MySQL数据库之存储过程与存储函数
1 引言
存储过程和存储函数类似于面向对象程序设计语言中的方法,可以简化代码,提高代码的重用性。本文主要介绍如何创建存储过程和存储函数,以及存储过程与函数的使用、修改、删除等操作。
2 存储过程与存储函数
MySQL中提供存储过程与存储函数机制,我们姑且将存储过程和存储函数合称为存储程序。与一般的SQL语句需要先编译然后立即执行不同,存储程序是一组为了完成特定功能的SQL语句集,经编译后存储在数据库中,当用户通过指定存储程序的名字并给定参数(如果该存储程序带有参数)来调用才会执行。
存储程序就是一条或者多条SQL语句和控制语句的集合,我们可以将其看作MySQL的批处理文件,当然,其作用不仅限于批处理。当想要在不同的应用程序或平台上执行相同的功能一段程序或者封装特定功能时,存储程序是非常有用的。数据库中的存储程序可以看做是面向对编程中面向对象方法,它允许控制数据的访问方式。
存储函数与存储过程有如下区别:
(1)存储函数的限制比较多,例如不能用临时表,只能用表变量,而存储过程的限制较少,存储过程的实现功能要复杂些,而函数的实现功能针对性比较强。
(2)返回值不同。存储函数必须有返回值,且仅返回一个结果值;存储过程可以没有返回值,但是能返回结果集(out,inout)。
(3)调用时的不同。存储函数嵌入在SQL中使用,可以在select 存储函数名(变量值);存储过程通过call语句调用 call 存储过程名。
(4)参数的不同。存储函数的参数类型类似于IN参数,没有类似于OUT和INOUT的参数。存储过程的参数类型有三种,IN、out和INOUT:
a. in:数据只是从外部传入内部使用(值传递),可以是数值也可以是变量
b. out:只允许过程内部使用(不用外部数据),给外部使用的(引用传递:外部的数据会被先清空才会进入到内部),只能是变量
c. inout:外部可以在内部使用,内部修改的也可以给外部使用,典型的引用 传递,只能传递变量。
3 存储过程
3.1 创建存储过程
创建存储过程语法结构如下:
CREATE PROCEDURE 过程名([[IN|OUT|INOUT] 参数名 数据类型[,[IN|OUT|INOUT] 参数名 数据类型…]]) [特性 ...] BEGIN 过程体 END
CREATE PROCEDURE是用来创建存储过程的关键字;[IN|OUT|INOUT]是参数的输入输出类型,IN表示输入参数,OUT表示输出参数,INOUT表示既可以输入也可以输出;过程体是包含若干SQL语句或流程控制语句的集合,可以用BEGIN…END来包裹。
在演示如果创建存储过程之前(emp表、dept表),先创建两个数据表,本文所有演示操作都基于这两个表来进行,创建表与插入数据SQL语句如下:
emp表:
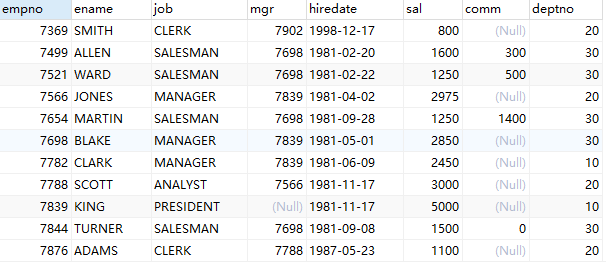


SET NAMES utf8mb4; SET FOREIGN_KEY_CHECKS = 0; -- ---------------------------- -- Table structure for emp -- ---------------------------- DROP TABLE IF EXISTS `emp`; CREATE TABLE `emp` ( `empno` int(4) NOT NULL, `ename` varchar(10) CHARACTER SET latin1 COLLATE latin1_swedish_ci NULL DEFAULT NULL, `job` varchar(9) CHARACTER SET latin1 COLLATE latin1_swedish_ci NULL DEFAULT NULL, `mgr` int(4) NULL DEFAULT NULL, `hiredate` date NULL DEFAULT NULL, `sal` float(7, 2) NULL DEFAULT NULL, `comm` float(7, 2) NULL DEFAULT NULL, `deptno` int(2) NULL DEFAULT NULL, PRIMARY KEY (`empno`) USING BTREE ) ENGINE = InnoDB CHARACTER SET = latin1 COLLATE = latin1_swedish_ci ROW_FORMAT = Compact; -- ---------------------------- -- Records of emp -- ---------------------------- INSERT INTO `emp` VALUES (7369, 'SMITH', 'CLERK', 7902, '1998-12-17', 800.00, NULL, 20); INSERT INTO `emp` VALUES (7499, 'ALLEN', 'SALESMAN', 7698, '1981-02-20', 