seaborn学习笔记(三):直方图、条形图、条带图
1 直方图与条形图¶
在过去很长一段时间,我一直分不清直方图和条形图,或者说一直认为两者是一样的,直到看到histplot()和barplot()两个绘图方法,前者是绘制直方图,后者是绘制条形图。通过仔细对比两者各项功能后,我得出结论,两者十分相似,但有些许不同:直方图侧重于统计数据在数轴上各个位置的分布情况,统计的对象往往是连续型数值数据的,根据数值的大小分区间进行分组统计,例如有100个学生的身高,需要统计100个学生在各个身高段的分布情况;条形图不同,条形图分组往往是针对离散型数据或者说定性的分类数据,例如对比男生的平均身高和女生的平均身高。不知道我这么理解对不对,欢迎留言讨论。
2 histplot():直方图¶
主要参数如下:
- data:绘图数据,可以是pandas.DataFrame,numpy.ndarray或者字典等
- x,y:指定的x轴, y轴数据,可以是向量或者字符串,当是字符串时,一定是data中的一个key
- hue:可以是向量(pandas中的一列,或者是list),也可以是字符串(data中的一个key),seaborn将根据这一列设置不同颜色
- weights: 数据加权的权重
-
stat: 柱形的统计方式
1)count:统计每个区间的值的个数
2)frequency:区间内取值个数除以区间宽度
3)probability或proportion:进行标准化使条形高度总和为1
4)percent:标准化使条形总高度为100
5)使条形总面积为1
- bins: 字符型、整型、向量都可以,可以是引用规则的名称、箱子的数量或箱子的分段或者分箱规则名称,规则名称见下方示例
- binwidth: 条形宽度
- binrange: 条形边缘的最大值或最小值
- discrete: 如果为True,则默认为binwidth=1,并绘制条形图,使其位于相应数据点的中心。这避免了在使用离散(整数)数据时可能出现的“间隙”。
- cumulative: 布尔型,是否逐个累加每个条形高度进行绘图
- multiple: 直接看下文效果吧
- element: 直接看下文效果吧
- fill: 条形内部是否填充颜色
- shrink: 缩小条形的宽度
- kde: 是否生成核密度曲线
- color: 设置条形颜色
- legend: 是否显示图例
- ax: 绘图的坐标轴实例
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
penguins = sns.load_dataset('penguins',data_home='.')
penguins.head(2)
2.1 为图像设置标题¶
histplot()方法返回值为matplotlib.axes._subplots.AxesSubplot类实例,通过实例的set_title()方法可以为图像添加标题:
pic = sns.histplot(penguins, x="flipper_length_mm")
pic.set_title('flipper_length_mm')
2.2 ax:自定义绘图坐标系¶
在不传递ax参数时,seaborn会自行创建坐标系进行绘图,我们也可以自己创建坐标系,通过ax参数传递,这样做的好处是可以灵活绘制多个子图:
fig, ax =plt.subplots(1,2,constrained_layout=True, figsize=(8, 3))
pic = sns.histplot(penguins, x="flipper_length_mm", ax=ax[0])
pic = sns.histplot(penguins, x="body_mass_g", ax=ax[1])
另外,在histplot()方法中,没有提供太多关于坐标轴设置的参数,难以对坐标轴进行个性化定制,如果在绘图前,先创建好坐标轴,即可完成对坐标轴的设置(关于坐标轴的创建和设置,请参考Matplotlib数据可视化(2):三大容器对象与常用设置
ax=plt.axes((0.1, 0.1, 0.8, 0.7), facecolor='green')
pic = sns.histplot(penguins, x="flipper_length_mm", ax=ax)
2.3 x, y:传递数据,控制图形方向¶
x, y参数不能同时传递,当传递x时,x轴为数据取值范围,y轴为统计次数;当传递y值时,y轴为数据取值范围,x轴为统计次数:
fig, ax =plt.subplots(1,2,constrained_layout=True, figsize=(8, 3))
