Pytorch建模过程中的DataLoader与Dataset
处理数据样本的代码会因为处理过程繁杂而变得混乱且难以维护,在理想情况下,我们希望数据预处理过程代码与我们的模型训练代码分离,以获得更好的可读性和模块化,为此,PyTorch提供了torch.utils.data.DataLoader 和 torch.utils.data.Dataset两个类用于数据处理。其中torch.utils.data.DataLoader用于将数据集进行打包封装成一个可迭代对象,torch.utils.data.Dataset存储有一些常用的数据集示例以及相关标签。
同时PyTorch针对不同的专业领域,也提供有不同的模块,例如 TorchText(自然语言处理), TorchVision(计算机视觉), TorchAudio(音频),这些模块中也都包含一些真实数据集示例。例如TorchVision模块中提供了CIFAR, COCO, FashionMNIST 数据集。
1 定义数据集¶
pytorch中提供两种风格的数据集定义方式:
- 字典映射风格。之所以称为映射风格,是因为在后续加载数据迭代时,pytorch将自动使用迭代索引作为key,通过字典索引的方式获取value,本质就是将数据集定义为一个字典,使用这种风格时,需要继承
Dataset类。
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
dataset = {0: '张三', 1:'李四', 2:'王五', 3:'赵六', 4:'陈七'}
dataloader = DataLoader(dataset, batch_size=2)
for i, value in enumerate(dataloader):
print(i, value)
0 ['张三', '李四'] 1 ['王五', '赵六'] 2 ['陈七']
- 迭代器风格。在自定义数据集类中,实现
__iter__和__next__方法,即定义为迭代器,在后续加载数据迭代时,pytorch将依次获取value,使用这种风格时,需要继承IterableDataset类。这种方法在数据量巨大,无法一下全部加载到内存时非常实用。
from torch.utils.data import DataLoader
from torch.utils.data import IterableDataset
dataset = [i for i in range(10)]
dataloader = DataLoader(dataset=dataset, batch_size=3, shuffle=True)
for i, item in enumerate(dataloader): # 迭代输出
print(i, item)
0 tensor([3, 1, 2]) 1 tensor([9, 7, 5]) 2 tensor([0, 8, 4]) 3 tensor([6])
如下所示,我们有一个蚂蚁蜜蜂图像分类数据集,目录结构如下所示,下面我们结合这个数据集,分别介绍如何使用这两个类定义真实数据集。
data
└── hymenoptera_data
├── train
│ ├── ants
│ │ ├── 0013035.jpg
│ │ ……
│ └── bees
│ ├── 1092977343_cb42b38d62.jpg
│ ……
└── val
├── ants
│ ├── 10308379_1b6c72e180.jpg
│ ……
└── bees
├── 1032546534_06907fe3b3.jpg
……1.2 Dataset类¶
自定义一个Dataset类,继承torch.utils.data.Dataset,且必须实现下面三个方法:
-
Dataset类里面的
__init__函数初始化一些参数,如读取外部数据源文件。 -
Dataset类里面的
__getitem__函数,映射取值是调用的方法,获取单个的数据,训练迭代时将会调用这个方法。 -
Dataset类里面的
__len__函数获取数据的总量。
import os
import pandas as pd
from PIL import Image
from torchvision.transforms import ToTensor, Lambda
from torchvision import transforms
import torchvision
class AntBeeDataset(Dataset):
# 把图片所在的文件夹路径分成两个部分,一部分是根目录,一部分是标签目录,这是因为标签目录的名称我们需要用到
def __init__(self, root_dir, transform=None, target_transform=None):
"""
root_dir:存放数据的根目录,即:data/hymenoptera_data
transform: 对图像数据进行处理,例如,将图片转换为Tensor、图片的维度可能不一致需要进行resize
target_transform:对标签数据进行处理,例如,将文本标签转换为数值
"""
self.root_dir = root_dir
self.transform = transform
self.target_transform = target_transform
# 获取文件夹下所有图片的名称和对应的标签
self.img_lst = []
for label in ['ants', 'bees']:
path = os.path.join(root_dir, label)
for img_name in os.listdir(path):
self.img_lst.append((os.path.join(root_dir, label, img_name), label))
def __getitem__(self, idx):
img_path, label = self.img_lst[idx]
img = Image.open(img_path).convert('RGB')
if self.transform:
img = self.transform(img)
if self.target_transform:
label = self.target_transform(label)
# 这个地方要注意,我们在计算loss的时候用交叉熵nn.CrossEntropyLoss()
# 交叉熵的输入有两个,一个是模型的输出outputs,一个是标签targets,注意targets是一维tensor
# 例如batchsize如果是2,ants的targets的应该[0,0],而不是[[0][0]]
# 因此label要返回0,而不是[0]
return img, label
def __len__(self):
return len(self.img_lst)
train_transform = transforms.Compose([
transforms.RandomResizedCrop(224), # 将给定图像随机裁剪为不同的大小和宽高比,然后缩放所裁剪得到的图像为制定的大小
transforms.RandomHorizontalFlip(), # 以给定的概率随机水平旋转给定的PIL的图像,默认为0.5
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
# 验证集并不需要做与训练集相同的处理,所有,通常使用更加简单的transformer
val_transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
# 根据标签目录的名称来确定图片是哪一类,如果是"ants",标签设置为0,如果是"bees",标签设置为1
target_transform = transforms.Lambda(lambda y: 0 if y == "ants" else 1)
train_dataset = AntBeeDataset('data/hymenoptera_data/train', transform=train_transform, target_transform=target_transform)
val_dataset = AntBeeDataset('data/hymenoptera_data/val', transform=val_transform, target_transform=target_transform)
1.2 Dataset数据集常用操作¶
1. 查看数据集大小:¶
len(train_dataset), len(val_dataset)
(245, 153)
2. 合并数据集¶
dataset = train_dataset + val_dataset
len(dataset)
398
3. 划分训练集、测试集¶
from torch.utils.data import random_split
# random_split 不能直接使用百分比划分,必须指定具体数字
train_size = int( len(dataset) * 0.8)
test_size = len(dataset) - train_size
train_dataset, val_dataset = random_split(dataset, [train_size, test_size])
len(train_dataset), len(val_dataset)
(318, 80)
1.3 IterableDataset类¶
使用迭代器风格时,必须继承IterableDataset类,且实现下面两个方法:
-
__init__,函数初始化一些参数,如读取外部数据源文件,在数据量过大时,通常只是获取操作句柄、数据库连接。 -
__iter__,获取迭代器。
虽然只需要实现这两个方法,但是通常还需要在迭代过程中对数据进行处理。IterableDataset类实现自定义数据集,本质就是创建一个数据集类,且实现__iter__返回一个迭代器。一下提供两种方法通过IterableDataset类自定义数据集:
方法一:¶
class AntBeeIterableDataset(IterableDataset):
# 把图片所在的文件夹路径分成两个部分,一部分是根目录,一部分是标签目录,这是因为标签目录的名称我们需要用到
def __init__(self, root_dir, transform=None, target_transform=None):
"""
root_dir:存放数据的根目录,即:data/hymenoptera_data
transform: 对图像数据进行处理,例如,将图片转换为Tensor、图片的维度可能不一致需要进行resize
target_transform:对标签数据进行处理,例如,将文本标签转换为数值
"""
self.root_dir = root_dir
self.transform = transform
self.target_transform = target_transform