1600.00, 300.00, 30); INSERT INTO `emp` VALUES (7521, 'WARD', 'SALESMAN', 7698, '1981-02-22', 1250.00, 500.00, 30); INSERT INTO `emp` VALUES (7566, 'JONES', 'MANAGER', 7839, '1981-04-02', 2975.00, NULL, 20); INSERT INTO `emp` VALUES (7654, 'MARTIN', 'SALESMAN', 7698, '1981-09-28', 1250.00, 1400.00, 30); INSERT INTO `emp` VALUES (7698, 'BLAKE', 'MANAGER', 7839, '1981-05-01', 2850.00, NULL, 30); INSERT INTO `emp` VALUES (7782, 'CLARK', 'MANAGER', 7839, '1981-06-09', 2450.00, NULL, 10); INSERT INTO `emp` VALUES (7788, 'SCOTT', 'ANALYST', 7566, '1981-11-17', 3000.00, NULL, 20); INSERT INTO `emp` VALUES (7839, 'KING', 'PRESIDENT', NULL, '1981-11-17', 5000.00, NULL, 10); INSERT INTO `emp` VALUES (7844, 'TURNER', 'SALESMAN', 7698, '1981-09-08', 1500.00, 0.00, 30); INSERT INTO `emp` VALUES (7876, 'ADAMS', 'CLERK', 7788, '1987-05-23', 1100.00, NULL, 20); INSERT INTO `emp` VALUES (7900, 'JAMES', 'CLERK', 7698, '1981-12-03', 950.00, NULL, 30); INSERT INTO `emp` VALUES (7902, 'FORD', 'ANALYST', 7566, '1981-12-03', 3000.00, NULL, 20); INSERT INTO `emp` VALUES (7934, 'MILLER', 'CLERK', 7782, '1982-02-23', 1300.00, NULL, 10); INSERT INTO `emp` VALUES (8888, 'CHB', 'CLERK', 7369, '2018-12-10', 8000.00, 100.00, NULL); SET FOREIGN_KEY_CHECKS = 1;
dept表:
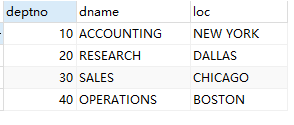
SET NAMES utf8mb4; SET FOREIGN_KEY_CHECKS = 0; -- ---------------------------- -- Table structure for dept -- ---------------------------- DROP TABLE IF EXISTS `dept`; CREATE TABLE `dept` ( `deptno` int(2) NOT NULL, `dname` varchar(14) CHARACTER SET latin1 COLLATE latin1_swedish_ci NULL DEFAULT NULL, `loc` varchar(13) CHARACTER SET latin1 COLLATE latin1_swedish_ci NULL DEFAULT NULL, PRIMARY KEY (`deptno`) USING BTREE ) ENGINE = InnoDB CHARACTER SET = latin1 COLLATE = latin1_swedish_ci ROW_FORMAT = Compact; -- ---------------------------- -- Records of dept -- ---------------------------- INSERT INTO `dept` VALUES (10, 'ACCOUNTING', 'NEW YORK'); INSERT INTO `dept` VALUES (20, 'RESEARCH', 'DALLAS'); INSERT INTO `dept` VALUES (30, 'SALES', 'CHICAGO'); INSERT INTO `dept` VALUES (40, 'OPERATIONS', 'BOSTON'); SET FOREIGN_KEY_CHECKS = 1;
建好表后,我们来创建一个存储过程。