pic = sns.histplot(penguins, x="flipper_length_mm", ax=ax[0])
pic.set_title('x')
pic = sns.histplot(penguins, y="flipper_length_mm", ax=ax[1])
pic.set_title('y')
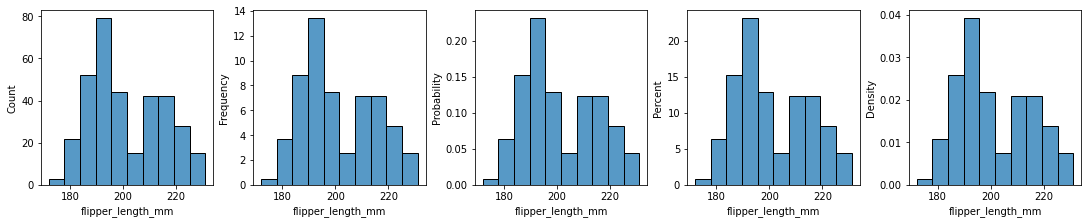
2.4 stat:y轴显示数据的方式¶
fig, ax =plt.subplots(1,5,constrained_layout=True, figsize=(15, 3))
_ = sns.histplot(penguins, x="flipper_length_mm", stat="count", ax=ax[0]) # count, 也是默认值
_ = sns.histplot(penguins, x="flipper_length_mm", stat="frequency", ax=ax[1]) # frequency
_ = sns.histplot(penguins, x="flipper_length_mm", stat="probability", ax=ax[2])# probability
_ = sns.histplot(penguins, x="flipper_length_mm", stat="percent", ax=ax[3]) # percent
_ = sns.histplot(penguins, x="flipper_length_mm", stat="density", ax=ax[4]) # density
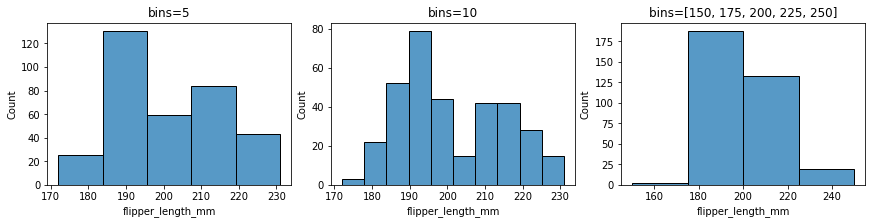
2.5 bins:指定分箱方式¶
指定分箱个数或者每个条形区间进行绘图:
fig, ax =plt.subplots(1,3,constrained_layout=True, figsize=(12, 3))
pic = sns.histplot(penguins, x="flipper_length_mm", ax=ax[0], bins=5)
pic.set_title('bins=5')
pic = sns.histplot(penguins, x="flipper_length_mm", ax=ax[1], bins=10)
pic.set_title('bins=10')
pic = sns.histplot(penguins, x="flipper_length_mm", ax=ax[2], bins=[150, 175, 200, 225, 250])
pic.set_title('bins=[150, 175, 200, 225, 250]')
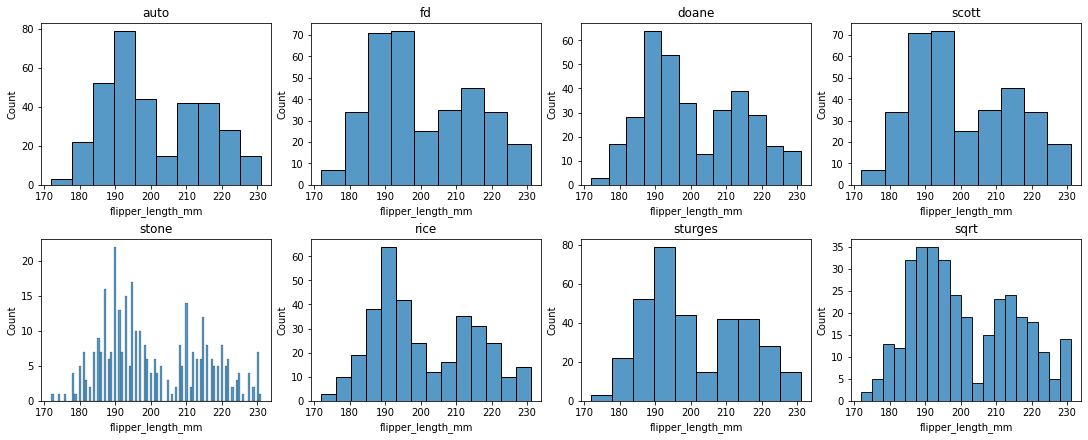
也可以指定分箱的规则:
fig, ax =plt.subplots(2,4,constrained_layout=True, figsize=(15, 6))
pic = sns.histplot(penguins, x="flipper_length_mm", bins="auto", ax=ax[0][0]) # count, 也是默认值
pic.set_title('auto')
pic = sns.histplot(penguins, x="flipper_length_mm", bins="fd", ax=ax[0][1]) # frequency
pic.set_title('fd')
pic = sns.histplot(penguins, x="flipper_length_mm", bins="doane", ax=ax[0][2])# probability
pic.set_title('doane')
pic = sns.histplot(penguins, x="flipper_length_mm", bins="scott", ax=ax[0][3]) # percent
pic.set_title('scott')
pic = sns.histplot(penguins, x="flipper_length_mm", bins="stone", ax=ax[1][0]) # count, 也是默认值
pic.set_title('stone')
pic = sns.histplot(penguins, x="flipper_length_mm", bins="rice", ax=ax[1][1]) # frequency
pic.set_title('rice')
