字符串格式化及函数
(1)字符串格式化
Python的字符串格式化有两种方式: 百分号方式、format方式
1.百分号格式
%[(name)][flags][width].[precision]typecode
- (name) 可选,用于选择指定的key
- flags 可选,可供选择的值有:
- + 右对齐;正数前加正好,负数前加负号;
- - 左对齐;正数前无符号,负数前加负号;
- 空格 右对齐;正数前加空格,负数前加负号;
- 0 右对齐;正数前无符号,负数前加负号;用0填充空白处
- width 可选,占有宽度
- .precision 可选,小数点后保留的位数
- typecode 必选
- s,获取传入对象的__str__方法的返回值,并将其格式化到指定位置
- r,获取传入对象的__repr__方法的返回值,并将其格式化到指定位置
- c,整数:将数字转换成其unicode对应的值,10进制范围为 0 <= i <= 1114111(py27则只支持0-255);字符:将字符添加到指定位置
- o,将整数转换成 八 进制表示,并将其格式化到指定位置
- x,将整数转换成十六进制表示,并将其格式化到指定位置
- d,将整数、浮点数转换成 十 进制表示,并将其格式化到指定位置
- e,将整数、浮点数转换成科学计数法,并将其格式化到指定位置(小写e)
- E,将整数、浮点数转换成科学计数法,并将其格式化到指定位置(大写E)
- f, 将整数、浮点数转换成浮点数表示,并将其格式化到指定位置(默认保留小数点后6位)
- F,同上
- g,自动调整将整数、浮点数转换成 浮点型或科学计数法表示(超过6位数用科学计数法),并将其格式化到指定位置(如果是科学计数则是e;)
- G,自动调整将整数、浮点数转换成 浮点型或科学计数法表示(超过6位数用科学计数法),并将其格式化到指定位置(如果是科学计数则是E;)
- %,当字符串中存在格式化标志时,需要用 %%表示一个百分号
注:Python中百分号格式化是不存在自动将整数转换成二进制表示的方式
常用:%s>>>>>>输入为字符串
%d>>>>>>输入格式为数字
%f>>>>>>>输入格式为浮点型,即小数,在%后加.数字表示保留小数点后几位,在f后加%%输入百分数
2.Format方式
[[fill]align][sign][#][0][width][,][.precision][type]
- fill 【可选】空白处填充的字符
- align 【可选】对齐方式(需配合width使用)
- <,内容左对齐
- >,内容右对齐(默认)
- =,内容右对齐,将符号放置在填充字符的左侧,且只对数字类型有效。 即使:符号+填充物+数字
- ^,内容居中
- sign 【可选】有无符号数字
- +,正号加正,负号加负;
- -,正号不变,负号加负;
- 空格 ,正号空格,负号加负;
- # 【可选】对于二进制、八进制、十六进制,如果加上#,会显示 0b/0o/0x,否则不显示
- , 【可选】为数字添加分隔符,如:1,000,000
- width 【可选】格式化位所占宽度
- .precision 【可选】小数位保留精度
- type 【可选】格式化类型
- 传入” 字符串类型 “的参数
- s,格式化字符串类型数据
- 空白,未指定类型,则默认是None,同s
- 传入“ 整数类型 ”的参数
- b,将10进制整数自动转换成2进制表示然后格式化
- c,将10进制整数自动转换为其对应的unicode字符
- d,十进制整数
- o,将10进制整数自动转换成8进制表示然后格式化;
- x,将10进制整数自动转换成16进制表示然后格式化(小写x)
- X,将10进制整数自动转换成16进制表示然后格式化(大写X)
- 传入“ 浮点型或小数类型 ”的参数
- e, 转换为科学计数法(小写e)表示,然后格式化;
- E, 转换为科学计数法(大写E)表示,然后格式化;
- f , 转换为浮点型(默认小数点后保留6位)表示,然后格式化;
- F, 转换为浮点型(默认小数点后保留6位)表示,然后格式化;
- g, 自动在e和f中切换
- G, 自动在E和F中切换
- %,显示百分比(默认显示小数点后6位)
注意,在字符串中引用format,默认替换变量下标由0开始
(2)函数》》》》》def
特点:一次创建可多次调用,增强代码的重用性和可读性,调用函数过程中,函数的代码块中变量会被赋值,但在调用结束后,变量对应的值会被清空,不会占用内存空间
1 def 函数名(参数): 2 3 ... 4 函数体 5 ... 6 返回值
函数的定义主要有如下要点:
- def:标识符,表示函数的关键字,
- 函数名:函数的名称,日后根据函数名调用函数,函数名实质也是一个变量
- 函数体:函数中进行一系列的逻辑计算,如:发送邮件、计算出 [11,22,38,888,2]中的最大数等...
