sc-stream-kafka-consumer-demo 项目,复制出 labx-11-sc-stream-kafka-consumer-ack 项目作为消费者。
12.2.1 配置文件
修改 application.yml 配置文件,设置 auto-commit-offset 配置项为 false,ack-each-record 配置项为 true,即使用 Spring-Kafka 的 MANUAL 模式,手动提交消费进度。完整配置如下:
spring:
application:
name: demo-consumer-application
cloud:
# Spring Cloud Stream 配置项,对应 BindingServiceProperties 类
stream:
# Binder 配置项,对应 BinderProperties Map
# binders:
# Binding 配置项,对应 BindingProperties Map
bindings:
demo01-input:
destination: DEMO-TOPIC-01 # 目的地。这里使用 Kafka Topic
content-type: application/json # 内容格式。这里使用 JSON
group: demo01-consumer-group # 消费者分组
# Spring Cloud Stream Kafka 配置项
kafka:
# Kafka Binder 配置项,对应 KafkaBinderConfigurationProperties 类
binder:
brokers: 127.0.0.1:9092 # 指定 Kafka Broker 地址,可以设置多个,以逗号分隔
# Kafka Binding 配置项,对应 KafkaBindingProperties 类
bindings:
demo01-input:
# Kafka Consumer 配置项,对应 KafkaConsumerProperties 类
consumer:
auto-commit-offset: false # 是否自动提交消费进度,默认为 true 自动提交。
ack-each-record: true # 是否每一条消息都进行提交消费进度,默认为 false 在每一批消费完成后一起提交。
server:
port: ${random.int[10000,19999]} # 随机端口,方便启动多个消费者
12.2.2 Demo01Consumer
修改 Demo01Consumer 类,增加手动提交消费进度的代码。代码如下:代码如下:
// Demo08Consumer.java
@Component
public class Demo08Consumer {
private Logger logger = LoggerFactory.getLogger(getClass());
@KafkaListener(topics = Demo08Message.TOPIC,
groupId = "demo08-consumer-group-" + Demo08Message.TOPIC)
public void onMessage(Demo08Message message, Acknowledgment acknowledgment) {
logger.info("[onMessage][线程编号:{} 消息内容:{}]", Thread.currentThread().getId(), message);
// 提交消费进度
if (message.getId() % 2 == 1) {
acknowledgment.acknowledge();
}
}
}
① 在消费方法上,我们增加了第二个方法参数,类型为 Acknowledgment 类。通过调用其 #acknowledge() 方法,可以提交当前消息的 Topic 的 Partition 的消费进度。
② 在消费逻辑中,我们故意只提交消费的第一条消息。😈 这样,我们只需要发送两条消息,如果第二条的消费进度没有被提交,就可以说明手动提交消费进度成功。
12.3 简单测试
友情提示:这里为了测试方便,避免其它示例污染,因此艿艿先直接删除了
DEMO-TOPIC-01Topic,然后重新创建。
① 执行 ConsumerApplication,启动消费者的实例。
② 执行 ProducerApplication,启动生产者的实例。
之后,请求 http://127.0.0.1:18080/demo01/send 接口,发送两条消息。IDEA 控制台输出日志如下:
// Consumer 消费 2 条消息成功
2020-03-10 08:28:52.274 INFO 86430 --- [container-0-C-1] c.i.s.l.k.c.listener.Demo01Consumer : [onMessage][线程编号:27 消息内容:Demo01Message{id=-1390450417}]
2020-03-10 08:28:53.101 INFO 86430 --- [container-0-C-1] c.i.s.l.k.c.listener.Demo01Consumer : [onMessage][线程编号:27 消息内容:Demo01Message{id=34018866}]
我们打开 Kafka 运维界面,查看下 DEMO-TOPIC-01 Topic 的消息进度情况,会看到一条消息的消费进度未被提交,符合预期。如下图所示: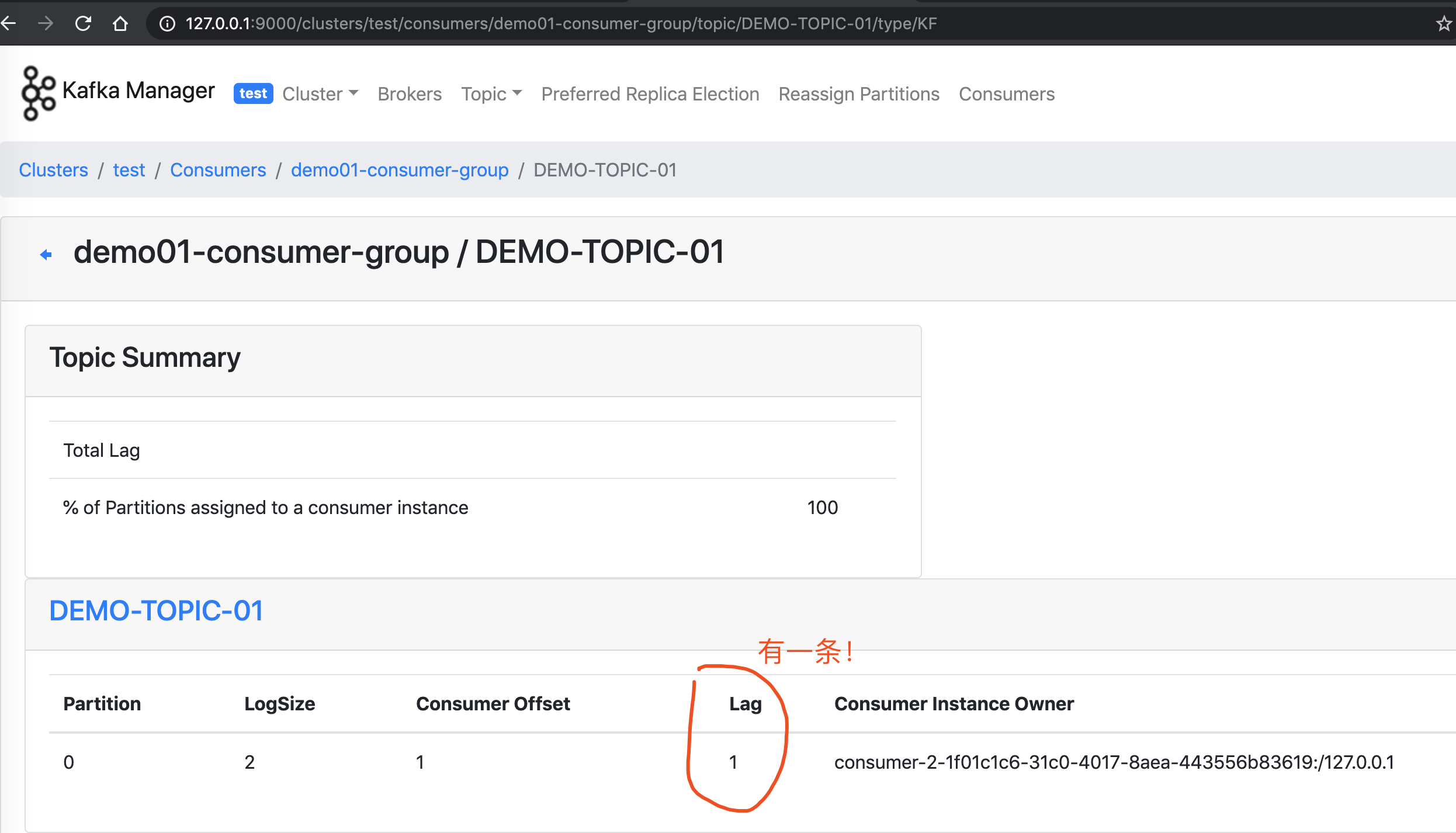
13. 批量发送消息
示例代码对应仓库:
在一些业务场景下,我们希望使用 Producer 批量发送消息,提高发送性能。不同于我们在《芋道 Spring Boot 消息队列 RocketMQ 入门》 的「4. 批量发送消息」 功能,RocketMQ 是提供了一个可以批量发送多条消息的 API 。
而 Kafka 提供的批量发送消息,它提供了一个 RecordAccumulator 消息收集器,将发送给相同 Topic 的相同 Partition 分区的消息们,“偷偷”收集在一起,当满足条件时候,一次性批量发送提交给 Kafka Broker 。通过在 spring.cloud.stream.kafka.bindings.<bindingName>.producer 下提供了两个配置项,满足任一即会批量发送:
- 【时间】
batch-timeout:超过收集的时间的最大等待时长,单位:毫秒。 - 【空间】
buffer-memory:超过收集的消息占用的最大内存。
下面,我们来实现一个 Spring Cloud Stream Kafka 下的批量发送消息的示例。最终项目如下图所示: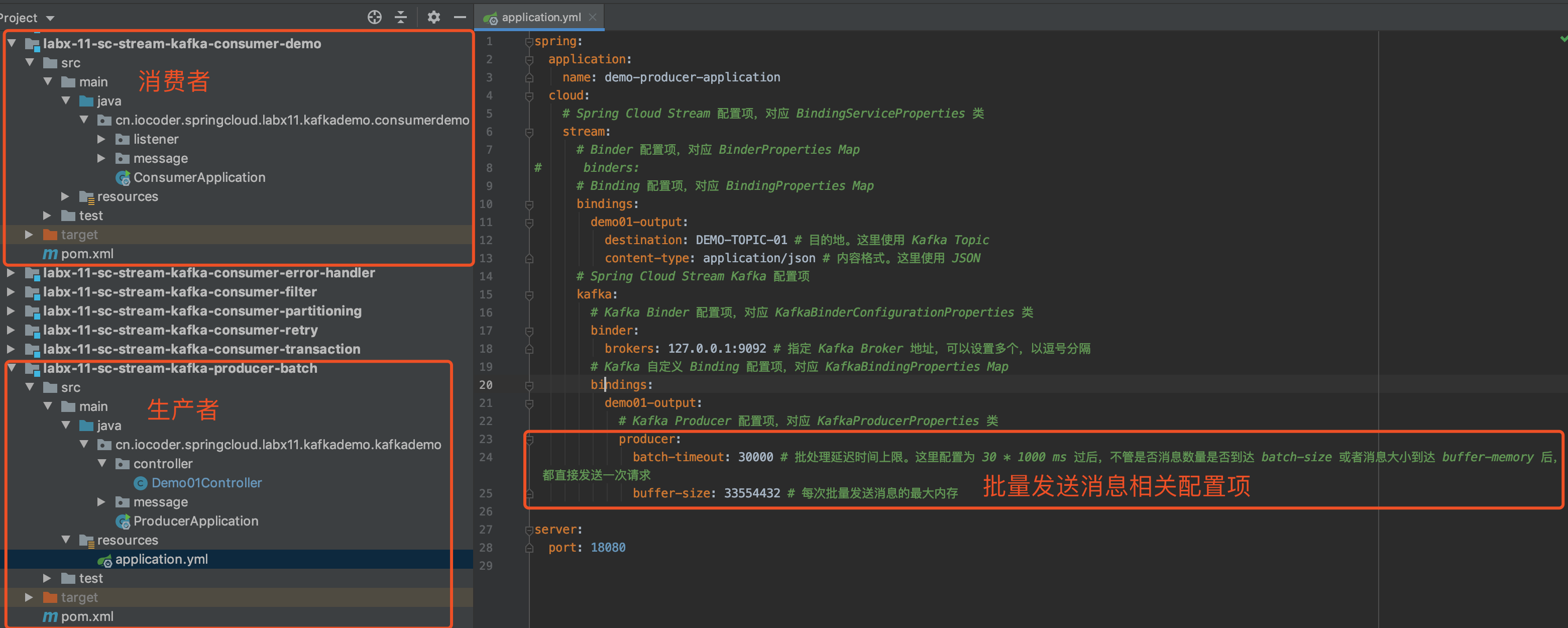
13.1 搭建生产者
从「3. 快速入门」小节的 labx-11-sc-stream-kafka-producer-demo 项目,复制出 labx-11-sc-stream-kafka-producer-batch 项目作为生产者。
13.1.1 配置文件
修改 application.yaml 配置文件,增加批量发送消息相关的配置项。完整配置如下:
spring:
application:
name: demo-producer-application
cloud:
# Spring Cloud Stream 配置项,对应 BindingServiceProperties 类
stream:
# Binder 配置项,对应 BinderProperties Map
# binders:
# Binding 配置项,对应 BindingProperties Map
bindings:
demo01-output:
destination: DEMO-TOPIC-01 # 目的地。这里使用 Kafka Topic
content-type: application/json # 内容格式。这里使用 JSON
# Spring Cloud Stream Kafka 配置项
kafka:
# Kafka Binder 配置项,对应 KafkaBinderConfigurationProperties 类
binder:
brokers: 127.0.0.1:9092 # 指定 Kafka Broker 地址,可以设置多个,以逗号分隔
# Kafka 自定义 Binding 配置项,对应 KafkaBindingProperties Map
bindings:
demo01-output:
# Kafka Producer 配置项,对应 KafkaProducerProperties 类
producer:
batch-timeout: 30000 # 批处理延迟时间上限。这里配置为 30 * 1000 ms 过后,不管是否消息数量是否到达 batch-size 或者消息大小到达 buffer-memory 后,都直接发送一次请求
buffer-size: 33554432 # 每次批量发送消息的最大内存
server:
port: 18080
具体 batch-timeout 和 buffer-size 配置项的数值配置多少,根据自己的应用来。这里,我们故意将 batch-timeout 配置成了 30 秒,主要为了演示之用。
13.1.2 Demo01Controller
修改 Demo01Controller 类,增加发送三条消息的 HTTP 接口,方便测试。代码如下:
// Demo01Controller.java
@GetMapping("/send_batch")
public boolean sendBatch() {
for (int i = 0; i < 3; i++) {
// 创建 Message
int id = new Random().nextInt();
Demo01Message message = new Demo01Message()
.setId(id);
// 创建 Spring Message 对象
Message<Demo01Message> springMessage = MessageBuilder.withPayload(message)
.build();
// 发送消息
mySource.demo01Output().send(springMessage);
logger.info("[send_transaction][发送编号:[{}] 发送成功]", id);
}
return true;
}
就是普通的发送消息的代码,多套了一层循环~
13.2 搭建消费者
直接使用「3. 快速入门」小节的 labx-11-sc-stream-kafka-consumer-demo 项目即可。
13.3 简单测试
① 执行 ConsumerApplication,启动消费者的实例。
② 执行 ProducerApplication,启动生产者的实例。
之后,请求 http://127.0.0.1:18080/demo01/send_batch 接口,发送三条消息。IDEA 控制台输出日志如下:
// Producer 发送了 3 条消息,被 RecordAccumulator 收集
2020-03-10 08:58:52.736 INFO 87258 --- [io-18080-exec-1] c.i.s.l.k.k.controller.Demo01Controller : [send_batch][发送编号:[-936892120] 发送成功]
2020-03-10 08:58:52.736 INFO 87258 --- [io-18080-exec-1] c.i.s.l.k.k.controller.Demo01Controller : [send_batch][发送编号:[128684651] 发送成功]
2020-03-10 08:58:52.737 INFO 87258 --- [io-18080-exec-1] c.i.s.l.k.k.controller.Demo01Controller : [send_batch][发送编号:[-1940691507] 发送成功]
// 30 秒后,Producer 批量发送消息。
// 此时,Consumer 消费到该消息。