pic = sns.histplot(penguins, x="flipper_length_mm", bins="sturges", ax=ax[1][2])# probability
pic.set_title('sturges')
pic = sns.histplot(penguins, x="flipper_length_mm", bins="sqrt", ax=ax[1][3]) # percent
pic.set_title('sqrt')
2.6 binwidth:设置柱形宽度¶
fig, ax =plt.subplots(1,2,constrained_layout=True, figsize=(8, 3))
_ = sns.histplot(penguins, x="flipper_length_mm", ax=ax[0], binwidth=1)
_ = sns.histplot(penguins, x="flipper_length_mm", ax=ax[1], binwidth=3)
2.7 cumulative:累积每个条形高度进行绘图¶
sns.histplot(penguins, x="flipper_length_mm", cumulative=True)
sns.histplot(penguins, x="flipper_length_mm", multiple="layer")
2.8 hue:颜色区分条形组成¶
_ = sns.histplot(penguins, x="flipper_length_mm", hue="species")
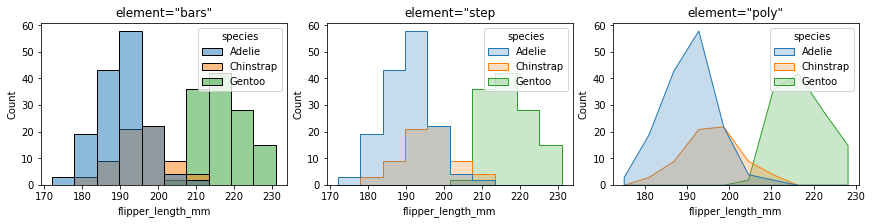
2.9 element¶
fig, ax =plt.subplots(1,3,constrained_layout=True, figsize=(12, 3))
pic = sns.histplot(penguins, x="flipper_length_mm", hue="species", ax=ax[0], element="bars")
pic.set_title('element="bars"')
pic = sns.histplot(penguins, x="flipper_length_mm", hue="species", ax=ax[1], element="step")
pic.set_title('element="step')
pic = sns.histplot(penguins, x="flipper_length_mm", hue="species", ax=ax[2], element="poly")
pic.set_title('element="poly"')
2.10 multiple¶
fig, ax =plt.subplots(1,4,constrained_layout=True, figsize=(16, 3))
pic = sns.histplot(penguins, x="flipper_length_mm", hue="species", ax=ax[0], multiple="layer")
pic.set_title('multiple="layer"')
pic = sns.histplot(penguins, x="flipper_length_mm", hue="species", ax=ax[1], multiple="dodge")
pic.set_title('multiple="dodge')
pic = sns.histplot(penguins, x="flipper_length_mm", hue="species", ax=ax[2], multiple="stack")
pic.set_title('multiple="stack"')
pic = sns.histplot(penguins, x="flipper_length_mm", hue="species", ax=ax[3], multiple="fill")
pic.set_title('multiple="fill"')

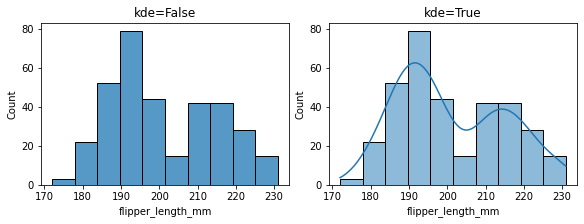
2.11 kde:是否生成核密度曲线¶
fig, ax =plt.subplots(1,2,constrained_layout=True, figsize=(8, 3))
pic = sns.histplot(penguins, x="flipper_length_mm", ax=ax[0], kde=False) # 默认值,不生成核密度曲线
pic.set_title('kde=False')