示例1:通过存储过程完成查询每个员工编号(empno)、姓名(ename)、职位(job)、领导编号(mgr)、领导姓名(empno)、部门名称(dname)、部门位置(loc)。
delimiter // create procedure select_pro() begin select e1.empno bianhao, e1.ename xingming, e1.job zhiwei, e1.mgr lindaobianhao, e2.ename lindaoxingming, d.dname bumenmingchen,
d.loc bumenweizhi from emp e1 , emp e2 , dept d where e1.mgr=e2.empno and e1.deptno=d.deptno ; end // delimiter ;
注:“delimiter //”语句的作用是将MySQL的结束符设置为//,因为MySQL默认的语句结束符是分号“;”,为了避免与存储过程中的SQL语句结束符相冲突,需要使用delimiter改变存储过程的结束符,设置为以“end //”结束存储过程。存储过程定义完毕之后,再使用“delimiter;”回复默认结束符。delimiter也可以指定其他符号作为结束符(“\”除外,这是转义字符)。当然,如果你在Navicat等图形界面下进行,可以不用设置delimiter。
示例1中SQL语句创建了一个名为select_pro的存储过程,通过“call select_pro()”,即可完成查询功能,不在需要每次查询都重写查询语句。
示例2:创建一个带参数的存储过程,删除emp表中empno为指定值得记录,并返回最高最高月薪,也返回大于指定月薪的人数。
delimiter // create procedure param_pro(in id int , out num int, inout p_sal int) begin delete from emp where empno = id ; select max(sal) from emp into num; select count(*) into p_sal from emp where sal >P_sal ; end // delimiter ;
调用上面创建好的存储过程param_pro:
set @p_sal = 1250 ; call param_pro(7369 , @num , @p_sal); select @num , @p_sal ;
输出结果如下:
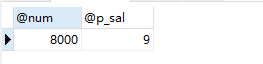
查看emp表,也发现empno为7369的记录确实被删除。
将查询结果赋值给变量时,可以使用into关键字,既可以在select子句末尾写into关键字,也可以在值后面写into语句。
3.2 创建存储函数
语法结构如下:
CREATE FUNCTION 函数名([ 参数名 数据类型 [, …]]) RETURNS返回类型 BEGIN 过程体 END
存储过程与存储函数一个很大的不同就是制定参数IN、OUT、INOUT只对存储过程有用,存储函数默认IN类型参数,不能设置其他两种类型。RETURNS子句声明返回值类型也只能在存储函数中使用,且一个存储函数必须包含一个RETURNS 语句。
示例3:用存储函数查询指定empno的员工的月薪sal
delimiter // create function fun1(id int) returns int begin return (select sal from emp where empno=id); end // delimiter ;
调用存储函数fun1:
select fun1(7698)
输出结果如下:

3.3 修改存储过程和函数
使用ALTER语句可以修改存储过程和函数的特性。语法结构如下:
ALTER {PROCEDURE | FUNCTION} sp_name [characteristic …]
其中,sp_name表示存储过程或函数的名称,characteristic参数指定存储过程或函数的特性,可能取值有:
CONTAINS SQL:子程序包含SQL语句,但不包含读或写数据的语句。
NO SQL:子程序不包含SQL语句。
READS SQL DATA:子程序包含读数据的语句。
MODIFIES SQL DATA:子程序包含写数据的语句。
SQL SECURITY { DEFINER | INVOKER}:指明谁有权限执行。
DEFINER:只有定义者自己才能执行。
INVOKER:调用者可以执行。
COMMENT ‘string’ :注释。
示例4:示例1中创建的存储过程param_pro,将其读写权限该为MODIFIES SQL DATA,并指明调用者可以执行。
ALTER PROCEDURE param_pro MODIFIES SQL DATA SQL SECURITY INVOKER ;
4 流程控制语句