# 获取文件夹下所有图片的名称和对应的标签
self.img_lst = []
for label in ['ants', 'bees']:
path = os.path.join(root_dir, label)
for img_name in os.listdir(path):
self.img_lst.append((os.path.join(root_dir, label, img_name), label))
def __iter__(self):
for img_path, label in self.img_lst:
img = Image.open(img_path).convert('RGB')
if self.transform:
img = self.transform(img)
if self.target_transform:
label = self.target_transform(label)
yield img, label
方法二:¶
class AntBeeIterableDataset(IterableDataset):
# 把图片所在的文件夹路径分成两个部分,一部分是根目录,一部分是标签目录,这是因为标签目录的名称我们需要用到
def __init__(self, root_dir, transform=None, target_transform=None):
"""
root_dir:存放数据的根目录,即:data/hymenoptera_data
transform: 对图像数据进行处理,例如,将图片转换为Tensor、图片的维度可能不一致需要进行resize
target_transform:对标签数据进行处理,例如,将文本标签转换为数值
"""
self.root_dir = root_dir
self.transform = transform
self.target_transform = target_transform
# 获取文件夹下所有图片的名称和对应的标签
self.img_lst = []
for label in ['ants', 'bees']:
path = os.path.join(root_dir, label)
for img_name in os.listdir(path):
self.img_lst.append((os.path.join(root_dir, label, img_name), label))
self.index = 0
def __iter__(self):
return self
def __next__(self):
try:
img_path, label = self.img_lst[self.index]
self.index += 1
img = Image.open(img_path).convert('RGB')
if self.transform:
img = self.transform(img)
if self.target_transform:
label = self.target_transform(label)
return img, label
except IndexError:
raise StopIteration()
train_dataset = AntBeeIterableDataset('data/hymenoptera_data/train', transform=train_transform, target_transform=target_transform)
val_dataset = AntBeeIterableDataset('data/hymenoptera_data/val', transform=val_transform, target_transform=target_transform)
在处理大数据集时,IterableDataset会比Dataset更有优势,例如数据存储在文件或者数据库中,只需要在自定义的IterableDataset之类中获取文件操作句柄或者数据库连接和游标惊喜迭代,每次只返回一条数据即可。我们把上文中蚂蚁蜜蜂数据集的所有图片、标签这里后写入hymenoptera_data.txt中,内容如下所示,假设有数亿行,那么,就不能直接将数据加载到内存了:
data/hymenoptera_data/train/ants/2288481644_83ff7e4572.jpg, ants
data/hymenoptera_data/train/ants/2278278459_6b99605e50.jpg, ants
data/hymenoptera_data/train/ants/543417860_b14237f569.jpg, ants
...
...可以参考一下方式定义IterableDataset子类:
class AntBeeIterableDataset(IterableDataset):
# 把图片所在的文件夹路径分成两个部分,一部分是根目录,一部分是标签目录,这是因为标签目录的名称我们需要用到
def __init__(self, filepath, transform=None, target_transform=None):
"""
filepath:hymenoptera_data.txt完整路径
transform: 对图像数据进行处理,例如,将图片转换为Tensor、图片的维度可能不一致需要进行resize
target_transform:对标签数据进行处理,例如,将文本标签转换为数值
"""