- 参数:为函数体提供数据
- 返回值:当函数执行完毕后,可以给调用者返回数据。,结束函数,可以一个return返回多个值以元组形式呈现,若没设置返回值,则会隐式返回一个none,
1.参数
函数参数分为形式参数跟实际参数
形式参数:在函数名后面括号里作为函数体逻辑判断的变量名
实际参数,在调用函数时,赋值给函数变量的值
位置参数和关键字(标准调用:实参与形参位置一一对应;关键字调用:位置无需固定)
默认参数,在定义形式参数的时候给参数赋值
参数组(*args》》》传列表元素,**kwargs传字典元素)
*arg若不传参数不会报错,会输出一个空元组,列表前不加*号默认将整个列表作为一个元素传给*arg
**kwarg若不传参数不会报错,会输出一个空字典,传值方式有键值对(类似于关键字传值)传值跟*+字典传值
2.局部变量与全局变量
全局变量:顶头无缩进定义的变量,对全局有效的变量
局部变量:在函数中定义的变量,只在调用该函数的时候对函数体起作用
global:声明修改全局变量
nonlocal:在函数内声明修改上一层变量,只能修改函数内变量,可以隔层往上寻找该变量,若最外层函数不存在该变量,会报错
name = "alex"#定义全局变量无缩进
def con(): name1 = "aric"#在函数中定义的变量为局部变量 print(name1)
name = "alex"#定义全局变量无缩进 def con(): name1 = "aric"#在函数中定义的变量为局部变量 print(name1)#》》》》aric con()#调用函数时候,局部变量只在函数内有效 print(name)#》》》》alex
n1 = "alex" def n2(): n1 = 123 print(n1)#》》》》123 def n3(): nonlocal n1#》》》》声明修改上一层变量 n1 = "aric" n3() print(n1)#》》》》aric print(n1)#》》》》alex n2() print(n1)#》》》》》alex
n1 = "aric" def coin(): global n1#global声明修改全局变量 n1 = "aric" print(n1)#》》》aric coin() print(n1)#》》》》aric
(3)函数的引用
由于python执行代码的顺序是由前之后,所以若要引用某函数,需先在引用之前定义好该函数,若在定义之前引用函数则会报错
def u(): pass q() u()#报错,q()未定义
def u(): pass q() def q(): pass u() q()#可以执行
(3)嵌套函数
在函数内层继续定义函数,调用函数的时候只能调用最外层函数,不能直接调用内层函数
作用域在定义函数时就已经固定住了,不会随着调用位置的改变而改变
n1 = "alex" def n2(): n1 = 123 print(n1)#》》》》123 def n3():#嵌套函数 nonlocal n1 n1 = "aric" n3() print(n1)#》》》》aric print(n1)#》》》》alex n2()
print(n1)#》》》》》alex
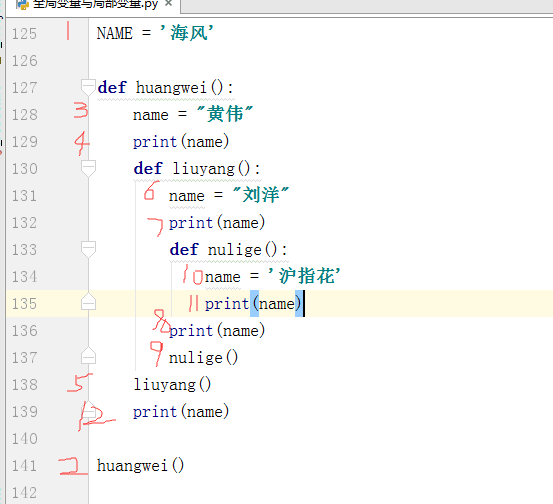
(4)递归函数
在函数内部,可以调用其他函数。如果一个函数在内部调用自身本身,这个函数就是递归函数。
递归特性:
1. 必须有一个明确的结束条件
2. 每次进入更深一层递归时,问题规模相比上次递归都应有所减少