pic = sns.histplot(penguins, x="flipper_length_mm", ax=ax[1], kde=True) # 值为True,显示核密度曲线
pic.set_title('kde=True')
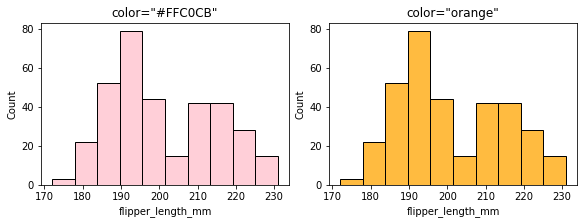
2.12 color:设置条形颜色¶
fig, ax =plt.subplots(1,2,constrained_layout=True, figsize=(8, 3))
pic = sns.histplot(penguins, x="flipper_length_mm", ax=ax[0], color="#FFC0CB") # 可以使16进制颜色
pic.set_title('color="#FFC0CB"')
pic = sns.histplot(penguins, x="flipper_length_mm", ax=ax[1], color="orange") # 也可以是 英文颜色字符串
pic.set_title('color="orange"')
fig, ax =plt.subplots(1,2,constrained_layout=True, figsize=(8, 3))
pic = sns.histplot(penguins, x="flipper_length_mm", ax=ax[0], color="#FFC0CB") # 可以使16进制颜色
pic.set_title('color="#FFC0CB"')
pic = sns.histplot(penguins, x="flipper_length_mm", ax=ax[1], color="orange") # 也可以是 英文颜色字符串
pic.set_title('color="orange"')
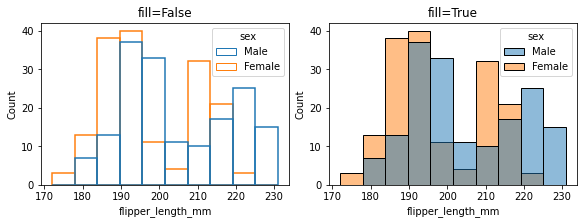
2.13 fill:条形内部是否填充颜色¶
fig, ax =plt.subplots(1,2,constrained_layout=True, figsize=(8, 3))
pic = sns.histplot(penguins, x="flipper_length_mm", hue='sex', ax=ax[0], fill=False)
pic.set_title('fill=False')
pic = sns.histplot(penguins, x="flipper_length_mm", hue='sex', ax=ax[1], fill=True)
pic.set_title('fill=True')
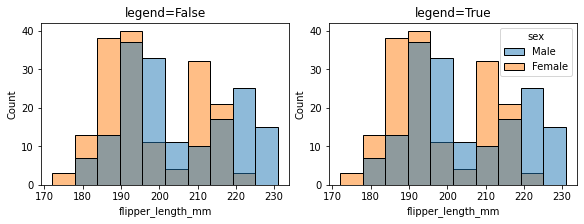
2.14 legend:是否显示图例¶
fig, ax =plt.subplots(1,2,constrained_layout=True, figsize=(8, 3))
pic = sns.histplot(penguins, x="flipper_length_mm", hue="sex", ax=ax[0], legend=False)
pic.set_title('legend=False')
pic = sns.histplot(penguins, x="flipper_length_mm", hue="sex", ax=ax[1], legend=True)
pic.set_title('legend=True')
2.15 shrink:缩小条形¶
shrink参数可以缩小条形增大条形之间的间隔:
fig, ax =plt.subplots(1,2,constrained_layout=True, figsize=(8, 3))
pic = sns.histplot(penguins, x="flipper_length_mm", ax=ax[0], shrink=0.5)
pic.set_title('shrink=0.5')
# pic = sns.histplot(penguins, x="flipper_length_mm", ax=ax[1], bins=10)
pic = sns.histplot(penguins, x="flipper_length_mm", ax=ax[1], shrink=0.8)
pic.set_title('shrink=0.8')
2.16 edgecolor:指定边框颜色¶
_ = sns.histplot(penguins, x="flipper_length_mm", edgecolor="red")
3 barplot():条形图¶