2020-03-10 08:59:22.753 INFO 87236 --- [container-0-C-1] c.i.s.l.k.c.listener.Demo01Consumer : [onMessage][线程编号:27 消息内容:Demo01Message{id=-936892120}]
2020-03-10 08:59:22.753 INFO 87236 --- [container-0-C-1] c.i.s.l.k.c.listener.Demo01Consumer : [onMessage][线程编号:27 消息内容:Demo01Message{id=128684651}]
2020-03-10 08:59:22.753 INFO 87236 --- [container-0-C-1] c.i.s.l.k.c.listener.Demo01Consumer : [onMessage][线程编号:27 消息内容:Demo01Message{id=-1940691507}]
Consumer 在消息批量发送后,才消费到该消息。符合预期~
14. 批量消费消息
示例代码对应仓库:
在一些业务场景下,我们希望使用 Consumer 批量消费消息,提高消费速度。要注意,Consumer 的批量消费消息,和 Producer 的「13. 批量发送消息」 没有直接关联哈。
其实现方式是,Consumer 阻塞等待最多 fetch.max.wait.ms 毫秒,至少拉取 fetch.min.bytes 数据量的消息,至多拉取 max.poll.records 数量的消息,进行批量消费。
- 如果在
fetch.max.wait.ms秒内已经成功拉取到max.poll.records条消息,则直接进行批量消费消息。 - 如果在
fetch.max.wait.ms秒还没拉取到max.poll.records条消息,不再等待,而是进行批量消费消息。
下面,我们来实现一个 Spring Cloud Stream Kafka 下的 Consumer 的批量消费消息的示例。最终项目如下图所示: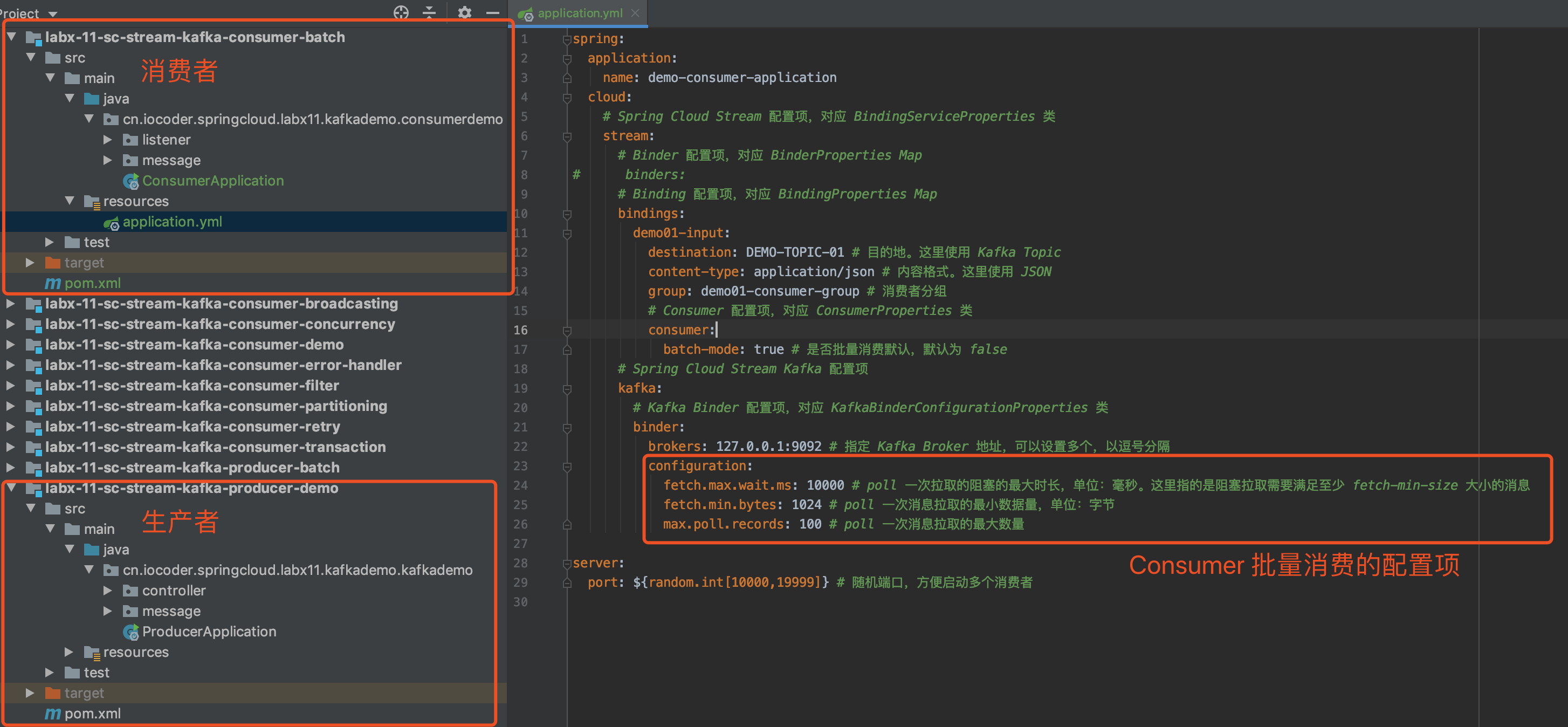
14.1 搭建生产者
直接使用「3. 快速入门」小节的 labx-11-sc-stream-kafka-producer-demo 项目即可。
14.2 搭建消费者
从「3. 快速入门」小节的 labx-11-sc-stream-kafka-consumer-demo 项目,复制出 labx-11-sc-stream-kafka-consumer-batch 项目作为消费者。
14.2.1 配置文件
修改 application.yaml 配置文件,增加批量消费消息相关的配置项。完整配置如下:
spring:
application:
name: demo-consumer-application
cloud:
# Spring Cloud Stream 配置项,对应 BindingServiceProperties 类
stream:
# Binder 配置项,对应 BinderProperties Map
# binders:
# Binding 配置项,对应 BindingProperties Map
bindings:
demo01-input:
destination: DEMO-TOPIC-01 # 目的地。这里使用 Kafka Topic
content-type: application/json # 内容格式。这里使用 JSON
group: demo01-consumer-group # 消费者分组
# Consumer 配置项,对应 ConsumerProperties 类
consumer:
batch-mode: true # 是否批量消费默认,默认为 false
# Spring Cloud Stream Kafka 配置项
kafka:
# Kafka Binder 配置项,对应 KafkaBinderConfigurationProperties 类
binder:
brokers: 127.0.0.1:9092 # 指定 Kafka Broker 地址,可以设置多个,以逗号分隔
configuration:
fetch.max.wait.ms: 10000 # poll 一次拉取的阻塞的最大时长,单位:毫秒。这里指的是阻塞拉取需要满足至少 fetch-min-size 大小的消息
fetch.min.bytes: 1024 # poll 一次消息拉取的最小数据量,单位:字节
max.poll.records: 100 # poll 一次消息拉取的最大数量
server:
port: ${random.int[10000,19999]} # 随机端口,方便启动多个消费者
① 具体 fetch.max.wait.ms、fetch.min.bytes、max.poll.records 配置项的数值配置多少,根据自己的应用来。这里,我们故意将 fetch.max.wait.ms 配置成了 10 秒,主要为了演示之用。
② 设置 spring.cloud.stream.bindings.<bindingName>.consumer.batch-mode 配置项为 true,开启 Consumer 批量消费模式。
14.2.2 Demo01Consumer
修改 Demo01Consumer 类,将消费消息的方法的参数改为 List<?>,从而批量消费消息。代码如下:
@Component
public class Demo01Consumer {
private Logger logger = LoggerFactory.getLogger(getClass());
@StreamListener(MySink.DEMO01_INPUT)
public void onMessage(@Payload List<Demo01Message> messages) {
logger.info("[onMessage][线程编号:{} 消息内容:{}]", Thread.currentThread().getId(), messages);
}
}
14.3 简单测试
① 执行 ConsumerApplication,启动消费者的实例。
② 执行 ProducerApplication,启动生产者的实例。