3. 递归效率不高,递归层次过多会导致栈溢出(在计算机中,函数调用是通过栈(stack)这种数据结构实现的,每当进入一个函数调用,栈就会加一层栈帧,每当函数返 回,栈就会减一层栈帧。由于栈的大小不是无限的,所以,递归调用的次数过多,会导致栈溢出。)
def cl(n): print(n) if (int(n/2)) == 0: return n return cl(int(n/2))#调用函数本身 cl(10)
(5)匿名函数》》》》lambda
匿名函数就是不需要显式的指定函数,直接可以调用,不需要先定义,形式为lambda x:x的逻辑体,其中x为变量,处理结果为输出经过x的逻辑体处理过的x的值,即函数中 的return,使用匿名函数可以简化很多简单函数
1 v = lambda x,y,z:(x+1,y+1,z+1)#表示x,y,z分别+1并以列表输出 2 print(v(1,2,3))#>>>>(2, 3, 4)
(6)函数式编程
当下主流的编程方法有三种:函数式,面向过程,面向对象,
函数式编程:函数式=编程语言定义的函数+数学意义的函数
特点:不可变数据(不用变量保存状态,不修改变量)
第一类对象(函数名可以当做参数传递,返回值可以是函数名)
尾调用优化(尾递归),在函数的最后一步调用另外一个函数(最后一行不一定是函数的最后一步)
高阶函数:满足俩个特性任意一个即为高阶函数(1.函数的传入参数是一个函数名,2.函数的返回值是一个函数名)
1.map函数用法:
map(a,b),a为处理逻辑,b为要处理的可迭代对象,处理过程(处理逻辑依次处理b中的元素),在python2中直接生成列表,在python3中需用list转换
1 l1 = [1,2,3,4,5,6,7] 2 def redu(x): 3 return x-1 4 print(list(map(redu,l1)))#map(a,b),a为处理逻辑,b为要处理的可迭代对象,处理过程(处理逻辑依次处理b中的元素),在python2中直接生成列表,在python3中需用list转换 5 print(list(map(lambda x:x-1,l1)))#运用匿名函数可以简化很多过程
1 a = "alex" 2 print(list(map(lambda x:x.upper(),a)))#>>>>>>['A', 'L', 'E', 'X']map可以处理很多可迭代对象
2.reduce函数用法:遍历对象,运用逻辑将可迭代对象合并
1 s = [1,2,3,4,5] 2 def reduce_test(func,array,init=None): 3 l=list(array) 4 if init is None: 5 res=l.pop(0) 6 else: 7 res=init 8 for i in l: 9 res=func(res,i) 10 return res 11 print(reduce_test(lambda x,y:x+y,s,50))#>>>>65
3.filter函数用法:相当于一个过滤器,filter(a,b)a相当于处理逻辑以布尔值方式作判断处理可迭代对象b,符合逻辑的保留,不符合的删除,生成迭代器,用list转换为列表
1 s = ["sb_alex","sb_wupeiqi","sb_yuanhao","linhaifeng"] 2 print(list(filter(lambda s:not s.startswith("sb"),s))) #>>>>>['linhaifeng']

 浙公网安备 33010602011771号
浙公网安备 33010602011771号