MySQL中用来构造流程控制语句的有:IF语句、CASE语句、LOOP语句、LEAVE语句、ITERATE语句、REPEAT语句和WHILE语句。每一个流程中可能包含一个单独的语句,或者是使用BEGIN…END构造复杂语句,构造可以被嵌套。
(1)IF语句
IF语句包含多个条件判断,根据判断结果为TRUE或FALSE来执行相应的语句,语法格式如下:
IF expr_condition THEN statement_list [ELSEIF expr_condition THEN statement_list] [ELSE statement_list] END IF
注意:所以IF语句都需要用END IF来结束,在THEN中执行,ELSEIF和ELSE是可选的。
示例5:有一个变量val,判断变量值是否为空,若为空,输出“val is NULL”;否则输出“val is not NULL”。
IF val IS NULL THEN SELECT ‘val is NULL’ ; ELSE SELECT ‘val is not NULL’ ; END IF;
(2)CASE语句
CASE是另一种条件判断语句,该语句有两种格式,第一种格式如下:
CASE case_expr WHEN when_value THEN statement_list [WHEN when_value THEN statement_list]…… [ELSE statement_list] END CASE
参数说明:
case_expr,表示条件判断的表达式,决定了哪一个WHEN自己会被执行
When_value,表示表达式可能的值,如果,某个when_value表达式与case_expr表达式结果相同,则执行对应THEN关键字后的statement中的语句
Statement_list,表示不同when_value值的执行语句
示例6:使用CASE流程控制语句的第一种格式,判断val值,若等于1则输出‘val is 1’ , 若等于2则输出‘val is 2’,或者两者都不等于则输出‘val is not 1 or 2’:
CASE val WHEN 1 THEN SELECT ‘val is 1’; WHEN 2 THEN SELECT ‘val is 2’; ELSE SELECT ‘val is not 1 or 2’; END CASE;
CASE语句的第二种格式:
CASE WHEN expr_condition THEN statement_list [WHEN expr_condition THEN statement_list] [ELSE statement_list] END CASE;
示例7:使用CASE流程控制语句的第二种格式判断变量val是否为空,小于零、大于零、等于零,并作对应的输出:
CASE WHEN val is NULL THEN SELECT ‘val is NULL’ ; WHEN val < 0 THEN SELECT ‘val is less than 0’ ; WHEN val > 0 THEN SELECT ‘val is greater than 0’ ; ELSE SELECT ‘val is 0’ ; END CASE ;
注意,这里存储过程中的CASE语句,与控制流程函数中的SQL CASE表达式中的CASE是不同的,存储过程中,CASE语句不能有ELSE NULL子句,并且用END CASE代替END来终止。
(3) LOOP语句与LEAVE语句
LOOP语句循环语句用来重复执行某些语句,与IF和CASE语句相比,LOOP只是创建了一个循环操作过程,并不进行条件判断。LOOP内的语句一直被重复执行直到循环被退出,跳出循环使用的是LEAVE子句,LOOP语句基本语法结构如下:
[loop_label:] LOOP statement_list END LOOP [lop_label]
loop_label表示LOOP语句的标注名称,该参数可以省略。statement_list参数表示循环执行的语句。
示例8:定义一个变量id,初始值为0,循环执行id加1的操作 ,当id值小于10时,循环重复执行,当id值大于或者等于10时,使用LEAVE语句退出循环
DECLARE id INT DEFAULT 0; Add_loop:LOOP SET id=id+1; IF id>=10 THEN LEAVE add_loop; END IF; END LOOP add_loop;
(4)ITERATE语句
ITERATE语句用于将执行顺序转到语句段的开头处,语法格式如下:
ITERATE lable
其中,lable,表示循环的标志.注意,ITERATE语句只可以出现在,LOOP、REPEAT和WHILE语句中。ITERATE的作用类似于Java和Python中的continue关键字。
示例9:p1的初始值为0,如果,p1的值小于10时,重复执行p1加1的操作,当p1大于或等于10,并且小于20时,打印消息p1 is between 10 and 20,当p1大于20时,退出循环