之后,请求 http://127.0.0.1:18080/demo01/send 接口三次,发送三条消息。IDEA 控制台输出日志如下:
// Producer 成功同步发送了 3 条消息
2020-03-14 15:36:42.630 INFO 92203 --- [io-18080-exec-6] c.i.s.l.k.k.controller.Demo01Controller : [send][发送编号:[-536147214] 发送成功]
2020-03-14 15:36:42.877 INFO 92203 --- [io-18080-exec-7] c.i.s.l.k.k.controller.Demo01Controller : [send][发送编号:[651899347] 发送成功]
2020-03-14 15:36:43.071 INFO 92203 --- [io-18080-exec-8] c.i.s.l.k.k.controller.Demo01Controller : [send][发送编号:[-1217020146] 发送成功]
// Consumer 拉取 30 秒超时后,获取到发送的 3 条消息,并批量消费了 3 条消息
2020-03-10 15:36:48.881 INFO 92667 --- [container-0-C-1] c.i.s.l.k.c.listener.Demo01Consumer : [onMessage][线程编号:30 消息内容:[[B@5cb66abe, [B@66be19cc, [B@63f992da]]
从日志中,我们可以看出,发送的 3 条消息被 Demo01Consumer 批量消费了。
15. 监控端点
示例代码对应仓库:
Spring Cloud Stream 的 endpoint 模块,基于 Spring Boot Actuator,提供了自定义监控端点 bindings 和 channels,用于获取 Spring Cloud Stream 的 Binding 和 Channel 信息。
同时,Spring Cloud Stream Kafka 拓展了 Spring Boot Actuator 内置的 health 端点,通过自定义的 KafkaBinderHealthIndicator,获取 Kafka 客户端的健康状态。
友情提示:对 Spring Boot Actuator 不了解的胖友,可以后续阅读《芋道 Spring Boot 监控端点 Actuator 入门》文章。
我们来搭建一个 Spring Cloud Stream RocketMQ 监控端点的使用示例。最终项目如下图所示:
15.1 搭建生产者
从「3. 快速入门」小节的 labx-11-sc-stream-kafka-consumer-demo 项目,复制出 labx-11-sc-stream-kafka-producer-actuator 项目作为生产者。
15.1.1 引入依赖
在 pom.xml 文件中,额外引入 Spring Boot Actuator 相关依赖。代码如下:
<!-- 实现对 Actuator 的自动化配置 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
15.1.2 配置文件
修改 application.yaml 配置文件,额外增加 Spring Boot Actuator 配置项。配置如下:
management:
endpoints:
web:
exposure:
include: '*' # 需要开放的端点。默认值只打开 health 和 info 两个端点。通过设置 * ,可以开放所有端点。
endpoint:
# Health 端点配置项,对应 HealthProperties 配置类
health:
enabled: true # 是否开启。默认为 true 开启。
show-details: ALWAYS # 何时显示完整的健康信息。默认为 NEVER 都不展示。可选 WHEN_AUTHORIZED 当经过授权的用户;可选 ALWAYS 总是展示。
每个配置项的作用,胖友看下艿艿添加的注释。如果还不理解的话,后续看下《芋道 Spring Boot 监控端点 Actuator 入门》文章。
15.1.3 简单测试
① 使用 ProducerApplication 启动生产者。
② 访问应用的 bindings 监控端点 http://127.0.0.1:18080/actuator/bindings,返回结果如下图:
③ 访问应用的 channels 监控端点 http://127.0.0.1:18080/actuator/channels,返回结果如下图:
④ 访问应用的 health 监控端点 http://127.0.0.1:18080/actuator/health,返回结果如下图:
15.2 搭建消费者
从「3. 快速入门」小节的 labx-11-sc-stream-kafka-consumer-demo 项目,复制出 labx-11-sc-stream-kafka-consumer-actuator 项目作为消费者。
15.2.1 引入依赖
在 pom.xml 文件中,额外引入 Spring Boot Actuator 相关依赖。代码如下:
<!-- 实现对 Actuator 的自动化配置 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
15.2.2 配置文件
修改 application.yaml 配置文件,额外增加 Spring Boot Actuator 配置项。配置如下:
management:
endpoints:
web:
exposure:
include: '*' # 需要开放的端点。默认值只打开 health 和 info 两个端点。通过设置 * ,可以开放所有端点。
endpoint:
# Health 端点配置项,对应 HealthProperties 配置类
health:
enabled: true # 是否开启。默认为 true 开启。
show-details: ALWAYS # 何时显示完整的健康信息。默认为 NEVER 都不展示。可选 WHEN_AUTHORIZED 当经过授权的用户;可选 ALWAYS 总是展示。