self.filepath = filepath
self.transform = transform
self.target_transform = target_transform
def __iter__(self):
with open(self.filepath, 'r') as f:
for line in f:
img_path, label = line.replace('\n', '').split(', ')
img = Image.open(img_path).convert('RGB')
if self.transform:
img = self.transform(img)
if self.target_transform:
label = self.target_transform(label)
yield img, label
train_dataset = AntBeeIterableDataset('hymenoptera_data.txt', transform=train_transform, target_transform=target_transform)
注意,IterableDataset方法在处理大数据集时确实比Dataset更有优势,但是,IterableDataset在迭代过程中,样本输出顺序是固定的,在使用DataLoader进行加载时,无法使用shuffle进行打乱,同时,因为在IterableDataset中并未强制限定必须实现__len__()方法(很多时候确实也没法获取数据总量),不能通过len()方法获取数据总量。
2 DataLoad¶
DataLoader的功能是构建可迭代的数据装载器,在训练的时候,每一个for循环,每一次Iteration,就是从DataLoader中获取一个batch_size大小的数据,节省内存的同时,它还可以实现多进程、数据打乱等处理。我们通过一张图来了解DataLoader数据读取机制:
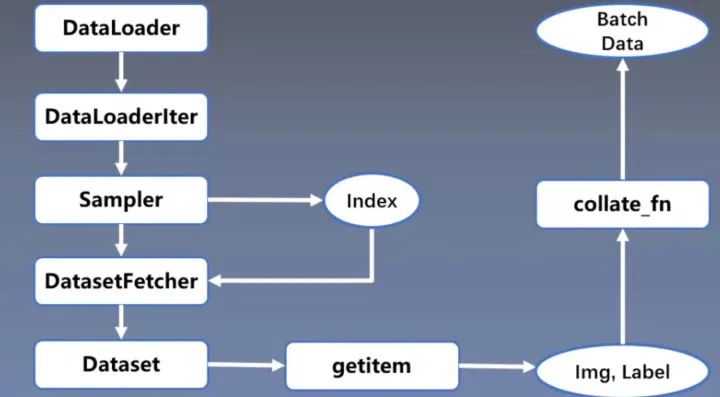
首先,在for循环中使用了DataLoader,进入DataLoader后,首先根据是否使用多进程DataLoaderIter,做出判断之后单线程还是多线程,接着使用Sampler得索引Index,然后将索引给到DatasetFetcher,在这里面调用Dataset,根据索引,通过getitem得到实际的数据和标签,得到一个batch size大小的数据后,通过collate_fn函数整理成一个Batch Data的形式输入到模型去训练。
在pytorch建模的数据处理、加载流程中,DataLoader应该算是最核心的一步操作DataLoader有很多参数,这里我们列出常用的几个:
- dataset:表示Dataset类,它决定了数据从哪读取以及如何读取;
- batch_size:表示批大小;
- num_works:表示是否多进程读取数据;
- shuffle:表示每个epoch是否乱序;
- drop_last:表示当样本数不能被batch_size整除时,是否舍弃最后一批数据;
- num_workers:启动多少个进程来加载数据。
我们重点说说多进程模式下使用DataLoader,在多进程模式下,每次 DataLoader 创建 iterator 时(遍历DataLoader时,例如,当调用时enumerate(dataloader)),都会创建 num_workers 工作进程。dataset, collate_fn, worker_init_fn 都会被传到每个worker中,每个worker都用独立的进程。
对于映射风格的数据集,即Dataset子类,主线程会用Sampler(采样器)产生indice,并将它们送到进程里。因此,shuffle是在主线程做的
对于迭代器风格的数据集,即IterableDataset子类,因为每个进程都有相同的data复制样本,并在各个进程里进行不同的操作,以防止每个进程输出的数据是重复的,所以一般用 torch.utils.data.get_worker_info() 来进行辅助处理。
这里,torch.utils.data.get_worker_info() 返回worker进程的一些信息(id, dataset, num_workers, seed),如果在主线程跑的话返回None
注意,通常不建议在多进程加载中返回CUDA张量,因为在使用CUDA和在多处理中共享CUDA张量时存在许多微妙之处(文档中提出:只要接收过程保留张量的副本,就需要发送过程来保留原始张量)。建议采用 pin_memory=True ,以将数据快速传输到支持CUDA的GPU。简而言之,不建议在使用多线程的情况下返回CUDA的tensor。
dataload = DataLoader(train_dataset, batch_size=2)
img, label = next(iter(dataload))
img.shape, label
(torch.Size([2, 3, 224, 224]), tensor([0, 0]))

作者:奥辰
微信号:chb1137796095
Github:https://github.com/ChenHuabin321
欢迎加V交流,共同学习,共同进步!
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接,否则保留追究法律责任的权利。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号