
1、为什么要进行参数化
滥大街的说法:为了更加真实的模拟真实场景
正确说法:
● 数据库或应用程序需对值进行了唯一性校验;
● 避免缓存造成的性能测试结果失真;
举例说明:如查询张三的信息,第一次会很慢,第二次再查询时明显速度快很多。
原因分析:查询用户信息时打开表后,会先检查内存(执行计划)里是否有该SQL语句的执行结果,有直接拿结果,没有则会去磁盘查,在磁盘找到数据后,再将数据同步到内存。
2、怎样进行参数化
1)如图,选择要参数化的值,右键选择[Replace with a parameter]
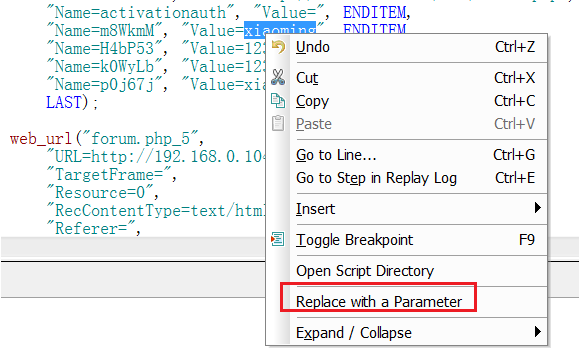
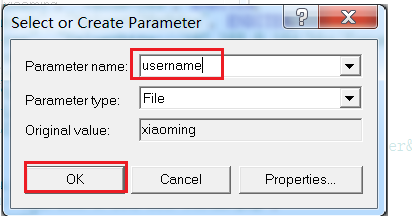
2)填写参数名称,点击[ok]即可

3)打开变量列表,填写变量值(或者从文件夹中打开)
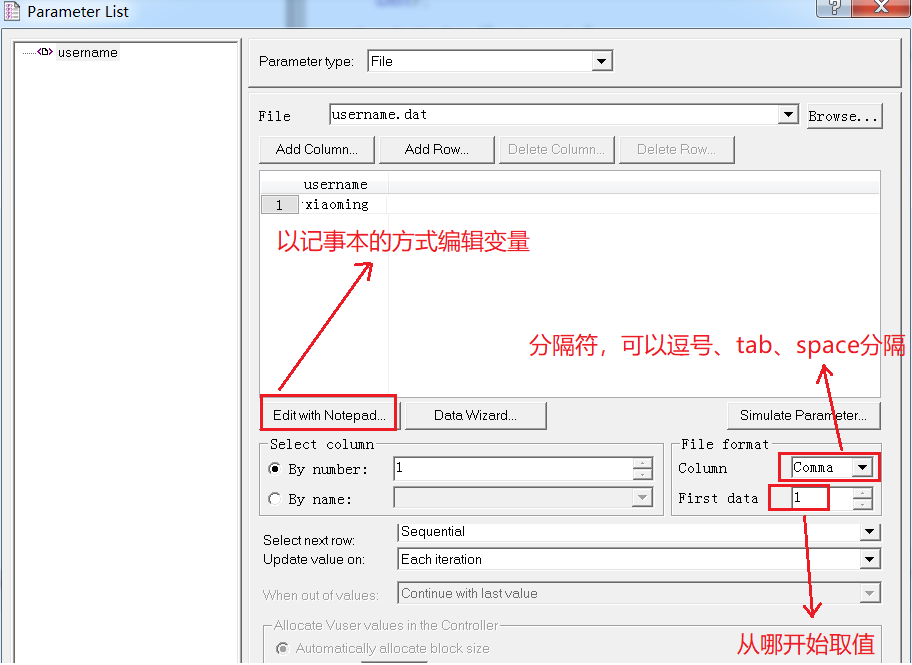
3、参数化变量和值是怎样对应的
根据脚本中的参数名({username})去找参数列表中的的参数username,再去找参数列表中的username对应的bat文件