每个配置项的作用,胖友看下艿艿添加的注释。如果还不理解的话,后续看下《芋道 Spring Boot 监控端点 Actuator 入门》文章。
15.2.3 简单测试
① 使用 ConsumerApplication 启动消费者,随机端口为 15748。
② 访问应用的 bindings 监控端点 http://127.0.0.1:15748/actuator/bindings,返回结果如下图:
③ 访问应用的 channels 监控端点 http://127.0.0.1:15748/actuator/channels,返回结果如下图:
④ 访问应用的 health 监控端点 http://127.0.0.1:15748/actuator/health,返回结果如下图:
--------
SpringCloud事件总线中的Kafka
--------
1. 概述
友情提示:在开始本文之前,胖友需要对 Kafka 进行简单的学习。可以阅读《Kafka 极简入门》文章,将第一二小节看完,在本机搭建一个 Kafka 服务。
Kafka 是一种高吞吐量的分布式发布订阅消息系统,她有如下特性:
- 通过 O(1) 的磁盘数据结构提供消息的持久化,这种结构对于即使数以TB的消息存储也能够保持长时间的稳定性能。
- 高吞吐量:即使是非常普通的硬件kafka也可以支持每秒数十万的消息。
- 支持通过 Kafka 服务器和消费机集群来分区消息。
本文我们来学习 Spring Cloud Bus Kafka 组件,基于 Spring Cloud Bus 的编程模型,接入 Kafka 消息队列,实现事件总线的功能。
Spring Cloud Bus 是事件、消息总线,用于在集群(例如,配置变化事件)中传播状态变化,可与 Spring Cloud Config 联合实现热部署。
在《芋道 Spring Boot 事件机制 Event 入门》文章,我们已经了解到,Spring 内置了事件机制,可以实现 JVM 进程内的事件发布与监听。但是如果想要跨 JVM 进程的事件发布与监听,此时它就无法满足我们的诉求了。
因此,Spring Cloud Bus 在 Spring 事件机制的基础之上进行拓展,结合 RabbitMQ、Kafka、RocketMQ 等等消息队列作为事件的“传输器”,通过发送事件(消息)到消息队列上,从而广播到订阅该事件(消息)的所有节点上。最终如下图所示: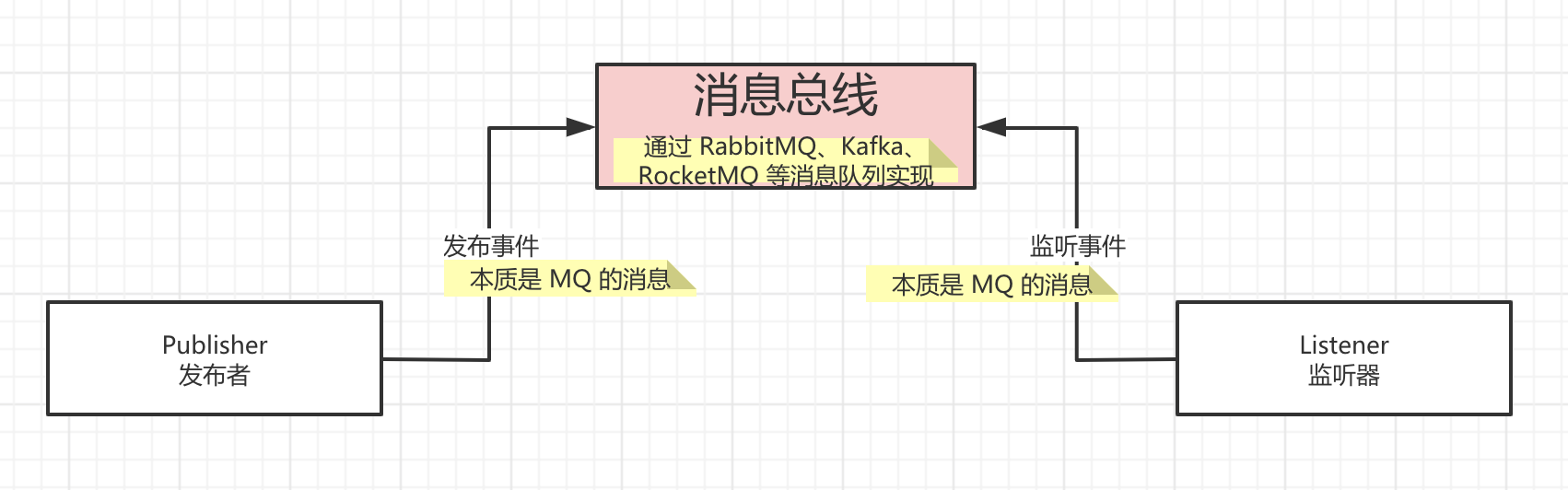
Spring Cloud Bus 定义了 RemoteApplicationEvent 类,远程的 ApplicationEvent 的抽象基类。核心代码如下:
@JsonTypeInfo(use = JsonTypeInfo.Id.NAME, property = "type")
@JsonIgnoreProperties("source") // <2>
public abstract class RemoteApplicationEvent extends ApplicationEvent { // <1>
private final String originService;
private final String destinationService;
private final String id;
// ... 省略一大撮代码
}
-
显然,我们使用 Spring Cloud Bus 发送的自定义事件,必须要继承 RemoteApplicationEvent 类。
-
<1>处,继承 Spring 事件机制定义的 ApplicationEvent 抽象基类。 -
<2>处,通过 Jackson 的@JsonIgnoreProperties注解,设置忽略继承自 ApplicationEvent 的source属性,避免序列化问题。 -
id属性,事件编号。一般情况下,RemoteApplicationEvent 会使用UUID.randomUUID().toString()代码,自动生成 UUID 即可。 -
originService属性,来源服务。Spring Cloud Bus 提供好了ServiceMatcher#getServiceId()方法,获取服务编号作为originService属性的值。友情提示:这个属性非常关键,艿艿稍后会详细讲一下,都是眼泪啊!!!
-
destinationService属性,目标服务。该属性的格式是{服务名}:{服务实例编号}。举个板栗:
- 如果想要广播给所有服务的所有实例,则设置为
**:**。 - 如果想要广播给
users服务的所有实例,则设置为users:**。 - 如如果想要广播给
users服务的指定实例,则设置为users:bc6d27d7-dc0f-4386-81fc-0b3363263a15。
- 如果想要广播给所有服务的所有实例,则设置为
2. 快速入门
示例代码对应仓库:
哔哔再多,不如撸个 Spring Cloud Bus 快速入门的示例。我们会新建两个项目:
labx-19-sc-bus-kafka-demo-publisher:扮演事件发布器的角色,使用 Spring Cloud Bus 发送事件。labx-19-sc-bus-kafka-demo-listener:扮演事件监听器的角色,使用 Spring Cloud Bus 监听事件。
2.1 事件发布器项目
创建 labx-19-sc-bus-kafka-demo-publisher 项目,扮演事件发布器的角色,使用 Spring Cloud Bus 发送事件。
2.1.1 引入依赖
创建 pom.xml 文件,引入 Spring Cloud Bus 相关依赖:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>labx-19</artifactId>
<groupId>cn.iocoder.springboot.labs</groupId>
<version>1.0-SNAPSHOT</version>
</parent>
<modelVersion>4.0.0</modelVersion>