演示ITERATE语句,在LOOP语句内的使用
CREATE PROCEDURE doiterate() BEGIN DECLARE p1 INT DEFAULT 0; my_loop:LOOP SET p1=p1+1; IF p1<10 THEN ITERATE my_loop; ELSEIF p1>20 THEN LEAVE my_loop; END IF; SELECT ‘p1 is between 10 and 20’; END LOOP my_loop; END
(5)REPEAT语句
REPEAT语句用于创建一个带有条件判断的循环过程,每次语句执行完毕之后,会对条件表达式进行判断,如果表达式为真,则循环结束,否则,重复执行循环中的语句。语法结构如下:
[repeat_lable:] REPEAT statement_list UNTIL expr_condition END REPEAT [repeat_lable]
其中,repeat_lable,为REPEAT语句的标注名称,该参数是可选的,REPEAT语句内的语句,或语句群被重复,直至expr_condition为真。
示例10:id值小于10前,重复循环让id值加1,使用REPEAT语句,执行循环过程
DECLARE id INT DEFAULT 0; REPEAT SET id=id+1; UNTIL id>=10; END REPEAT;
(6)WHILE语句
WHILE语句创建一个带条件判断的循环过程 与REPEAT不同的是,WHILE在语句执行时,先对指定的条件进行判断,如果为真,则执行循环内的语句,否则退出循环。语法结构如下:
[while_lable:] WHILE expr_condition DO Statement_list END WHILE [while_lable]
其中,while_lable为WHILE语句的标注名称,Expr_condition,为进行判断的表达式,如果表达式为真,WHILE语句内的语句,或语句群就被执行,直至expr_condition为假,退出循环。
示例11:创建一个变量i,初始值为0,当i小于10时重复执行加1。
DECLARE i INT DEFAULT 0; WHILE i<10 DO SET i=i+1; END WHILE;
5 查看存储过程和函数
(1) 使用SHOW STATUS语句查看存储过程和函数的状态
SHOW STATUS语句可以查看存储过程和函数的状态,其基本语法结构如下:
SHOW {PROCEDURE | FUNCTION} STATUS [LIKE ‘pattern’]
语法结构中,使用LIKE语句表示匹配存储过程或函数的名称。
示例12:查看示例2中创建的存储过程信息。
SHOW PROCEDURE STATUS LIKE ‘param_pro’ ;
部分输出结果如下:

(2)使用SHOW CREATE语句查看存储过程和函数的定义
SHOW CREATE语法结构如下:
SHOW CREATE {PROCEDURE | FUNCTION} sp_name
示例13:查看示例3中创建的存储函数信息。
SHOW CREATE FUNCTION fun1;

(3)从information_schema.Routines表中查看存储过程和函数信息
MySQL中的存储过程和函数的信息存储在information_schema.Routines表中,可以通过查询该表中的记录来查询存储过程和函数的信息。
示例14:从Routines表中查看形成为param_pro的存储过程信息。
SELECT * FROM information_schema.Routines WHERE ROUTINE_NAME = 'param_pro' AND ROUTINE_TYPE='PROCEDURE' ;
查询结果如下:

6 删除存储过程和函数
删除存储过程和函数可以使用DROP语句,其语法结构如下:
DROP {PROCEDURE | FUNCTION } [IF EXISTS] sp_name
示例15:删除存储过程select_pro和存储函数fun1。
DROP PROCEDURE IF EXISTS select_pro ; DROP FUNCTION IF EXISTS fun1 ;
7 总结
本文系统地介绍了MySQL中存储过程和存储函数的使用,包括了存储过程和存储函数的创建、修改、查看、删除等内容。不过对于游标等内容并未介绍。

作者:奥辰
微信号:chb1137796095
Github:https://github.com/ChenHuabin321
欢迎加V交流,共同学习,共同进步!
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接,否则保留追究法律责任的权利。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号