Python面向对象中super用法与MRO机制
1. 引言
最近在研究django rest_framework的源码,老是遇到super,搞得一团蒙,多番查看各路大神博客,总算明白了一点,今天做一点总结。
2. 为什么要用super
1)让代码维护更加简单
Python是一门面向对象的语言,定义类时经常用到继承的概念,既然用到继承就少不得要在子类中引用父类的属性,我们可以通过“父类名.属性名”的方式来调用,代码如下:
class A: def fun(self): print('A.fun') class B(A): def fun(self): A.fun(self) print('B.fun')
上述代码中,我们在子类B中调用了父类A的方法,这时候如果我们改变了A类的类名也只需要在B类中修改一下就好了,但是如果有几十上百个类继承了A类呢?一旦A类类名改了,我们就要分别到那几十上百个子类中修改,不但要改继承时用到的A类名,调用A类方法时用到的A类名也要改,繁琐的很,用super就好多了:
class A: def fun(self): print('A.fun') class B(A): def fun(self): super().fun() print('B.fun')
这时候,就算A类类名改了,也只需要在子类声明继承关系时修改就好了,简单得大多。
2)解决多继承带来的重复调用(菱形继承)、查找顺序(MRO)问题
上面说到的例子是单继承,用“父类名.属性”的方法调用出来代码维护时繁琐一点也并无不可,但Python是的继承机制是多继承,还是用这种方法来调用父类属性就会就回带来许多问题。假如有A、B、C、D这4个类,继承关系如下,我们要在各子类方法中显式调用父类的方法(姑且不考虑是否符合需求):
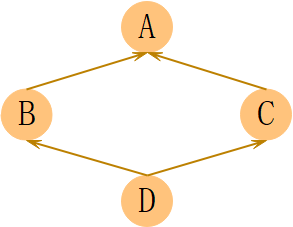
图1
用“父类名.属性名” 的方式调用,代码如下:
class A: def fun(self): print('A.fun') class B(A): def fun(self): A.fun(self) print('B.fun') class C(A): def fun(self): A.fun(self) print('C.fun') class D(B , C): def fun(self): B.fun(self) C.fun(self) print('D.fun') D().fun()
输出结果为:
A.fun
B.fun
A.fun
C.fun
D.fun
可见,A类被实例化了两次。这就是多继承带来的重复调用(菱形继承)的问题。使用super可以很好的解决这一问题:
class A: def fun(self): print('A.fun') class B(A): def fun(self): super(B , self).fun() print('B.fun') class C(A): def fun(self): super(C , self).fun() print('C.fun') class D(B , C): def fun(self): super(D , self).fun() print('D.fun') D().fun()
输出结果如下:
A.fun
C.fun
B.fun
D.fun
那么,为什么输出顺序是A->C->B->D而不是A->B->C->D呢?这就涉及到Python继承中的MRO(Method Resolution Order):方法解析顺序。
3. super与mro机制
事实上,在每个类声明之后,Python都会自动为创建一个名为“__mro__”的内置属性,这个属性就是Python的MRO机制生成的,该属性是一个tuple,定义的是该类的方法解析顺序(继承顺序),当用super调用父类的方法时,会按照__mro__属性中的元素顺序去挨个查找方法。我们可以通过“类名.__mro__”或“类名.mro()”来查看上面代码中D类的__mro__属性值:
print(D.__mro__) print(D.mro())
输出结果为:
(<class '__main__.D'>, <class '__main__.B'>, <class '__main__.C'>, <class '__main__.A'>, <class 'object'>)
[<class '__main__.D'>, <class '__main__.B'>, <class '__main__.C'>, <class '__main__.A'>, <class 'object'>]
一个是tuple,一个list,但本质上是一个东西。这个顺序是怎么生成的呢?在Python新式类中(Python3中也只存在新式类了),采用的是C3算法(可不是广度优先,更不是深度优先)。我们通过如下图所示的继承关系来简单介绍C3算法(箭头指向父类)。
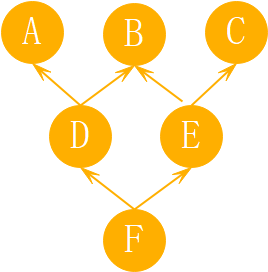 图2
图2
当要生成F的继承顺序时,C3算法过程如下:首先将入度(指向该节点的箭头数量)为零的节点放入列表,并将F节点及与F节点有关的箭头从上图树中删除;继续找入度为0的节点,找到D和E,左侧优先,故而现将D放入列表,并从上图树中删除D,这是列表中就有了F、D。继续找入度为0的节点,有A和E满足,左侧优先,所以是A,将A从上图中取出放入列表,列表中顺序为F、D、E;接下来入度为0的节点只剩下E,取出E放入列表;只剩下B和C节点,且入度都为0,但左侧优先,二先将B放入列表,然后才是后才是C;不过别忘了,Python所有类都有一个共同的父类,那就是object类,所以,最好还会把object放入列表末尾。最终生成列表中元素顺序为:F->D->A->E->B->C->object。我们用代码验证一下:
class A(object): pass class B(object): pass class C(object): pass class D(A,B): pass class E(B, C): pass class F(D, E): pass print(F.__mro__)
输出结果为:
(<class '__main__.F'>, <class '__main__.D'>, <class '__main__.A'>, <class '__main__.E'>, <class '__main__.B'>, <class '__main__.C'>, <class 'object'>)
所以,图1中的继承顺序为什么是D->B->C->A就好解释了。但还没弄清楚图1用super实现的代码输出顺序的问题,所以,我们还要继续看super的用法。
4. 怎么用super
super是一个类(不是方法),实例化之后得到的是一个代理的对象,而不是得到了父类,并且我们使用这个代理对象来调用父类或者兄弟类的方法。使用格式如下:
super([type[, object-or-type]])
将这个格式展开来就有一下几种传参方式:
super()