<artifactId>labx-19-sc-bus-kafka-demo-publisher</artifactId>
<properties>
<maven.compiler.target>1.8</maven.compiler.target>
<maven.compiler.source>1.8</maven.compiler.source>
<spring.boot.version>2.2.4.RELEASE</spring.boot.version>
<spring.cloud.version>Hoxton.SR1</spring.cloud.version>
</properties>
<!--
引入 Spring Boot、Spring Cloud、Spring Cloud Alibaba 三者 BOM 文件,进行依赖版本的管理,防止不兼容。
在 https://dwz.cn/mcLIfNKt 文章中,Spring Cloud Alibaba 开发团队推荐了三者的依赖关系
-->
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>${spring.boot.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>${spring.cloud.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<!-- 引入 SpringMVC 相关依赖,并实现对其的自动配置 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- 引入基于 Kafka 的 Spring Cloud Bus 的实现的依赖,并实现对其的自动配置 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-bus-kafka</artifactId>
</dependency>
</dependencies>
</project>
2.1.2 配置文件
创建 application.yml 配置文件,添加 Spring Cloud Bus 相关配置:
spring:
application:
name: publisher-demo
# Kafka 配置项,对应 KafkaProperties 配置类
kafka:
bootstrap-servers: 127.0.0.1:9092 # 指定 Kafka Broker 地址,可以设置多个,以逗号分隔
# Bus 相关配置项,对应 BusProperties
cloud:
bus:
enabled: true # 是否开启,默认为 true
destination: springCloudBus # 目标消息队列,默认为 springCloudBus
① spring.kafka 配置项,为 Kafka 相关配置项。
友情提示:感兴趣的胖友,可以阅读《芋道 Spring Boot 消息队列 Kafka 入门》文章。
② spring.cloud.bus 配置项,为 Spring Cloud Bus 配置项,对应 BusProperties 类。一般情况下,使用默认值即可。
2.1.3 UserRegisterEvent
创建 UserRegisterEvent 类,用户注册事件。代码如下:
public class UserRegisterEvent extends RemoteApplicationEvent {
/**
* 用户名
*/
private String username;
public UserRegisterEvent() { // 序列化
}
public UserRegisterEvent(Object source, String originService, String destinationService, String username) {
super(source, originService);
this.username = username;
}
public String getUsername() {
return username;
}
}
① 继承 RemoteApplicationEvent 抽象基类。
② 创建一个空的构造方法,毕竟要序列化。
2.1.4 DemoController
创建 DemoController 类,提供 /demo/register 注册接口,发送 UserRegisterEvent 事件。代码如下:
@RestController
@RequestMapping("/demo")
public class DemoController {
private Logger logger = LoggerFactory.getLogger(getClass());
@Autowired
private ApplicationEventPublisher applicationEventPublisher;
@Autowired
private ServiceMatcher busServiceMatcher;
@GetMapping("/register")
public String register(String username) {
// ... 执行注册逻辑
logger.info("[register][执行用户({}) 的注册逻辑]", username);
// ... <2> 发布
applicationEventPublisher.publishEvent(new UserRegisterEvent(this, busServiceMatcher.getServiceId(),
null, username)); // <1>
return "success";
}
}
<1> 处,创建 UserRegisterEvent 对象。
originService属性,通过ServiceMatcher#getServiceId()方法,获得服务编号。destinationService属性,我们传入null值。RemoteApplicationEvent 会自动转换成**,表示广播给所有监听该消息的实例。