- x,y:指定的x轴, y轴数据,可以是向量或者字符串,当是字符串时,一定是data中的一个key
- hue:可以是向量(pandas中的一列,或者是list),也可以是字符串(data中的一个key),seaborn将根据这一列设置不同颜色
- data:绘图数据,可以是pandas.DataFrame,numpy.ndarray或者字典等
- order:包含所有分组属性的列表,用于指定条形顺序,注意如果某个分组不在order中,该分组将不会显示
- hue_order:字符串组成的list,设置hue后设置各颜色顺序
-
estimator:可调用对象,分组统计的方式,或者说条形图长度所表示的意义,可以使以下值:
-
len:调用内置的len方法统计数据总长
-
np.mean:表示统计各分组平均值,这也是默认的方式
-
np.sum:表示统计各分组总和
-
np.ptp:极差
-
np.median:统计中位数
-
np.std:标准差
-
np.var:方差
-
- ci:float或者"sd"或None,在估计值附近绘制置信区间的大小,如果是"sd",则跳过bootstrapping并绘制观察的标准差,如果为None,则不执行bootstrapping,并且不绘制错误条。
- orient:当x,y都是离散型或者数值型数据时,通过orient可设置图像方向
- color:为所有条形设置统一颜色
- palette:颜色面板,比color参数功能更加强大,更加个性化地设置条形的颜色
- errcolor:错误带的颜色
- errwidth:错误带的宽度
- capsize:错误带“帽子”宽度
- ax:自定义坐标系
tips = sns.load_dataset("tips")
tips.head(2)
3.1 x, y:传递数据,控制图形方向¶
x, y为绘图时指定的x轴和y轴数据,x、y如果有一个是离散型数据(或者说定性数据、分类数据),另一个是连续性数值数据,seaborn将会根据其中的离散型数据对另一个连续性数据进行分组统计,同时也决定绘图的方向。如果两个都是数值型数据,可以通过orient指定方向。
fig, ax =plt.subplots(1,2,constrained_layout=True, figsize=(8, 3))
pic = sns.barplot(x="total_bill", y="day", data=tips, ax=ax[0])
pic.set_title('x="total_bill", y="day"')
pic = sns.barplot(x="day", y="total_bill", data=tips, ax=ax[1])
pic.set_title('x="day", y="total_bill"')
3.2 estimator:分组统计方式¶
fig, ax =plt.subplots(1,3,constrained_layout=True, figsize=(12, 3))
pic = sns.barplot(x="day", y="total_bill", data=tips, ax=ax[0], estimator=np.mean)
pic.set_title('estimator=np.mean')
pic = sns.barplot(x="day", y="total_bill", data=tips, ax=ax[1], estimator=np.std)
pic.set_title('np.std')
pic = sns.barplot(x="day", y="total_bill", data=tips, ax=ax[2], estimator=len) # 内置方法len统计总次数
pic.set_title('len')
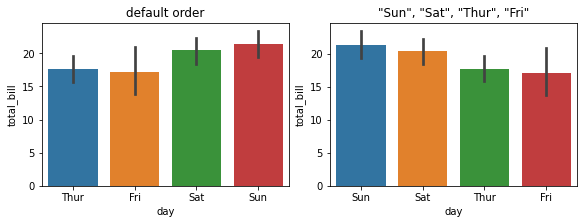
3.3 order:指定条形顺序¶
fig, ax =plt.subplots(1,2,constrained_layout=True, figsize=(8, 3))
pic = sns.barplot(x="day", y="total_bill", data=tips, ax=ax[0])
pic.set_title('default order')
pic = sns.barplot(x="day", y="total_bill", data=tips, order=['Sun', 'Sat', 'Thur', 'Fri'], ax=ax[1])
pic.set_title('"Sun", "Sat", "Thur", "Fri"')