4、参数化取值策略详解
如下:Loadrunner参数化取值策略由[select next row]、[update value on]两部分组成。各取值情况如下:
● Select next row(除去same as):顺序、随机、唯一
● Update value on:每次迭代、每次出现、唯一
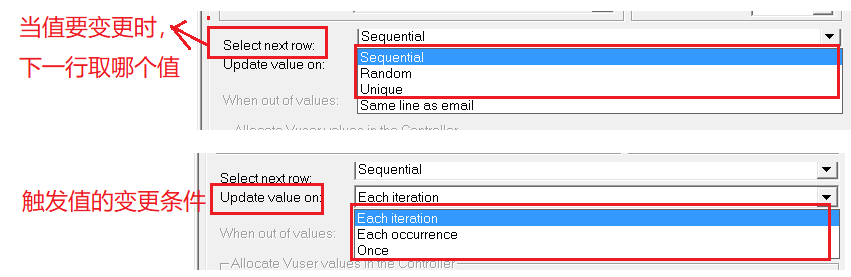
取值策略简单理解就是:当触发值的变更值条件时,下一个取值怎么取,除去same as 这种取值,根据排列组合共有9种取值情况。
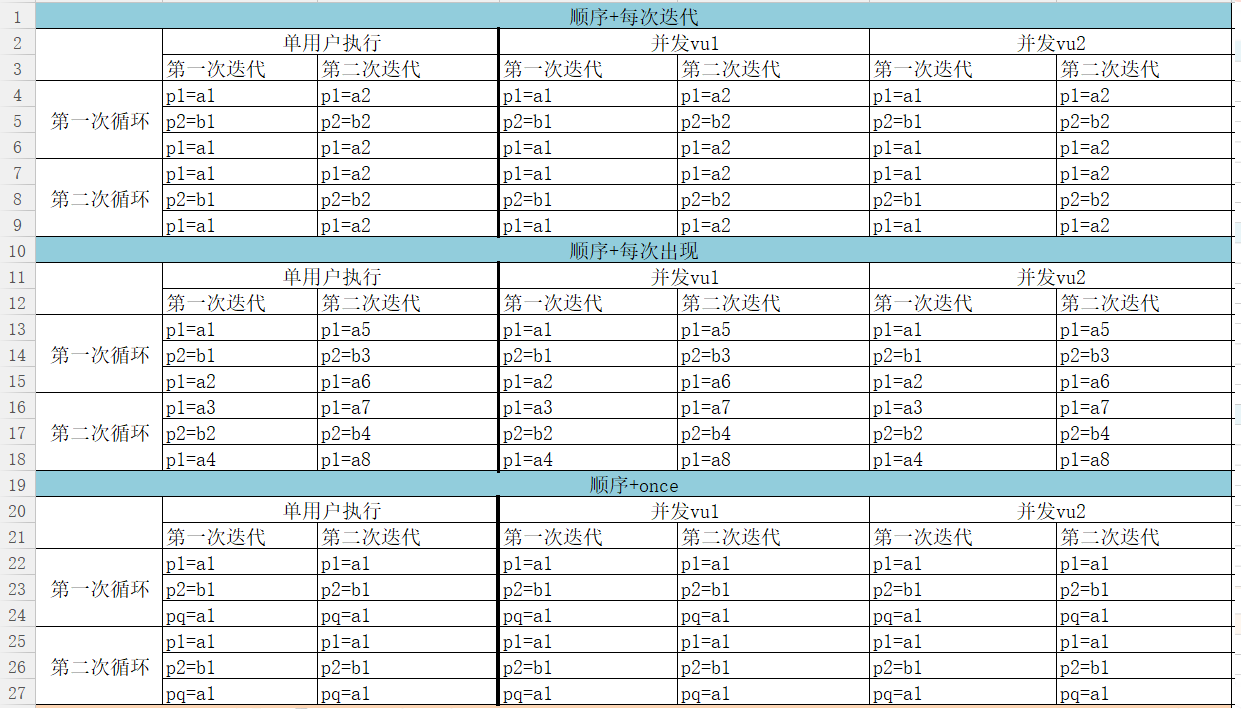
【例】:用以下脚本,迭代2次来说明这9种取值组合,其中p1参数值为a1-a10,p2参数值为b1-b10。
Action() { int i; //申明变量 for (i=0;i<2;i++) //循环2次 { char *a = "{p1}"; //获得参数赋值给a char *b = "{p2}"; //获得参数赋值给b char *c = "{p1}"; //获得参数赋值给c //打印9种参数化取值组合结果 lr_output_message("%s,%s\n,%s\n",lr_eval_string (a),lr_eval_string (b),lr_eval_string (c)); } return 0; }
取值结果详见下图:
策略1-6:
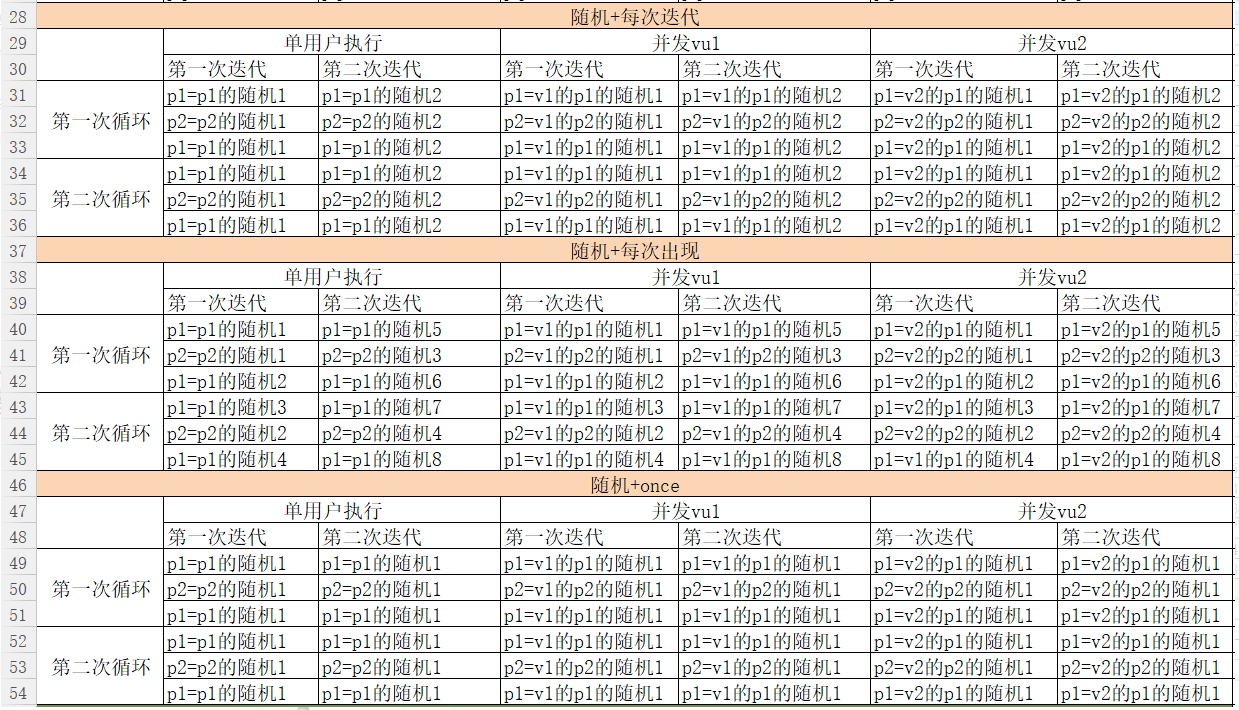
策略7-9:
唯一性体现在并发时:用户跟用户之间取值的唯一,即用户与用户之间取值没有交集
唯一+每次迭代:(除了用户之间取值不同,取值方式类似顺序+每次迭代)
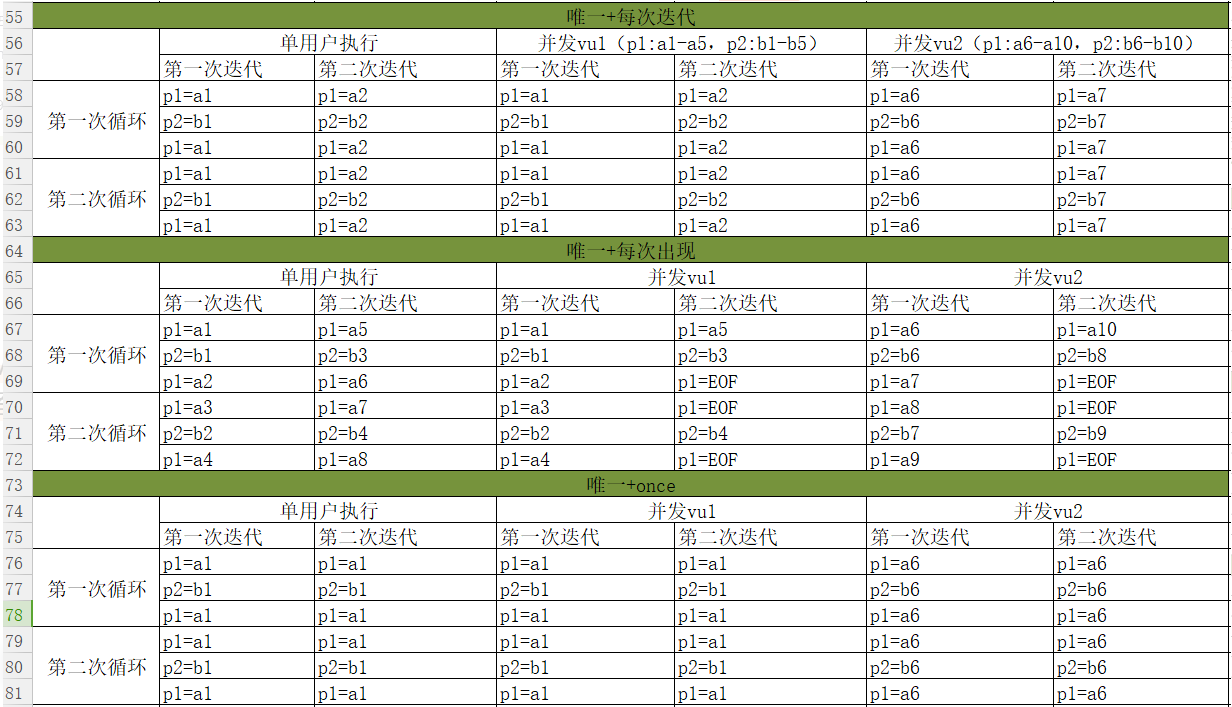
5、特别说明
当update value on值为[unique]时,可设置[when out of values]、[Allocate Vuser values in Cotroller]值
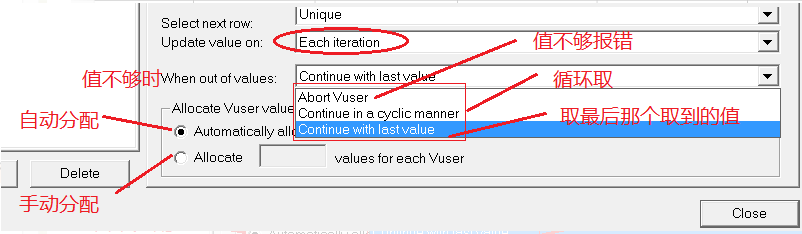
注意:
● 唯一+每次出现:不能自动分配(loadrunner不会读脚本,不知道脚本中的循环),只能手动分配
● 手动分配时要注意:计算每个用户分配多少个值、参数化文件中要录足够的值
计算手动分配时,为每个用户分配多少个值:
例1:银行流水号参数化,100个并发,跑10分钟,基准测试1个用户跑1s--TPS=1,假如服务器的tps无限大
解:10个并发每秒跑的请求量:1*10*10=100
10个并发跑10分钟请求量:100*10*60=60000
10钟每个用户跑的请求数:60000/10=6000
则理想情况下为每个用户分配6000个值,考虑到实际可为每个用户分配6200个值。
例2银行流水号参数化,10个并发,跑10分钟,1个用户跑TPS=10,假如服务器的tps为50
解:10个并发每秒跑的请求量:1*10*10=100>服务器TPS。服务器处理不过来
以服务器最大TPS来处理
10个并发跑10分钟请求量:50*10*60=30000
10钟每个用户跑的请求数:30000/10=3000
则为每个用户分配3000+个值即可
————————————————
原文链接:https://blog.csdn.net/yishuifengxiao/article/details/79645622
