
Node学习笔记 http
node url
querystring 第二个参数指定分隔符
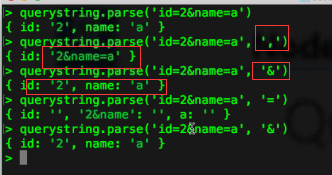
也可以指定三个参数,效果和两个参数类似

不同于querystring,下面是querystringfy的用法

queryescape与encodeURIComponent方法类似,能解析中文

HTTP爬虫
测试能不能从豆瓣请求到数据
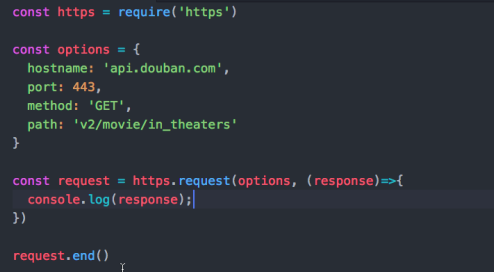
在当前文件的文件夹用node运行这个文件

数据请求成功
查看数据的headers

重新run一下这个文件

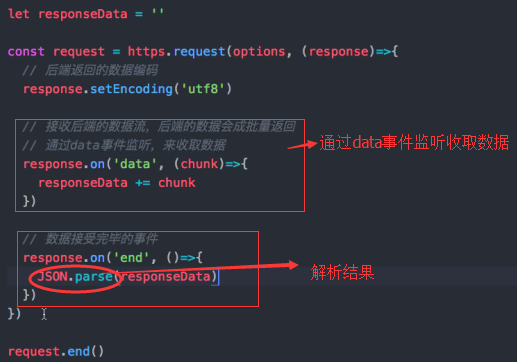
在后端设置返回数据的编码
response.setEncoding('utf8')
通过data事件监听收取数据
后端跨域方案
后端没有同源策略,直接获得数据返回给前端,前端可以直接用

通了之后,开始通过http协议做一个小爬虫程序
爬虫爬到的数据是服务器直接返回的内容,不会去爬取网页中异步获取的数据。
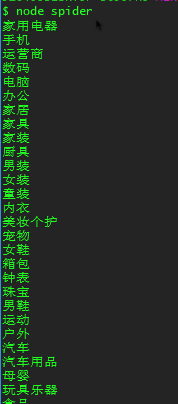
爬取京东的页面信息
过程中安装了一个cheerio的包,这个包是相当于服务器端的jQuery 装包: npm install cheerio -S
代码如下
const https = require('https')
const cheerio = require('cheerio')
options = {
hostname: 'www.jd.com',
port: 443,
method: "GET",
path: '/'
}
let responseData = ''
//过滤
function filterData(data){
let $ = cheerio.load(data)
let a = $('.cate_menu_item').find('a')
a.each((index,value)=>{
console.log($(value).text());
})
}
const request =https.request(options,(response)=>{
response.setEncoding = 'utf-8'
response.on('data',(chunk)=>{
responseData += chunk
})
response.on('end',()=>{
console.log(responseData);
filterData(responseData);
})
})
request.end()
爬取结果
EventEmitter
const EventEmitter = require('events')
class Player extends EventEmitter {}
let player = new Player()
player.on('play',(track)=>{
console.log(`正在直播${track}`)
})
player.emit('play','人民的名义')
player.emit('play','琅琊榜')
结果


 浙公网安备 33010602011771号
浙公网安备 33010602011771号