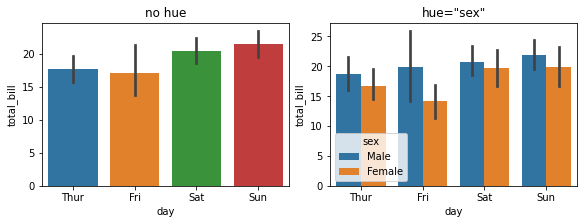
3.4 hue:根据字段设置不同颜色¶
fig, ax =plt.subplots(1,2,constrained_layout=True, figsize=(8, 3))
pic = sns.barplot(x="day", y="total_bill", data=tips, ax=ax[0])
pic.set_title('no hue')
pic = sns.barplot(x="day", y="total_bill", data=tips, ax=ax[1], hue="sex")
pic.set_title('hue="sex"')
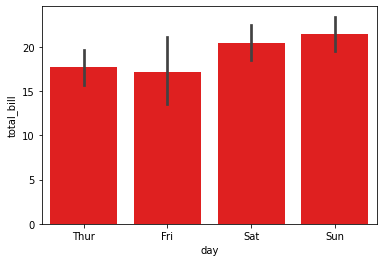
3.5 color,saturation:设置条形颜色和饱和度¶
注意,color只能一次性设置所有条形统一的颜色,如果要为条形设置不同颜色,要通过palette参数:
ax = sns.barplot(x="day", y="total_bill", data=tips, color="red")
ax = sns.barplot(x="day", y="total_bill", data=tips, color="red",saturation=0.5 )
3.6 errcolor:错误带的颜色¶
ax = sns.barplot(x="day", y="total_bill", data=tips, errcolor="red")
3.7 errwidth:错误带的宽度¶
ax = sns.barplot(x="day", y="total_bill", data=tips, errwidth=8)
3.8 capsize:错误带“帽子”宽度¶
ax = sns.barplot(x="day", y="total_bill", data=tips, capsize=.2)
4 stripplot():条带图¶
条带图是是一种比较少见的图表,综合了散点图和直方图/条形图的图形特征和优势,其表达的含义又与箱型图十分类似。stripplot()参数如下:
- x,y:指定的x轴, y轴数据,可以是向量或者字符串,当是字符串时,一定是data中的一个key
- hue:可以是向量(pandas中的一列,或者是list),也可以是字符串(data中的一个key),seaborn将根据这一列设置不同颜色
- data:绘图数据,可以是pandas.DataFrame,numpy.ndarray或者字典等
- order:包含所有分组属性的列表,用于指定条形顺序,注意如果某个分组不在order中,该分组将不会显示
- hue_order:字符串组成的list,设置hue后设置各颜色顺序
- jitter:抖动量,当数据很多时,增加抖动量,使散点不至于聚成一团
- dodge:在hue基础上,将不同颜色的散点分开
- orient:当x,y都是离散型或者数值型数据时,通过orient可设置图像方向
- color:统一设置所有散点的颜色
- palette:颜色面板
- size:散点的大小
- edgecolor:散点的边框颜色
- linewidth:散点边框宽度
- ax:自定义坐标系
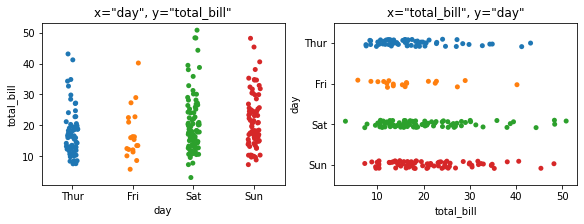
4.1 x, y:传递数据,控制图形方向¶
x, y为绘图时指定的x轴和y轴数据,x、y如果有一个是离散型数据(或者说定性数据、分类数据),另一个是连续性数值数据,seaborn将会根据其中的离散型数据对另一个连续性数据进行绘制其在另一条数轴上的分布。
fig, ax =plt.subplots(1,2,constrained_layout=True, figsize=(8, 3))
pic = sns.stripplot(x="day", y="total_bill", data=tips, ax=ax[0])
pic.set_title('x="day", y="total_bill"')
pic = sns.stripplot(x="total_bill", y="day", data=tips, ax=ax[1])
pic.set_title('x="total_bill", y="day"')
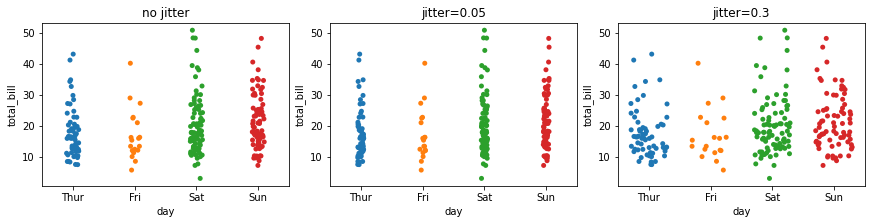
4.2 jitter:抖动量¶
fig, ax =plt.subplots(1,3,constrained_layout=True, figsize=(12, 3))
pic = sns.stripplot(x="day", y="total_bill", data=tips, ax=ax[0], )