super(type , obj)
super(type_1 , type_2)
注意,可没有super(type)这种方式。下面说说上面三种传参方式。
4.1 super(type , obj)
先说super(type , obj),这个方式要传入两个常数,第一个参数type必须是一个类名,第二个参数是一个该类的实例化对象,不过可以不是直接的实例化对象,该类的子类的实例化对象也行。在上文中已经说到,super会按照__mro__属性中的顺序去查找方法,super(type , obj)两个参数中type作用是定义在__mro__数组中的那个位置开始找,obj定义的是用哪个类的__mro__元素。我们用代码来说明,将图2的代码各个类中添加一个fun方法,继承关系不变,代码如下:
class A(object): def fun(self): print('A.fun') class B(object): def fun(self): print('B.fun') class C(object): def fun(self): print('C.fun') class D(A,B): def fun(self): print('D.fun') class E(B, C): def fun(self): print('E.fun') class F(D, E): def fun(self): print('F.fun')
然后尝试super(type , obj)两个参数的不同组合,看看输出结果。
先让obj都为F类的实例,尝试不同type下的输出结果:
super(E , F()).fun() # 输出结果:B.fun super(D , F()).fun() # 输出结果:A.fun super(F , F()).fun() # 输出结果:D.fun
再回顾一下__mro__的顺序:F->D->A->E->B->C->object,发现规律没?调用的都是type对应的类在__mro__顺序中的下一个类的fun方法。所以,我们可以通过type参数来指定调用父类的范围。
再让type保持不变,obj尝试不同的实例:
super(B , F()).fun() # 输出结果:C.fun super(B , E()).fun() # 输出结果:C.fun super(B , B()).fun() # 这是错误的,会报错
发现规律了吗?上面这个类继承关系太简单,可能规律并不明显。事实上,obj参数指定的是用那个类的__mro__属性。
好了,我们现在回到图2中使用super()之后的代码,来解释一下为什么输出顺序是A->C->B->D。首先我们要明白,D类的__mro__顺序是D->B->C->A,在D类中调用fun方法,然后在D类fun方法中遇到super(D , self).fun(),这个self指的是D类的实例化对象,所以用的是D类的__mro__顺序,而且指明位置是D后面也就是B类,所以继续调用B类的fun方法,遇到super(B , self).fun(),这时候需要注意,这里的self还是原来的D类实例(千万注意不是B类实例),所以还是用D类的__mro__顺序,那就继续调用下一个C类的fun方法,同理继续调用下一个父类,也就是A类的fun方法,执行完A类的fun方法后,回到C的fun方法中,打印输出,然后回到B类的fun方法,知道D类的fun方法打印输出完。懂了吗?
4.2 super()
super()事实上是懒人版的super(type , obj),这种方式只能用在类体内部,Python会自动把两个参数填充上,type指代当前类,obj指导当前类的实例对象,相当于super(__class__ , self)。所以,以下三种代码是完全等效的:
代码一:
class B(A): def fun(self): super().fun() print('B.fun')
代码二:
class B(A): def fun(self): super(B , self).fun() print('B.fun')
代码三:
class B(A): def fun(self): super(__class__ , self).fun() print('B.fun')
4.3 super(type_1 , type_2)
当super传入的两个参数都是类名是,type_2必须是type_1的子类。功能上与super(type , obj)有什么不同呢?我们继续上一小节的代码输出测试:
print(super(F , F())) #输出结果为:<super: <class 'F'>, <F object>> print(super(F , F)) #输出结果为:<super: <class 'F'>, <F object>>
输出结果是一样的,那你就以为super(type_1 , type_2)与super(type , obj)一样吗?看下面输出:
print(super(F , F()).fun()) #输出结果为:D.fun print(super(F , F).fun()) # 报错:TypeError: fun() missing 1 required positional argument: 'self'
所以,super(type_1 , type_2)与super(type , obj)有区别,在看一下下列输出:
print(super(F , F()).fun)# 输出结果:<bound method D.fun of <__main__.F object at 0x000001BD44A98B38>> print(super(F , F).fun) # 输出结果:<function D.fun at 0x000001BD44A9EE18> print(D.fun) # 输出结果:<function D.fun at 0x000001BD44A9EE18>
所以,当super传入的两个传输都是类时,得到的就是一个指向继承顺序下的类的代理,并未绑定实例,要调用D类的fun方法,还需传入实例:
print(super(F , F).fun(F())) #输出结果:D.fun
所以,当super传入的两个参数都是类的时候,最好只用来调用类的静态方法或者类方法。静态方法、类方法、实例方法在我的上一篇博文中已详细讲述了。
5. 总结
最好,在实际写代码时,最好不要用诸如super(self.__class__, self) 的写法,容易导致异常,super 的第一个参数尽量为当前的类。至此,super的总结就结束了。

作者:奥辰
微信号:chb1137796095
Github:https://github.com/ChenHuabin321
欢迎加V交流,共同学习,共同进步!
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接,否则保留追究法律责任的权利。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号