<2> 处,和 Spring 事件机制一样,通过 ApplicationEventPublisher 的 #publishEvent(event) 方法,直接发送事件到 Spring Cloud Bus 消息总线。好奇的胖友,可以打开 BusAutoConfiguration 的代码,如下图所示:
友情提示:如果胖友仔细看的话,还可以发现 Spring Cloud Bus 是使用 Spring Cloud Stream 进行消息的收发的。
2.1.5 PublisherDemoApplication
创建 PublisherDemoApplication 类,作为启动类。代码如下:
@SpringBootApplication
public class PublisherDemoApplication {
public static void main(String[] args) {
SpringApplication.run(PublisherDemoApplication.class, args);
}
}
2.2 事件监听器项目
创建 labx-19-sc-bus-kafka-demo-listener 项目,扮演事件监听器的角色,使用 Spring Cloud Bus 监听事件。
2.2.1 引入依赖
创建 pom.xml 文件,引入相关的依赖。和「2.1.1 引入依赖」是一致的,就不重复“贴”出来了,胖友点击 pom.xml 文件查看。
2.2.2 配置文件
创建 application.yaml 配置文件,添加相关的配置项。和「2.1.2 配置文件」是一致的,就不重复“贴”出来了,胖友点击 application.yaml 文件查看。
2.2.3 UserRegisterEvent
创建 UserRegisterEvent 类,用户注册事件。和「2.1.3 UserRegisterEvent」是一致的,就不重复“贴”出来了,胖友点击 UserRegisterEvent 文件查看。
2.2.4 UserRegisterListener
创建 UserRegisterListener 类,监听 UserRegisterEvent 事件。代码如下:
/**
* 用户注册事件的监听器
*/
@Component
public class UserRegisterListener implements ApplicationListener<UserRegisterEvent> {
private Logger logger = LoggerFactory.getLogger(getClass());
@Override
public void onApplicationEvent(UserRegisterEvent event) {
logger.info("[onApplicationEvent][监听到用户({}) 注册]", event.getUsername());
}
}
和 Spring 事件机制一样,只需要监听指定事件即可。好奇的胖友,可以打开 BusAutoConfiguration 的代码,如下图所示:
2.2.5 ListenerDemoApplication
创建 ListenerDemoApplication 类,作为启动类。代码如下:
@SpringBootApplication
@RemoteApplicationEventScan
public class ListenerDemoApplication {
public static void main(String[] args) {
SpringApplication.run(ListenerDemoApplication.class, args);
}
}
在类上,添加 Spring Cloud Bus 定义的 @RemoteApplicationEventScan 注解,声明要从 Spring Cloud Bus 监听 RemoteApplicationEvent 事件。
2.3 简单测试
① 执行 PublisherDemoApplication 一次,启动一个事件发布器。
② 执行 ListenerDemoApplication 两次,启动两个事件监听器。需要将「Allow parallel run」进行勾选,如下图所示:
此时,我们可以在 Kafka 运维界面看到 springCloudBus 这个 Topic,如下图所示:
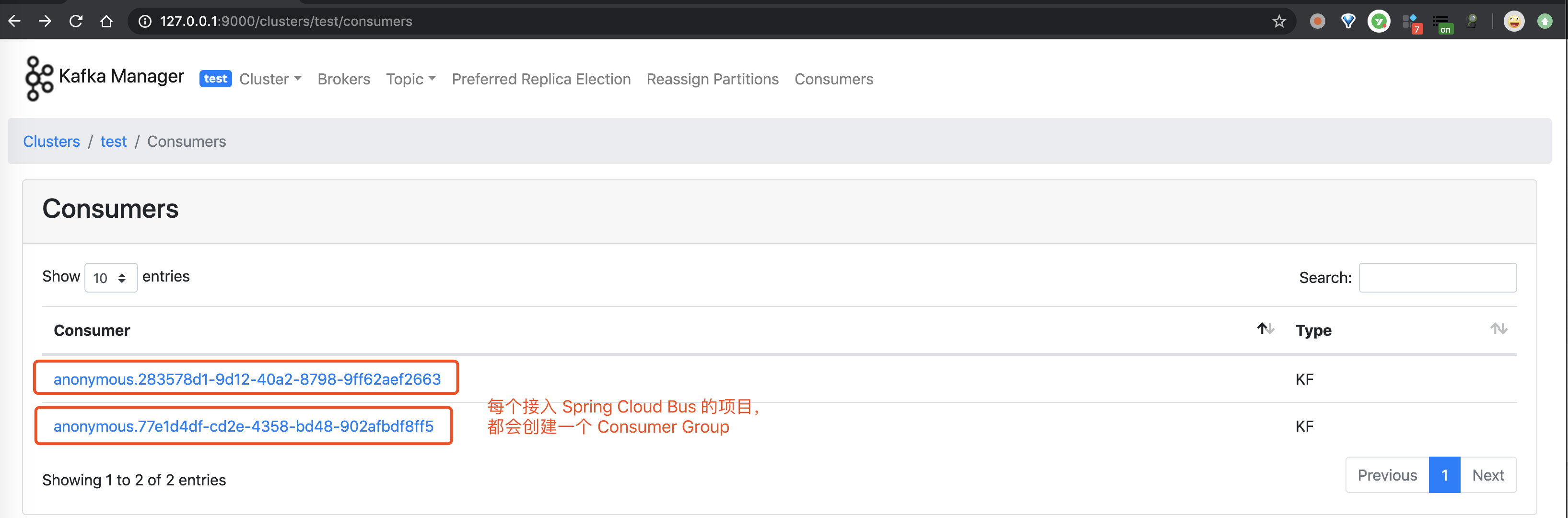
③ 调用 http://127.0.0.1:8080/demo/register?username=yudaoyuanma 接口,进行注册。IDEA 控制台打印日志如下:
# PublisherDemoApplication 控制台
2020-04-09 07:42:03.417 INFO 31050 --- [nio-8080-exec-1] c.i.s.l.p.controller.DemoController : [register][执行用户(haha) 的注册逻辑]
# ListenerDemoApplication 控制台 01
2020-04-09 07:42:03.603 INFO 31027 --- [container-0-C-1] c.i.s.l.l.listener.UserRegisterListener : [onApplicationEvent][监听到用户(haha) 注册]
# ListenerDemoApplication 控制台 02
2020-04-09 07:42:03.603 INFO 31040 --- [container-0-C-1] c.i.s.l.l.listener.UserRegisterListener : [onApplicationEvent][监听到用户(haha) 注册]
发布的 UserRegisterEvent 事件,被两个事件监听器的进程都监听成功。
3. 监控端点
Spring Cloud Bus 的 endpoint 模块,基于 Spring Boot Actuator,提供了两个自定义监控端点:
bus-env端点:发布 EnvironmentChangeRemoteApplicationEvent 事件,配合 EnvironmentChangeListener 监听器,实现通知并修改远程服务的本地配置项。如下图所示:
bus-refresh端点:发布 RefreshRemoteApplicationEvent 事件,配合 RefreshListener 监听器,实现通知并刷新远程服务的 Spring Context。如下图所示:
同时,Spring Cloud Bus 拓展了 Spring Boot Actuator 内置的 httptrace 端点,会监听 Spring Cloud Bus 发送消息时产生的 SentApplicationEvent 事件和确认消息的产生 AckRemoteApplicationEvent 事件,配合 TraceListener 监听器,记录相应的跟踪信息。不过因为 httptrace 端点改版了,所以目前该功能已经失效,而且失效了 2 年多了,具体代码如下:
友情提示:对 Spring Boot Actuator 不了解的胖友,可以后续阅读《芋道 Spring Boot 监控端点 Actuator 入门》文章。
我们来搭建一个 Spring Cloud Bus 监控端点的使用示例。考虑方便,我们直接复用「2. 快速入门」小节的项目,从 labx-19-sc-bus-kafka-demo-listener 复制出 labx-19-sc-bus-kafka-demo-listener-actuator,测试 Spring Cloud Bus 的监控端点结果。最终项目如下图所示: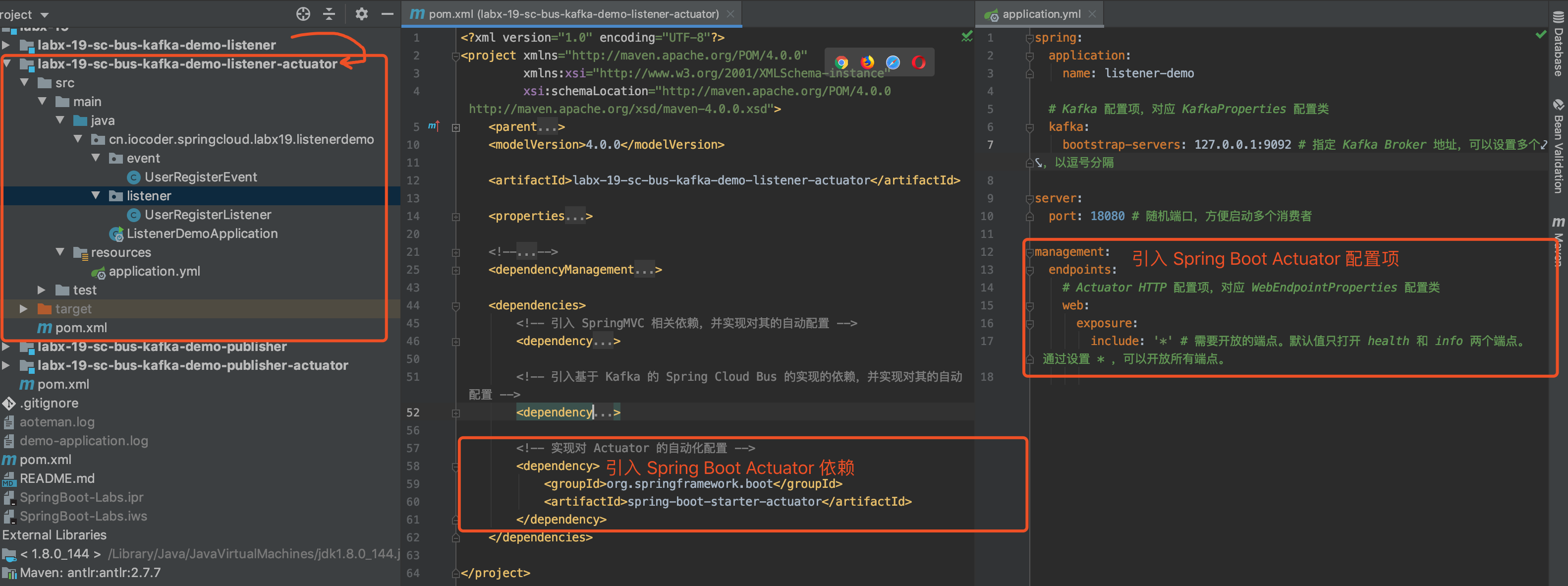
友情提示:不使用
labx-19-sc-bus-kafka-demo-publisher的原因是,未添加@RemoteApplicationEventScan注解,不会从 Spring Cloud Bus 中监听 RemoteApplicationEvent 事件。
3.1 引入依赖
在 pom.xml 文件中,额外引入 Spring Boot Actuator 相关依赖。代码如下:
<!-- 实现对 Actuator 的自动化配置 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
3.2 配置文件
修改 application.yaml 配置文件,额外增加 Spring Boot Actuator 配置项。配置如下:
spring:
application:
name: listener-demo
# Kafka 配置项,对应 KafkaProperties 配置类
kafka:
bootstrap-servers: 127.0.0.1:9092 # 指定 Kafka Broker 地址,可以设置多个,以逗号分隔
server:
port: 18080 # 随机端口,方便启动多个消费者
management:
endpoints:
# Actuator HTTP 配置项,对应 WebEndpointProperties 配置类
web:
exposure:
include: '*' # 需要开放的端点。默认值只打开 health 和 info 两个端点。通过设置 * ,可以开放所有端点。
新增 management 配置项,设置 Spring Boot Actuator 配置项。这里先不详细解析,后续看下《芋道 Spring Boot 监控端点 Actuator 入门》文章。
3.3 简单测试
执行 ListenerDemoApplication 启动项目。
① 使用 Postman 模拟请求 bus-env 端点,如下图所示: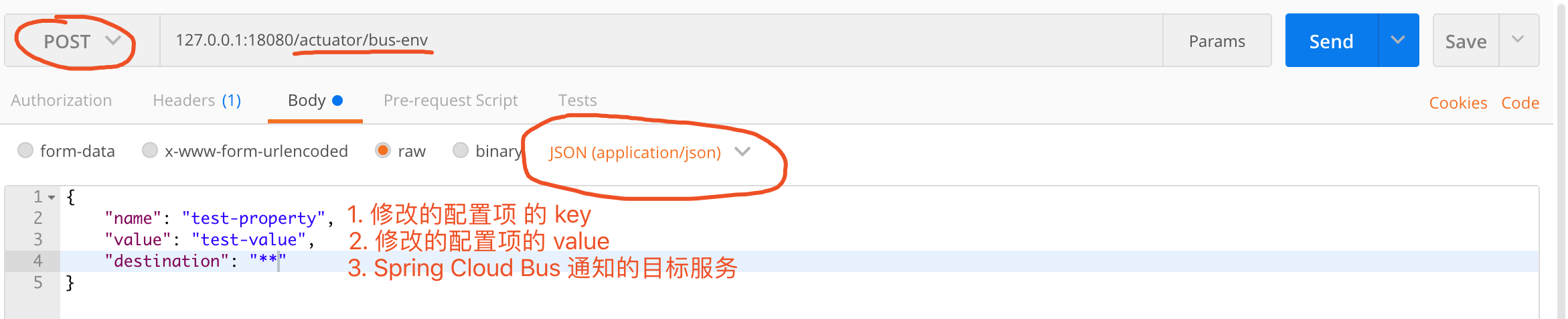
此时,我们在控制台可以看到 EnvironmentChangeListener 打印日志如下,说明成功接收到 EnvironmentChangeRemoteApplicationEvent 事件:
2020-04-09 07:53:33.737 INFO 31712 --- [io-18080-exec-1] o.s.c.b.event.EnvironmentChangeListener : Received remote environment change request. Keys/values to update {test-property=test-value}
② 使用 Postman 模拟请求 bus-refresh 端点,如下图所示:
此时,我们在控制台可以看到 RefreshListener 打印日志如下,说明成功接收到 RefreshRemoteApplicationEvent 事件:
2020-04-09 07:53:46.409 INFO 31712 --- [io-18080-exec-2] o.s.cloud.bus.event.RefreshListener : Received remote refresh request. Keys refreshed []
4. 集成到 Spring Cloud Config
实际上,Spring Cloud Bus 在日常开发中,基本不会使用到。绝大多数情况下,我们通过使用 Spring Cloud Stream 即可实现它所有的功能,并且更加强大和灵活。同时,艿艿也找了一些在使用 Spring Cloud 作为微服务解决方案的胖友,确实一个都没有在使用 Spring Cloud Bus 的 = =。
倔强的艿艿又翻阅了网上的相关资料,绝大多数都是提到通过 Spring Cloud Bus,实现 Spring Cloud Config 配置中心的自动配置刷新的功能。因此,可能我们不是很必要去学习它,哈哈哈。
不过良心的艿艿,还是在《芋道 Spring Cloud 配置中心 Spring Cloud Config 入门》文章的「5. 自动配置刷新(第二弹)」小节中,将 Spring Cloud Bus 集成到 Spring Cloud Config 中,实现配置中心的自动配置刷新的功能。
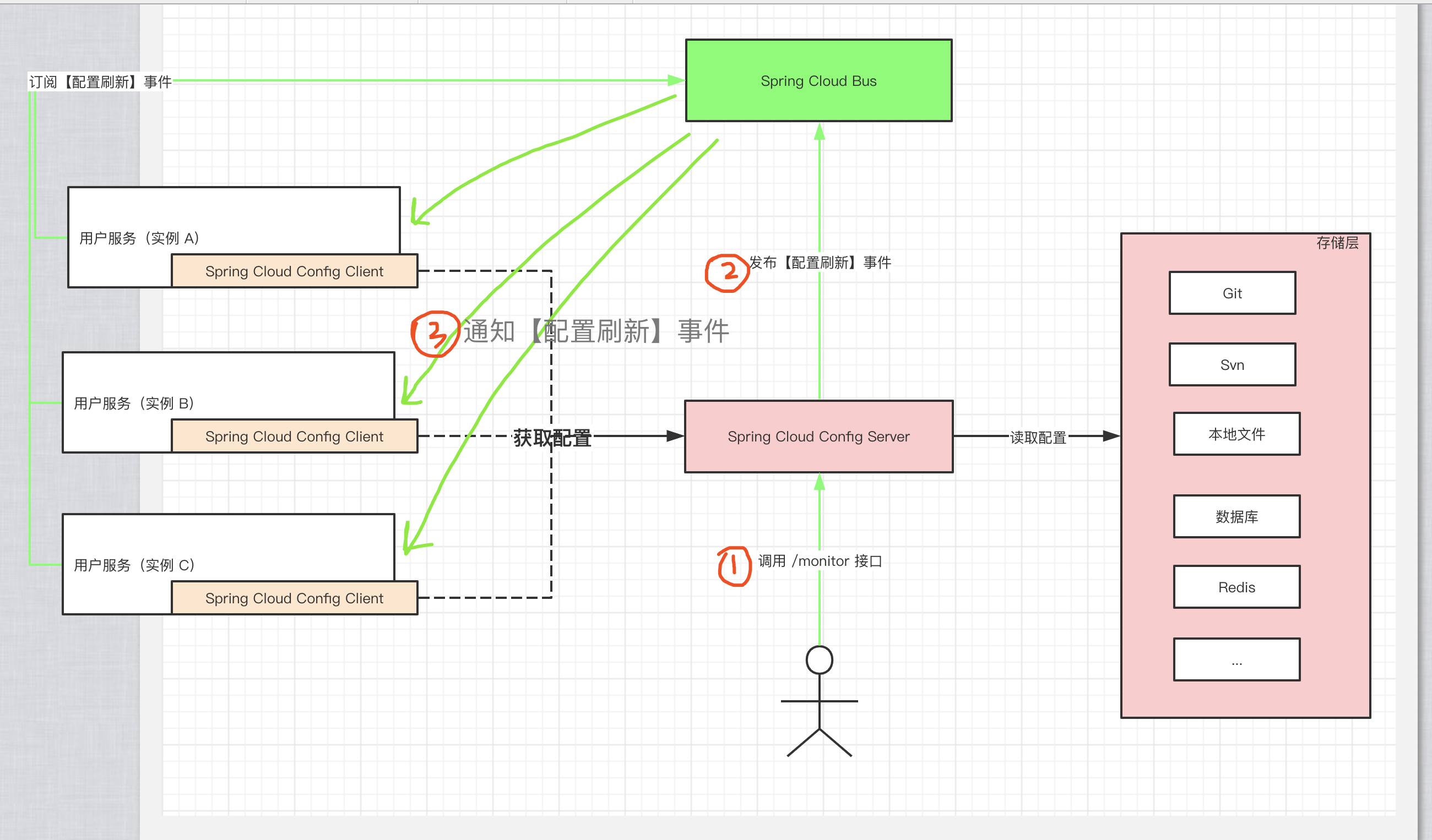
示例代码对应仓库:


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义