pic.set_title('no jitter')
pic = sns.stripplot(x="day", y="total_bill", data=tips, ax=ax[1], jitter=0.05)
pic.set_title('jitter=0.05')
pic = sns.stripplot(x="day", y="total_bill", data=tips, ax=ax[2], jitter=0.3)
pic.set_title('jitter=0.3')
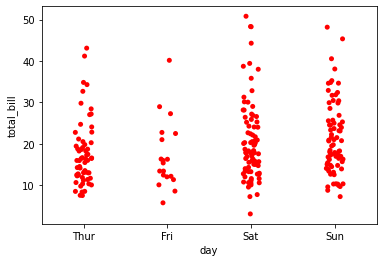
4.3 color:统一设置散点的颜色¶
sns.stripplot(x="day", y="total_bill", data=tips, color='red')
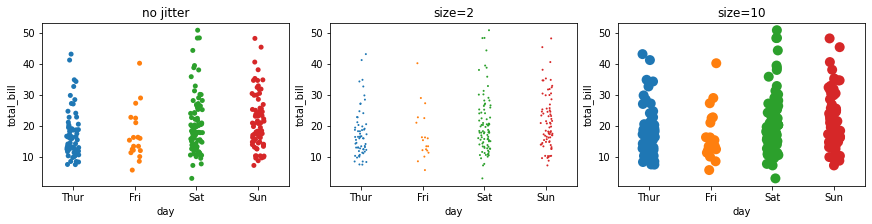
4.4 size:散点的大小¶
fig, ax =plt.subplots(1,3,constrained_layout=True, figsize=(12, 3))
pic = sns.stripplot(x="day", y="total_bill", data=tips, ax=ax[0], )
pic.set_title('no jitter')
pic = sns.stripplot(x="day", y="total_bill", data=tips, ax=ax[1], size=2)
pic.set_title('size=2')
pic = sns.stripplot(x="day", y="total_bill", data=tips, ax=ax[2], size=10)
pic.set_title('size=10')
4.5 linewidth与edgecolor:散点边框宽度、颜色¶
fig, ax =plt.subplots(1,4,constrained_layout=True, figsize=(16, 3))
pic = sns.stripplot(x="day", y="total_bill", data=tips, ax=ax[0], )
pic.set_title('no linewidth')
pic = sns.stripplot(x="day", y="total_bill", data=tips, ax=ax[1], linewidth=1)
pic.set_title('linewidth=1')
pic = sns.stripplot(x="day", y="total_bill", data=tips, ax=ax[2], linewidth=2)
pic.set_title('linewidth=2')
pic = sns.stripplot(x="day", y="total_bill", data=tips, ax=ax[3], linewidth=1, edgecolor="yellow")
pic.set_title('linewidth=1, edgecolor="red"')

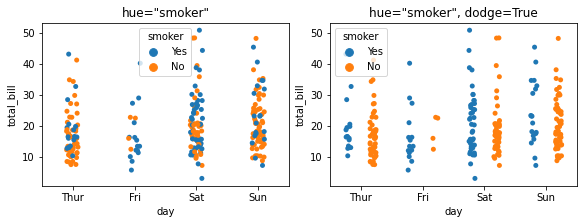
4.6 hue与dodge:根据指定指定绘制散点颜色¶
hue和dodge常常需要一起配合使用,hue只是根据指定字段绘制不同颜色的散点,进一步地,dodge可以将不同颜色的散点分开
fig, ax =plt.subplots(1,2,constrained_layout=True, figsize=(8, 3))
pic = sns.stripplot(x="day", y="total_bill", data=tips, ax=ax[0], hue="smoker")
pic.set_title('hue="smoker"')
pic = sns.stripplot(x="day", y="total_bill", data=tips, ax=ax[1], hue="smoker", dodge=True)
pic.set_title('hue="smoker", dodge=True')

作者:奥辰
微信号:chb1137796095
Github:https://github.com/ChenHuabin321
欢迎加V交流,共同学习,共同进步!
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接,否则保留追究法律责任的权利。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号